
KMCT分页控件与存储过程分页完美结合---存储过程分页篇(原创)
上一篇分页控件(KCMT开源控件之--方便简洁的分页控件 )出来以后,好几位网友期待我的存储过程分页与该控件结合使用的例程,这个星期工作很忙,一直没有时间完成。今天终于抽出时间来完成这篇文章。
首先从存储过程分页谈起
为什么要选择用存储过程分页呢?其实原因很简单,数据库查询功能的性能终究是有限的。即使我们对数据库进行了最优配置,对数据表设计再三斟酌,然而一旦面临海量数据,且返回结果集较大的时候,常规的查询语句就无能为力了。一般说来,当返回的结果集超过总数量的40%时,数据库层面上的优化就显得束手无策了。此时,我相信大多数同行首先想到的便是分页。当我们指定好每页的记录总数(PageSize)和当前页的索引(CurrentPage)时,理想的状况便发生了,首先我们不再从一个海量数据(百万级)中检索出超过40%的数据量,我们可以做个估算如果每页显示50条记录,那么也就是从100万条记录中查询50条记录,这个比例我相信大家都比较清楚。其次,网络中的数据通信量将大大缩减,我想这笔帐就不用我再做过多解释。同时,查询数量的减少对内存开销、页面的刷新、用户的等待时间都会得到相应的减少。
好处颇多,如何实现呢?我大致总结了以下几种实现方式。下面,我将一一介绍:
我将表分成两类
1.数据表中有唯一的自增索引,并且这个字段没有出现断号现象。在此我姑且称之为连续表,后面文章中出现的连续表就是指此类表。
2.数据表中不存在唯一的自增索引,或者存在唯一自增索引,但是由于删除记录等操作让该索引不连续,对于这类表我称之为不联系表。
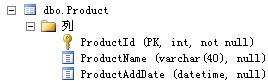
分页之前我们模拟一张产品表,其结构如下图:
插入1000000条记录
SET @I=0
WHILE(@I<1000000)
BEGIN
INSERT INTO PRODUCT(ProductName,ProductAddDate) VALUES('产品名',GETDATE())
SET @I=@I+1
END
同时给出存储过程的结构,由于今天只讨论分页,所以查询条件、排序分组方法等请读者自行补充。
@PageSize int,
@CurrentPage int,
@TotalPage int output
AS
BEGIN
--select method
END
GO
说明:由于上一篇文章的分页控件需要一个总页数的参数,因此将@TotalPage 作为输出参数返回符合记录的总页数。@CurrentPage为0表示
第一页。
执行存储过程代码
SET STATISTICS IO ON
SET STATISTICS TIME ON
GO
DECLARE @return_value int,
@TotalPage int
EXEC @return_value = [dbo].[SelectProduct]
@PageSize = 50,
@CurrentPage = 1,
@TotalPage = @TotalPage OUTPUT
SELECT @TotalPage as N'@TotalPage'
SELECT 'Return Value' = @return_value
GO
SET STATISTICS PROFILE OFF
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
测试环境:
Win2003、SqlServer2005、720775条记录、每页50条记录、本机直接访问数据库、每组10次查询取平均值
连续表的分页方案:
方案:利用ID筛选出要得到的数据
@PageSize int,
@CurrentPage int,
@TotalPage int output
AS
BEGIN
EXEC('SELECT TOP '+@PageSize+'* FROM Product WHERE ProductId>('+@PageSize+'*'+@CurrentPage+')')
SELECT @TotalPage=COUNT(*)/@PageSize FROM Product
END
说明:SELECT TOP 后面不能直接跟变量,所以采用了拼接sql的办法
测试结果:
页码 执行时间(ms)
1 1
100 2
1000 4
5000 9
10000 13
14000 16
分析结果发现在百万级数据都在小于0.1秒,这足以满足大多数要求,但是随着数据页的增大呈现一种查询变缓的趋势。
当然还有其他对ID进行比较的如:between and and so,当然还有游标分页,虽然通用性很好,但是性能很差。今天我就不一一列举,因
为今天要讨论的重点是不连续表的分页技术。
不连续表的分页技术
为了让上面的表不连续我们将部分记录删除
执行完成后(30032 行受影响)即30032条记录被删除,如果我们再用连续表的分页方式在此表上分页就不再适用。因为检索的记录中存在断
号现象。所以我们需寻求新的方法分页
方案一:重建数据表的唯一自增索引
重建之后采用连续表的分页方式,因为该方式是效率最高的分页查询。该方案不适用于将该唯一自增索引作为其他表外键的关系型数据库,
