Linux 三剑客之awk
 三剑客"老大"awk,教程超级详细,看完就能get!
三剑客"老大"awk,教程超级详细,看完就能get!
目录
Linux 三剑客之awk

简介
awk主要是用来格式化文本,也有人称awk是一种语言,类似 C,awk 是三剑客的老大,利剑出鞘,必会不同凡响。
应用场景
- 过滤,统计,计算,统计日志
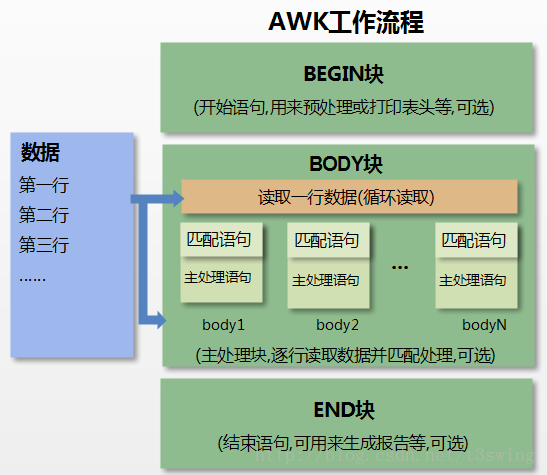
awk执行流程图
-
awk读取文件之前执行BEGIN,注意BEGIN读取文件之前就可以执行,后面不跟文件,也可以执行
# 直接执行BEGIN,不跟文件 [root@localhost ~]# awk 'BEGIN{print "直接执行"}' 直接执行 -
awk读取文件时,执行BODY块
-
awk读取文件后,执行END块
-
格式:
awk [参数] 'BEGIN{读取文件前执行的内容}条件{读取文件执行的动作}END{读取完文件执行的内容}' [文件路径]
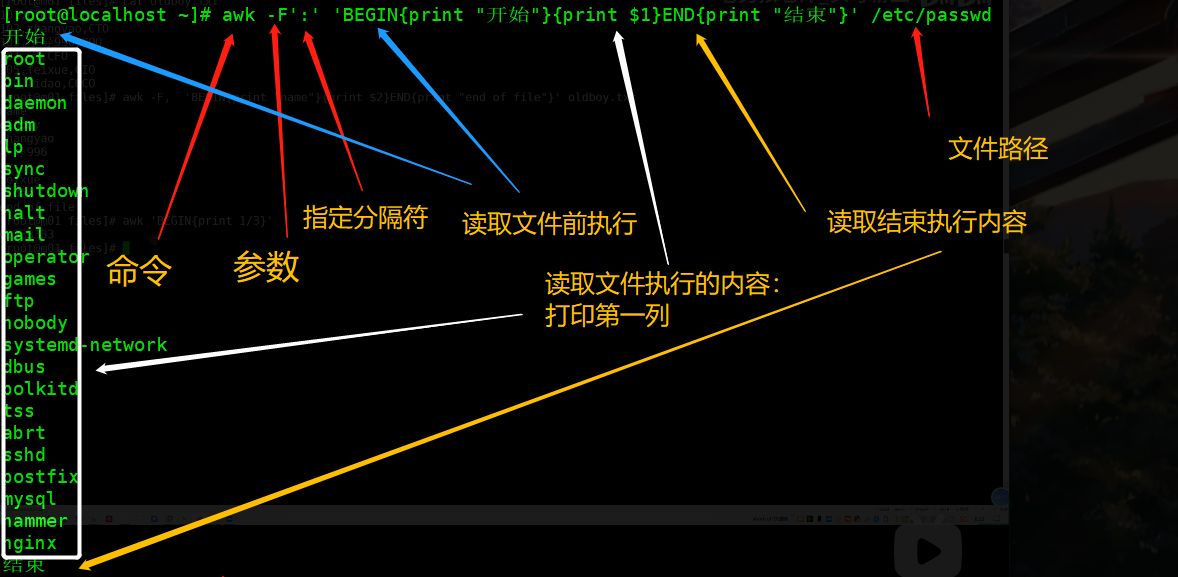
完整流程示例(无条件要求演示):
读取文件前可以加条件,条件包括正则判断等,继续往下看,看完就明白了~
awk生命周期
grep、sed和awk都是读一行处理一行,直至处理完成
# 生命周期如下:
接收一行作为输入
把刚刚读入进来得到文本进行分解
使用处理规则处理文本
输入一行,赋值给$0,直至处理完成($0代表当前行的内容)
把处理完成之后的所有的数据交给END{}来再次处理
awk内置(预定义)变量
| 内置变量符号 | 功能描述 |
|---|---|
| $0 | 代表当前行 |
| $n | 代表第n列 |
| NF | 记录当前行的字段数(当前行的列数),$NF表示最后一列 |
| NR | 用来记录行号(相当于计数器) |
| FS | 指定文本内容字段分隔符(默认是空格) |
| RS | 文本分割符 默认为换行符 |
| OFS | 指定打印字段分隔符(默认空格) |
| ORS | 输出的记录分隔符 默认为换行符 |
行与列描述
| 名称 | 描述 | 说明 |
|---|---|---|
| 行 | 记录record | 每一行结尾默认通过回车分隔 |
| 列 | 记录字段/域field | 列与列默认以空格分隔,可以指定分隔符 |
取行#
| awk取行字符 | 描述 |
|---|---|
| NR==1 | 取出第1行 |
| NR>=1&&NR<=5 | 取出1到5行 ---范围取 |
| //,// | 正则取,谁开头到谁结尾 |
| 符号 | > < >= <= == != |
# 输出第一行
[root@localhost ~]# awk 'NR==1' a.sh
asdfgdghgf aadadadad
# 输出1到5行
[root@localhost ~]# awk 'NR>=1&&NR<=5{print NR,$0}' a.sh
1 asdfgdghgf aadadadad
2 sdasdasda hjhjjg
3 asd adas sdasdas asdasdahgf
4 asdas asdasdad adasdasd
5 baaaaaaaaaaaaaaaaaaaabbbbbbbb
# 正则取,h开头的行,到m开头的行
[root@localhost ~]# cat a.sh | nl
1 hammerze
2 hanswang
3 jianiubi
4 guangtou
5 meimei
6 zhengyu
7 xuegongzi
[root@localhost ~]# awk '/^h/,/^m/ {print NR,$0}' a.sh
1 hammerze
2 hanswang
3 jianiubi
4 guangtou
5 meimei
取列#
