【NetDevOps】新一代网工需要了解的那点事儿---云计算中的网络虚拟化(一)
这篇文章本应该在2018年更详细的记录在《docker by F0rGeEk》中,由于那本书正好写到网络章节时出了点状况所以没有继续写下去。。。😂还是那句老话:出来混早晚都得还😅😅😅
本文篇幅较长虽有目录,为方便阅读特将本文按章节拆成几个部分:
【NetDevOps】新一代网工需要了解的那点事儿(一)---网络虚拟化
【NetDevOps】新一代网工需要了解的那点事儿(二)---veth-pair
【NetDevOps】新一代网工需要了解的那点事儿(三)---Linux Bridge
【NetDevOps】新一代网工需要了解的那点事儿(四)---tun/tap
【NetDevOps】新一代网工需要了解的那点事儿(五)---iptables
【NetDevOps】新一代网工需要了解的那点事儿(六)---VTI
【NetDevOps】新一代网工需要了解的那点事儿(七)---VXLAN
【NetDevOps】新一代网工需要了解的那点事儿(八)---Macvlan
1. 网络虚拟化
1.1 传统网络虚拟化
随着云计算、大二层、SDN等等这些名词的出现,传统网络架构面临的挑战变得越来越迫切。业内曾有人说“要想实现真正的软件自定义数据中心,网络虚拟化将是最后一公里”从架构上来看确实没毛病。这时候着急的是传统网络厂商,如果不与时俱进则很有可能被淘汰。就好比人家都在玩触屏,你(NOKIA)却还执意玩按键(当然这不是主要原因)。其实传统的网络在前几年数据中心比较火的时候,也催生出很多虚拟化相关的技术。网络虚拟化其实并不陌生,我们常用的Overlays、VLAN、VPN、VRF、HSRP、MPLS这些都是传统网络不断迭代出的虚拟化技术,迫于数据中心、云计算等的需要相继出现了类似STACK、VSS、VDC、VPC、VEB、VEPA、VN-TAG、VXLAN、MacVLAN等技术。这些技术有的能在有限的物理网络架构中支持多个逻辑网络,有的能将不同的物理硬件整合到一起,有的则类似计算虚拟化将有限的物理资源虚拟出多个逻辑资源。
最近在看一本书《Kubernetes网络权威指南》,看了部分章节后觉得有必要暂停脚步理一理。首先是感谢作者提供这么一本书,让传统网工有机会接触Linux中的网络虚拟化,感谢这本书中的坑给我机会去了解Linux底层IP路由是如何实现的。其次是要吐槽一下对于Linux底层不了解的读者来说,第一章可能就晕了!亲身经历😷😷😷 有些地方理解起来和传统网络还真有差别,下面我将戴着口罩😷以一个传统网工的角度来讲解Linux中的网络虚拟化。
1.2 Linux中网络结构
Linux 虚拟网络的基石都是由一个个的虚拟设备构成的。虚拟化技术没出现之前,计算机网络系统都只包含物理的网卡设备,通过网卡适配器,线缆介质,连接外部网络,构成庞大的 Internet(如下图所示)。然而,随着虚拟化技术的出现,网络也随之被虚拟化,相较于单一的物理网络,虚拟网络变得非常复杂,在一个主机系统里面,需要实现诸如交换、路由、隧道、隔离、聚合等多种网络功能。而实现这些功能的基本元素就是虚拟的网络设备,比如 bridge、tap、tun 和 veth/veth-pair。
Physical NIC
+--------------+
| Socket API |
+-------+------+
User Space |
+------------------------------------------+
Kernel Space |
raw ethernet
|
+-------+-------+
| Network Stack |
+-------+-------+
|
+-------+-------+
| eth0 |
+-------+-------+
|
+-------+-------+
| NIC |
+-------+-------+
|
wire
1.3 Linux network namespace
传统网络中我们有一个技术叫VRF,一般我们可以将每一个VRF看作是一台专用的PE设备。它有独立的路由表、地址空间,有属于自己的网络接口、路由协议。在Linux中类似VRF的功能被称作是network namespace,当然Linux还有其他很多的namespace这里就不做过多讲解(因为我不专业😴)。每个network namespce都有自己的网络设备(如IP、路由表、端口范围、安全策略、/proc/net目录等)。在Linux中维护network namespace主要使用netns这个工具,下面我们逐一展开来讲解。
注:下文为方便书写特将network namespace用NS代替。
1.3.1 netns各参数意义
[root@F0rGeEk ~]# ip netns help # 该命令可获取netns相关帮助文档
Usage: ip netns list # 查看系统中的ns
ip netns add NAME # 创建一个ns
ip netns set NAME NETNSID # 给某个ns分配ID
ip [-all] netns delete [NAME] # 删除一个ns
ip netns identify [PID] # 查看某个进程的ns
ip netns pids NAME # 查找关于这个ns为主的进程
ip [-all] netns exec [NAME] cmd ... # 在某个ns中执行命令
ip netns monitor # 监控对ns的操作
ip netns list-id # 通过list-id显示ns
1.3.2 创建一个ns
我们创建一个名为forgeek的NS,其过程如下;当我们创建一个NS时,系统会自动在/var/run/netns目录中生成一个挂载点。这个挂载点即方便对ns的管理,也是NS在没有进程运行的情况下依然存在。
[root@F0rGeEk ~]# ip netns add forgeek
[root@F0rGeEk netns]# pwd
/var/run/netns
[root@F0rGeEk netns]# ls -l
total 0
-r--r--r--. 1 root root 0 Mar 17 03:23 forgeek
1.3.3 在NS中执行命令
在主机中我们可以在NS中执行一些命令,经过实践发现居然可以在NS中执行bash切换到NS的shell,比较好奇这样在安全上有没有风险。这里为了区分两个shell,我特意将新建的NS中的hostname命名为ns-forgeek:
[root@F0rGeEk ~]# ip netns exec forgeek ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@F0rGeEk ~]# ip netns exec forgeek bash
[root@ns-forgeek ~]# ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@ns-forgeek ~]# exit
exit
[root@F0rGeEk ~]#
1.3.4 激活ns中的环回接口
通过1.2.3实验过程,我们可以看到当我们创建一个ns后,系统默认会给该ns分配一个loopback接口,并且默认情况下这个接口处于DOWN的状态。这里我们将其设置为UP,之所以要在这里花费一个小结做这个,是因为如果该接口处于DOWN状态的话,后期会有很多你想不到的坑在等你!真的是经验之谈😂😂😂
# 方法一:
[root@F0rGeEk ~]# ip netns exec forgeek ip link set dev lo up
[root@F0rGeEk ~]# ip netns exec forgeek ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 方法二:
[root@F0rGeEk ~]# ip netns exec forgeek bash
[root@ns-forgeek ~]# ip link set dev lo up
[root@ns-forgeek ~]# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
1.3.5 查询并删除一个NS
[root@F0rGeEk ~]# ip netns list
forgeek
[root@F0rGeEk ~]# ip netns delete forgeek
[root@F0rGeEk ~]# ip netns list
[root@F0rGeEk ~]#
1.4 虚拟网络设备veth-pair
veth从名字上来看是 Virtual Ethernet 的缩写,veth是成对出现的一种虚拟网络设备。一端连接着协议栈,一端连接着彼此,数据从一端出,从另一端进,通常也称作veth-pair(如下图所示)。它的作用很简单,就是要把从一个 network namespace 发出的数据包转发到另一个 namespace中。正因为它的这个特性,常常被用来连接不同的虚拟网络组件,构建大规模的虚拟网络拓扑,比如连接Bridge、OVS、LXC、Docker容器等。很常见的案例就是它被用于Docker网络还有OpenStack Neutron,构建非常复杂的网络形态。
Veth Pair
+--------------+ +--------------+
| Socket API | | Socket API |
+-------+------+ +-------+------+
| |
User Space | |
+------------------------------------------------------------------+
Kernel Space + +
raw ethernet raw ethernet
+ +
+-------+-------+ +-------+-------+
| Network Stack | | Network Stack |
+-------+-------+ +-------+-------+
| |
+-------+-------+ +-------+-------+
| vethX | | vethX |
+-------+-------+ +-------+-------+
| |
+---------------------------+
1.4.1 创建veth-pair
我们通过"ip link"相关命令,创建一对虚拟网卡veth0和veth1。其中给veth0配置IP为12.1.1.1/24,veth1配置IP为12.1.1.2/24,并激活这一对虚拟网卡。"ip link"命令相关参数比较多,可以使用"ip link help"查看这里就不做过多解释。最后通过"ip link list"查看虚拟网卡相关状态,连接图及创建过程如下:
+--------------------------------------------------------------------------------------+
| +-------------------------------------------------------------+ |
| | Network Protocol Stack | |
| +------+------------------------+-----------------------+-----+ |
| ^ ^ ^ |
| | | | |
+--------------------------------------------------------------------------------------+
| | | | |
| v v v |
| +-------+------+ +-----+-----+ +-----+-----+ |
| | Eth0 | | Veth0 | | Veth1 | |
| +-------+------+ +-----+-----+ +------+----+ |
| ^ ^ ^ |
| 10.10.10.137 | 12.1.1.1/24| |12.1.1.2/24 |
| | +------------------------+ |
| | |
+--------------------v-----------------------------------------------------------------+
| Physical Network By:[F0rGeEk] |
+--------------------------------------------------------------------------------------+
- 创建一对veth
[root@d1 ~]# ip link add veth0 type veth peer name veth1
# 查看是否创建成功
[root@d1 ~]# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:97:0f:70 brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 12:64:bd:95:4f:40 brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 96:10:c9:07:77:d9 brd ff:ff:ff:ff:ff:ff
- 为虚拟网卡配置IP
[root@d1 ~]# ip addr add 12.1.1.1/24 dev veth0
[root@d1 ~]# ip addr add 12.1.1.2/24 dev veth1
# 查看是否配置成功
[root@d1 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:97:0f:70 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.137/24 brd 10.10.10.255 scope global noprefixroute dynamic ens33
valid_lft 5444486sec preferred_lft 5444486sec
inet6 fe80::d956:a6bf:6a6e:b6a7/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 12:64:bd:95:4f:40 brd ff:ff:ff:ff:ff:ff
inet 12.1.1.2/24 scope global veth1
valid_lft forever preferred_lft forever
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 96:10:c9:07:77:d9 brd ff:ff:ff:ff:ff:ff
inet 12.1.1.1/24 scope global veth0
valid_lft forever preferred_lft forever
- 激活这一对虚拟网卡
[root@d1 ~]# ip link set veth0 up
[root@d1 ~]# ip link set veth1 up
# 查看是否激活
[root@d1 ~]# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:97:0f:70 brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 12:64:bd:95:4f:40 brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 96:10:c9:07:77:d9 brd ff:ff:ff:ff:ff:ff
1.4.2 veth-pair连通性
接1.4.1步骤这一对虚拟网卡IP地址在同一段且均已激活,这里我们用veth0 ping veth1,查看网络是否可以连通。测试过程如下:
[root@d1 ~]# ping 12.1.1.2 -c 3 -I veth0
PING 12.1.1.2 (12.1.1.2) from 12.1.1.1 veth0: 56(84) bytes of data.
