
OpenMLDB+Byzer,SQL 也能玩转机器学习全流程
本文整理自 Byzer PMC、Kyligence 技术合伙人祝海林在第四范式技术日「高效落地的AI开源生态」分论坛的主题分享——《OpenMLDB 和 Byzer 整合之路》。

很荣幸今天能够参加第四范式的分享。
Byzer 是什么
设计理念
想必通过前面的分享大家已经对 OpenMLDB 有了一定的了解,那在这里我就不过多赘述 OpenMLDB,而是先向大家简单介绍一下 Byzer。
首先 Byzer 的诞生是为了降低 Data+AI 的门槛,让其成为水和电。OpenMLDB 的目标和 Byzer 是一致的。因为目前在大数据和 AI 之间,不管是平台还是语言依旧存在着比较强的割裂。同时,维护也存在困难,使用门槛比较高。我们希望能够通过一些技术和工具来降低这些成本,提高大家使用大数据和 AI 的效率。我们如何去实现这一点呢?我们会通过诸如 OpenMLDB 的一系列 FeatureOps 产品去完成这件事情。
而 Byzer 是什么呢?Byzer 其实是一个面向 Data+AI 领域的一个云原生的类 SQL 语言,它几乎支持所有主流的 SQL 使用需求,例如可以用 Byzer 去完成 ETL 数据挖掘、机器学习建模和模型部署、可视化。

使用形态
它目前使用形态也是比较多的,普通的分析师或者医生,可以直接使用我们的桌面版做数据分析。假设是需要给一个公司使用,那我们一般推荐使用 Byzer 的 Notebook,这一个纯 web 版的工具,完成部署后整个公司的人都可以使用。而对于一个普通的研发工程师,需要要到某个机器上临时分析一个数据,如果还想简单使用 SQL 来做分析,那么传统的部署流程会比较复杂,这个时候就可以使用我们的 Byzer-shell。
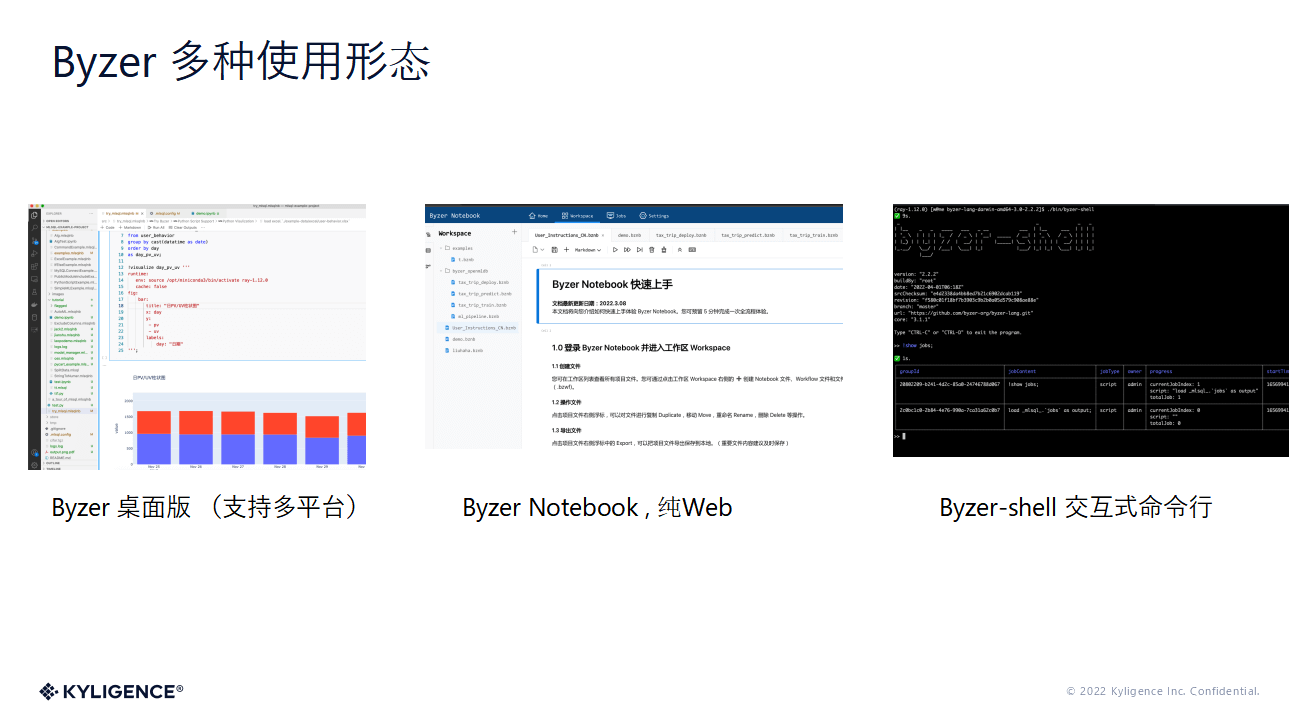
OpenMLDB+Byzer
需求场景
Byzer 其实更倾向于服务 Data+AI,所以它一定能够完成数据的抽取,从各个地方去获取,然后把数据转换成表,并且可以使用 SQL 去做一些数据处理。同时的话,它还覆盖了 AI 领域的建模和预测。
然而,Byzer 还是缺少一部分功能,就是特征工程的一部分,尤其是实时特征工程。比如我们可能需要在使用模型做一个预测的时候,里面可能会用到一些实时类的特征,例如最近三个小时某一个用户的购买点击数,那这些的话是要进行实时计算的。
流程介绍
在这里,我会简单介绍一下这个实时计算流程大概是什么样子的?以及如何通过我们的 OpenMLDB+Byzer,使用 SQL 去完成这一整套流程。
假设我们要进行一个特征工程加一个模型训练,这是离线部分。那我们可能还有一个部署,加上 OpenMLDB 之后的话,我们可以把特征像模型一样进行部署。最后的话,我们可以通过HTTP接口提供一个实时的预测API,那整个 pipeline 流程就走完了。
大致上 Byzer 和 OpenMLDB 衔接的话,主要是通过存储的文件系统,当然也可以通过类似于 Kafka 之类的流处理平台进行衔接。在今天的例子里,我会使用文件存储系统进行衔接。第一步,我们加载了一个数仓里面的数据(当然也可以从其他地方进行加载)。
加载完成之后,需要保存到特定目录,可能是对象存储,也可能 HDFS。之后我就可以利用 Byzer 里面的 OpenMLDB 的插件,让它去加载我们刚刚写到文件系统里面的数据,加载的目标表是 T1。
加载到 T1 表之后,我们就可以使用 OpenMLDB 里面的 SQL 进行一个特征工程,并且把特征工程的结果保存到文件目录里面去。
