MySQL 快速入门(一)
 MySQL快速入门,看这一篇就够了,库、表、数据相关操作都在这里👆
MySQL快速入门,看这一篇就够了,库、表、数据相关操作都在这里👆
MySQL快速入门(一)

简介
存储数据的演变过程
- 数据的存储通过我们自己编写来决定,存到文件的样式千差万别
- 软件开发目录规范规定了文件的位置,不同的文件存储相应功能的代码和不同类型的数据
- 通过数据库来存储所有文件内的数据,统一成一个格式的数据,所有人操作数据都来一个地方(都用SQL语句)
'''
不管BS还是CS架构,服务端和客户端都是基于socket通信来收发消息的,后台的编程语言有很多,数据类型可能不一样,那么在存储数据的时候使用数据库,SQL语句就规定了统一操作数据的语言
'''
主要版本
- 5.6:使用频率较高的版本
- 5.7:目前正在过渡的版本
- 8.0:目前最新的版本
数据库分类
-
关系型数据库特点
- 数据之间彼此有关系或者约束
- 存储数据的表现形式通常以表格存储,每个字段还会有存储类型的限制
MySQL:开源免费,比较好用 Oracle:收费,维护成本高,大型公司可能会用 PostgreSQL:支持二次开发 MariaDB:MySQL的替代产品(并且有自己的特性) sqlite:小型数据库(django框架自带该数据库) -
非关系型数据库特点:
- 存储数据通常以K,V键值对形式存储
- 约束不是很大,用于缓存等
redis:目前最火的缓存数据库 具有很多数据结构 功能强大 mongodb:文档型数据库 可以用在大数据和爬虫领域 memcache:已经被redis淘汰
概念介绍
类比理解
- 库:文件夹
- 表:文件
- 记录:文件内一行行的数据
- 表头:表格的第一行
MySQL安装
推荐下载5.6,5.7版本左右的,尽量不要下载最新版本
步骤如下:
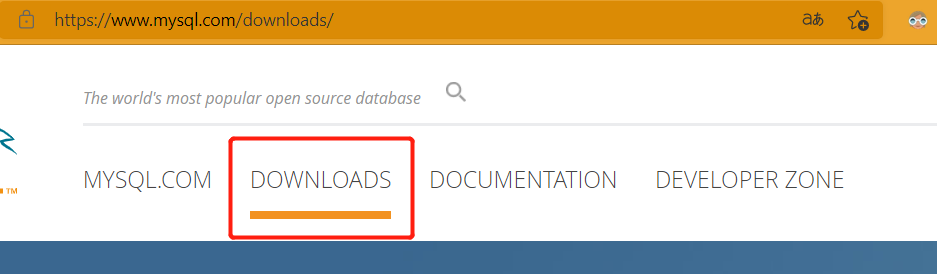
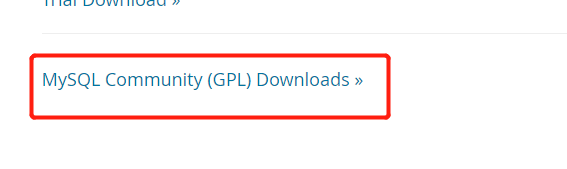
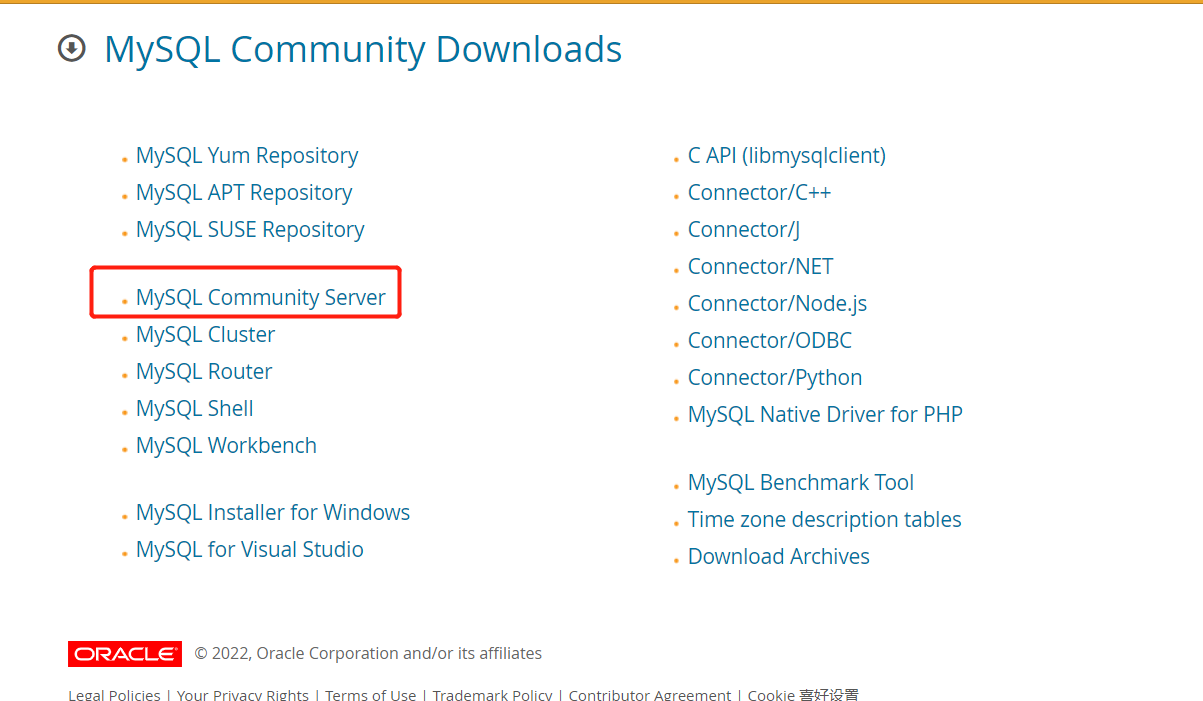
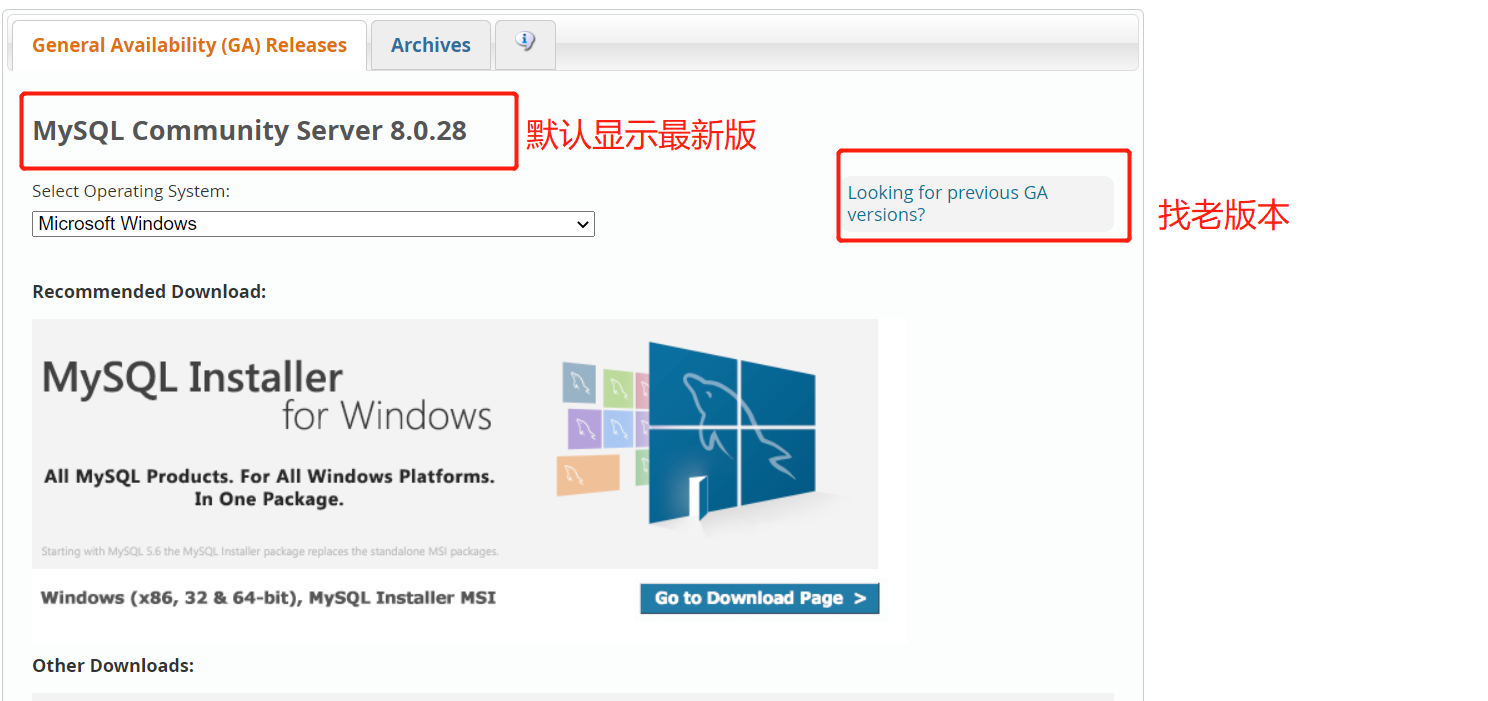
下载后解压缩
'''
打开bin文件
1. 服务端:mysqld.exe
2. 客户端:mysql.exe
'''
登录
# 在超级管理员身份下打开cmd命令窗口登录
mysql -uroot -h 127.0.0.1 -P 3306 -p
-u:用户
-h:地址
-P:端口
-p:密码
# 简写
mysql -uroot -p
# 只写mysql
mysql登录游客模式,不是管理员登录,只能体会lowb的功能
MySQL命令初始
show databases; # 展示所有数据库
\c或 ctrl+c(新版本) # 取消执行
exit\ctrl+z(新版本) # 退出
环境变量配置
win命令补充
# 查看进程
tasklist
tasklist |findstr mysqld
# 杀死进程(管理员模式)
taskkill /F /PID PID号
MySQL环境变量配置
步骤
1.配置环境变量,将mysqld所在路径添加到path中
D:\MySQL\mysql-5.6.48-winx64\mysql-5.6.48-winx64\bin
2.将mysql服务端mysqld制作成开机自启动的服务
打开cmd,输入mysqld --install
# 移除mysql服务:mysql --remove
修改配置文件
[mysqld] : mysql服务端,启动mysql服务加载的配置
[mysql] :mysql客户端,启动mysql加载的配置
[client] :其他客户端
