训练STGCN中的知识点
STGCN输入
输入的格式为(num_samples, num_nodes, num_timesteps_train, num_features)(batch, 节点数, 连续时间片个数, 节点特征维度)
STGCN结构
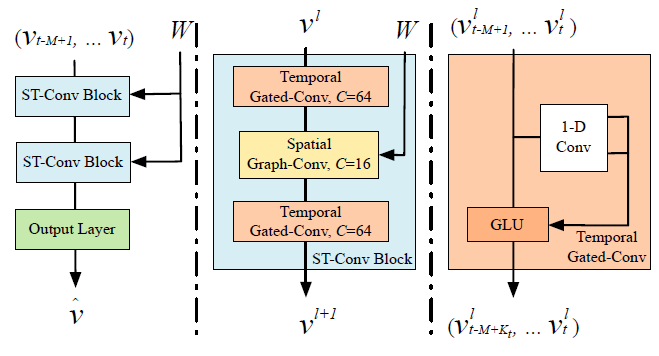
STGCN 的结构如下,两层时空卷积块和一层时域卷积块。
时空卷积块(图中的中间部分)又是由两个时域卷积块夹着一层空域卷积构成的。
时域卷积块(图中的最右部分)是由一维卷积构成,该卷积核是一个k时间步和c维的(k*c)的形式,卷积核在时间步上进行卷积(只沿着时间方向走,所以称为1维卷积)。之后通过一个GLU(门控线性单元)。GLU:线性变换乘以自身的非线性变换,如下图。
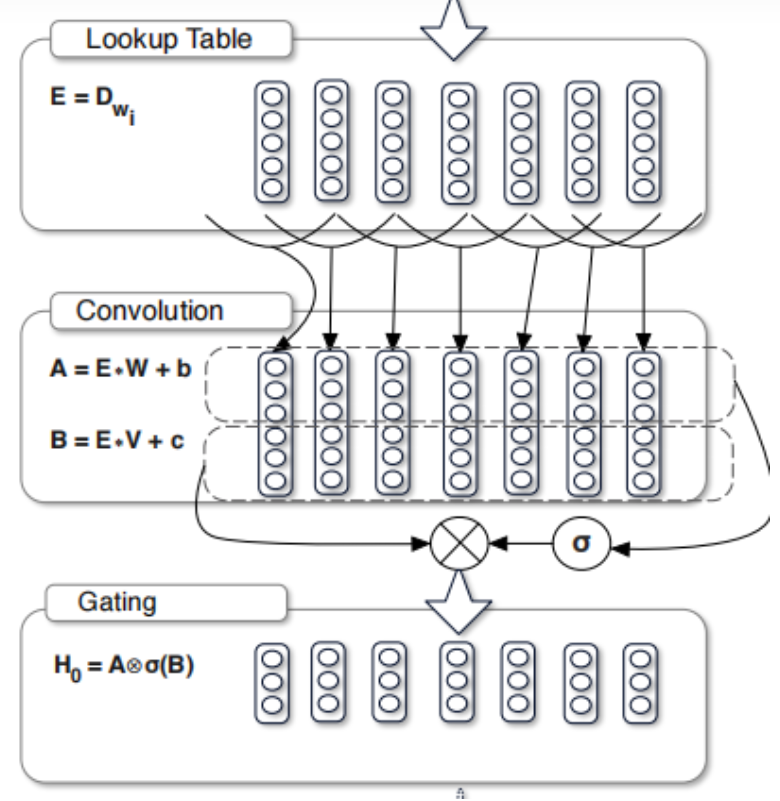
在glu后面再加一个残差结构,用relu再进行激活。最终的公式:
relu ( conv1(X) * sigmoid(conv2(X)) + conv3(X) )
空域卷积块在论文中用chebGCN,代码中直接用GCN实现。它对每个时间步的图上进行(不在时间步之间进行)。GCN:求每个结点的其邻居(包括自己)节点的特征向量的带权和
在每个时域卷积块和空域卷积块中,都使用了残差连接。
最后接上全连接层做预测
optimizer.zero_grad(), loss.backward(), optimizer.step()
这三个函数出现在神经网络训练过程中,框架如下
model = MyModel() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4) for epoch in range(1, epochs): for i, (inputs, labels) in enumerate(train_loader): output= model(inputs) loss = criterion(output, labels) # compute gradient and do SGD step optimizer.zero_grad() loss.backward() optimizer.step()
在每一轮epoch中,会依次使用这三个函数,他们是先将梯度归零(optimizer.zero_grad()),然后反向传播计算得到每个参数的梯度值(loss.backward()),最后通过梯度下降执行一步参数更新(optimizer.step())。
optimizer.zero_grad():因为训练的过程通常使用mini-batch方法,所以如果不将梯度清零的话,梯度会与上一个batch的数据相关,因此该函数要写在反向传播和梯度下降之前。
loss.backward():做完运算后使用tensor.backward(),所有的梯度就会自动运算,tensor的梯度将会累加到它的.grad属性里面去。如果没有进行tensor.backward()的话,梯度值将会是None,因此loss.backward()要写在optimizer.step()之前。
optimizer.step():step()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。step() 只负责通过梯度下降进行优化,而不负责产生梯度,梯度是tensor.backward()方法产生的。
单机多卡训练
只需要在定义的model外面套上nn.DataParallel()
model = ...
model = nn.DataParallel(model.to(device), device_ids=gpus, output_device=gpus[0])
DataParallel并没有改变模型的输入和输出。只是将数据分摊给各个GPU进行传播,因此之前设置的batch,在每个GPU上会变成(batch/GPU数量)。进行完前向传播后,各个GPU的输出再返回到主设备cuda0上进行合并和loss计算。
缺点是这样相当于压力又只在cuda0上,出现了计算负载不均衡的情况。解决办法是将loss计算写在model里面,即每个GPU在完成前项传播输出后,继续计算loss,这样得到多个loss,再采用取平均或者其他方式转为
不需要对原来单卡训练的代码进行较大改动。也可以使用最新的DistributedDataParallel,代码如下,这是一个多进程的方式,不同进程之间的loss可以取平均
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号