生成之后就可以去实时 infer 一下生成的数据。接着用 Byzer 做一些简单的数据处理,比如说类型转换,包括特征的转换。
最后的话,使用 Byzer 线性回归的算法进行一个训练,最后我们可能会得到一个模型。这个整个过程中的话,其实我们产生了两个比较重要的结果:
- 第一个,我们产生了一个特征工程的逻辑,在这里面得到体现。
- 第二个,我们产生了一个模型,它会保存在 model/tax-trip 目录下。
如果我们希望把它部署成一个 API 服务的话,那就需要有一个部署的过程。对于部署的过程,因为我们需要部署一个特征工程和一个模型。特征工程这一块,依然使用 FeatureStoreExt 插件,然后去把刚刚的计算逻辑去 deploy 到我们的 OpenMLDB 里面去,即可完成。
Byzer 这边的模型,我们可以使用 Register 语法注册线性回归的模型,并且把它转换成一个 UDF 函数去使用。在这里我们是通过一个注解来完成,把这个模型注册到一个 API 服务里面去。那这样的话,就相当于我们把线下的模型和特征工程的成果都已经注册到线上的一个 online 的预测服务里面去了。
模型是部署在 online 的预测服务里面的,接着我们怎么去调用这个特征工程呢?实际上是我们会发起一个 rest 接口的请求。这些所有功能组合,可以通过Byzer 的多个UDF 函数来完成,最终完成预测流程。
在演示案例里,我会去访问 OpenMLDB 特征工程的地址,然后对这个数据进行处理。之后把它转换成 JSON,进行一个切割。切割后,把它转换成一个向量,使用之前注册的预测函数进行预测,最终得到结果。
其中我们使用 Byzer的 curl 插件,整个执行速度应该还是会非常快的。就相当于说,整个流程的话,完全使用了 Byzer+OpenMLDB 就完成了一个端到端的机器学习流程。从数据的抽取,然后特征工程、模型训练到部署,到最后提供 API 服务进行一个预测,整个过程不需要离开 Notebook 就可以全部完成。
从演示可以看出,Byzer+OpenMLDB 极大地降低了使用的成本,而且全程 SQL 化,降低了整个 AI 包括数据处理的门槛。这是 OpenMLDB+Byzer 产生的一个巨大价值。
我们做完演示,接着回顾一下在整个端到端的机器学习中,特征计算通过 Byzer 的插件 FeatureStoreExt 转换到了OpenMLDB 里面去计算。Online 部分通过 Rest 的 UDF 函数去实时请求 OpenMLDB,因为 OpenMLDB支 持毫秒级的特征值的计算。Byzer 的 UDF 函数也能够支持到毫秒级预测的能力。

整合方案介绍
最后是 Byzer 还可以作为 OpenMLDB 的前置处理,比如说我们把数据通过批或者流的方式 写到对应的文件系统里,OpenMLDB 可以把它加载进去。当然了,Byzer 也能做流式的处理,所以也可以说把数据规整化写入到Kafka,然后经过 Kafka 然后流入到OpenMLDB 去进行一个计算。我们整个流程全都是类 SQL 的语法,所以是可以很好地去降低整个大数据和 AI 的门槛的。
从扩展性的角度来说,在 Byzer 里面通过 Ext 插件,我们就可以把 OpenMLDB 整合进来。其实通过一些其他的插件,也可以把其他的一些产品,或者说我们 MLOps 里面的一些其他的组件纳入流程中,这是 Byzer 的价值所在。
我们再来看一下这个过程中的话,OpenMLDB+Byzer 整合是使用了一些什么样的技术方案?
