Hex2Vec论文阅读
Context-Aware Embedding H3 Hexagons with OpenStreetMap Tags
介绍了一种用公共开放地图数据,将地图上的小区域进行向量化表示的方法。
选了36个城市,用Uber H3将城市划分为六边形蜂巢,每个蜂巢手工标注上标签(比如建筑,绿地),用负采样的skip-gram的方式,计算了蜂巢的向量表示。(类似word2vec获得词的语义信息,hex2vec获得蜂巢语义信息)这些向量可以做聚类表示地理相似性,有可解释性。
现在这个公共开放地图有两个问题,一个是覆盖程度不够,一个是没有可用标签。
手动划分地图区域很困难,所以选空间索引,有Uber的H3和google的S2,该文章选用H3划分地图
之前的embedding方式有
Loc2Vec:用图像的方式做,12个channel,每个channel展示一个特征(道路啊设施啊),用triplet loss 来做自监督训练,位置相近的格网认为分类相同,作为正样本,随机选个不相连的格网做负样本。
Tile2Vec:和Loc2Vec差不多,区别是这个用了卫星图,还有就是网络换成了ResNet-18。
Zone2Vec:路网划分区域,用出租车行驶轨迹,得到区域到区域之间的序列,用Skip-Gram model做,也是最大化相邻区域的概率,负样本从当前区域的邻域外随机选取。然后又用了社交网络的数据,在这一区域发的微博之类的
内容,将其向量化,作为这个区域的label信息。
RegionEncoder:用出租车的轨迹、POI和卫星图像等多种信息作为来源。划分矩形格网。格网内poi信息统计并标准化,得到格网的poi向量。用出租车通行数据构建出以格网为顶点的图,权重是出租车游走的次数的标准化。网络有去噪卷积自编码机和图卷积神经网络,处理了poi向量和格网图,再接一个mlp,来分辨前面的两个向量是否来自于同一个地区。
Urban2Vec:用POI和街景地图。poi的文本信息(分类,打分和评论)通过nlp的方式(GloVe)得到embedding,街景图片的embedding和poi的embedding去贴(和上面的方法一样,多个数据的数据好像都是这么做,不同来源的数据各自embedding,然后训练让描绘同一个地区的embedding相近,不同的相远)
Region2Vec:用POI信息和手机基站信息,用GloVe和LDA实现embedding。每个基站范围的poi作为一篇文档,用皮尔逊相关系数生成相似矩阵,这些相似矩阵取平均生成相似区域(。。。?没看懂)
IRN2Vec:。。。
这篇文章说自己的不同点是,只用了公共开放地图的图像数据,并且用H3作为格网划分依据(上面介绍的要么是矩形格要么是路网要么是已有的行政区划分)
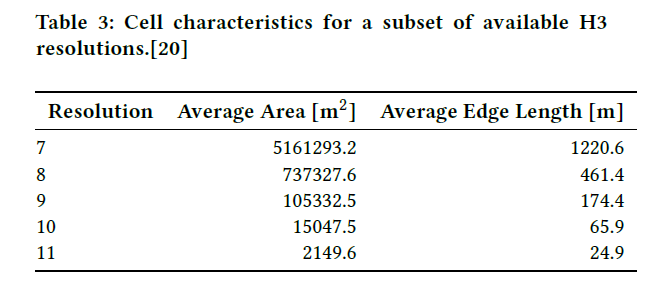
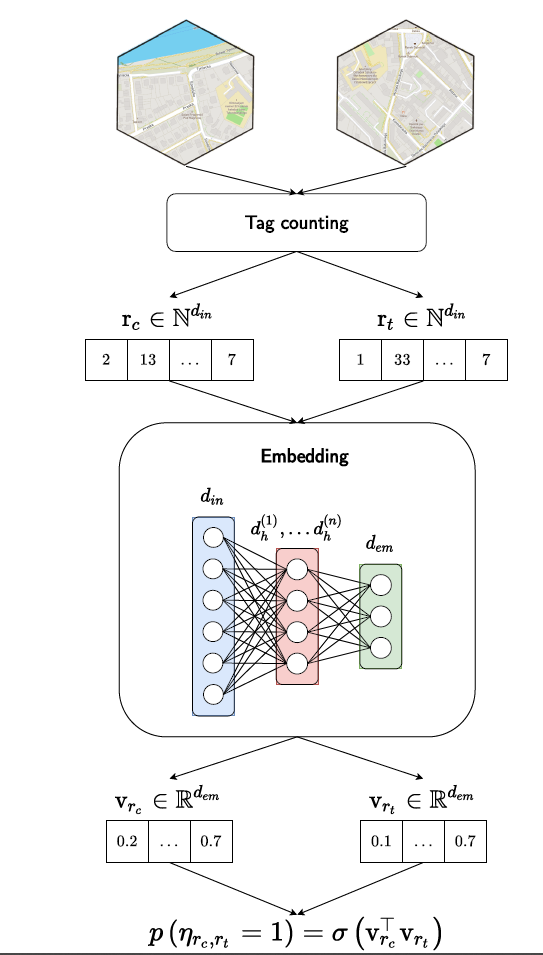
在地图上有很多认为标记的点,这些点中作者选了725个作为tags,例如building,office,water这些,然后用H3的第九级划分格子,每个格子可以包含一个或多个tags,用词袋模型将这些tags作为格子的feature。
Skip-gram模型的目标函数就是
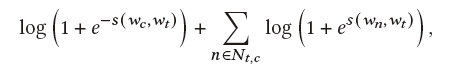
s是打分函数,wc是wt的上下文单词,wn是wt的非上下文单词。然后该文章还是用了一个假设,临近的蜂巢的embedding应该是相近的。计算方式是先把蜂巢的词袋表示通过全连接网络映射到低维向量。然后定义打分函数就是两个低维向量的乘积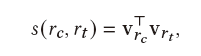 ,向量约接近,乘积越高,为了表示成概率的样子,在s外面套了一个sigmoid
,向量约接近,乘积越高,为了表示成概率的样子,在s外面套了一个sigmoid 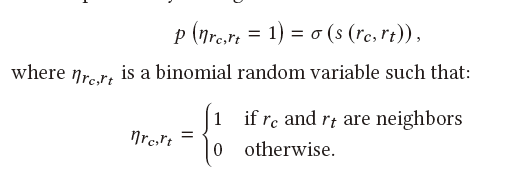
最终的目标函数长这样
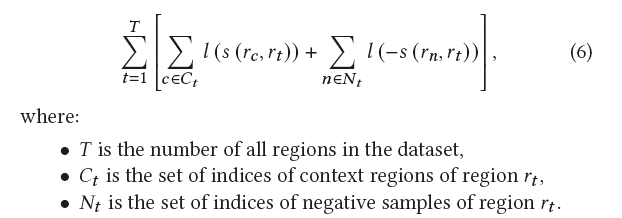
其中
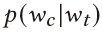
一开始是softmax算,后来改成了负采样算,见论文【Tomás Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013.Distributed Representations of Words and Phrases and their Compositionality.CoRR abs/1310.4546 (2013). arXiv:1310.4546 http://arxiv.org/abs/1310.4546】
整体结构长这样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号