
python 等频率切分数据
小编最近入坑风控,在工作中需要对数据进行等频率切分,也就是将数据划分成几段,在每段中,数据的出现频率,出现次数是大致相同的,让数据集在每段上呈现出分布均匀的趋势。
小编先是想到df.describe
cutlist = data[col].describe()
出来的结果是:
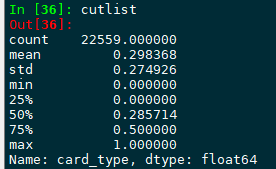
描述结果分别就是 计数,均值,标准差,最小,四分位数,最大值
我要的是十分位,那就要借助describe的参数percentiles 了,percentiles 中可以存放切分点的列表
cutlist = data[col].describe(percentiles = [1.0*i/k for i in range(k+1)])
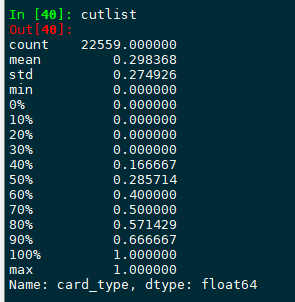
这时候就有十分位数了,再将十分位数取出来,但这个时候会遇到一个问题,在 cutlist["0%":"100%"] 之中,有一些重复的值,比如0%到30%的分位数都是0 ,这样子来做切分数据,是会出错,所以应该对数据进行去重
cutdata = pd.DataFrame(pd.cut(data[score],cutlist["0%":"100%"],include_lowest=True))
后来小编发现一个更加好用的函数 quantile ,顺便用drop_duplicates(keep="last") 去重并保留最后一个重复值
cutlist = data[col].quantile([1.0*i/k for i in range(k+1)],interpolation= "lower").drop_duplicates(keep="last")
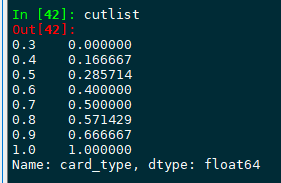
quantile值得注意的是他的参数 interpolation ( 插值方法 当所需分位数位于两个数据点i和j之间时,这个可选参数指定要使用的插值方法: ) ,可填选的值为 :‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’
官方文档的解释是:
linear :i + (j - i) *分数,其中分数是索引中被 i 和 j 包围的小数部分。
lower: i.
higher: j.
nearest: i or j 取最近的
midpoint: (i + j) / 2. 取中位数
如果不指定插值方法,当出现无法判断的情况时,是不会进行插值的
linear的插值方法example:
比如0.166666 是介于 (0.000000,0.166667 ] 之间 ,索引中被 i 和 j 包围的小数部分就是 0.3和0.4之间的小数部分0.4 ,那么
0.000000+(0.166667 - 0.000000)* 0.4 = 0.0666668
介于(0.000000,0.166667 ] 即被分到(0.000000,0.166667 ] 这段之间了。
以上是小编的想法,仅供参考,有任何新想法欢迎和我讨论!
