
基于 OpenMLDB 的联邦学习方案被国际数据挖掘学术会议 CIKM 录取
本周,数据挖掘领域的国际顶级学术会议 CIKM 2022 (https://www.cikm2022.org/) 正在美国亚特兰大举行。由第四范式和新加坡国立大学合作的论文 "A System for Time Series Feature Extraction in Federated Learning" 被 CIKM 录取。
该论文主要描述了基于 OpenMLDB 的时序数据特征抽取的语义,扩展到联邦学习的创新性研究工作。该方案进一步和流行的开源联邦学习框架 FATE 进行了无缝整合,进行了开源并且可以直接运行。
经过实验验证,使用该方案的 FATE 应用模型质量(AUC)提升 3% , 召回率提升 10%;在广告投放业务中,带来 10% 的投放增效。
-
论文原文:
https://dl.acm.org/doi/pdf/10.1145/3511808.3557176
(点击“阅读原文”,即可跳转查看)
-
演讲视频:
-
代码 repo:
https://github.com/4paradigm/tsfe
(包含了源代码以及和 FATE 整合的可运行框架)
随着严格的数据隐私安全要求的出台,各个企业之间数据不能随意地交流交换,一个个数据孤岛日渐形成。联邦学习,一种在保护数据隐私的前提下进行联合机器学习的方法,应运而生。联邦学习在如反欺诈、风控、推荐等场景下有广泛的应用前景。此类场景中,基于时序数据的特征工程是最终能达成业务效果的关键一环。但是,在目前流行的联邦学习框架下,时序数据的特征工程并没有被很好的支持。因此,第四范式基于 OpenMLDB 时序特征工程的语义,在联邦学习的场景下进行扩展,赋能严格数据隐私要求下联邦时序特征的构建能力。
第四范式的方案基于两大工业级产品:OpenMLDB 和 FATE,打造整合了联邦时序特征生成的联邦学习全流程。其中,自动时序特征生成和筛选的算法基于 OpenMLDB,功能实现上无缝连接 FATE 联邦学习全流程的各个模块。如下图一显示了基于 OpenMLDB 的时序特征方案和 FATE 整合的流程,在样本对齐以后,额外增加了联邦时序特征抽取的步骤,在原始特征上添加了时序特征,再把所有特征一起放入模型训练。
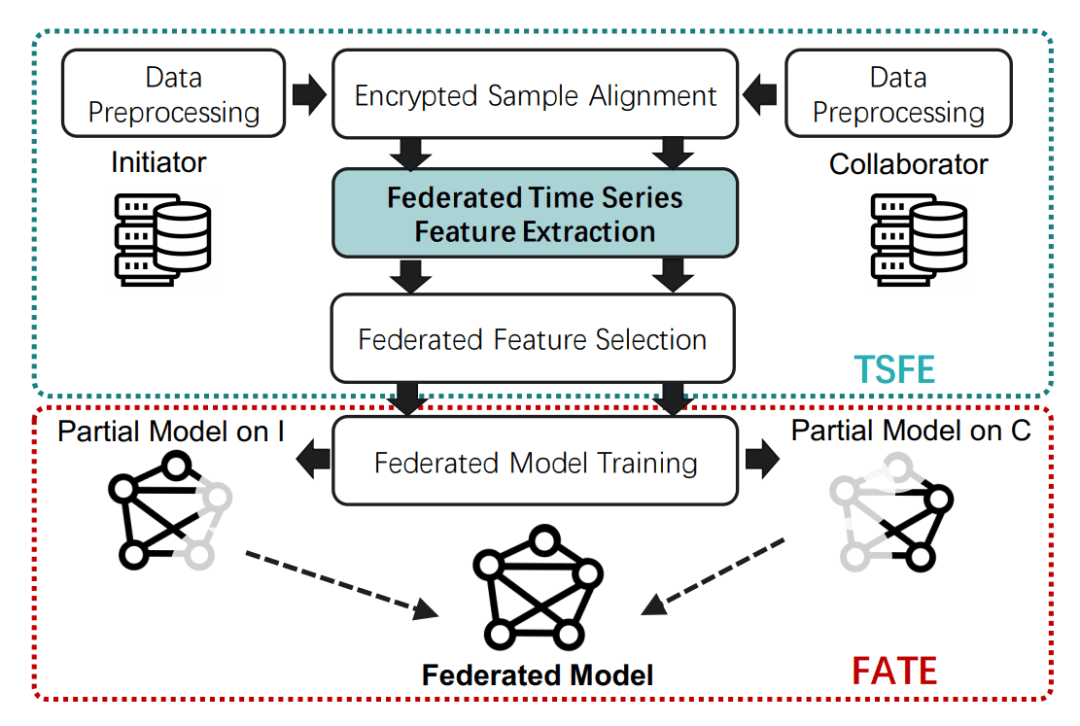
图一:联邦时序特征抽取模块(TSFE)和 FATE 框架的全流程整合
时序数据的特征工程一般包括时间戳衍生和时序值衍生两类:
- 时间戳衍生类特征工程:只需要使用到时间戳单列特征来生成,较为简单。例如,是否为早晨,距离周末的天数等。
- 时序值衍生类特征工程:例如滑动窗口统计,在隐私数据保护的要求下,在联邦学习框架下的实现具有技术挑战性。
以银行交易欺诈判断为例,银行在判断交易是否为欺诈时,可以使用用户过去一周的电信公司通话记录信息来作为一项参考。这种场景下,用来生成时序特征的起始时间戳记录存储在银行数据库中,而用来生成特征的数据,如通话时长、通话次数等,存储在电信公司的数据库中。
在第四范式的方案中,提供了一种基于同态加密和随机函数加密机制实现隐私保护的通信协议,在加密分享关键信息的同时,保证原始数据不出库,确保安全高效,使得参与建模的双方在不披露原始数据的前提下,分享加密的时间窗口信息,合作方可以利用该窗口信息在本地生成发起方所请求的时序特征,用于之后的联邦时序建模。该方案同时提供特征选择功能,基于特征的 IV 值筛选新特征,进一步提升联邦建模效能。下图二显示了该协议的详细工作步骤,更多细节可以参考论文原文。

图二:联邦时序特征生成具体步骤举例
未来,第四范式以及OpenMLDB 社区也将继续推进在基于隐私计算方面的研究和开发工作,也欢迎感兴趣的社区小伙伴加入我们。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号