首先来看一下 OpenMLDB 对外的接口,这里的罗列不一定完全,目前我看到的是有 JDBC、SDK 和 Rest 这三种类型的。
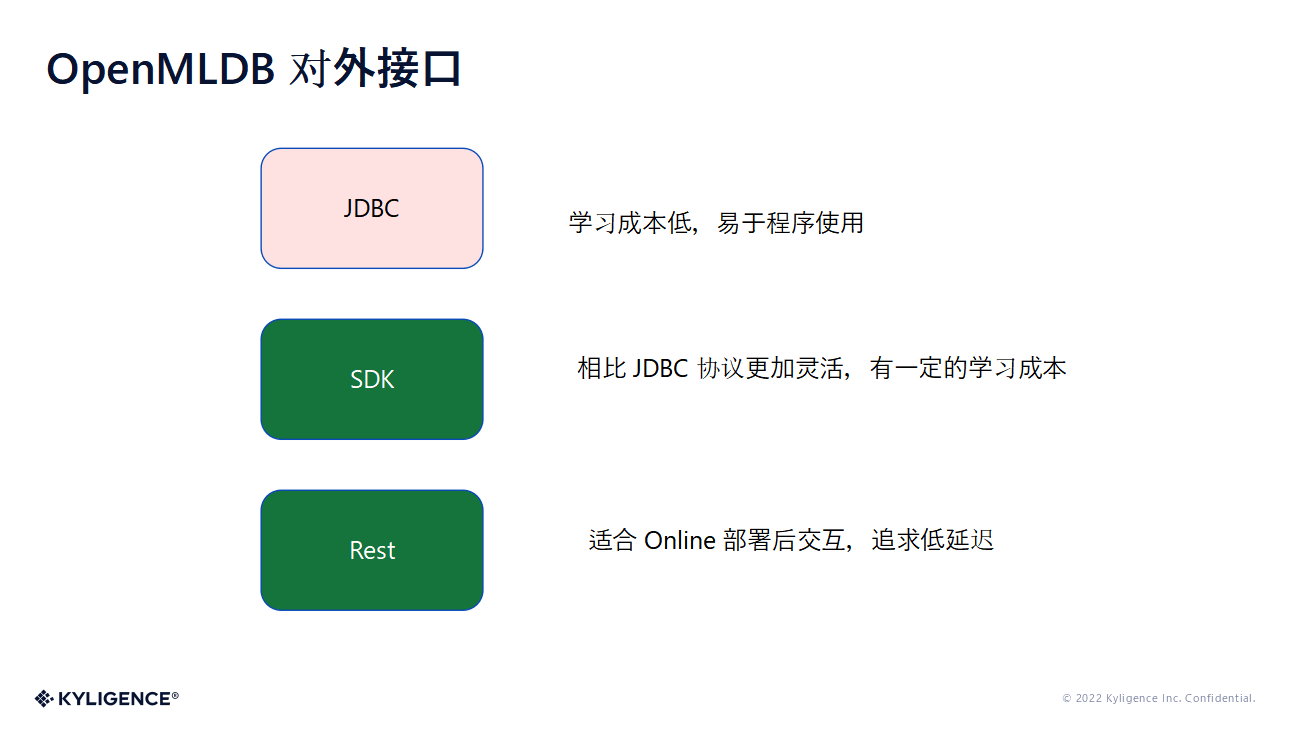
JDBC 的话,因为足够普及,所以它的学习成本就比较低,普及成本也比较低,而且容易被程序去使用。
但 SDK 的话,相对来说比 JDBC 更灵活,涵盖更多 OpenMLDB 里面的功能。如果需要有更详细掌控的话更加推荐使用 SDK。当然,使用 SDK 的缺点是有一定的学习成本。
最后一个是 Rest API,也就是说你是可以通过 API 请求去访问 OpenMLDB。这个接口主要是为了追求一个低延时的交互。
这些都是 OpenMLDB 对外提供的能力,这些能力的话就可以很方便第三方去集成 OpenMLDB。
那 Byzer 是如何去用 OpenMLDB 的三种交互方式呢?首先在Byzer里面,我们会去开发一个叫 FeatureStoreExt 插件。这在 Byzer 里面其实就是一个类。然后你把它写好之后打完 Jar 包丢到Byzer里面去,之后启动时,它就可以作为以Byzer语言的语法来进行调用。