--- 12.1.1.2 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 1999ms
由上面步骤可以看出,实际上这一对虚拟网卡并不能互相通信。可是依据理论来讲,他们是可以互相通信的。这里我们通过抓包来分析一下原因,首先从veth0长pingveth1,然后分别抓veth0和veth1这两个虚拟网卡的包:
- veth0
[root@d1 ~]# tcpdump -nnt -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
- veth1
[root@d1 ~]# tcpdump -nnt -i veth1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytes
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
ARP, Request who-has 12.1.1.2 tell 12.1.1.1, length 28
通过以上抓包分析:veth0和veth1处于同一网段12.1.1.0/24,由于是第一次通信会通过ARP来确定MAC。可是在两个网卡的抓包情况来看,只有veth0发出的Request包并没有veth1回应的Raply包。有一定传统网络Trouble Shooting功底的您,看到这种现象肯定会想这肯定是防火墙策略阻止了吧😷您的猜测完全正确,经过查阅相关文档得知:大部分发行版Linux在默认情况下,内核中关于ARP是有一定限制的。所以为了使这一对虚拟网卡在根NS能直接互通,必须要修改默认的策略:
# 修改IP路由默认策略及默认ARP策略
[root@d1 ~]# echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
[root@d1 ~]# echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
# 接下来再测试连通性
[root@d1 ~]# ping 12.1.1.2 -c 3 -I veth0
PING 12.1.1.2 (12.1.1.2) from 12.1.1.1 veth0: 56(84) bytes of data.
64 bytes from 12.1.1.2: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 12.1.1.2: icmp_seq=2 ttl=64 time=0.051 ms
64 bytes from 12.1.1.2: icmp_seq=3 ttl=64 time=0.045 ms
--- 12.1.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2034ms
rtt min/avg/max/mdev = 0.037/0.044/0.051/0.005 ms
注:至于为什么修改上述策略才能通信,过两天还是单独写一篇文章来解释吧。
1.4.3 在NS中的连通性
接下来我们将veth1关联到1.3章节中创建的NS,然后看看和veth0通信的过程。
[root@d1 ~]# ip link set veth1 netns forgeek
[root@d1 ~]# ip netns exec forgeek ifconfig veth1 12.1.1.2/24
[root@d1 ~]# ip netns exec forgeek ip link set dev veth1 up
[root@d1 ~]# ping 12.1.1.2 -c 3 -I veth0
PING 12.1.1.2 (12.1.1.2) from 12.1.1.1 veth0: 56(84) bytes of data.
64 bytes from 12.1.1.2: icmp_seq=1 ttl=64 time=0.115 ms
64 bytes from 12.1.1.2: icmp_seq=2 ttl=64 time=0.066 ms
64 bytes from 12.1.1.2: icmp_seq=3 ttl=64 time=0.072 ms
--- 12.1.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.066/0.084/0.115/0.023 ms
1.4.4 NS之间的连通性
之前我们说veth-pair主要是用来解决不同NS之间通信的,那么接下来我们来创建两个NS:ns1,ns2。然后将veth0
加入到ns1中,veth1加入到ns2中,分别给veth0和veth1配置IP地址如下图所示:
+------------------------------------------------------------------+
| |
| +-----------------+ +-----------------+ |
| | NS1 | | NS2 | |
| | +--+ Veth pair +--+ | |
| | | +--------------------------+ | | |
| | +--+veth0 veth1+--+ | |
| | Name Space |12.1.1.1 12.1.1.2| Name Space | |
| +-----------------+ +-----------------+ |
| |
| Linux Server |
| By:[F0rGeEk] |
+------------------------------------------------------------------|
操作过程如下:
[root@d1 ~]# ip netns add ns1
[root@d1 ~]# ip netns add ns2
[root@d1 ~]# ip link set veth0 netns ns1
[root@d1 ~]# ip link set veth1 netns ns2
# 验证网卡是否加入对应的NS中
[root@d1 ~]# ip netns exec ns1 ip link ls
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: veth0@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 02:77:ea:e8:3a:30 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@d1 ~]# ip netns exec ns2 ip link ls
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
7: veth1@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ce:47:33:1f:90:fe brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 激活相应的网卡
[root@d1 ~]# ip netns exec ns1 ip link set dev veth0 up
[root@d1 ~]# ip netns exec ns2 ip link set dev veth1 up
# 为网卡配置IP地址
[root@d1 ~]# ip netns exec ns1 ifconfig veth0 12.1.1.1/24
[root@d1 ~]# ip netns exec ns2 ifconfig veth1 12.1.1.2/24
# 测试连通性
[root@d1 ~]# ip netns exec ns1 ping 12.1.1.2 -c 3 -I veth0
PING 12.1.1.2 (12.1.1.2) from 12.1.1.1 veth0: 56(84) bytes of data.
64 bytes from 12.1.1.2: icmp_seq=1 ttl=64 time=0.051 ms
64 bytes from 12.1.1.2: icmp_seq=2 ttl=64 time=0.057 ms
64 bytes from 12.1.1.2: icmp_seq=3 ttl=64 time=0.052 ms
--- 12.1.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.051/0.053/0.057/0.006 ms
1.5 Linux bridge
和veth-pari一样,Linux bridge也是一种虚拟网络设备。这里可以将bridge看作是一个普通的二层交换机,因为它具备二层交换机的所有功能。对于普通的物理设备来说一般只有两端,从一端进来的数据会从另一端出去,比如物理网卡从外面网络中收到的数据会转发到内核协议栈中,而从协议栈过来的数据会转发到外面的物理网络中。而bridge有多个端口,数据可以从多个端口进,也可以从多个端口出去。Bridge的这个特性使得它主要被用于和其他网络设备接入使用,比如虚拟网络设备、物理网卡等。
bridge是建立在从设备上(物理设备、虚拟设备、vlan设备等,即attach一个从设备,类似于现实世界中的交换机和一个用户终端之间连接了一根网线),并且可以为bridge配置一个IP(参考LinuxBridge MAC地址行为),这样该主机就可以通过这个bridge设备与网络中的其他主机进行通信了。另外它的从设备被虚拟化为端口port,它们的IP及MAC都不在可用,且它们被设置为接受任何包,最终由bridge设备来决定数据包的去向:接收到本机、转发、丢弃、广播。
1.5.1 实现原理
Bridge的功能主要在内核里实现。当一个从设备被 attach 到 Bridge 上时,相当于现实世界里交换机的端口被插入了一根连有终端设备的网线。这时在内核程序里,一个用于接受数据的回调函数(netdev_rx_handler_register())被注册。以后每当这个从设备收到数据时都会调用这个函数用来把数据转发到Bridge上。当Bridge接收到此数据时,br_handle_frame()被调用,进行一个和现实世界中的交换机类似的处理过程:判断包的类别(广播/单点),查找内部MAC端口映射表,定位目标端口号,将数据转发到目标端口或丢弃,自动更新内部 MAC 端口映射表以自我学习。
Bridge和一般的二层交换机有一个区别:数据被直接发到 Bridge上,而不是从一个端口接收。这种情况可以看做 Bridge自己有一个MAC可以主动发送报文,或者说Bridge自带了一个隐藏端口和宿主Linux系统自动连接,Linux上的程序可以直接从这个端口向Bridge上的其他端口发数据。所以当一个Bridge拥有一个网络设备时,如 bridge0 加入了 eth0 时,实际上bridge0拥有两个有效MAC地址,一个是bridge0的,一个是eth0的,他们之间可以通讯。这里还有一个有意思的事情是,Bridge可以设置IP地址。通常来说IP地址是三层协议的内容,不应该出现在二层设备Bridge上。但是Linux里Bridge是通用网络设备抽象的一种,只要是网络设备就能够设定IP地址。当一个bridge0拥有IP后,Linux便可以通过路由表或者IP表规则在三层定位bridge0,此时相当于Linux拥有了另外一个隐藏的虚拟网卡和Bridge的隐藏端口相连,这个网卡就是名为bridge0的通用网络设备,IP可以看成是这个网卡的。当有符合此IP的数据到达bridge0时,内核协议栈认为收到了一包目标为本机的数据,此时应用程序可以通过Socket接收到它。一个更好的对比例子是现实世界中的带路由的交换机设备,它也拥有一个隐藏的MAC地址,供设备中的三层协议处理程序和管理程序使用。设备里的三层协议处理程序,对应名为bridge0的通用网络设备的三层协议处理程序,即宿主Linux系统内核协议栈程序。设备里的管理程序,对应bridge0所在宿主Linux 系统里的应用程序。
Bridge的实现在当前有一个限制:当一个设备被attach到Bridge上时,那个设备的IP会变的无效,Linux不再使用那个IP在三层接收数据。举例如下:如果 veth0 本来的IP是 12.1.1.2,此时如果收到一个目标地址是12.1.1.2 的数据,Linux的应用程序能通过Socket操作接收到它。而当veth0被attach到一个bridge0后,尽管veth0的IP还在,但应用程序是无法接收到上述数据的。此时若想收到该数据则应该把IP 12.1.1.2 赋bridge0。
1.5.2 创建bridge
如下图所示,我们创建一对veth-pari:veth0、veth1;然后创建一个Bridge:br0,其中veth0配置IP地址为12.1.1.1/24,veth1配置IP地址为12.1.1.2/24。然后我们将veth0加入到br0中,此时我们在veth1上ping12.1.1.1测试网络是否连通。为验证1.5.1中介绍原理,我们将veth0的IP地址移至br0,此时再通过veth1去ping12.1.1.1测试网络是否连通。实验过程如下:
+----------------------------------------------------------+
| By:[f0rGeEk] |
| +--------------------------------------------------+ |
| | | |
| | Network Protocal Stack | |
| | | |
| +---+--------------+--------------+------------+---+ |
| ^ ^ | ^ |
| | | | | |
+----------------------------------------------------------+
| | | | | |
| | | | | |
| v v v v |
| +--+---+ +----+---+ +--+---+ +--+---+ |
| | | | | | | | | |
| | eth0 | | br0 |<----->+ veth0| | veth1| |
| | | |12.1.1.1/24 | | |12.1.1.2/24
| +---+--+ +--------+ +--+---+ +---+--+ |
| ^ ^ ^ |
| | | | |
| | +-------------+ |
| | |
+----------------------------------------------------------+
|
v
Physical Network
- 创建veth-pair、bridge
[root@d1 ~]# ip link add veth0 type veth peer name veth1
[root@d1 ~]# ip link set dev veth0 up
[root@d1 ~]# ip link set dev veth1 up
[root@d1 ~]# ip addr add 12.1.1.1/24 dev veth0
[root@d1 ~]# ip addr add 12.1.1.2/24 dev veth1
# 创建并激活一个bridge
[root@d1 ~]# ip link add name br0 type bridge
[root@d1 ~]# ip link set br0 up
[root@d1 ~]# ip link list br0
9: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether a2:47:b8:b7:21:9d brd ff:ff:ff:ff:ff:ff
# 将veth0加入bridge中
[root@d1 ~]# ip link set dev veth0 master br0
[root@d1 ~]# ip link list br0
9: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 22:d0:1d:fd:5d:9b brd ff:ff:ff:ff:ff:ff
# 查看桥接信息
[root@d1 ~]# bridge link
8: veth0 state UP @veth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
# 首先修改各虚拟网络设备的access_local和rp_filter
[root@d1 ~]# echo 1 > /proc/sys/net/ipv4/conf/br0/accept_local
[root@d1 ~]# echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/br0/rp_filter
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
[root@d1 ~]# echo 0 > /proc/sys/net/ipv4/conf/default/rp_filter
仔细观察上述过程,我们发现一个有趣的现象,当veth0加入bridge br0后,br0的MAC地址则变成了veth0的MAC地址。下面我们在veth1上ping12.1.1.1测试连通性:
- 测试
[root@d1 ~]# ping -c 3 -I veth1 12.1.1.1
ping: Warning: source address might be selected on device other than veth1.
