1、缓存IO
缓存I/O又被称作标准I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。
在Linux的缓存I/O机制中,对于write,数据会先被拷贝用户缓冲区,再拷贝到内核缓冲区,然后才会写到存储设备中。对于read,数据会先被拷贝到内核缓冲区,然后从内核缓冲区拷贝到用户缓冲区,最后交给用户程序处理。
缓存IO的缺点:数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
2、IO模型
根据以上基础知识,我们知道IO读写是一个耗费资源和时间的过程。网络IO的模型大致有如下几种:
- 同步阻塞IO(blocking IO)
- 同步非阻塞IO(nonblocking IO)
- IO多路复用( IO multiplexing)
- 信号驱动IO( signal driven IO)
- 异步IO(asynchronous IO)
注:信号驱动IO在实际中并不常用,所以常见的主要是四种IO模型。
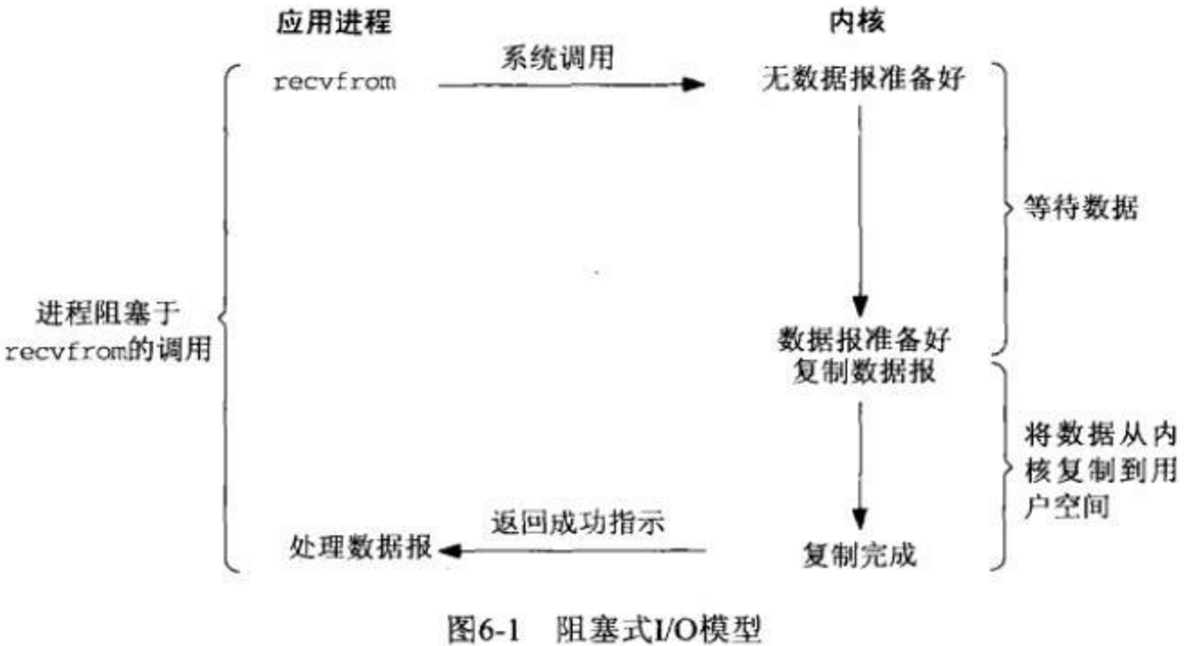
同步阻塞IO(blocking IO)
同步阻塞IO即在整个IO系统调用的过程中,进程都处于阻塞状态。在linux中,默认情况下所有的socket都是blocking。
以read为例:进程发起read,进行recvfrom系统调用,同时进程进入阻塞(进程是自己选择阻塞与否),等待数据;
内核开始准备数据(从磁盘拷贝到内核缓冲区),进程请求的数据并不是一下就能准备好;准备数据是需要时间的;
内核将数据从内核缓冲区拷贝到了用户缓冲区,内核返回结果,进程解除阻塞。
也就是说,内核准备数据和数据从内核拷贝到用户空间这两个过程都是阻塞的。
阻塞IO的过程如图所示:
优点:能够及时返回数据,无延迟。
调用代码逻辑简单。
缺点:等待浪费很长时间,影响程序性能。
同步非阻塞IO(nonblocking IO)
同步非阻塞IO即在IO系统调用的过程中,进程不必阻塞,而是采用定时轮询(polling)的方式数据是否准备就绪;在此期间,进程可以处理其他的任务。
以read为例:
进程发起read,进行recvfrom系统调用,如果kernel中的数据还没有准备好,就立刻返回一个error;