-F:指定分隔符,指定每一列结束标记(默认是空格,连续的空格Tab键),-F后也支持正则(案例4)-v:修改变量- $数字:表示取出某一列
$0:表示整行的内容- 补充知识:
column -t格式化输出,美化操作

awk '{print $0}' a.sh输出的内容和cat的效果一样
[root@localhost ~]# awk '{print $0}' a.sh
hammerze
hanswang
jianiubi
guangtou
meimei
zhengyu
xuegongzi
[root@localhost ~]# cat a.sh
hammerze
hanswang
jianiubi
guangtou
meimei
zhengyu
xuegongzi
案例1:取出/etc/passwd文件中的第一列和最后一列
# 为例节省占用文章空间,这里输出5行
[root@localhost ~]# awk -F: '{print NR,$1,$NF}' /etc/passwd | column -t | head -n5
1 root /bin/bash
2 bin /sbin/nologin
3 daemon /sbin/nologin
4 adm /sbin/nologin
5 lp /sbin/nologin
案例2:美化操作
[root@localhost ~]# awk -F: '{print NR,"用户名:"$1,"解释器:"$NF}' /etc/passwd | column -t | head -n5
1 用户名:root 解释器:/bin/bash
2 用户名:bin 解释器:/sbin/nologin
3 用户名:daemon 解释器:/sbin/nologin
4 用户名:adm 解释器:/sbin/nologin
5 用户名:lp 解释器:/sbin/nologin
案例3:将/etc/passwd文件的最后一列和第一列互换位置
[root@localhost ~]# awk -F':' '{print $NF,$2,$3,$4,$5,$6,$1}' /etc/passwd | head -n5
/bin/bash x 0 0 root /root root
/sbin/nologin x 1 1 bin /bin bin
/sbin/nologin x 2 2 daemon /sbin daemon
/sbin/nologin x 3 4 adm /var/adm adm
/sbin/nologin x 4 7 lp /var/spool/lpd lp
# 这样得到的结果,和原来文件内容不一样缺少冒号
# 用-vOFS=:,这样空格就修改称原来的冒号就加回来了,`-F: == -vOFS=:`
[root@localhost ~]# awk -F: -vOFS=: '{print $NF,$2,$3,$4,$5,$6,$1}' /etc/passwd | head -n5
/bin/bash:x:0:0:root:/root:root
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
/sbin/nologin:x:3:4:adm:/var/adm:adm
/sbin/nologin:x:4:7:lp:/var/spool/lpd:lp
案例4:取行和取列实现了文本内容“指哪打哪”,取行又取列
# 精确取ip
[root@localhost ~]# ip a | awk -F "[ /]+" 'NR==3{print $3}'
127.0.0.1
# 剖析命令
awk : 命令
-F"[ /]+" : 选项
NR==3: 条件
{print $3} : 模式(动作)
取行和取列主要用到的是比较,大于小于等于···
awk中的函数
- print函数:打印
- printf函数:格式化打印
函数搭配字符