PING 12.1.1.1 (12.1.1.1) from 10.10.10.137 veth1: 56(84) bytes of data.
--- 12.1.1.1 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2009ms
- 为bridge配置IP地址
[root@d1 ~]# ip addr del 12.1.1.1/24 dev veth0
[root@d1 ~]# ip addr add 12.1.1.1/24 dev br0
- 测试
[root@d1 ~]# ping -c 2 -I veth1 12.1.1.1
PING 12.1.1.1 (12.1.1.1) from 12.1.1.2 veth1: 56(84) bytes of data.
64 bytes from 12.1.1.1: icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from 12.1.1.1: icmp_seq=2 ttl=64 time=0.072 ms
1.5.3 连接两个NS
如下图所示,我们创建两个NS:ns1、ns2,同时创建两对veth-pari:veth0>br-veth0;veth>br-veth1。创建一个bridge:br0,并将veth0和veth1加入至br0然后为br-veth0和br-veth1分别配置IP地址。最后在br-veth0接口上ping12.1.1.2测试网络是否连通。
+-----------------------------------------------------------------------------+
| By:[F0rGeEk] |
| Linux Bridge connetc NS |
| +--------------------+ +-------------------+ |
| | NameSpace NS1| | NameSpace NS2| |
| | | | | |
| | br-veth1 | | br-veth0 | |
| | +---+ | | +---+ | |
| | | | | | | | | |
| +-------+---+--------+ +--------+---+------+ |
| |12.1.1.2/24 12.1.1.1/24| |
| | | |
| | +---------------+ | |
| | veth-pari | | veth-pari | |
| | +--+ +--+ | |
| +------------------+ | | +-------------------+ |
| veth1+--+ +--+ veth0 |
| | Bridge 0 | |
| +---------------+ |
+-----------------------------------------------------------------------------+
- 创建ns1、ns2、br0 两对veth-pair
[root@d1 ~]# ip netns add ns1
[root@d1 ~]# ip netns add ns2
[root@d1 ~]# ip link add veth0 type veth peer name br-veth0
[root@d1 ~]# ip link add veth1 type veth peer name br-veth1
[root@d1 ~]# ip link add name br0 type bridge
[root@d1 ~]# ip link set dev veth0 up
[root@d1 ~]# ip link set dev veth1 up
[root@d1 ~]# ip link set dev br-veth0 up
[root@d1 ~]# ip link set dev br-veth1 up
[root@d1 ~]# ip link set dev br0 up
- 将veth-pair分别加入NS和bridge中,并激活NS中的所有接口
[root@d1 ~]# ip link set br-veth0 netns ns2
[root@d1 ~]# ip link set br-veth1 netns ns1
[root@d1 ~]# ip link set dev veth0 master br0
[root@d1 ~]# ip link set dev veth1 master br0
# 激活NS中的接口
[root@d1 ~]# ip netns exec ns1 ifconfig br-veth1 up
[root@d1 ~]# ip netns exec ns2 ifconfig br-veth0 up
- 配置IP地址
[root@d1 ~]# ip netns exec ns1 ifconfig br-veth1 12.1.1.1/24
[root@d1 ~]# ip netns exec ns2 ifconfig br-veth0 12.1.1.2/24
- 检查上述配置
# 查看NS中网卡IP配置
[root@d1 ~]# ip netns exec ns1 ip addr show br-veth1
5: br-veth1@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 1a:36:ef:1e:8b:98 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 12.1.1.1/24 brd 12.1.1.255 scope global br-veth1
valid_lft forever preferred_lft forever
inet6 fe80::1836:efff:fe1e:8b98/64 scope link
valid_lft forever preferred_lft forever
[root@d1 ~]# ip netns exec ns2 ip addr show br-veth0
3: br-veth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d2:45:60:46:ab:77 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 12.1.1.2/24 brd 12.1.1.255 scope global br-veth0
valid_lft forever preferred_lft forever
inet6 fe80::d045:60ff:fe46:ab77/64 scope link
valid_lft forever preferred_lft forever
# 检查bridge配置
[root@d1 ~]# bridge link
4: veth0 state UP @(null): <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
6: veth1 state UP @(null): <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
- 测试两个NS之间的连通性
# ipv4连通测试
[root@d1 ~]# ip netns exec ns2 ping 12.1.1.1 -c3 -I br-veth0
PING 12.1.1.1 (12.1.1.1) from 12.1.1.2 br-veth0: 56(84) bytes of data.
64 bytes from 12.1.1.1: icmp_seq=1 ttl=64 time=0.058 ms
64 bytes from 12.1.1.1: icmp_seq=2 ttl=64 time=0.062 ms
64 bytes from 12.1.1.1: icmp_seq=3 ttl=64 time=0.064 ms
--- 12.1.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.058/0.061/0.064/0.006 ms
# ipv6连通测试
[root@d1 ~]# ip netns exec ns2 ping6 fe80::1836:efff:fe1e:8b98 -c 3 -I br-veth0
PING fe80::1836:efff:fe1e:8b98(fe80::1836:efff:fe1e:8b98) from fe80::d045:60ff:fe46:ab77%br-veth0 br-veth0: 56 data bytes
64 bytes from fe80::1836:efff:fe1e:8b98%br-veth0: icmp_seq=1 ttl=64 time=0.057 ms
64 bytes from fe80::1836:efff:fe1e:8b98%br-veth0: icmp_seq=2 ttl=64 time=0.067 ms
64 bytes from fe80::1836:efff:fe1e:8b98%br-veth0: icmp_seq=3 ttl=64 time=0.069 ms
--- fe80::1836:efff:fe1e:8b98 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.057/0.064/0.069/0.008 ms
1.6 tun/tap
虚拟网络设备也归内核的网络设备管理子系统管理。对于Linux内核网络设备管理模块来说,虚拟设备和物理设备没有区别,都是网络设备,都能配置IP,从网络设备来的数据,都会转发给协议栈,协议栈过来的数据,也会交由这些网络设备发送出去,至于是如何发送、发送到哪,这都由设备驱动来完成,跟Linux内核就没关系了。
1.6.1 tun/tap概述
从Linux文件系统来看,它们是用户可以用文件来操作的字符设备;但是从网络虚拟化的角度来看,它们是虚拟网卡,一端是APP一端是网络协议栈。与普通的网络接受发数据不同,tun/tap设备比较特殊,它是通过文件来收发数据包。如下图所示,tunX 和上面的 eth0 在逻辑上面是等价的, tunX 也代表了一个网络接口,虽然这个接口是系统通过软件所模拟出来的。网卡接口 tunX 所代表的虚拟网卡通过文件 /dev/tunX 与我们的应用程序(App) 相连,应用程序每次使用 write 之类的系统调用将数据写入该文件,这些数据会以网络层数据包的形式,通过该虚拟网卡,经由网络接口 tunX 传递给网络协议栈,同时该应用程序也可以通过 read 之类的系统调用,经由文件 /dev/tunX 读取到协议栈向 tunX 传递的所有数据包。其实这里的tunX和其他普通网卡基本一样,唯独的区别是这个虚拟网卡没有MAC地址,由于tunX仅能虚拟到网络层,所以要MAC地址也没用。但如果是tapX网卡则不同,因为它比runX更深入一层。对于协议栈来看tapX和物理网卡是没有区别的。
+-------------------------------------------------------------------------------+
| |
| +--------------+ +---------------+ |
| | APP | | Socket API | |
| | | | | |
| +------+-------+ +------+--------+ |
| | | |
| | | |
| USER +------+--------+ | |
+------------+ /dev/tunX +--------------------------------------------------+
|LINUX KERNEL| | | |
| +-------+-------+ +--------------+-----------+ |
| | | | |
| | | Network Protocal Stack | |
| | | | |
| | +--------------+-----------+ |
| | | |
| | | |
| | | |
| | | |
| | +--------------+ | |
| | | | | |
| +---------+ tunX +------------------+ |
| | | |
| +--------------+ By:[F0rGeEk] |
| |
++-------------------------------------------------------------------------------+
1.6.2 典型使用场景
较为常见的tun/tap使用场景有数据加密、数据压缩等,这里我们主要讲解最常用的VPN。它是利用tun设备做UDP的VPN,如下图所示。在用户层有两个APP1和APP2,Linux内核层有socket、网络协议站、网络设备。其中socket实质上是网络协议栈的一部分。这里我们将eth0的IP设定为10.8.8.11,eth0网络的网关为10.8.8.254;tun0的IP设定为12.1.1.11。我们这里假设VPN用户是eth0网络10.8.8.0/24中的某一台主机,这台主机本地有12.1.1.0/24网络,我们的目的是通过APP 1能与VPN主机本地网络中的成员进行通讯。
+--------------------------------------------------------------------------+
| +---------------------+ +-----------------------+ |
| | | | | |
| | AAP 1 | | APP 2 <-------+ |
| | | | | | |
| +---------+-----------+ +-----------+-----------+ | |
| | | | |
| | | | |
+--------------------------------------------------------------------------+
| | | | |
| | | | |
| v v | |
| +------+------+ +------+------+ | |
| | | | | | |
| | Socket 1 | | Socket 2 | | |
| | | | | | |
| +--+-------------+---------------------+-------------+-----+ | |
| | | | |
| | Network Protocal Stack | | |
| | | | |
| +---------+-----------------------------------+------------+ | |
| | | | |
| | | | |
| | | | |
| +-------v------+ +------v-------+ | |
| | | | | | |
| | eth0 | | tun0 | | |
| | | | | | |
| +-------+------+ +------+-------+ | |
| | 10.8.8.11/24 | 12.1.1.11/24 | |
| | +-------------------+ |
| | |
| | By:[F0rGeEk] |
+--------------------------------------------------------------------------+