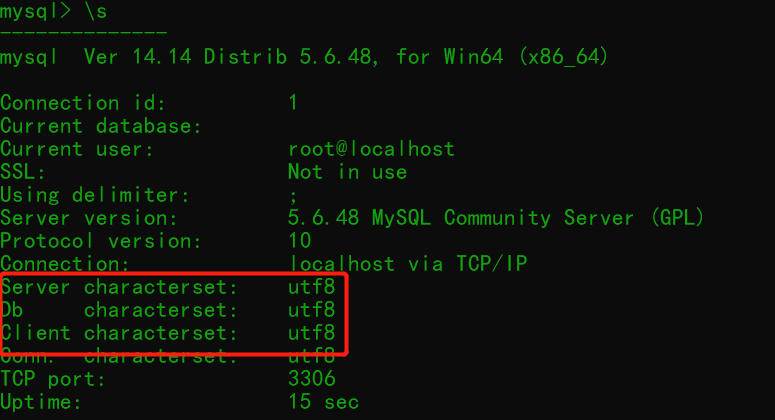
统一编码配置,在目录下新建
my.ini文件,写入以下内容
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
# 然后重启服务
# \s查看
配置用户名和密码,登录可以不用输入(可选)
[mysql]
user="root"
password=[密码]
设置新密码
# 下载好的MySQL初始没有密码,可以设置新密码,
# 在cmd中,注意-uroot和-p[oldpwd]是整体
mysqladmin -uroot -p[oldpwd] password [newpwd]
# 登录mysql修改
mysql -u root -p 登录后
set password for username@localhost = password(newpwd);
# set password for root@localhost = password('7410');
忘记密码的情况
1. 先关闭mysql服务
# 命令行启动,原理是跳过登录密码验证功能
2. mysqld --skip-grant-tables
3.无密码登录:mysql -uroot -p
4.修改当前用户的密码(mysql文件夹中的user表):update mysql.user set password=password(新密码) where user='root' and host='localhost'; # 括号内写密码('1234')
5.将修改数据刷到硬盘:flush privileges;
6.重新启动服务就可以正常校验登录了,登录
基本sql语句
大部分程序的业务逻辑都是增删改查,如果内容较多展示补全出现错乱的情况 可以在语句后面加
\G
库的增删改查(文件夹)
# 增加数据库
create database 数据库名;
create database 数据库名 charset ='gbk'; # 设置库的字符集编码
# 查看数据库
show database; # 查所有数据库
show create database 数据库名; # 查单个
# 修改数据库
alter database 数据库名 charset='gbk';
# 删除数据库
drop database [数据库名];
表的增删改查(文件)
操作表,需要指定该表所在的库(文件夹)
# 查看当前所在库的名字
select database();
# 切换库
use 数据库名;
# 增加表
create table 表名(字段1,字段2);
create table t1(id int,name char(4));
# 删除表
drop table [表名];
# 修改表
alter table 表名 rename 新表名 ;
alter table 表名 change 字段名 新字段名 类型;
alter table 表名 modify 字段 字段类型 ;
alter table t1 modify name char(16);
# 查看表
show tables; # 查看库下所有表
show create table 表名; # 查看单表
desc 表名; # 查看表的详细字段信息
# 在一个数据库操作另外一个数据库内的表,可以不use
数据库名.表名
数据的增删改查(数据)
操作数据,先确定库,在确定表,在操作数据
# 增加数据
insert into 表名 values(value1, value2,···);
insert into t1 values(1,'hammer') # 插入单个
insert into t1 values(1,'hammer'),(2,'ze'); # 插入多个