| 搭配字符 | 功能 |
|---|---|
| %s | 代表字符串 |
| %d | 代表数字 |
| - | 左对齐 |
| + | 右对齐 |
| n | 占用字符 eg:15代表占用15个字符长度 |
# 格式化输出,以|为分隔符,换行对齐输出,没有空格补齐,超出就怼出去
[root@localhost ~]# awk -F: 'BEGIN{OFS=" | "}{printf "|%+15s|%-15s|\n", $NF,$1}' /etc/passwd
# OFS输出分隔符,上面的结果打印5行看看
[root@localhost ~]# awk -F: 'BEGIN{OFS=" | "}{printf "|%+15s|%-15s|\n", $NF,$1}' /etc/passwd |head -n5
| /bin/bash|root |
| /sbin/nologin|bin |
| /sbin/nologin|daemon |
| /sbin/nologin|adm |
| /sbin/nologin|lp |
条件的分类
运算符参考表
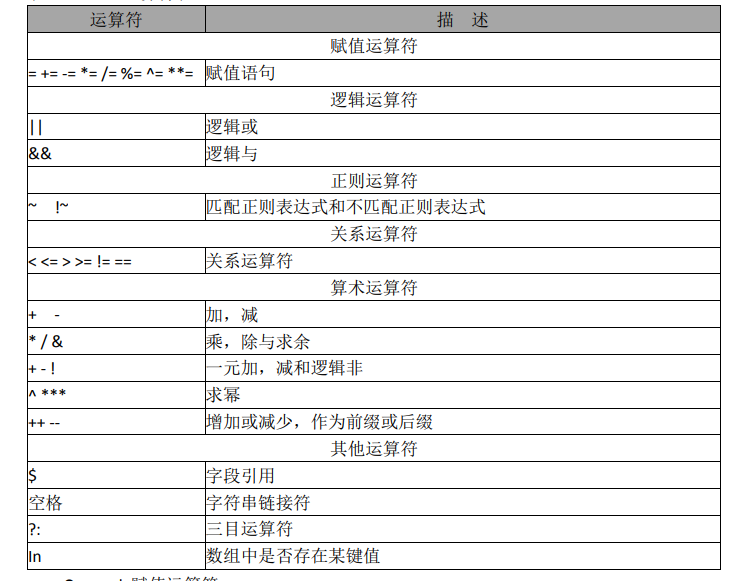
格式:
awk [参数] 'BEGIN{读取文件前执行的内容}条件{读取文件执行的动作}END{读取完文件执行的内容}' [文件路径]awk中的条件有如下的操作👇
awk正则详细:#
//内写正则- awk正则可以精确到某一行,某一列中包含什么内容,或这行不包含什么内容
~:包含!~:不包含
普通正则和awk正则区别#
| 正则 | awk正则 | 示例 |
|---|---|---|
^ 代表以什么开头的行 |
某一列的开头 | $3~/^hammer/:第三列以hammer开头的行 |
| **` | 正则 | awk正则 |
| -------------------------- | ---------------- | ------------------------------------------ |
代表以什么结尾的行** | 某一列的结尾 | $3~/hammer$/:第三列以hammer结尾的行 |
||
| ^$ 代表空行 | 某一列是空的 |
# 第三列以1开头的行
[root@localhost ~]# awk -F: '$3~/^1/{print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
hammer:x:1000:1000::/home/hammer:/bin/bash
# 第三列以1或者2开头的行,用|表示或注意写法,不要写成^1|2,写成^(1|2)
[root@localhost ~]# awk -F: '$3~/^[12]/{print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
hammer:x:1000:1000::/home/hammer:/bin/bash
# 最后一列以bash结尾的行
[root@localhost ~]# awk -F: '$NF~/bash$/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
hammer:x:1000:1000::/home/hammer:/bin/bash
范围表达式#
/哪里开始/哪里结束/-- 字符取范围,也是正则,经常用NR==1,NR==5:数字表示范围,第一行开始到第五行结束,类似sed -n '1,5p'
# 从root开头的行开始,到以ftp开头的行结束
[root@localhost ~]# awk -F: '/^root/,/^ftp/{print $0}' /etc/passwd