v
Physical Network
这里假设10.8.8.33要与12.1.1.33通过VPN互访,下面我们来看看数据包的流程:
- 首选APP 1通过socket 1发送了一个目的地为12.1.1.33的数据包,socket将该数据包转发给网络协议栈;
- 协议栈收到该数据包后,根据本地路由规则进行匹配,将该数据包扔给tun0处理;
- tun0收到数据包后,由于另一端连着APP 2,所以它会直接将数据包转发至APP 2;
- APP 2收到数据包后,根据需要进行重构,重构时会将原有的数据包原封不动的包在新数据包中,然后再有APP 2发送出去。新数据包的源地址会变成eth0的地址10.8.8.11,而目的地址将会变成10.8.8.33;
- Socket收到由APP 2发出的数据包后,会直接转发给协议栈;
- 协议栈收到数据包后,匹配本地路由规则,将数据包转发给eth0;
- eth0收到数据包后,会直接通过物理网络将数据包发送出去;
- 当10.8.8.33收到数据包后,首先是打开数据包读取里面的原始数据,并将该数据包转发给12.1.1.33;如果12.1.1.33收到数据包并且回复的话,那么当收到12.1.1.33回复的数据包后进行数据包的重构,同样将原始数据封装在新的数据包中,再由原路返回;
- 这样最终APP 1即通过VPN完成了与12.1.1.33的通信。
1.6.3 tun与tap的区别
通过1.6.2小节的通信流程来看,tun/tap设备的用处是将协议栈中的部分数据包转发给用户空间的应用程序,再由用户空间的程序来处理这个数据包。tun/tap设备不仅能做基于DUP的VPN,类似的tunnel以及IPSec都是比较常用的场景。虽然它们的工作方式完全相同,但还是有一些区别:
- 户层程序通过tun设备只能读写IP数据包,而通过tap设备能读写链路层数据包;
- tun设备相当于是一个三层设备,,它无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。可以使用ifconfig之类的命令给该设备设定 IP 地址;
- tap设备则相当于是一个二层设备,可以工作在数据链路层,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。可以通过ifconfig之类的命令给该设备设定 IP 地址,甚至还可以给它设定 MAC 地址。
1.7 iptables
有人说在Linux中iptables就是防火墙,其实它并不是真正的防火墙。一般情况我们可以通过类似"service iptables start"命令启动iptables,但iptables并没有守护进程,所以它还不能算真正意义上的服务。如果非要给iptables给一个定义,那么称它为Linux内核提供的功能一点不为过。而Linux中真正的防火墙是netfilter,它位于Linux内核空间。netfilter/iptables与大多数的Linux软件一样,这个包过滤防火墙也是免费的,它可以完成防火墙的基本功能。比如包过滤、包的重定向、NAT等。
1.7.1 iptables基础
实际上iptables是执行我们设定的rules,而这些预设的rules一般都是由相关管理员来设置。这些rules都存储在内核空间的信息包过滤表中,这些rules不仅需要指定源地址、目的地址、传输协议、源服务类型、目标协议,还需要指定如果数据包匹配到rules后如何操作,一般有accept、drop和reject。说到这里其实有关iptables的操作和传统网络防火墙比较类似,日常的维护无外乎就是增删改查这些rules。
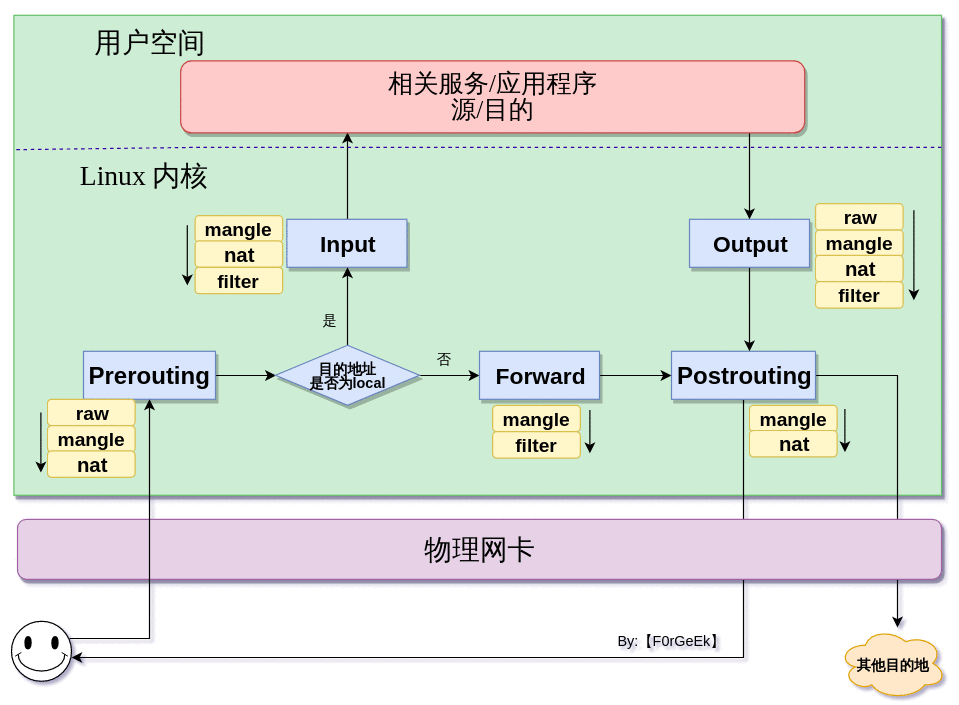
如下图所示,当我们启用了防火墙功能后,数据包在进入我们的主机时会经过如下各种"关卡"。如果客户端发来的请求报文目的地是本机,那么由Prerouting、Postrouting、Input和Output"关卡"来负责数据包的放行与转发。那么如果客户端发来的请求报文目的地不是本机,这时会由Prerouting、Forward、Postrouting"关卡"来负责数据包的放行与转发。在Linux的iptables中我们提到的这些"关卡"被称作Chains(也就是常说的链)。
这五个链中,Prerouting链主要处理刚到达本机并在路由转发前的数据包,通常用于DNAT;Input链主要处理来自外部的数据;Output链主要处理向外发送的数据;Forward链主要处理数据转发;Postrouting链主要处理即将离开本机的数据包,通常用于SNAT。
1.7.2 iptables的结构
iptables的结构:iptables -> Tables -> Chains -> Rules。也就是说tables由chains组成而chains又由rules组成,他们之间是互相包含的关系。如下图所示:
+-----------------------------------------------------------------------------------+
| IPTABLES |
| |
| +------------------------------+ +------------------------------+ |
| | Table 1 | | Table N | |
| | | | | |
| | +-------------------------+ | | +-------------------------+ | |
| | | Chain 1 | | | | Chain 1 | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | Rule 1 | | | | | | Rule 1 | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | | | | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | Rule 2 | | | | | | Rule 2 | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | +-------------------------+ | ......... | +-------------------------+ | |
| | | | ......... | |
| | +-------------------------+ | | +-------------------------+ | |
| | | Chain 2 | | | | Chain N | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | Rule 1 | | | | | | Rule 1 | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | | | | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | | | Rule 2 | | | | | | Rule 2 | | | |
| | | +-------------------+ | | | | +-------------------+ | | |
| | +-------------------------+ | | +-------------------------+ | |
| +------------------------------+ +------------------------------+ |
| By:[F0rGeEk] |
+-----------------------------------------------------------------------------------+
-
Rules
所谓的规则主要是相关管理员定义的准入条件,这个规则的主旨是:如果数据包符合xx条件,那么就将这个数据包yy。一般rules需要制定源地址、目的地之、传输协议、服务类型或端口等,而数据包匹配规则后的操作则有accept、reject或drop。这里的rules就好比物理防火墙中的一条条安全策略,只不过在物理防火墙中数据被匹配后的动作是permit、deny和drop其实意义都一样。 -
Chains
上文中我们说将这些决定数据包流向的"关卡"称为"链",为什么要称为链呢?一般情况下,防火墙的作用就是对经过的数据报文进行规则匹配,然后执行相应的动作。所以当一个数据包要经过防火墙时,那么它就要进行规则的匹配,而现实情况是一个关卡可能会有很多的规则,这些规则又是串联在一起的,由于形似所以就被称为链。这里我们也可以把它可以理解为物理防火墙中的策略组,一般情况下一个策略组中我们也会做很多类似的"规则"。 -
Tables
Iptables中的表也比较好理解,试想我们对于每条链上都有很多的rule,但这些rule可能会有一些相似的。比如均是开启80端口或者都是拒绝SSH等,那么如果每个链都需要这样的策略,如果有很多个链需要修改的话那管理员的烦恼就来了。所以这里引入表,所谓的表就是可以将相同功能的rule放在一起的合集。看到这里网工又开心了,这部就是物理防火墙中的策略表嘛😅😅😅当然可以这样理解,物理防火墙根据性能不同可以创建N多个策略表,但是Iptables为我们内建了4种表(fiter、nat、mangle、raw),而我们定义的每条rule也都离不开这四种表。
1.7.3 表链关系
现在我们已经知道iptables有四个内建表:Filter表、NAT表、Mangle表和Raw表,它还有五个链:PREROUTING链、INPUT链、OUTPUT链、FORWARD链、POSTROUTING链。下面我们就简单来说说这"四表五链"之间的关系。
-
Filter表
Filter表为iptables的默认表,也就是说如果你没有自定义表,那么默认就使用Filter表,它主要负责报文过滤。内核模块为iptables_filter,它具有3个内建链:INPUT链、OUTPUT链 、FORWARD链 。 -
NAT表
众所周知NAT为Network Address Translation的缩写,主要提供网络地址转换功能。其内核模块为iptables_nat,它具有3个内建链:PREROUTING链、POSTROUTING链 、OUTPUT链。 -
Mangle表
Mangle表主要用于指定如何处理数据包,拆解并作出修改,然后重新封装的功能。其内核模块为iptables_mangle,它具有5个内建链:PREROUTING链、OUTPUT链、FORWARD链、INPUT链和POSTROUTING链。 -
Raw表
Raw表主要用于处理异常,可以关闭NAT表上启用的连接追踪机制。它的内核模块为iptables_raw,它具有2个内建链:PREROUTING链和OUTPUT链。
这时我们在看数据报文经过防火墙的流程就更清晰了:
1.7.4 iptables Rules
上文我们说过,所谓的规则就是制定匹配条件然匹配每个经过的数据报文,一旦匹配成功则进行预设的动作,如果匹配为成功则判断下一条rule。所以对于任何一个rule来说,它的结构则是由匹配条件和执行动作来组成。
-
匹配条件
匹配条件一般包含源地址(SOURCE IP)和目的地址(DESTINATION IP),以及扩展条件。这些扩展条件实际上是netfiler中的一部分,比如源端口、目的端口、协议等。 -
执行动作
执行动作在iptables中被称为target,一般的执行动作有ACCEPT(允许数据包通过)、REJECT(拒绝数据包通过,必要是回复客户端拒绝响应信息)、DROP(拒绝数据包通过并直接丢弃不回复任何响应信息)。在实际应用中我们还经常会使用一些扩展动作:SNAT(源地址转换,比如局域网用户使用同一个公网IP上网)、DNAT(目的地址转换,可用来保护内网重要信息)、REDIRECT(在本地进行端口映射)、MASQUERADE(SNAT的一种特殊形式,适用于动态IP)以及LOG(仅对数据包进行记录不做任何操作)。
1.7.5 iptables基础操作
- 查询防火墙可用规则
# 以下输出说明当前系统没有启用防火墙,仅有默认的filter表以及默认的链。
[root@d1 ~]# iptables --list
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
- 查询某个表
# 用法iptables -t 表名 --list
# 如下查询nat表
[root@d1 ~]# iptables -t nat --list
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
- 清空所有rules
[root@d1 ~]# iptables --flush
# 或者
[root@d1 ~]# iptables -F
# 执行完以上两条命令。并不意味着所有规则都清空了
# 因为在有的Linux版本中,通过以上命令不会清空NAT表,所以最好手动清空NAT:
[root@d1 ~]# iptables -t NAT -F
- 保存修改
[root@d1 ~]# iptables-save
# Generated by iptables-save v1.8.4 on Fri Mar 27 15:26:45 2020
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
COMMIT
# Completed on Fri Mar 27 15:26:45 2020
# Generated by iptables-save v1.8.4 on Fri Mar 27 15:26:45 2020
*nat
:PREROUTING ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
COMMIT
# Completed on Fri Mar 27 15:26:45 2020
- 追加规则
首先我们来了解一下iptables的常用参数:
| 参数 | 描述 | 参数 | 描述 |
|---|---|---|---|
| -p | 指定协议 | -A | 追加到链 |
| -s | 指定源地址 | -C | 检查存在的rule |
| -d | 指定目的地址 | -D | 从指定链中删除rule |
| -j | 指定执行target | -I | 通过指定rulenum插入rule |
| -i | 指定入接口 | -R | 替换指定rulenum的rule |
| -o | 指定出接口 | -F | 清空所有rules |
| -t | 指定要操作的表 | -N | 创建一个自定义链 |
| -g | 跳转到指定的链 | -P | 修改指定链中的策略 |
| -m | 匹配扩展模块 | -X | 删除用户自定义的链 |
| 还有一些扩展参数: |
| 参数 | 描述 |
|---|---|
| --sport | 源端口,默认匹配所有端口 |
| --dport | 目的端口,与--sport类似 |
| --tcp-flags | TCP标志,一般有SYN、ACK、FIN、RST、URG、PSH |
| --icmp-type | ICMP类型,一般0表示echo reply,1表示echo |
| --timestart | 根据起始时间匹配数据 |
| --timestop | 和timestart配合使用,用来指定一个时间段 |
| --connlimit-above | 限制每个IP地址链接到server的链接数 |
比如我们将一台Linux做成SSH跳板机,这时我们可以使用iptables来做一些限制:
