

linux网络收包过程
记录一下linux数据包从网卡进入协议栈的过程,不涉及驱动,不涉及其他层的协议处理。
内核是如何知道网卡收到数据的,这就涉及到网卡和内核的交互方式:
轮询(poll):内核周期性的检查网卡,查看是否收到数据。优点:数据包非常多的时候,这种处理方法会非常快速有效。缺点:数据包少的时候会CPU总是轮询却没有收到数据包,造成CPU资源的浪费。这种方法很少使用。
中断(interrupt):网卡收到数据就给内核发送硬件中断打断内核的正常运行,让内核来处理数据包。优点:在数据包少的时候CPU能及时中断其他任务来处理数据包,比较高效。缺点:数据包多的时候每个数据包都引发一次中断,造成CPU频繁地在收包过程和其他过程之间切换,浪费时间。在极端情况下收包中断可能会一直抢占CPU造成软中断无法运行,收包队列得不到处理,进而造成大量丢包。这就是所谓的receive-livelock。
Llinux早期是采用中断的方式处理数据包的,之后引入了另一种方式NAPI,NAPI结合了轮询和中断的优点,在数据包少的时候采用中断方式,数据包多的时候采用轮询的方式,从而在两种极端情况下也会有比较好的表现。
在NAPI下收包的过程
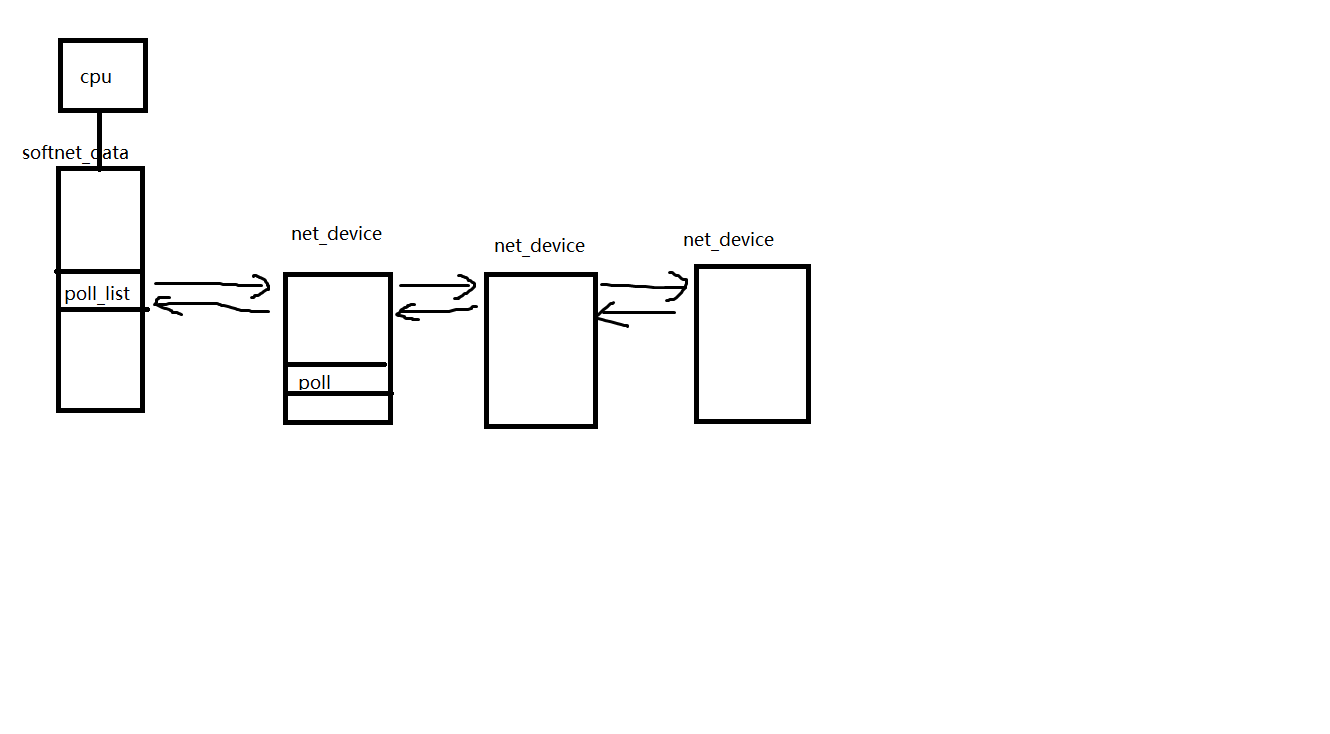
先看一个比较关键的结构softnet_data,每个逻辑CPU都有一个softnet_data结构,这个结构的poll_list是非常重要的。
struct softnet_data { struct net_device *output_queue; //收报队列,这个队列是给传统收报方法兼容新收报架构用的(backlog_dev),用来模拟NAPI的 struct sk_buff_head input_pkt_queue; //用于收包的net_device struct list_head poll_list; struct sk_buff *completion_queue; //backlog_dev是一个伪造的net_device用来来处理input_pkt_queue里的数据 struct net_device backlog_dev; /* Sorry. 8) */ };
收包过程可以分成两步:
- 当网卡收到数据包中断发生,中断处理程序就会把当前网卡的net_device插入当前CPU的softnet_data的poll_list链表,调度软中断。
- 软中断处理链表poll_list,读出数据包,放入协议栈。
第一步的中断的代码可以参考drivers/net/tg3.c文件的tg3_interrupt函数,中断发生的时候它会调用netif_rx_schedule把当前网卡的net_device插入当前CPU的softnet_data的poll_list链表。netif_rx_schedule函数又调度了软中断NET_RX_SOFTIRQ。大致结构就是下图这样子
第二步软中断在合适的时机得以执行,看一下他的执行过程:
static void net_rx_action(struct softirq_action *h) { struct softnet_data *queue = &__get_cpu_var(softnet_data); unsigned long start_time = jiffies; //预算,所有网卡的总配额 int budget = netdev_budget; void *have; local_irq_disable(); while (!list_empty(&queue->poll_list)) { struct