



快速数据分析工具:pandas-profiling,超好用!
小编最近发现一个好用的工具, pandas-profiling,对于做数据分析的朋友们来说,这可是个好工具,它可以以网页的形式展现给你数据总体概况
在pandas中 df.describe() 是比较基础的探索性数据分析函数,而pandas_profiling则是在DataFrame的基础上扩展,用于快速数据分析。
对于DataFrame中的每一列,和类别有关的指标都会以交互式的网页展现出来
- Essentials: type, unique values, missing values
- (概要:类型,唯一值,缺失值)
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
- (分位数统计:像最小值,Q1,中位数,Q3, ,最大值,值域,四分位距)
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- (描述性统计:像均值,众数,标准差,和,绝对中位差,变异系数,峰值,偏度系数)
- Most frequent values
- (最频繁出现的值)
- Histogram
- (直方图/柱状图)
- Correlations highlighting of highly correlated variables, Spearman, Pearson and Kendall matrices
- (相关性,突出强相关的变量,Spearman, Pearson 和Kendall模型)
- Missing values matrix, count, heatmap and dendrogram of missing values
- (缺失值矩阵,计数,热图和缺失值的树状图)
首先,下载 pandas-profiling
pip install pandas-profiling
conda install -c anaconda pandas-profiling
也可以从github中下载
pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
接着,导入及应用
分析器(profiling)接收的数据类型为DataFrame
import pandas as pd
import pandas_profiling
data = pd.read_excel("")
profile = pandas_profiling.ProfileReport(data,title = "",pool_size = 3,minify_html = True)
profile.to_file(output_file="") 输出为html文件
profile.to_html() 输出为html源码
分析器的设置有:titile,线程池的个数(cpu),html是否要最小化,还有其他设置,可以参考:官方文档
生成报告文件之后,打开报告文件,你就可以看到关于这四个部分的内容
综述:包括数据量,数据类型,很贴心的还有warning,提醒你变量中零值占比和变量相关性
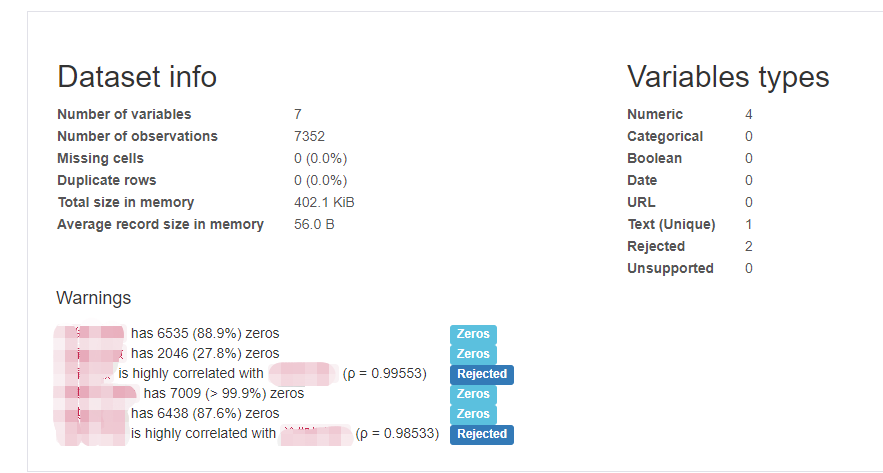
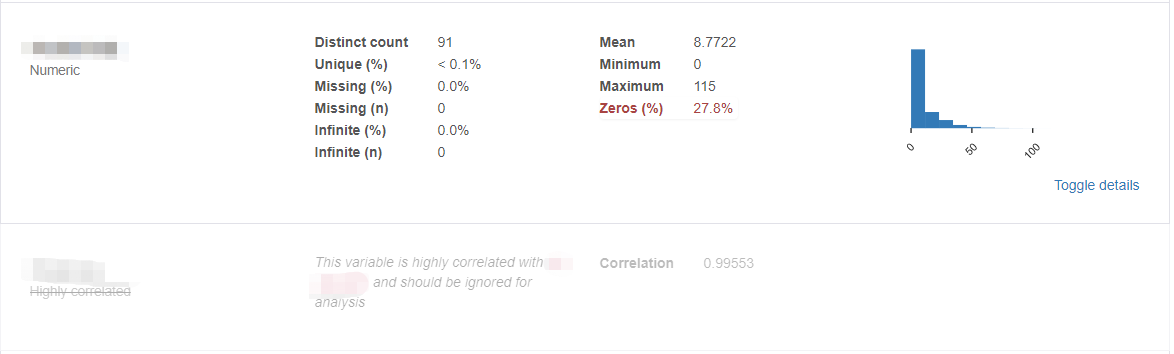
变量:将每个变量的去重后计数,缺失个数,缺失占比,均值,最大最小值,零值占比,右边还有个柱状图显示数据分布,点击右下角的展示细节,会有更加详细的分位数统计和描述性统计,极值前5展示,柱状图,
有意思的是,强相关的变量,会只展示其中一个变量。你会看到那一栏会灰色,它告诉你,这个变量和XX变量强相关
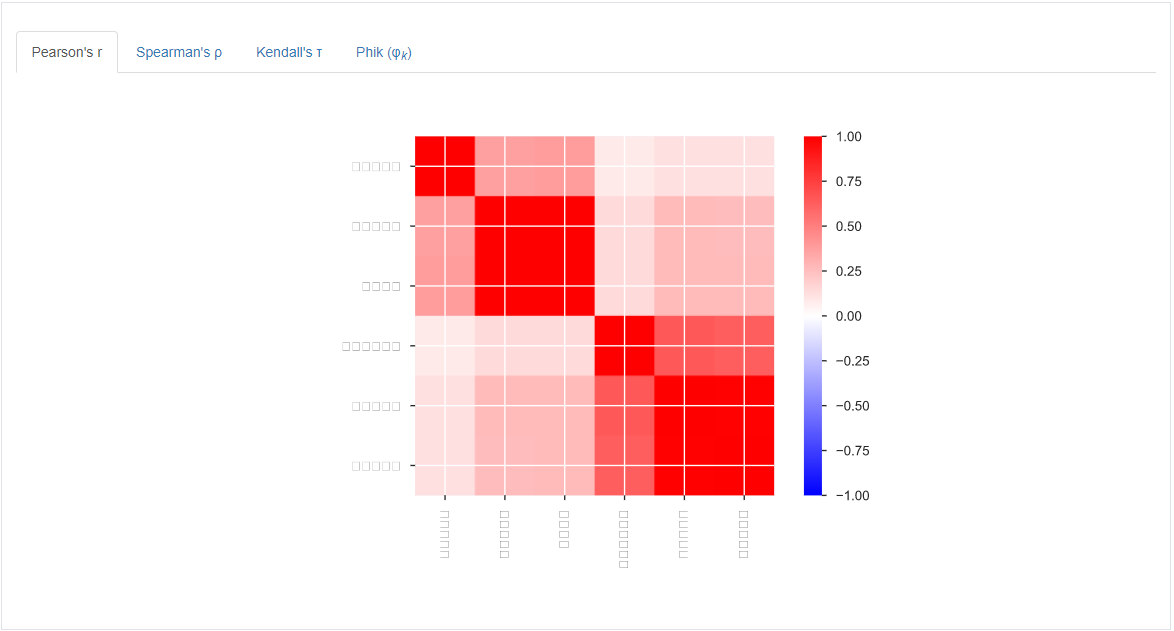
相关性:是以一个热图来展示,发现这里不太兼容中文
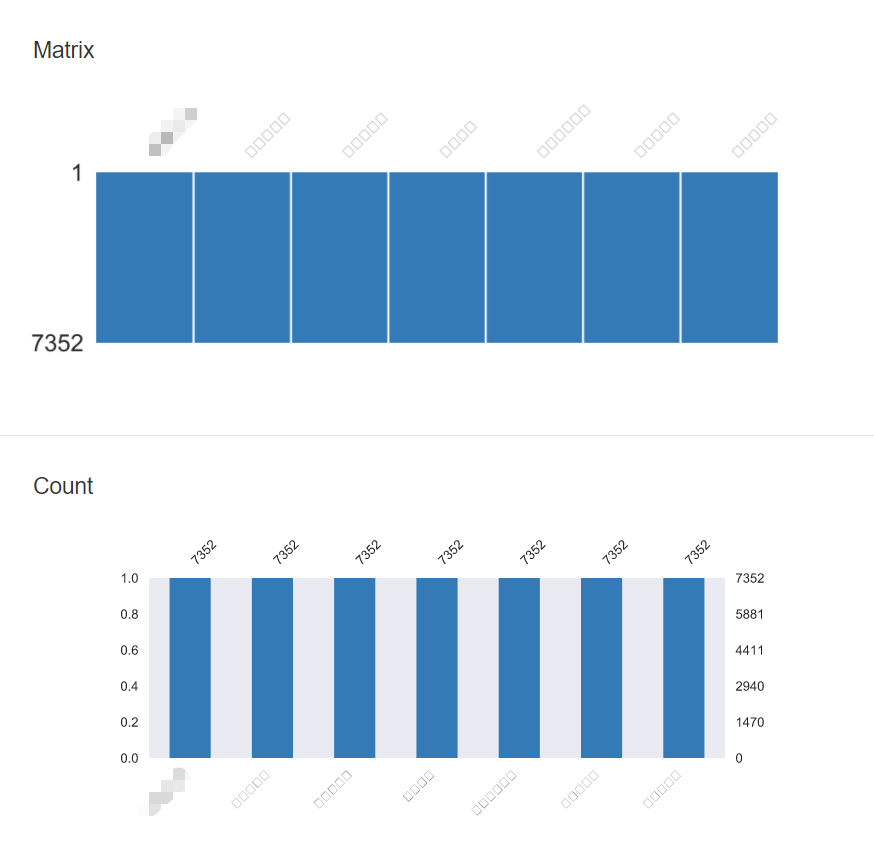
缺失值:是以两个柱状图来展现
样本:展现出前后10行的的样本
小编觉得pandas-profiling还挺好用的,源码还是python写的,简单易懂,想修改点功能还能自己改源码。快去试试吧,看过点个赞或推荐哦。