# 发出的数据包目的端口为22
[root@d1 ~]# iptables -A OUTPUT -o eth0 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
# 接收的数据包源端口为22
[root@d1 ~]# iptables -A INPUT -i eth0 -p tcp--sport 22 -m state --state ESTABLISHED -j ACCEPT
1.7.6 常用命令总结
- 将12.1.1.1访问10.1.1.1的所有包都拒绝
[root@d1 ~]# iptables -t filter -I INPUT -s 12.1.1.1 -d 10.1.1.1 -j DROP
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * * 12.1.1.1 10.1.1.1
- 所有访问12.1.1.1的包均拒绝
[root@d1 ~]# iptables -t filter -I INPUT -d 12.1.1.1 -j DROP
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * * 0.0.0.0/0 12.1.1.1
- 允许12.1.1.1SSH10.1.1.1
[root@d1 ~]# iptables -t filter -I INPUT -s 12.1.1.1 -d 10.1.1.1 -p tcp --sport 22 -j ACCEPT
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 12.1.1.1 10.1.1.1 tcp spt:22
- 拒绝由某网卡流入的icmp
[root@d1 ~]# iptables -t filter -I INPUT -i ens33 -p icmp -j DROP
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP icmp -- ens33 * 0.0.0.0/0 0.0.0.0/0
- 允许任意源访问10.1.1.1的80、443端口
[root@d1 ~]# iptables -t filter -I INPUT -d 10.1.1.1 -p tcp -m multiport --dports 80,443 -j ACCEPT
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 10.1.1.1 multiport dports 80,443
- 将所有filter表以序号标记显示
[root@d1 ~]# iptables -nL -t filter --line-numbers
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT tcp -- 0.0.0.0/0 10.1.1.1 multiport dports 80,443
2 DROP icmp -- 0.0.0.0/0 0.0.0.0/0
3 ACCEPT tcp -- 12.1.1.1 10.1.1.1 tcp spt:22
4 DROP all -- 0.0.0.0/0 12.1.1.1
5 DROP all -- 12.1.1.1 10.1.1.1
6 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
7 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
8 INPUT_direct all -- 0.0.0.0/0 0.0.0.0/0
9 INPUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0
10 INPUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0
11 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID
12 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
- 删除已添加的rule
[root@d1 ~]# iptables -D INPUT 5
[root@d1 ~]# iptables -nL -t filter --line-numbers
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT tcp -- 0.0.0.0/0 10.1.1.1 multiport dports 80,443
2 DROP icmp -- 0.0.0.0/0 0.0.0.0/0
3 ACCEPT tcp -- 12.1.1.1 10.1.1.1 tcp spt:22
4 DROP all -- 0.0.0.0/0 12.1.1.1
5 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
6 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0
7 INPUT_direct all -- 0.0.0.0/0 0.0.0.0/0
8 INPUT_ZONES_SOURCE all -- 0.0.0.0/0 0.0.0.0/0
9 INPUT_ZONES all -- 0.0.0.0/0 0.0.0.0/0
10 DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID
11 REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
- 清除已有的rules
[root@d1 ~]# iptables -F
[root@d1 ~]# iptables -nvL INPUT
Chain INPUT (policy ACCEPT 19 packets, 1852 bytes)
pkts bytes target prot opt in out source destination
1.8 隧道技术VTI
VTI对于网工来说比较好理解,所以就拿它开刀好了。除VTI外,现在的Linux原生支持下列5种L3隧道:
- ipip:也称为ipv4 in ipv4,就是说在一个ipv4的报文基础上再封装一个ipv4报文;
- GRE:全称通用路由封装,在数通中这个技术非常常见。主要就是在任意的网络协议上封装其他任意一种网络协议,比如OSPF封装在EGP中可以跨区域;
- sit:sit和ipip类似,区别是sit是将ipv6报文封装在ipv4中,有点像ipv6toipv4技术;
- ISATAP:全称站内自动隧道寻址协议,主要是用于ipv6的隧道封装;
- VTI:全称虚拟隧道接口,对于网工来说应该很熟悉吧,这是Cisco提出的一种关于IPSec隧道技术;
以上这5中隧道协议,它们的底层实现都离不开1.6章节介绍过的tun设备。就目前市面上常用的VPN软硬件,其底层实现都离不开这5中隧道协议。下面我们以VTI为例来看看它是如何实现的,其实其他4中隧道协议也都大同小异。
1.8.1 技术概述
这里我们主要讲解Cisco的VTI,从本质上说它就是完全虚拟的网卡,但和OpenVPN不同的是它在内核中就完成了几乎所有的功能。这一点虽然增加了性能,但是灵活性却相对减少了。控制明文的特性应该被配置到VTI接口上,控制密文的特性应该被运用到物理接口上,当我们使用IPsec VTI技术,我们可以对明文和加密后流量分开运用NAT,ACL和QoS等特性。如果我们运用传统的cryptomap技术,运用这些加密特性和IPsec隧道就会变的非常麻烦。VTI接口一般分为两种:静态VTI(SVTI)和动态VTI(DVTI)
1.8.2 VTI的实现
对于VTI的实现不要觉得有多么的复杂,其实很简单就把它想象成在GRE引擎上使用IPSec协议来封装数据报文。也就是说虚拟网卡是GRE实现的,而对于虚拟网卡内部数据封装格式则使用的是IPSec。下面我们主要介绍SVTI的实现过程:
实验环境出了点问题,后续更新。。。。
1.9 VXLAN
1.9.1 VXLAN概述
VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网),是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展。VXLAN 本质上是一种隧道封装技术。它使用 TCP/IP 协议栈的惯用手法——封装/解封装技术,将二层的以太网帧(Ethernet frames)封装成四层的 UDP 数据报(datagrams),然后在三层的网络中传输,效果就像 L2 的以太网帧在一个广播域中传输一样,实际上是跨越了 L3 网络,但却感知不到三层网络的存在。VXLAN 是应网络虚拟化技术而生的。随着数据中心网络不断扩增,Cisco、VMware 和 Arista Networks 这些巨头发现,传统的 VLAN 隔离已经无法应对网络虚拟化技术所带来的成千上万的设备增长,于是便联合起草了这个协议,一直到 2014 年才定稿,由RFC 7348所定义。
1.9.2 VXLAN和VLAN区别
首先我们知道VLAN是二层网络设备或者虚拟化设备用来隔离广播域的一种技术,同时我们也知道VLAN本身被限制最多只能有4094个。在以前较为简单的IT基础架构中使用VLAN来隔离广播域显得绰绰有余,但是在现如今云计算基础架构中动则数百万的虚拟设备中,要隔离这些广播域如果使用VLAN就显得捉襟见肘了。所以这里迭代出VXLAN技术通过网络虚拟化来解决超大型广播域隔离的问题。
其次是资源的问题,传统网络使用VLAN来隔离广播域,为避免二层环路一般会使用STP来管理网络链路。那么在使用STP时我们知道,它是通过STP的根来负责转发,一般会根据优先级以及链路成本来选择一条最优的链路进行数据转发,其余链路均作为备份链路。虽然这样即避免了环路也增强了链路可用性,但这里有一点就是链路的使用率却没有提高,明明有多条链路可以使用实际上始终只能用其中一条。所以我们通过VXLAN来解决在大流量情况下实现链路负载和提升数据传输能力。还有一点是MAC地址表的限制,传统二层网络都需要交换机的MAC地址表进行转发。不同性能的交换机所能支持的MAC地址表条目书不同,那么一般数据中心用TOR交换机来连接物理服务器,如果一台服务器虚拟出上百台虚拟机时,TOR交换机的一个物理口就要对应上百个MAC地址,在交换机MAC地址表条目数量有限的情况下,这可能会造成网络接入的瓶颈。如果这里使用VXLAN就会解决这个问题,VXLAN使用VTEP封装二层帧并在三层网络中传输。所以一台物理机对应一个VTEP,而这个VTEP可以被这台物理机上的所有虚机使用。那么对于TOR交换机来说,一个物理口对应一台物理机对应一个VETP信息即可,这样就解决了因为虚拟化带来的交换机MAC地址表爆增的问题。
最后是关于网络灵活性,传统基于VLAN的网络环境是不存在overlay的,仅仅是underlay网络。物理网络与虚拟机属于同VLAN的数据可以互访,这就使得虚拟机所在的网络无法打破物理网络的界限。比如说在虚拟机的部署和迁移,传统网络仅支持在相同VLAN的网络中进行内部的操作,如果跨网段部署和迁移就显得非常麻烦。通过 VXLAN 的封装,在一个三层网络上构建了 二层 网络,或者说基于 underlay 网络的 overlay 网络,虚拟机的数据可以打破传统二层网络的限制,在三层网络上传输,虚拟机的部署和迁移也不受物理网络的限制,可以灵活部署和迁移,使得整个数据中心保持一个平均的利用率。
从以上几点来看,VXLAN 相比 VLAN 有很多的优势,不过至少现在还不能完全替代 VLAN,这需要根据使用场景具体分析。VXLAN 的优势更多体现大规模环境下,如果网络设备规模,不论是虚拟的还是物理的,只有百十台的样子,那么直接使用 VLAN 就足够了。另外一个 VXLAN 的封装解封装机制也会影响性能,所以需要综合考虑。
1.9.3 VXLAN网络模型
如下图所示,左右两边是 Layer2 广播域,中间跨越一个 L3 网络,VTEP 是 VXLAN 隧道端点(VxLAN Tunnel Point),当 Layer2 以太网帧到达 VTEP 的时候,通过 VxLAN 的封装,跨越 Layer3 层网络完成通信,由于 VXLAN 的封装"屏蔽"了 Layer3 网络的存在,所以整个过程就像在同一个 Layer2 广播域中传输一样。
+----------------------------------------------------------------------------------------------+
| +-----------+ +------------+ |
| +--------+ | | +--------------------+ | | +--------+ |
| | +-----+ +------+ VXLAN Tunnel +-------+ +-----+ | |
| | Host A | | VTEP A | +--------------------+ | VTEP B | | Host B | |
| +--------+ | | L3 IP Fabric | | +--------+ |
| +-----------+ +------------+ |
| |
| + + + + |
| | | | | |
| | Layer 2 | Layer 3 | Layer 2 | |
| +<------------------------>-<--------------------------------->-<------------------------->+ |
| | | | | |
| + + + + |
| By:[F0rGeEk] |
+----------------------------------------------------------------------------------------------+
传统网络中的交换机会根据本地的FDB地址表进行转发,FDB表存储的是MAC地址、vlan id和接口的对应关系。那么在VXLAN网络中,交换机则需要维护一张VTEP的信息表。这张表中主要内容是MAC地址、VNI、VTEP IP之间的对应关系。
-
VTEP(VXLAN Tunnel Endpoints,VXLAN隧道端点)
VXLAN网络的边缘设备,是VXLAN隧道的起点和终点,VXLAN报文的相关处理均在这上面进行。总之,它是VXLAN网络中绝对的主角。VTEP既可以是一***立的网络设备(比如华为的CE系列交换机),也可以是虚拟机所在的服务器。那它究竟是如何发挥作用的呢?答案稍候揭晓。 -
VNI(VXLAN Network Identifier,VXLAN 网络标识符)
上文提到,以太网数据帧中VLAN本身被限制最多只能有4094个,这使得VLAN的隔离能力在数据中心网络中力不从心。而VNI的出现,就是专门解决这个问题的。VNI是一种类似于VLAN ID的标识,一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信。VXLAN报文封装时,给VNI分配了足够的空间使其可以支持海量租户的隔离。详细的实现,我们将在后文中介绍。 -
VXLAN Tunnel
“隧道”是一个逻辑上的概念,它并不新鲜,比如大家熟悉的GRE。说白了就是将原始报文“变身”后再加以“包装”,好让它可以在承载网络(比如IP网络)上传输。从主机的角度看,就好像原始报文的起点和终点之间,有一条直通的链路一样。而这个看起来直通的链路,就是“隧道”。顾名思义,“VXLAN隧道”便是用来传输经过VXLAN封装的报文的,它是建立在两个VTEP之间的一条虚拟通道。
