RegionEncoder论文阅读
RegionEncoder - Unsupervised Representation Learning of Spatial Data via Multimodal Embedding
作者将这个工作叫做 Learning an Embedding Space for Regions (LESR),将空间区域映射到低维特征。空间有自相关性和异质性,一个好的embedding表示需要捕捉到这两种特性。自相关性从两个角度去做,(1)图卷积神经网络(局部谱运算?),(2)一个区分不相关的负样本的鉴别器。异质性通过出租车的加权轨迹图建模。
文章主要贡献有三点
- 用多模态构建了空间embedding
- 提出了一种新的网络结构
- 在两个不同的城市验证有效
该文章用卫星图像,poi,加权人口流动图和空间信息这些多模态数据得到了区域语义信息。
空间信息:地理上相邻的地方理应相似
人员流动:人们从一个区域走到另一个区域,这两个区域应该有语义上的关联
POI信息:即使地理位置不相连,但是POI信息也能反映出两个区域的相似性(POI信息应该是高维的?)
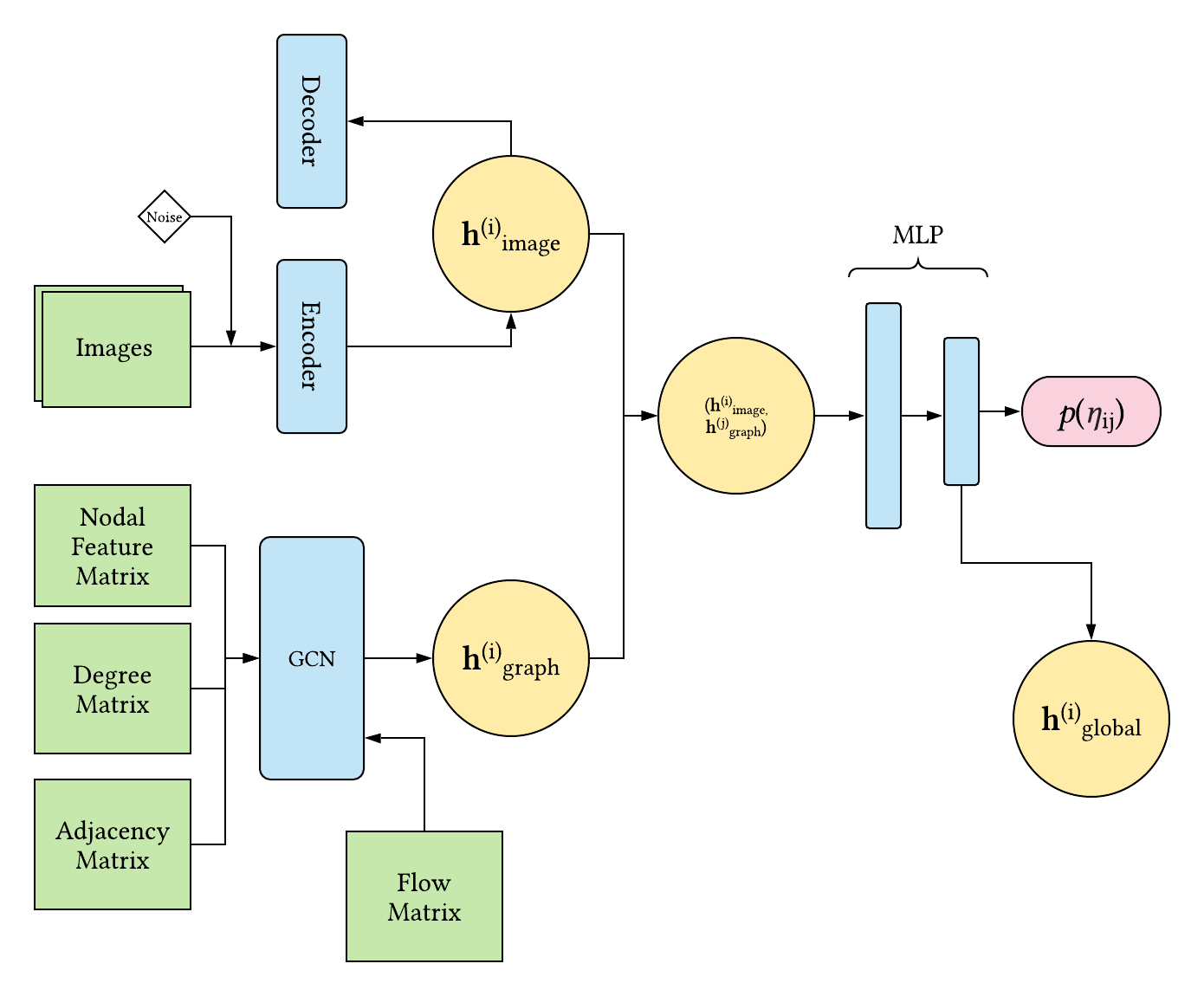
去噪自编码器
enconder层是两个卷积层再接三个全连接层, decoder是三个全连接加两个卷积层。
图卷积
一部分是空间信息和POI信息
![]()
Z是要求的隐向量,Z0初始值为X,激活函数为RELU。该文章用了两层GCN,第二层GCN提取了隐向量,就是Z2。
然后就是训练的损失函数了,还是用skip-gram和负采样做损失函数
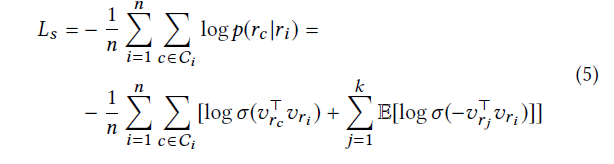
另一部分是交通图
用KL散度对加权的图重新建模
定义两个小矩形连接的概率如下,两个向量越接近,乘积越大,分母越小。
![]()
而两个小矩形在训练数据连接的频率是
![]()
用KL散度得到了最后的损失函数
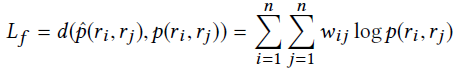
这个图是同时最小化这两个损失函数
vr就是训练后得到的隐向量
最后用MLP做分类器,上两部分分别得到的隐向量,如果两个向量属于一个格子,则为1,不是的话则为0。训练分类器后,拿mlp中间的隐层作为最终隐向量。
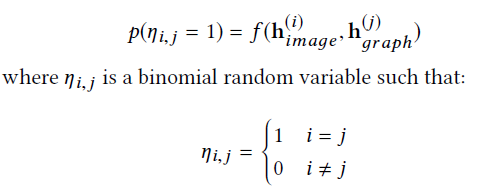
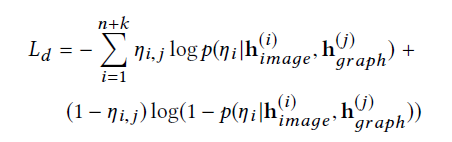
所以总的损失函数为
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号