net_device *dev; //预算用完了,或者时间太长了,跳出等下一轮处理 if (budget <= 0 || jiffies - start_time > 1) goto softnet_break; local_irq_enable(); dev = list_entry(queue->poll_list.next, struct net_device, poll_list); have = netpoll_poll_lock(dev); if (dev->quota <= 0 || dev->poll(dev, &budget)) { netpoll_poll_unlock(have); local_irq_disable(); //没处理完,放到队尾准备下次处理,注意是list_move_tai,不是 //list_insert_tail list_move_tail(&dev->poll_list, &queue->poll_list); if (dev->quota < 0) dev->quota += dev->weight; else dev->quota = dev->weight; } else { netpoll_poll_unlock(have); dev_put(dev); local_irq_disable(); } } //省略部分代码 }
软中断不能长时间占用CPU,否则会造成用户态进程长时间得不到调度,net_rx_action也一样。所以net_rx_action函数每次执行最多会处理budget个数据包(所有网卡都算),同时这budget个数据包也需要平均分配,不能只处理一个网卡造成其他网卡得不到处理,net_device的weight和quota是用来处理这个问题的。这个代码的大概意思是每次从poll_list里取出一个网卡,调用该网卡的poll函数尽可能多的收包(但是不会超过weight),poll函数收包后调用netif_receive_skb把数据包放入协议栈。如果网卡里的数据包没处理完就会把net_device继续放到poll_list链表等待下一次软中断继续处理,如果网卡里的数据包处理完了就把该net_device从poll_list摘除。
传统中断收包方式
linux网卡驱动还有部分是用的传统中断收包方式,为了兼容也都挪到了NAPI架构上。用softnet_data结构的backlog_dev伪造了一个net_device。中断发生的时候把数据包放到了softnet_data结构的input_pkt_queue链表里。
static int __init net_dev_init(void) { //省略部分代码 for_each_possible_cpu(i) { struct softnet_data *queue; queue = &per_cpu(softnet_data, i); skb_queue_head_init(&queue->input_pkt_queue); queue->completion_queue = NULL; INIT_LIST_HEAD(&queue->poll_list); set_bit(__LINK_STATE_START, &queue->backlog_dev.state); queue->backlog_dev.weight = weight_p; queue->backlog_dev.poll = process_backlog; atomic_set(&queue->backlog_dev.refcnt, 1); } }
软中断的处理过程和NAPI类似。