-
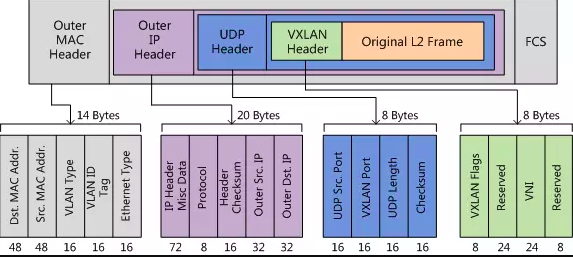
UDP Header
VXLAN头和原始以太帧一起作为UDP的数据。UDP头中,目的端口号(VXLAN Port)固定为4789,源端口号(UDP Src. Port)是原始以太帧通过哈希算法计算后的值。 -
Outer IP Header
封装外层IP头。其中,源IP地址(Outer Src. IP)为源VM所属VTEP的IP地址,目的IP地址(Outer Dst. IP)为目的VM所属VTEP的IP地址。 -
Outer MAC Header
封装外层以太头。其中,源MAC地址(Src. MAC Addr.)为源VM所属VTEP的MAC地址,目的MAC地址(Dst. MAC Addr.)为到达目的VTEP的路径上下一跳设备的MAC地址。
1.9.4 VXLAN实践
本次关于VXLAN的实践均是在Linux中进行,主要分为两个实验:1. 点对点VXLAN通信;2.容器环境中跨物理机通信
- 1. 点对点VXLAN
点对点VXLAN是最简单的一种实践方式,它有助于我们理解上文讲的那些干货。如下图所示,我们在两台server上各创建一个vxlan类型的接口,其中VXLAN1和VXLAN2为它们所在物理机的VTEP设备。我们制定VXLAN接口IP地址为10.1.1.0/24网段中,最终我们在VTEP设备之间构建一条VXLAN Tunnel,然后将10.1.1.0/24这个网络通过该隧道打通。
+------------------------------------------------------------------------+
| |
| SERVER A SERVER B |
| +-------------------+ +-------------------+ |
| | 10.1.1.1 | | 10.1.1.2 | |
| | +------+ | VXLAN Tunnel | +------+ | |
| | |VXLAN1| +---------------------------------+ |VXLAN2| | |
| | +---+--+ +---------------------------------+ +---+--+ | |
| | | | | | | |
| | | | | | | |
| | +----+----+ | | +----+----+ | |
| | | ens33 | | | | ens33 | | |
| +----+----+----+----+ +----+----+----+ ---+ |
| | 172.16.116.131/24 172.16.116.132/24 | |
| | | |
| +--------------------------------------------+ |
| |
| By:[F0rGeEk] |
+------------------------------------------------------------------------+
其实现还是非常简单的,具体操作过程如下:
# 设备OS版本信息
[root@d1 ~]# uname -r
3.10.0-957.el7.x86_64
[root@d1 ~]# cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
- SERVER A上的配置
[root@d1 ~]# ip link add vxlan1 type vxlan id 33 remote 172.16.116.132 dstport 4789 dev ens33
[root@d1 ~]# ip link set vxlan1 up
[root@d1 ~]# ip addr add 10.1.1.1/24 dev vxlan1
# 查看创建的vxlan1网络设备信息
[root@d1 ~]# ifconfig vxlan1
vxlan1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.1.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::58d9:3eff:fed9:659d prefixlen 64 scopeid 0x20<link>
ether 5a:d9:3e:d9:65:9d txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 544 (544.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 查看关于10.1.1.0/24网络路由情况
[root@d1 ~]# route -n | grep 10.1.1.0
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan1
- SERVER B上的配置
[root@d2 ~]# ip link add vxlan2 type vxlan id 33 remote 172.16.116.131 dstport 4789 dev ens33
[root@d2 ~]# ip link set vxlan2 up
[root@d2 ~]# ip addr add 10.1.1.2/24 dev vxlan2
# 查看创建的vxlan2网络设备信息
[root@d2 ~]# ifconfig vxlan2
vxlan2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.1.1.2 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::a8fd:5bff:fed4:7cb2 prefixlen 64 scopeid 0x20<link>
ether aa:fd:5b:d4:7c:b2 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 544 (544.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 查看关于10.1.1.0/24网络路由情况
[root@d2 ~]# route -n | grep 10.1.1.0
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 vxlan2
- 测试连通性
# 为方便测试这里将CentOS的防火墙关闭
[root@d1 ~]# systemctl stop firewalld
[root@d1 ~]# ping 10.1.1.2 -c 3
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.826 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.973 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=1.00 ms
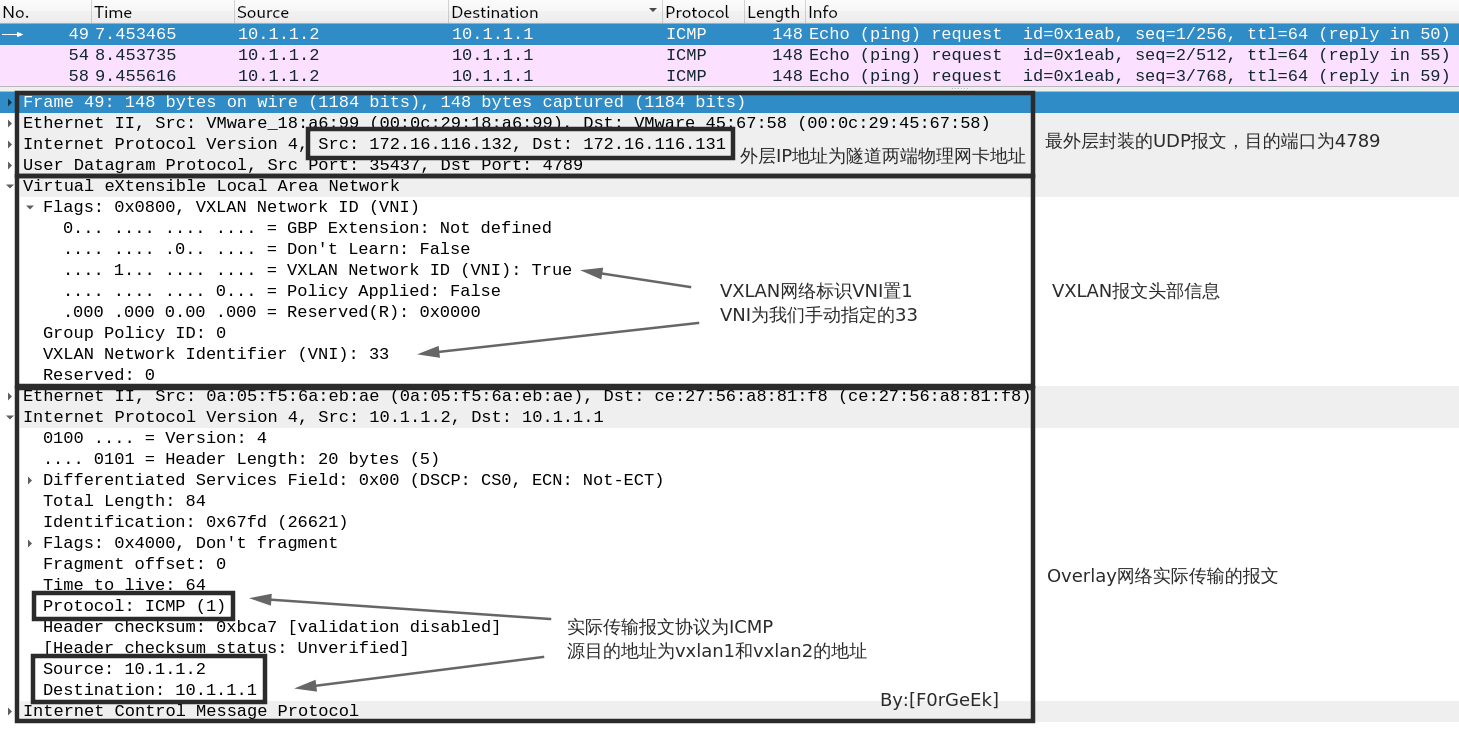
- 抓包分析
# 在SERVER A上针对物理接口进行抓包
[root@d1 ~]# tcpdump -i ens33 -w vxlan.pcap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
^C90 packets captured
92 packets received by filter
0 packets dropped by kernel
# 在SERVER B上ping10.1.1.1
[root@d2 ~]# ping 10.1.1.1 -c 3
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.991 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=1.30 ms
64 bytes from 10.1.1.1: icmp_seq=3 ttl=64 time=1.21 ms
- 2. 跨主机容器之间的VXLAN
实验环境是在两台SERVER上分别部署一个docker容器,两个容器均在同一个网段,最终实现不同宿主机上的同一网段的容器之间可以互访。熟悉K8S的朋友可能要说,这个在K8S里部署docker时默认就可以互通啊。是的没错,这里我们就是将底层是如何实现的来做个讲解。
+------------------------------------------------------------------------+
| |
| SERVER A SERVER B |
| +-------------------+ +-------------------+ |
| | | | | |
| | +---------+ | | +---------+ | |
| | | Docker A| | | | Docker B| | |
| | +---------+ | | +---------+ | |
| | 172.33.1.11 | | 172.33.1.12 | |
| | | | | | | |
| | +------+------+ | | +------+------+ | |
| | | Bridge1 | | | | Bridge2 | | |
| | +------+------+ | | +------+------+ | |
| | | | | | | |
| | +------+------+ | | +------+------+ | |
| | |VXLAN_DockerA| | | |VXLAN_DockerB| | |
| | +------+------+ | | +------+------+ | |
| | | | | | | |
| | +----+----+ | | +----+----+ | |
| | | ens33 | | | | ens33 | | |
| +----+---------+----+ +----+---------+----+ |
| 172.16.116.131/24 172.16.116.132/24 |
| | | |
| +--------------------------------------------+ |
| By:[F0rGeEk] |
+------------------------------------------------------------------------+
这里需要说明一点,当启动docker服务后,系统默认会创建一个docker0的网络。默认是172.17.0.0/16这个网段,启动容器时默认会从172.17.0.2开始自动分配给容器。按照实验环境的需求,我们这里需要指定容器的ip地址。docker默认的docker0是不允许被指定IP给容器的,只有在用户定义的网络上才支持用户指定容器的IP地址。所以这里我们需要创建一个自定义的网络。
- 自定义网络
[root@d1 ~]# docker network create bridge1 \
-o com.docker.network.bridge.name=bridge1 \
--subnet 172.33.1.0/24
# 验证是否成功创建网络
[root@d1 ~]# docker network list
NETWORK ID NAME DRIVER SCOPE
0b57d2a226b4 bridge bridge local
eab6c2991f09 bridge1 bridge local
a96c8a04be60 host host local
8f8172bcf173 none null local
[root@d1 ~]# ifconfig
bridge1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.33.1.1 netmask 255.255.255.0 broadcast 172.33.1.255
ether 02:42:aa:6d:ae:45 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- 创建并启动容器
# SERVER A
[root@d1 ~]# docker run -itd --net bridge1 --ip 172.33.1.11 busybox
# 验证容器是否成功创建
[root@d1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b3b055b49d4c busybox "sh" 5 seconds ago Up 3 seconds quizzical_mestorf
#检查新创建容器的IP地址
[root@d1 ~]# docker exec -it b3b055b49d4c sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:21:01:0B
inet addr:172.33.1.11 Bcast:172.33.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:16 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1312 (1.2 KiB) TX bytes:0 (0.0 B)
# SERVER B
[root@d2 ~]# docker run -itd --net bridge2 --ip 172.33.1.12 busybox
00bb21c402f00fabe576b88841116515475a1b54fd660debccefc1d00ec464d0
[root@d2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
00bb21c402f0 busybox "sh" 4 seconds ago Up 2 seconds elated_mirzakhani
#检查新创建容器的IP地址
[root@d2 ~]# docker exec -it 00bb21c402f0 sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:21:01:0C
inet addr:172.33.1.12 Bcast:172.33.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:16 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1312 (1.2 KiB) TX bytes:0 (0.0 B)
- 创建VXLAN接口并加入docker网桥
# SERVER A
[root@d1 ~]# ip link add VXLAN_DockerA type vxlan id 33 remote 172.16.116.132 dstport 4789 dev ens33
[root@d1 ~]# ip link set VXLAN_DockerA up
[root@d1 ~]# brctl addif bridge1 VXLAN_DockerA
# 查看VXLAN信息
[root@d1 ~]# ip -d link show VXLAN_DockerA