之后 Where 条件里面对应的,比如说 train 方法中的 params 其实就是一个Map,这个Map 里则是一堆的 key value。之后的话,代码会去获得连接地址之后对它进行一个执行。这里面我们主要是调用了 OpenMLDB 的 SDK 和 OpenMLDB 进行一个交互。
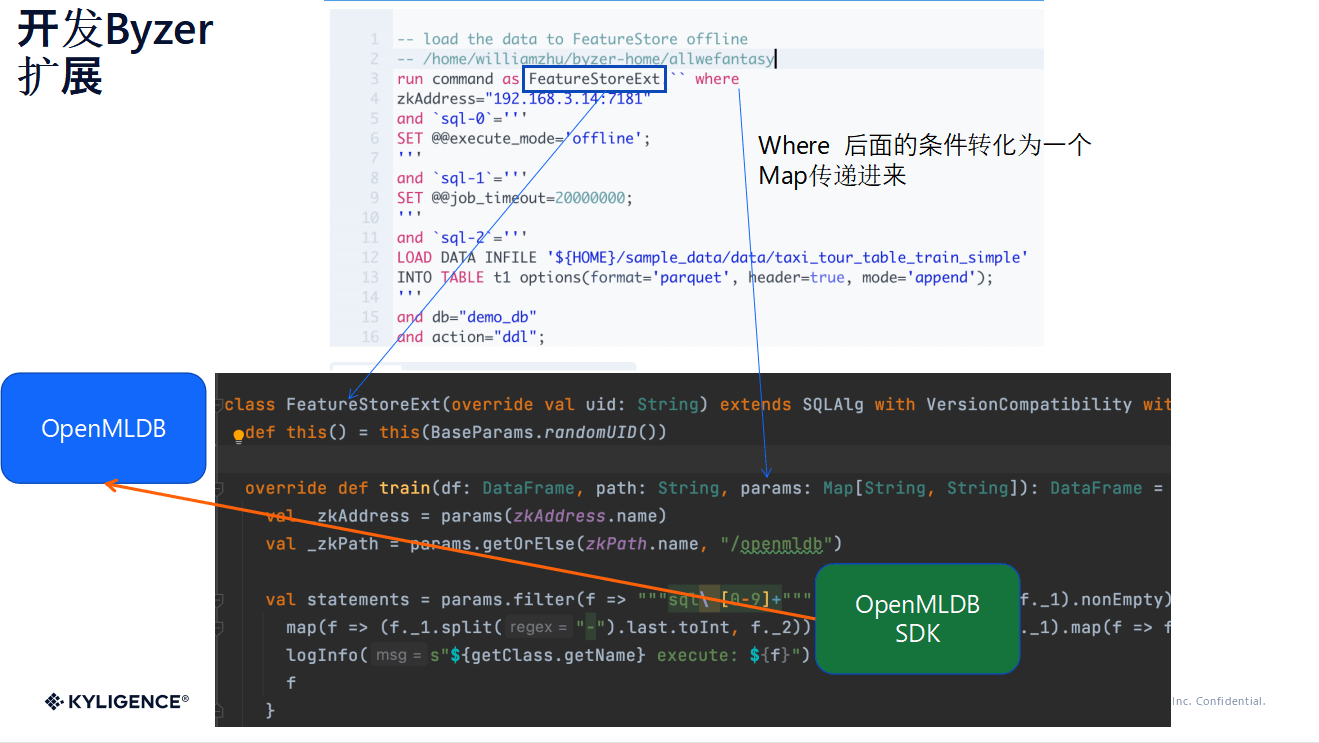
这个插件也比较简单,比如说我们开发完这个插件之后,就可以在 Byzer 的 Notebook 里面通过 plugin app add 的命令,把 Byzer OpenMLDB 扩展插件装上就可以了。

刚刚那一部分的话,我们主要是离线训练部分,还有一个是在线预测这一块。在线预测这一块,因为 OpenMLDB 提供了 Rest 的接口,所以在 Byzer 预测服务这一块,也就是 model server 这一块可以直接去调用内置的 rest request 的函数。在这里面会展示会更清楚一些,调用这个 OpenMLDB 的接口,然后使用 POST 的请求,用户传进来的参数就是出租车的数据。