# 查看数据
select * from 表名; # 查看所有数据
select 字段名 from 表名;
select name from t1; # 获取t1表中的所有name值
# 修改数据
update 表名 set 字段名='值' where 字段条件
update t1 set name='hammer' where id>1; # id大于1的name修改成hammer
# 删除数据
delete from 表名; # 删除表内所有数据
delete from 表名 where 条件;
delete from t1 where id>1; # 将id>1的数据删除
delete from t1 where name='hammer';
补充:在创建字段的时候可以加上相应的注释
create table t12(
id int comment '序号',
name char(4) comment '姓名'
);
存储引擎
日常生活中文件格式有很多种,针对不同文件的格式会有对应不同存储方式和处理机制,针对不同的数据应该有对应的不同处理机制来存储;
- 存储引擎就是不同的处理机制;
MySQL主要存储引擎
InnoDB:MySQL5.5版本之后默认的存储引擎(默认)MyISAM:MySQL5.5版本之前默认的存储引擎,比InnoDB快,但是InnoDB更安全- memory:内存引擎,数据全部存放在内存中(危险,断电数据丢失,但是快)
- blackhole:无论存储什么,都立刻消失(黑洞)
命令
- 查看所有存储引擎:
show engines;
mysql> show engines;
InnoDB :DEFAULT(默认的) Supports transactions(支持事物), row-levellocking(行锁), and foreign keys(外键)
- 指定引擎
create table 表名(类型,字段) engine=[引擎名]
# 验证不同的存储引擎在存储表的时候,异同点
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=blackhole;
create table t4(id int) engine=memory;
# 文件区别如下图
# 存数据
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
# 重启服务查看
select * from t1;
+------+
| id |
+------+
| 1 |
+------+
select * from t2;
+------+
| id |
+------+
| 1 |
+------+
select * from t3; # 内存中会消失
Empty set (0.00 sec)
select * from t4; # "黑洞"存啥消失啥
Empty set (0.00 sec)

查询条件过滤
- 使用关键字 WHERE 指定查询的过滤条件
- WHERE 位于 FROM 之后,用于指定一个或者多个过滤条件;只有满足条件的数据才会返回,其他数据将被忽略
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 等于 | WHERE emp_id = 1 |
| != | 不等于 | WHERE sex != '男' |
| > | 大于 | WHERE salary > 10000 |
| < | 小于 | WHERE hire_date >= DATE '2018-01-01' |
| >= | 大于等于 | WHERE bonus < 15000 |