调用返回后进程可以进行其他操作,然后再次发起recvfrom系统调用,不断重复;(这个过程称为轮询polling)
kernel中的数据准备好以后,再次收到recvfrom调用,就将数据拷贝到了用户内存,然后返回;
需要注意,在数据从内核拷贝到用户内存的过程中,进程仍然是属于阻塞的状态。
非阻塞IO过程如下图所示:

优点:能在IO操作的过程中处理其他事物。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
IO多路复用(IO multiplexing)
I/O多路复用就是通过一种机制,可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。常见的select, poll, epoll 都是IO多路复用。
需要注意的是,select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
IO多路复用过程如下图所示:

关于select, poll, epoll的细节:
select、poll、epoll之间的区别总结
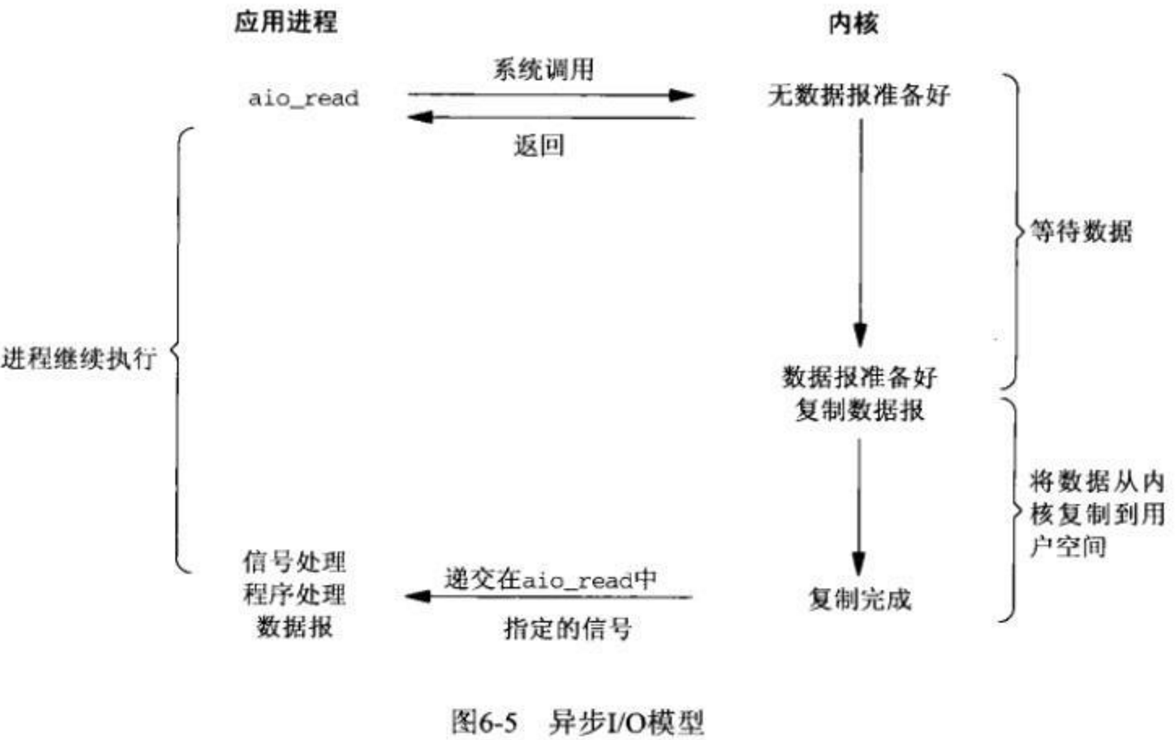
异步IO(asynchronous IO)
异步IO是事件驱动IO。用户进程发起IO操作之后,会立即返回,然后可以处理其他任务。kernel会等待数据准备完成,然后将数据拷贝到用户内存。当这一切都完成之后,kernel会给用户进程发送一个signal,通知IO操作完成。在IO
两个阶段,进程都是非阻塞的。
目前有很多开源的异步IO库,例如libevent、libev、libuv。
异步IO过程如下图所示:
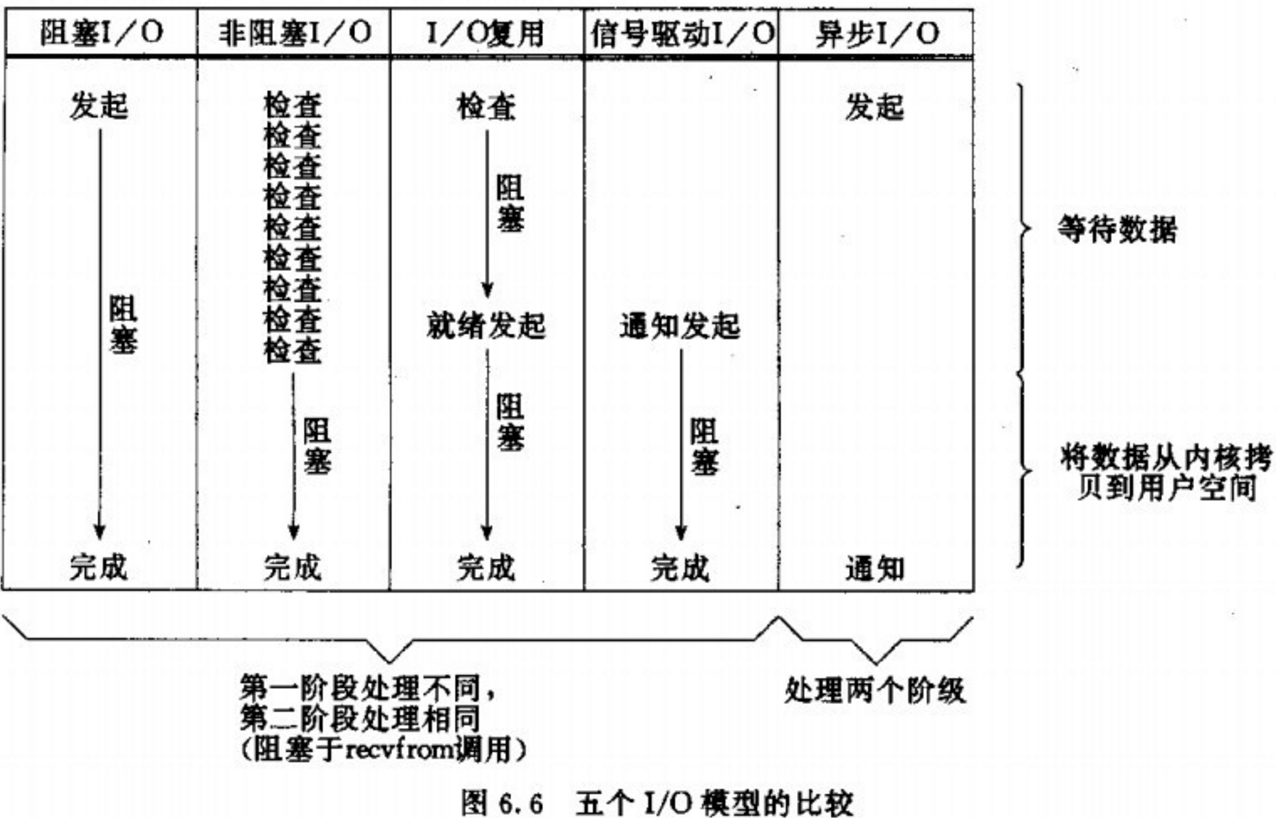
IO模型总结
3、协程
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是协程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
协程的优点:
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级。
2. 单线程内就可以实现并发的效果,最大限度地利用cpu。
协程的缺点:
1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程。
2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程。
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
4、Greenlet模块
简单实现单线程内的任务切换:
1: import greenlet 2: def eat(name): 3: print("%s eat 1" % name) 4: # 第二步 5: g2.switch("egon") 6: print("%s eat 2" % name) 7: # 第四步 8: g2.switch() 9: def play(name): 10: print("%s play 1" % name) 11: # 第三步 12: g1.switch() 13: print("%s play 2" % name) 14: g1 = greenlet.greenlet(eat) 15: g2 = greenlet.greenlet(play) 16: # 第一步 17: g1.switch("egon")
输出结果为:
1: egon eat 1 2: egon play 1 3: egon eat 2 4: egon play 2
注意单纯的切换(没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度。我们需要另一个模块--gevent模块。
5、gevent模块
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程。
用法:
1: g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 2: 3: g2=gevent.spawn(func2) 4: 5: g1.join() #等待g1结束 6: 7: g2.join() #等待g2结束 8: 9: #或者上述两步合作一步:gevent.joinall([g1,g2]) 10: 11: g1.value#拿到func1的返回值
遇到IO阻塞时会自动切换任务