12: VXLAN_DockerA: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master bridge1 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 5a:6e:12:f7:02:9c brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 33 remote 172.16.116.132 dev ens33 srcport 0 0 dstport 4789 ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx
bridge_slave state forwarding priority 32 cost 100 hairpin off guard off root_block off fastleave off learning on flood on port_id 0x8002 port_no 0x2 designated_port 32770 designated_cost 0 designated_bridge 8000.2:42:aa:6d:ae:45 designated_root 8000.2:42:aa:6d:ae:45 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# SERVER B
[root@d2 ~]# ip link add VXLAN_DockerB type vxlan id 33 remote 172.16.116.131 dstport 4789 dev ens33
[root@d2 ~]# ip link set VXLAN_DockerB up
[root@d2 ~]# brctl addif bridge2 VXLAN_DockerB
# 查看VXLAN信息
[root@d2 ~]# ip -d link show VXLAN_DockerB
10: VXLAN_DockerB: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master bridge2 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fa:8b:b6:00:70:1e brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 33 remote 172.16.116.131 dev ens33 srcport 0 0 dstport 4789 ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx
bridge_slave state forwarding priority 32 cost 100 hairpin off guard off root_block off fastleave off learning on flood on port_id 0x8002 port_no 0x2 designated_port 32770 designated_cost 0 designated_bridge 8000.2:42:c2:0:9:dd designated_root 8000.2:42:c2:0:9:dd hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
- 连通性测试
# SERVER A
[root@d1 ~]# docker exec -it b3b055b49d4c sh
/ # ping 172.33.1.12 -c 3
PING 172.33.1.12 (172.33.1.12): 56 data bytes
64 bytes from 172.33.1.12: seq=0 ttl=64 time=1.793 ms
64 bytes from 172.33.1.12: seq=1 ttl=64 time=0.598 ms
64 bytes from 172.33.1.12: seq=2 ttl=64 time=1.511 ms
--- 172.33.1.12 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.598/1.300/1.793 ms
# SERVER B
[root@d2 ~]# tcpdump -n -i ens33 icmp -w docker_vxlan.pcap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
^C4 packets captured
4 packets received by filter
0 packets dropped by kernel
[root@d2 ~]# sz docker_vxlan.pcap
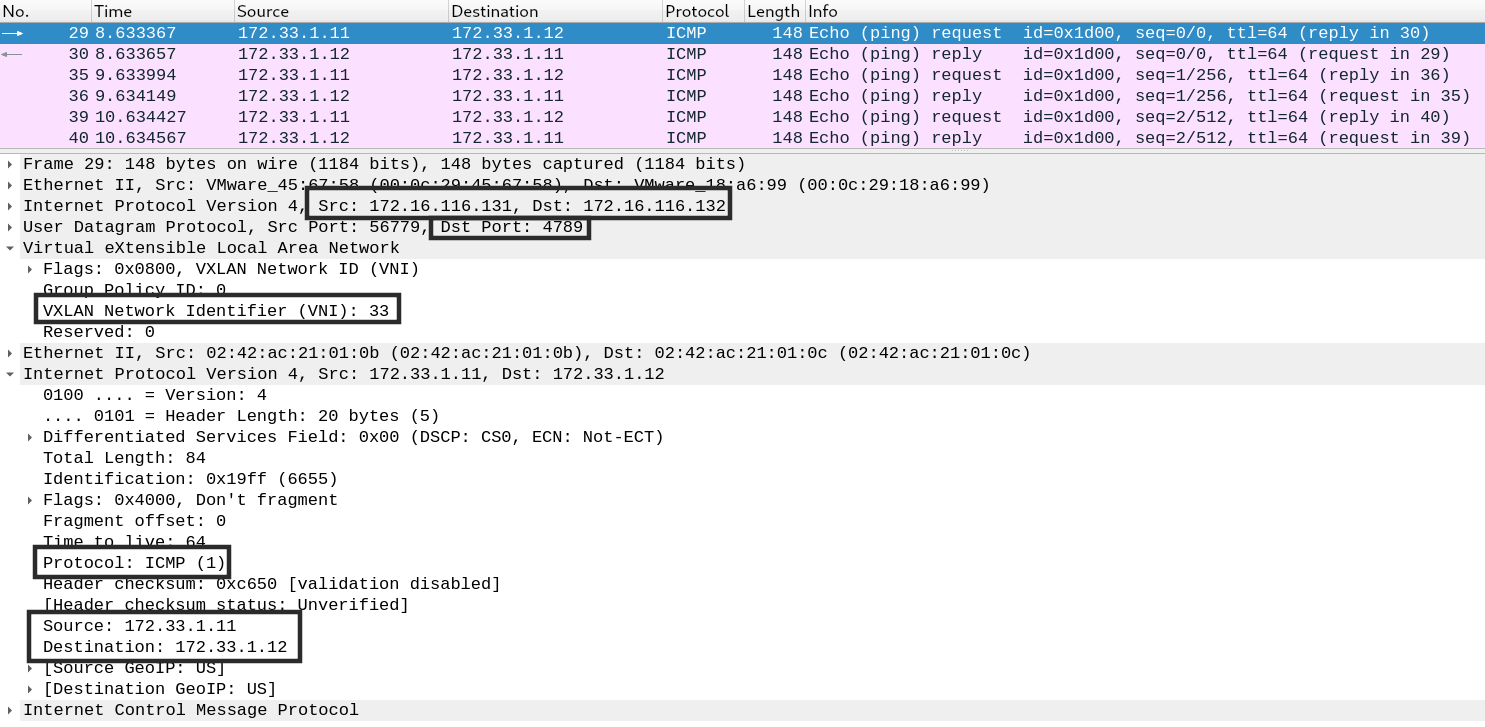
1.10 MacVLAN
前面的章节介绍了几种 Linux 虚拟网络设备:tap/tun、veth-pair、bridge等它们本质上是Linux内核提供的网络虚拟化解决方案,本章节要讲的MacVLAN也是其中的一种,准确说这是一种网卡虚拟化的解决方案。因为MacVLAN这种技术能将 一块物理网卡虚拟成多块虚拟网卡 ,由一个变多个(前提是网卡要打开混杂模式)。针对每一个虚拟网卡都可以分配一个独立的MAC地址和IP地址,这就相当于多个虚拟网卡通过一块物理网卡连接到物理网络中。
1.10.1 基本原理
macvlan是 Linux内核支持的一项特性,支持的版本有 v3.9-3.19 和 4.0+,推荐比较稳定的版本4.0+。它一般是以内核模块的形式存在,我们可以通过以下方法判断当前系统是否支持:
[root@d1 ~]# modprobe macvlan
[root@d1 ~]# lsmod | grep macvlan
macvlan 19239 0
如果以上命令报错或者没有回显,那么说明您的系统暂时不支持macvlan。对于网工肯定纠结macvlan和vlan有啥区别,其实只是长得有点像实现机制是真心不一样啊。通过macvlan虚拟出来的子接口和原来的物理接口是完全独立的,这些macvlan虚拟接口可以单独配置MAC地址和IP地址,而vlan子接口和主接口需共用相同的MAC地址。vlan主要用来划分广播域,而 macvlan本身就是在同一个广播域中。macvlan通过不同的子接口来做到流量的隔离,一般通过收到报文的目的MAC来判断这个包需要交给哪个虚拟网卡转发,虚拟网卡再将数据包交给上层协议栈来处理。
+------------------------------------------------------------------------+
| |
| +-------------------------+ |
| Eth0 | Network Stack | |
| +------------+ | |
| | +----------------+---+--+-+ |
| | | | | |
|Physical Network | | | | |
| + | | | | |
| | | AA +------------+ | | | |
| | | +--------+ Macvlan A +---+ | | |
| | | | +------------+ | | |
| | | | | | |
| +----+----+ | | | | |
| | | +-------+---+ BB +-------------+ | | |
| | Eth 0 +--------+if dst mac is+-------+ Macvlan B +------+ | |
| | | +-----------+ +-------------+ | |
| +---------+ | | |
| | | |
| | CC +-------------+ | |
| +--------+ Macvlan C +---------+ |
| +-------------+ |
| By:[F0rGeEk] |
+------------------------------------------------------------------------+
1.10.2 工作模式
macvlan子接口之间的通信模式,macvlan分为以下四种网络模式。其中最常用的是bridge模式。
- 1. privite
在private模式下,同一主接口下的子接口之间彼此隔离不能通信。即使从外部的物理网络引流,也不能互相通信。 - 2. vepa
在vepa模式下,子接口之间的通信流量需要引流到外部支持802.1Qbg/VPEA功能的交换机上(可以是物理的或者虚拟的交换机),经由外部交换机转发再绕回来。这里所说的支持802.1Qbg/VPEA功能的交换机是指支持"端口回流"功能或者叫"支持hairpin模式",也就是说数据包从一个端口收到后还能通过这个端口再转发出去。 - 3. bridge
这bridge式下,主要是模拟Linux bridge的功能,但比bridge要好的一点的是每个接口的MAC地址是已知的,不用学习。所以在这种模式下,子接口之间默认就可以互相通信。 - 4. passthru
这种模式只允许单个子接口连接主接口,且必须设置成混杂模式,一般用于子接口桥接和创建 VLAN 子接口的场景。
1.10.3 MacVLAN实践
这里我们也分两部分来进行实践,一种实在普通的Linux网络环境下,另一种实在Docker容器环境中实践。在Docker网络环境中还可以分为两种,一种是相同macvlan之间的通信还有一种是不同macvlan之间的通信。其中不同vlan之间的通信类似数通中的单臂路由,因为二层是不通的所以需要借助三层网络通信,这里就需要通过一台路由设备(也可以是开启ip_forward的Linux主机)来进行路由转发。本文就介绍最基础最底层的实践方式,不同macvlan之间的通信相信对于网工的你来说简直easy的不要不要的。
- MacVLAN连接连个不同的NS
+-------------------------------------+
| +-------+ +-------+ |
| | NS1 | | NS2 | |
| +---+---+ +---+---+ |
| | | |
| | XXXXXXX | |
| | XX XX | |
| +---+X MacVLAN X+---+ |
| XX XX |
| XXXXXXX |
| + + |
| | | |
| +-----+--+--+-----+ |
| 12.1.1.1| Mac1 | Mac2 |12.1.1.2 |
| +--------+--------+ |
| | ens33 | |
| +-----------------+ |
| By:[F0rGeEk] |
+-------------------------------------+
这里我们的实验环境是将两个不同的Name Space之间通过macvlan连通,如上图所示为物理接口ens33创建两个macvlan子接口,使用bridge模式,并配置IP地址然后将它们分别加入到两个不同的NS中,最后测试连通性。具体过程如下:
# 创建两个macvlan子接口
[root@d1 ~]# ip link add link ens33 dev mac1 type macvlan mode bridge
[root@d1 ~]# ip link add link ens33 dev mac2 type macvlan mode bridge
# 创建两个NS
[root@d1 ~]# ip netns add ns1
[root@d1 ~]# ip netns add ns2
# 将两个macvlan子接口分别加入ns1和ns2
[root@d1 ~]# ip link set mac1 netns ns1
[root@d1 ~]# ip link set mac2 netns ns2
# 为两个macvlan子接口配置IP地址并激活
[root@d1 ~]# ip netns exec ns1 ip addr add 12.1.1.1/24 dev mac1
[root@d1 ~]# ip netns exec ns1 ip link set mac1 up
[root@d1 ~]# ip netns exec ns2 ip addr add 12.1.1.2/24 dev mac2
[root@d1 ~]# ip netns exec ns2 ip link set mac2 up
# 查看两个ns中的macvlan子接口配置信息
[root@d1 ~]# ip netns exec ns1 ip -d link show mac1
3: mac1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 42:e3:dc:fc:32:54 brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 0
macvlan mode bridge addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
[root@d1 ~]# ip netns exec ns2 ip -d link show mac2
4: mac2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fa:9e:76:06:1a:dd brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 0
macvlan mode bridge addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
[root@d1 ~]# ip netns exec ns1 ip addr show mac1
3: mac1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 42:e3:dc:fc:32:54 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 12.1.1.1/24 scope global mac1
valid_lft forever preferred_lft forever
inet6 fe80::40e3:dcff:fefc:3254/64 scope link
valid_lft forever preferred_lft forever
[root@d1 ~]# ip netns exec ns2 ip addr show mac2
4: mac2@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether fa:9e:76:06:1a:dd brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 12.1.1.2/24 scope global mac2
valid_lft forever preferred_lft forever
inet6 fe80::f89e:76ff:fe06:1add/64 scope link
valid_lft forever preferred_lft forever
# 测试连通性
[root@d1 ~]# ip netns exec ns1 ping 12.1.1.2 -c 3
PING 12.1.1.2 (12.1.1.2) 56(84) bytes of data.
