
数据生态第四弹 | OpenMLDB Hive Connector,架构起数据仓库到特征工程的生态桥梁
导读
近日,OpenMLDB 实现了与开源数据仓库软件 Hive 的连接,继完成与 Kafka、Pulsar、RocketMQ 等实时数据源生态整合后,持续构建离线数据生态,期待建设一个更加全面一体的上下游生态圈,在吸引更多用户的同时也能降低用户的使用门槛。
OpenMLDB Hive Connector
背景
OpenMLDB Hive Connector 的开发解决了 OpenMLDB 无法轻松连接使用 Hive 数据源的问题,利用其可以简单地对 Hive 数据进行读写,优化用户使用体验和降低时间成本。
介绍
通过 OpenMLDB Hive Connector 可以连接 Hive 数据源,对其进行数据访问和元数据操作。Hive 数据源的访问通过 Hive Metastore Service (HMS)。在使用 Hive Connector 之前,要确保 HMS 已启动。
优势
- Connector 联通 Hive 之后,只需配置好 Hive,就可以在 OpenMLDB 中用 hive:// 方式读写 Hive 表。
- 学习成本低,易上手。Hive 是 Apache Hadoop 上的 SQL 接口,可以写 SQL 语句来对数据进行处理和运算。
注意
- 在使用 Hive Connector 之前,必须启动 HMS。
- 目前只支持整表导入,不支持分区导入。
配置操作
OpenMLDB 版本要求:v0.6.7 及以上。
关键流程
- 启动 Hive 与 Hive metastore 服务
- OpenMLDB 配置 Hive metastore URI
- 启动 OpenMLDB 集群
- 测试——从 Hive 导入数据到 OpenMLDB 、从 OpenMLDB 导出数据到 Hive 表
具体操作
- Docker 上拉取并运行 OpenMLDB 镜像(镜像下载大小大约 1GB,解压后约 1.7 GB):
docker run -it 4pdosc/openmldb:0.6.7 bash
- 安装支持
a. 安装 jdk8:Docker 镜像内默认为 jdk11,Hive 不支持 jdk11,建议安装 jdk8:
apt-get update && apt-get install -y gnupg2
curl -s https://adoptopenjdk.jfrog.io/adoptopenjdk/api/gpg/key/public | apt-key add -
apt-get update && apt-get install -y adoptopenjdk-8-hotspot
export JAVA_HOME=/usr/lib/jvm/adoptopenjdk-8-hotspot-amd64
export PATH=$JAVA_HOME/bin:$PATH
b. 安装 Hadoop:
curl -SLO https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
tar zxf hadoop-3.2.3.tar.gz
export HADOOP_HOME=`pwd`/hadoop-3.2.3
curl -SLO http://mirror.bit.edu.cn/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
tar zxf apache-hive-3.1.3-bin.tar.gz
export HIVE_HOME=`pwd`/apache-hive-3.1.3-bin
c. 由于 Hadoop 和 Hive 的 Guava 版本不一致,运行以下命令调整为一致版本:
rm $HIVE_HOME/lib/guava-19.0.jar
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
$HIVE_HOME/bin/schematool -dbType derby -initSchema
- 使用 Hive 客户端创建表
使用 Hive 客户端创建表 htable(表会创建到默认数据库 default,如需使用其他数据库,请保证数据库已存在,OpenMLDB 不会自动创建 Hive 数据库);插入一条数据,可以查询出已插入的数据:
$HIVE_HOME/bin/hive
CREATE TABLE htable(key INT, value STRING NOT NULL);
INSERT INTO htable VALUES (NULL, "n"), (1,"a"), (2,"b");
SELECT * FROM htable;
- 启动 Hive metastore 服务(默认端口号为 9083):
$HIVE_HOME/bin/hive --service metastore > metastore.log 2>&1 &