| <= | 小于等于 | WHERE dept_id <= 2 |
| BETWEEN | 位于范围之内 | WHERE salary BETWEEN 10000 AND 15000 |
| IN | 属于列表之内 | WHERE emp_name IN ('hammer', 'hans', 'jason') |
- 如何判断某个值是否为空值呢?在 SQL 中需要使用两个特殊的运算符:
expression IS NULL;expression IS NOT NULL;
# 注意判断空值不能使用等于或者不等于;
SELECT emp_name, manager
FROM employee
WHERE manager = NULL; # 这是错误的
这个错误的原因在于将一个值与一个未知的值进行数学比较,结果仍然未知;即使是将两个空值进行比较,结果也是未知;
# 错误示例
NULL = 5;
NULL = NULL;
NULL != NULL;
如果表达式 expression 的值为空,IS NULL 返回真,IS NOT NULL 返回假;如果表达式的值不为空,IS NULL 返回假,IS NOT NULL 返回真;
select * from self_info where id is not null;
+------+--------+
| id | name |
+------+--------+
| 1 | hammer |
| 2 | hans |
+------+--------+
模糊查找
当需要查找的信息不太确定时,例如只记住了某个员工姓名的一部分,可以使用模糊查找的功能进行搜索。SQL 提供了两种模糊匹配的方法:LIKE 运算符和正则表达式函数;
LIKE 用于指定一个模式,并且返回匹配该模式的数据
LIKE运算符
%:百分号可以匹配零个或者多个任意字符-:下划线可以匹配一个任意字符
mysql> select name from self_info where name like '%mmer';
+--------+
| name |
+--------+
| hammer |
+--------+
mysql> select name from self_info where name like 'han_';
+------+
| name |
+------+
| hans |
+------+
转义字符
转义字符可以将通配符“%”和“_”进行转义,将它们当作普通字符使用转义字符\
mysql> select name from self_info where name like '\%';
+------+
| name |
+------+
| % |
+------+
注意::
- MySQL 和 SQL Server 默认不区分 LIKE 中的大小写
- Oracle 和 PostgreSQL 默认区分 LIKE 中的大小写,PostgreSQL 提供了不区分大小写的 ILIKE 运算符
正则表达式
正则表达式用于检索或者替换符合某个模式(规则)的文本
select * from emp where name regexp '^H.*(n|y)$';
严格模式
5.7版本之后默认开启了严格模式,规定多少宽度,就插入多少数据,超出报错
这里是5.6版本设置一下严格模式,保证数据格式的正确性,规定多少存多少
- 查看严格模式:
show variables like "%mode";
mysql> show variables like '%mode';
+----------------------------+------------------------+
| Variable_name | Value |