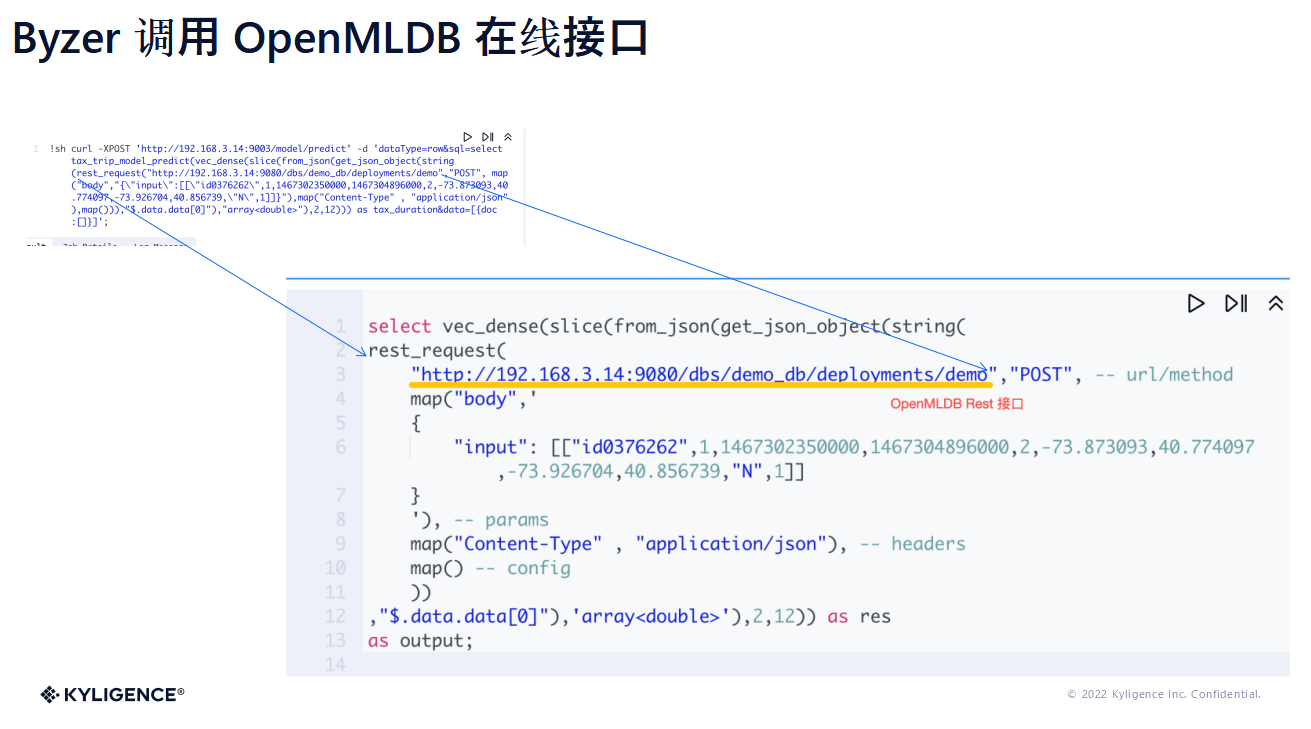
之后的话,我们使用 JSON 的格式,可以再进一步做处理将特征转换成一个向量,供我们后面的模型的 UDF 函数去使用。
这样的话,我们就通过 Byzer 和 OpenMLDB 在离线和在线这个接口方面,就完成了一个全面的整合。Byzer 和 OpenMLDB 整合过程中的话,OpenMLDB 在 Byzer 这边看来其实就是一个类似于数据库的服务。通过它提供的那三种类型的接口,我们就可以很好地去进行集成,那也证明它很容易被第三方集成。
在 Byzer 这边的话,Byzer 也可以通过自己的扩展能力去很好地集成 OpenMLDB 这类第三方的应用,从而完成一个端到端的工作流程。

今天的分享到此结束,也欢迎大家关注一下 Byzer 社区,感谢收听。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号