- OpenMLDB 配置 Hive 连接,并启动 OpenMLDB 集群
有多种方式配置 Hive 连接,具体请参考 Hive 配置文档。此处使用“在 taskmanager 配置文件中添加 Hive 连接配置”的方式。
a. 打开 taskmanager 配置文件:
vim openmldb/conf/taskmanager.properties
b. 在 spark.default.conf 配置项中添加配置
spark.hadoop.hive.metastore.uris:
spark.default.conf=...;spark.hadoop.hive.metastore.uris=thrift://localhost:9083
c. 启动 OpenMLDB 集群:
/work/init.sh
- 从 Hive 导入数据到 OpenMLDB
需要提前创建好 OpenMLDB 表 otable,使用LOAD DATA语句,只需使用hive://前缀并指定 Hive 表名便可导入表中数据到 OpenMLDB 表 otable。支持导入到在线和离线。运行以下代码导入到离线:
CREATE DATABASE db;
USE db;
CREATE TABLE otable(key INT, value STRING NOT NULL);
SET @@sync_job=true;
SET @@job_timeout=600000;
LOAD DATA INFILE 'hive://htable' INTO TABLE otable OPTIONS(mode='overwrite');
- 将 OpenMLDB 表数据导出到 Hive
使用SELECT INTO语句,同样路径只需要使用hive://前缀并指定表名(表可以不存在,将自动创建)。
USE db;
SET @@sync_job=true;
SET @@job_timeout=600000;
SELECT * FROM otable INTO OUTFILE 'hive://hsaved' OPTIONS(mode='overwrite');
可以在 Hive 中查询到 hsaved 表,由于演示使用的是 derby 作为元数据库,请将 metastore 进程关闭后再使用 $HIVE_HOME/bin/hive 查询:
SELECT * FROM hsaved;
也可直接在 Hive 的保存目录中看到 hsaved 表:
ls /user/hive/warehouse/hsaved
写在最后
关于 OpenMLDB
OpenMLDB 是一个开源机器学习数据库,致力于闭环解决 AI 工程化落地的数据治理难题,为企业提供全栈的低门槛特征数据计算和管理平台。OpenMLDB 包含 Feature Store 的全部功能,并且提供更为完整的 FeatureOps 全栈方案。除了提供特征存储功能,还具有基于 SQL 的低门槛数据库开发体验、面向特征计算优化的 OpenMLDB Spark 发行版、针对实时特征计算优化的索引结构、特征上线服务、企业级运维和管理等功能,让特征工程开发回归于本质——专注于高质量的特征计算脚本开发。
关于 Hive
Hive 是 Facebook 实现并开源的基于 Hadoop 的一个数据仓库工具。Hive 本质上将 SQL 语句转换为 MapReduce 任务运行,让不熟悉 MapReduce 编程模型的用户可以快速地使用 HiveQL 处理和计算存储在 HDFS 上的结构化数据,适用于离线的批量数据计算。Hive 适用于传统数仓业务,不适用于低延迟的交互访问。
生态上下游体系
为了降低开发者使用 OpenMLDB 的门槛,OpenMLDB 社区将持续打造面向上下游技术组件的生态圈,为开发者提供更多简单易用的生态 Connector。
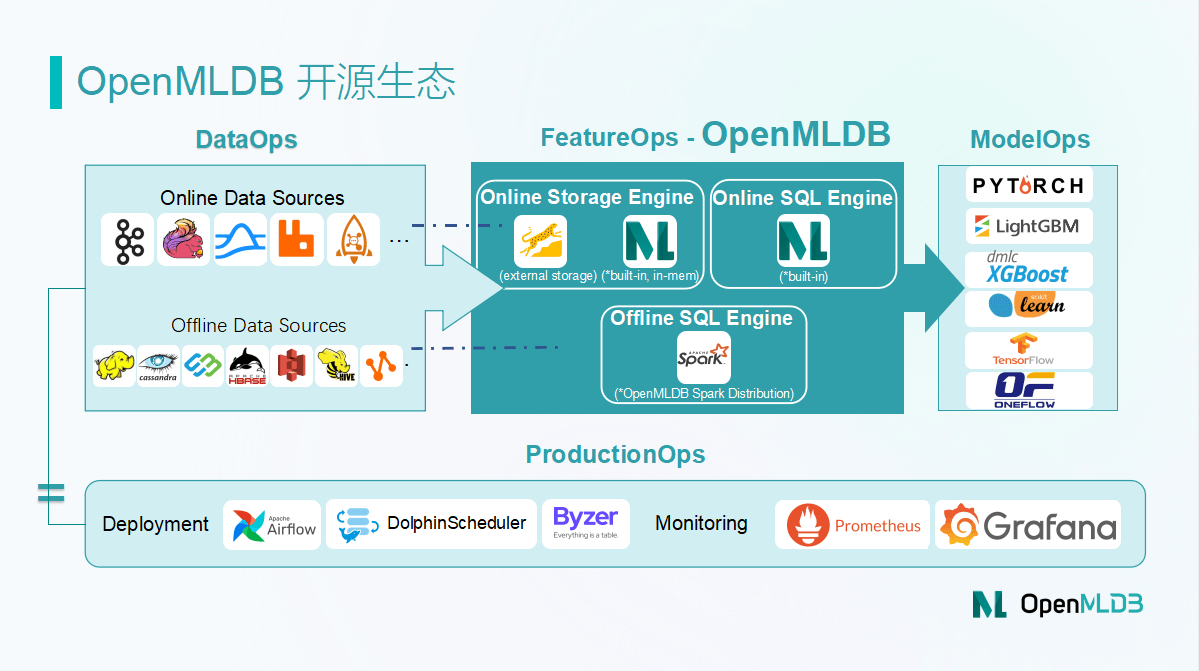
- 面向线上数据生态,如:Pulsar、Kafka、RocketMQ、Flink、RabbitMQ 等。
- 面向离线数据生态,如: HDFS、Hive、MaxCompute、HBase、Cassandra、S3 等。
- 面向模型构建的算法、框架,如:XGBoost、LightGBM、TensorFlow、PyTorch、OneFlow、ScikitLearn 等。
- 面向机器学习建模全流程的调度框架、部署工具,如:DolphinScheduler、Airflow、Byzer、Kubeflow、Prometheus、Grafana 等。
相关阅读
OpenMLDB 文档:https://openmldb.ai/docs/zh/main/
OpenMLDB Hive Connector 产品文档:http://openmldb.ai/docs/zh/main/reference/sql/dml/LOAD_DATA_STATEMENT.html#hive
若您有相关问题,可以加入微信交流群:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号