+----------------------------+------------------------+
| binlogging_impossible_mode | IGNORE_ERROR |
| block_encryption_mode | aes-128-ecb |
| gtid_mode | OFF |
| innodb_autoinc_lock_mode | 1 |
| innodb_strict_mode | OFF |
| pseudo_slave_mode | OFF |
| slave_exec_mode | STRICT |
| sql_mode | NO_ENGINE_SUBSTITUTION |
+----------------------------+------------------------+
修改严格模式(可选)
- 临时修改:
set session - 永久修改:
set global
# 修改严格模式
set global sql_mode = 'STRICT_TRANS_TABLES';
# 取消剔除空格:set global sql_mode = 'STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH';
# 修改完重新登录
创建表的完整语法
格式:create table 表名 (
字段1 类型(宽度) 约束条件,
字段2 类型(宽度) 约束条件,
字段3 类型(宽度) 约束条件
···
)
约束条件:
unsigned 让数字没有正负号
zerofill 多余的使用数字0填充
not null 非空
新增表数据的方式
方式1: 按照字段顺序一一传值
insert into t1 values(1,'Hammer');
方式2: 自定义传值顺序,甚至不传
insert into t1(name,id) values('Hammer',1);
insert into t1(id) values(1);
- 字段名不能重复
- 宽度和约束条件可以选择,宽度有默认值,约束条件可以有多个
- 字段名和字段类型是必须写的
- 最后一行不能有逗号','
宽度是对数据进行限制
mysql> create table t5(name char);
mysql> desc t5; # 宽度默认为1
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| name | char(1) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
insert into t5 values('hammer'); # 插入值
mysql> select *from t5;
+------+
| name |
+------+
| h |
+------+
# 只能插入一个字符,不同版本不同限制,不同效果
# 5.7版本之后默认开启了严格模式,规定多少宽度,就插入多少数据,超出报错
约束条件
desc查看表结构,查看是否可以插入空值
mysql> desc t5;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| name | char(1) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
* null yes:可以插入空值
基本数据类型
每个数据类型都有默认宽度的限制,整型是个特例,比如
int(8),如果设置该宽度,数字超出了8位,有几位就存几位,没超过8位不足的用空格填充至8位
creat table t7(id int(8));