这样将会导致数据混乱,望慎用。
方案二:采用临时表分页
局部临时表的生存期一次会话过程,说得简单点就是当一个用户执行一个查询时创建,查询执行完成后自动删除。
@PageSize int,
@CurrentPage int,
@TotalPage int output
AS
BEGIN
DECLARE @BeginID INT ,@EndID INT
SET @BeginId=@PageSize*@CurrentPage
SET @EndID=@PageSize*(@CurrentPage+1)
CREATE TABLE #TmpProduct(
Id int IDENTITY(1,1) PRIMARY KEY,
ProductId int not null)
INSERT INTO #TmpProduct(ProductId) SELECT ProductId FROM Product
SET @TotalPage=@@ROWCOUNT/@PageSize
SELECT * FROM Product as p,#TmpProduct as t WHERE p.ProductId=t.ProductId and t.ProductId BETWEEN @BeginId AND
@EndID
END
测试结果:
记录总数 查询时间(ms)
10000 198
100000 669
250000 1454
500000 3980
700000 5543
由此我们发现规律,当数据量越小查询速度也就越快,因此该方法适用于小数据量的表。从执行计划中发现向临时表中插入数据占用了整个
查询过程的90%-95%时间,而真正查询我们想要的产品记录仅仅占了5%-10%,那么有没有办法不去反复执行插入过程呢?那么我们可以采用
全局临时表或者普通表,代码如下:
首先创建全局临时表并插入记录:
Id int IDENTITY(1,1) PRIMARY KEY,
ProductId int not null)
INSERT INTO ##TmpProduct(ProductId) SELECT ProductId FROM Product
重写存储过程
@PageSize int,
@CurrentPage int,
@TotalPage int output
AS
BEGIN
DECLARE @BeginID INT ,@EndID INT
SET @BeginId=@PageSize*@CurrentPage
SET @EndID=@PageSize*(@CurrentPage+1)
SELECT * FROM Product as p,##TmpProduct as t WHERE p.ProductId=t.ProductId and t.ProductId BETWEEN @BeginId AND
@EndID
SELECT @TotalPage=COUNT(*)/@PageSize FROM PRODUCT
END
测试结果:
记录总数 查询时间(ms)
10000 10
100000 27
250000 41
500000 69
700000 86
综合两种临时表分页方法分析,很明显采用全局临时表分页的效率远高于局部临时表分页,但是全局临时表需要定时维护,包括记录改变,
索引改变。这种维护成本限制了该方法的发展。所以,在小数据量的情况下建议使用局部临时表分页,如果数据量较大请参考下面的方案。
方案三:采用ROW_NUMBER()分页
@PageSize int,
@CurrentPage int,
@TotalPage int output
AS
BEGIN
DECLARE @BeginID INT ,@EndID INT
SET @BeginId=@PageSize*@CurrentPage
SET @EndID=@PageSize*(@CurrentPage+1)
SELECT * FROM (SELECT *,ROW_NUMBER()OVER(order by ProductId) AS ROWNUM FROM Product) as t WHERE ROWNUM BETWEEN
@BeginId AND @EndID
SELECT @TotalPage=COUNT(*)/@PageSize FROM Product
END
测试结果:
记录总数 查询时间(ms)
10000 210
100000 150
250000 165
500000 69
700000 86
从统计数据中不难看出
综合所有分页我们发现,分页无非就是对记录的编号进行处理,如果编号符合我们要求的我们就可以用连续表的方式直接使用,如果不符合
要求的,我们便改变这种编号使其符合要求,如重新建立编号,其实临时表和ROW_NUMBER()均属于重建编号的过程。
备注:文章中的数据均亲自实测得来,该数据仅作参考和比较,不同的目标机运行时间都将不同。如果文章中存在不正确的观点和看法,望
大家指出,不能误导读者。请大家尊重笔者的劳动果实,转载望注明出处:http://www.cnblogs.com/4inwork。当明白了存储过程分页的原
理子后下篇文章将结合控件来一个具体事例。