64 bytes from 12.1.1.2: icmp_seq=1 ttl=64 time=0.035 ms
64 bytes from 12.1.1.2: icmp_seq=2 ttl=64 time=0.037 ms
64 bytes from 12.1.1.2: icmp_seq=3 ttl=64 time=0.037 ms
--- 12.1.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.035/0.036/0.037/0.005 ms
抓包分析 ICMP 报文
[root@d1 ~]# tcpdump -i ens33 -w macvlan.pcap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
^C18 packets captured
19 packets received by filter
0 packets dropped by kernel
[root@d1 ~]# sz macvlan.pcap A
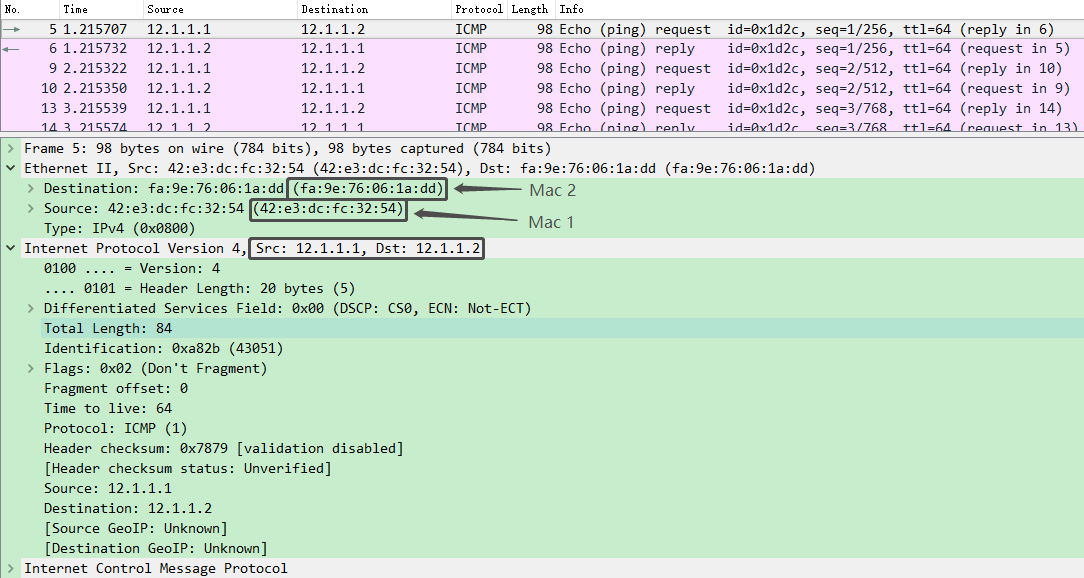
- 容器网络环境中相同macvlan之间
在docker容器网络环境中,macvlan也是一种非常常见且重要的跨主机网络模型。下面我们就针对容器网络进行相同macvlan在不同主机之间通信的实践。实验环境为两台server:Server A和Server B;分别启用一个自定义网络172.33.1.0/24名称为mac1和mac2;分别创建两个容器并指定IP地址;最后测试两个容器之间的网络连通性。
+------------------------------------------------------------------------+
| |
| +-------------------+ +-------------------+ |
| |Server A | |Server B | |
| | +---------+ | | +---------+ | |
| | | Docker A| | | | Docker B| | |
| | +---------+ | | +---------+ | |
| | 172.33.1.11 | | 172.33.1.12 | |
| | | | | | | |
| | +------+------+ | | +------+------+ | |
| | | Mac 1 | | | | Mac 2 | | |
| | +------+------+ | | +------+------+ | |
| | | | | | | |
| | +----+----+ | | +----+----+ | |
| | | ens33 | | | | ens33 | | |
| +----+---------+----+ +----+---------+----+ |
| 172.16.116.131/24 172.16.116.132/24 |
| | | |
| +--------------------------------------------+ |
| By:[F0rGeEk] |
+------------------------------------------------------------------------+
具体实践过程如下:
# 启动docker服务
[root@d1 ~]# service docker start
Redirecting to /bin/systemctl start docker.service
# 创建docker自定义网络
[root@d1 ~]# docker network create -d macvlan --subnet=172.33.1.0/24 --gateway=172.33.1.1 -o parent=ens33 mac1
[root@d2 ~]# docker network create -d macvlan --subnet=172.33.1.0/24 --gateway=172.33.1.1 -o parent=ens33 mac2
# 检查自定义网络是否创建成功
[root@d1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
f8a5e7ba5015 bridge bridge local
a96c8a04be60 host host local
e179ce74baa4 mac1 macvlan local
8f8172bcf173 none null local
[root@d2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
68199147d7fe bridge bridge local
eb0d0e219eb8 host host local
9c2b18b8a08a mac2 macvlan local
b7ac4a61fcce none null local
#创建并启用容器
[root@d1 ~]# docker run -itd --name DockerA --ip=172.33.1.11 --network mac1 busybox
00dda3a8691564dce5e062a2c4ea89cb5c9640373102d587eb2c83e122642a67
[root@d1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
00dda3a86915 busybox "sh" 4 seconds ago Up 2 seconds DockerA
[root@d2 ~]# docker run -itd --name DockerB --ip=172.33.1.12 --network mac2 busybox
debe59d38ece790d1ffd3d2dc17240a15812b73025fd89b23d9d394f53fa7dc8
[root@d2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
debe59d38ece busybox "sh" 2 seconds ago Up 2 seconds DockerB
# 验证不同宿主机上的容器网络连通性
[root@d1 ~]# docker exec -it DockerA sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:21:01:0B
inet addr:172.33.1.11 Bcast:172.33.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:28 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2544 (2.4 KiB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 172.33.1.12 -c 3
PING 172.33.1.12 (172.33.1.12): 56 data bytes
64 bytes from 172.33.1.12: seq=0 ttl=64 time=0.405 ms
64 bytes from 172.33.1.12: seq=1 ttl=64 time=0.361 ms
64 bytes from 172.33.1.12: seq=2 ttl=64 time=0.310 ms
--- 172.33.1.12 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.310/0.358/0.405 ms
抓包分析 ICMP 报文
[root@d2 ~]# tcpdump -i ens33 -w macvlan.pcap
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
^C25 packets captured
26 packets received by filter
0 packets dropped by kernel
[root@d2 ~]# sz macvlan.pcap
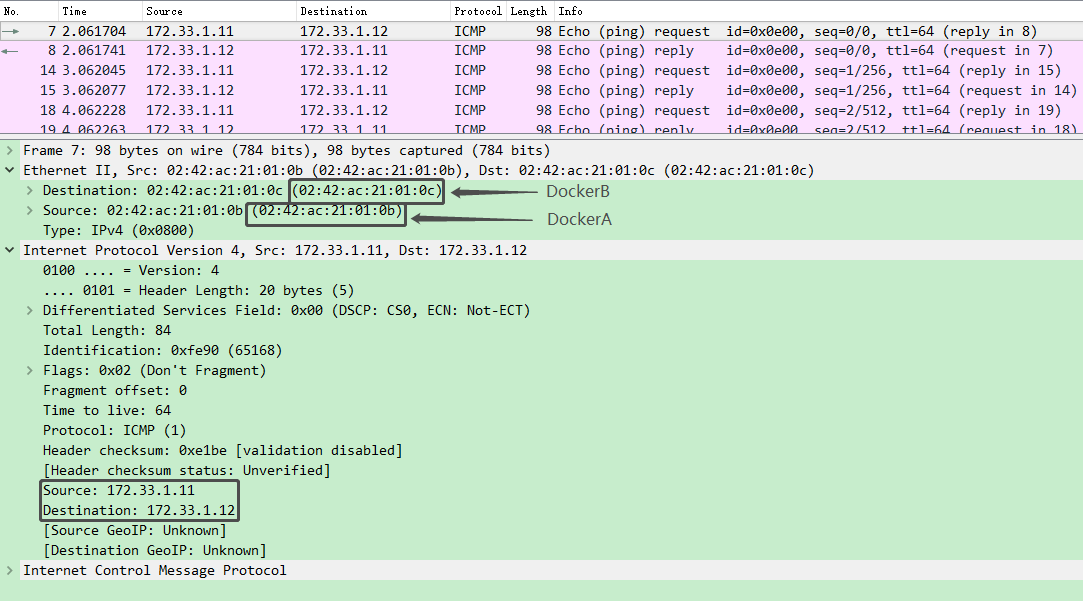
酝酿酝酿准备写云计算中的网络虚拟化(二),主要计划围绕容器中的各种网络模型来写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号