

学习深度学习--逻辑斯特回归
逻辑斯特回归虽然名字叫做回归,但是他却是解决的分类问题,他的原理在线性回归的基础上进行一次映射,通常使用sigmoid函数将线性回归出来的值映射到[0,1]的空间上,以0.5作为分界线以达到分类的目的:
z=w.T*x+b
y_h = sigmoid(z) = 1/(1+exp(-z))
优化函数的选择:
1. 在给定的x和w情况下,h(x)表示结果取1的概率,1-h(x)表示结果取0的概率
P(y=1|x;w) = h(x)
P(y=0|x;w) = 1-h(x)
2. 用一个简化的形式来表达
P(y|x;w) = h(x)^y*(1-h(x))^(1-y)
3. 那么它的最大似然函数: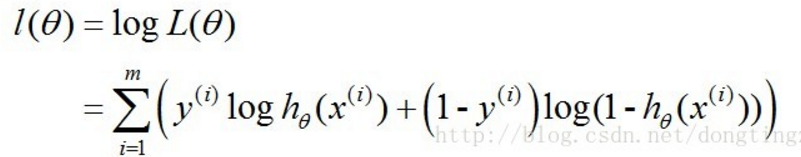
4. 对最大似然函数取log,不改变单调性: 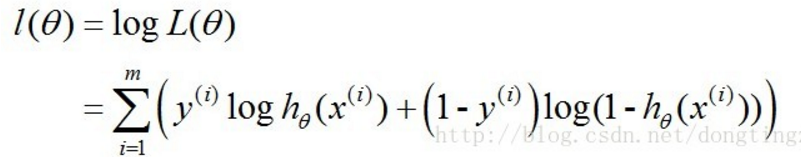
5. 那我们优化的目标就是要找到一组参数w,使得l(w)最大,等价与使1/m*l(w)最小
J(w)=1/m*l(w)
直接上代码吧:
%matplotlib inline import numpy as np import matplotlib from matplotlib import pyplot as plt #先看看sigmoid函数长什么样 def sigmoid(x): return 1.0/(1.0+np.exp(-x)) z=np.arange(-10.0,10.0,0.5) zeros = np.zeros_like(z) sigmoid = 1.0/(1+np.exp(-z)) plt.plot(z,sigmoid) #和学习线性回归一样,先构造一个训练集,这里就不能够完全用随机的方法来构造了,如果全部都是随机的,没有办法做分类,看了网上一些都没有提供数据集,偷懒就直接用函数取生成了: num_features = 2 num_samples = 1000 true_w = [5,3.5] true_b = 10 #构建一个m个样本,2个特征的数据集 features = np.random.normal(scale=5,size=(num_samples,num_features)) #print(time.time()) labels = sigmoid(np.dot(features,true_w)+true_b) labels[labels<0.5]=0 labels[labels>0.5]=1 labels[labels==0.5]=1 #画下图,长这样的 fig = plt.figure() ax=fig.add_subplot(111) ax.scatter(X0_0,X1_0,s=10,c='red') ax.scatter(X0_1,X1_1,s=10,c='green') plt.show() # ax.scatter(x1List,y1List,s=10,c='green') #用向量化的方式定义梯度下降: def BGD(X,y): m,n=X.shape w = np.ones(shape=(n,1)) b = 0 i = 0 alpha = 0.03 while i<500000: Z = np.dot(X,w) + b A = sigmoid(Z) dZ = A-y.reshape(m,1) dw = 1/m*np.dot(X.T,dZ) db = 1/m*np.sum(dZ) w = w - alpha*dw b = b - alpha*db i+=1 # print(X.shape,w.shape,Z.shape,A.shape,dZ.shape,b.shape) print(w,b) if __name__ == '__main__': BGD(features,labels)
posted on 2018-12-19 17:15 四个男人和一个女人的博客 阅读(326) 评论(0) 编辑 收藏 举报

