
Zone2Vec论文阅读
Zone2Vec: Distributed Representation Learning of Urban Zones
提出了一种新的区域embedding的方法,他们叫做SAZE。考虑到了区域之间的连通性(出租车轨迹连接各个区域),也考虑了区域本身内在的属性(通过社交网络找到本区域的属性)。作者认为文章有两点贡献,一个是城市区域的分布式表示学习,一个是将多源数据融合。
看一下其他人做的工作
- 有用北京POI信息和公交卡信息,转成2维时间序列做的
- 有用同一群体的人经常聚到一起,分析他们的交通轨迹做的
- 有考虑用户、活动、时间和地点,用多维度协同推荐做的
- MC-TEM模型是用轨迹的多种上下文信息融合起来,得到分布式表示的一种模型,但是这种方式是找区域之间的轨迹,不适合发现区域的关系
- 有用LDA和DMR(主题模型)的,格网做词汇表,区域当做文章,移动的轨迹串起来的格网作为单词,这个区域的功能作为文章主题(不一定对)。但这个一个个“单词”是词袋表示,忽略了顺序,所以还有改进空间(感觉这篇文章可以重点看看 【N. J. Yuan, Y. Zheng, X. Xie, Y. Wang, K. Zheng, and H. Xiong, “Discovering urban functional zones using latent activity trajectories,” IEEE Transactions on Knowledge and Data Engineering, vol. 27, pp. 712–725, 2015.】)
所以作者在这篇文章用了skip-gram,把各个块的顺序也能考虑进来,并且发掘了这个区域本身的表达。
本文要点
- 用城市道路分割区域
- 分车型
- 区域有自己的向量表示t,根据轨迹串起来的连续区域,其向量拼起来作为矩阵T
- 区域之间有轨迹相连,可以构建邻接矩阵A,矩阵里面的值Mij表示从i区域开到j区域的频率
- 用T和M生成区域的embedding
![]() ,v个区域,每个区域向量k维
,v个区域,每个区域向量k维 - 从i走到相邻的区域的概率为
,此处有个上下文的窗口限制,计算概率可以用softmax
但是这样计算成本大,然后用了个负采样的方式近似计算
 ,
, ![]()
- 上面这样没有结合区域本身的语义信息,所以要加上微博数据,签到的位置映射到对应的区域作为label,签到内容去停用词和分词之后,当做文档内容,用doc2vec,得到每个区域的向量表示,拼起来就是矩阵T。然后按照矩阵分解降维的思路,找到低维的W和H。W和H都是凸函数,可以交替着目标训练,最终将W和HT拼到一起作为低维表示。
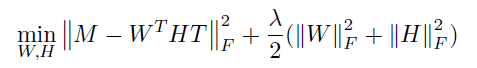
最后这个北京被道路分割的区域图挺有意思,看一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号