insert into t7 values(1234); # 不足8个用空格填充
insert into t7 values(123456789); # 超过8位也ok
# 用0填充不够得位数
create table t8(id int(8) unsigned zerofill);
# 约束条件位无符号和0填充
insert into t8 values(1);
数值类型
有符号直接加类型即可,无符号关键字
unsigned,0填充关键字zerofill整型字段定义阶段,不需要加括号,默认宽度就够用了
# 有符号
create table 表名(字段 类型);
# 无符号
create table 表名(字段 类型,unsigned);
# 示例
create table t6(id tinyint);
insert into t6(-129),(256);
create table t7(id tinyint,unsigned);
insert into t7 values(-1),(256);
整型(5种)和浮点型(3种)
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
浮点型demo,三种浮点型的精度不一样
float(255,30) # 总共255位,小数占30位
double(255,30) # 总共255位,小数占30位
decimal(255,30) # 总共255位,小数占30位
# 精确度
float < double < decimal
日期和时间类型
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
create table info(
id int,
name varchar(32),
reg_time date,
birth datetime,
study_time time,
join_time year
);
insert into client values(1,'Hammer','2000-11-11','2000-1-21 11:11:11','11:11:11',1999);
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
ps:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符,超出报错
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
枚举与集合类型
- 分类
- 枚举(enum):多选一
- 比如性别选择
- 集合(set):多选多
- 比如爱好选择
- 枚举(enum):多选一
- 使用如下
create table user(
id int,
name varchar(16),
gender enum('male','female','others'), # 枚举类型
hobby set('read','basketball','skiing','baseball','others') # 集合类型
)
# 插入的时候只能插入枚举类型指定的字段
insert into user values(1,'hammer','male'); # 正确的
insert into user values(2,'hans','xx'); # 错误的
# 集合可以写一个或者多个,但是只能写集合定义好的
insert into user values(3,'ze','male','skiing,baseball'); # 正确的
insert into user values(4,'mei','male','eat'); # 不正确的