# 从第一行开始到第五行结束
[root@localhost ~]# awk -F: 'NR==1,NR==5' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
逻辑表达式#
&&:逻辑与||:逻辑或|:逻辑非
[root@localhost ~]# awk -F: '$3 + $4 > 2000 && $3 * $4 > 2000{print $0}' /etc/passwd
[root@localhost ~]# awk -F: '$3 + $4 > 2000 || $3 * $4 > 2000{print $0}' /etc/passwd
[root@localhost ~]# awk -F: '!($3 + $4 > 2000){print $0}' /etc/passwd
算术表达式#
+:加-:减*:乘/:除%:取模
案例:要求属组 + 属主的ID 大于 2000
[root@localhost ~]# awk -F: '$3 + $4 > 2000{print $0}' /etc/passwd
案例:要求属组 * 属主的ID 大于 2000
[root@localhost ~]# awk -F: '$3 * $4 > 2000{print $0}' /etc/passwd
案例:要求打印偶数行
[root@localhost ~]# awk -F: 'NR % 2 == 0{print $0}' /etc/passwd
案例:要求打印奇数行
[root@localhost ~]# awk -F: 'NR % 2 == 1{print $0}' /etc/passwd
案例:要求每隔5行打印-------
[root@localhost ~]# awk -F: '{if(NR%5==0){print "----------------"}print $0}' /etc/passwd
特殊模式BEGIN{}和END{}
| 模式 | 含义 | 应用场景 |
|---|---|---|
| BEGIN | awk读文件之前执行 | 1、进行统计,变量初始化,不涉及读取文件等 2、处理文件之前添加表头 3、用来定义awk变量(不常用) |
| END | awk读文件之后执行 | 1、用来接收前面的结果,统计输出结果(常用) 2、awk使用数组,用来接收和输出数组的结果(常用) |
- END{}用于统计计算
- 统计方法如下
| 统计方法 | 简写 | 描述 | 示例描述 |
|---|---|---|---|
| i=i+1 | i++ | 计数,统计次数 | 1-100一共几个数 |
| sum = sum+数值 | sum+=数值 | 求和,累加 | 前100n项和 |
| 注意,i和sum都是变量随便写 |
# 统计/etc/services里面的空行个数
[root@localhost ~]# awk '/^$/' /etc/services | wc -l
17
# 用累计的方式统计空行
[root@localhost ~]# awk '/^$/{i++}END{print i}' /etc/services
17
# 显示累计过程
[root@localhost ~]# awk '/^$/{i++;print i}' /etc/services
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 求和示例,100前n项和
[root@localhost ~]# seq 100 | awk '{sum=sum+$1}END{print sum}'
5050
可以把END前{}理解为
循环
awk数组
主要应用场景如下👇
- 统计日志:主要应用为统计日志,类似于统计每个ip出现次数,统计每种状态码出现的次数·····
- 累加求和,统计
| awk数组 | 形式 | 使用 | |
|---|---|---|---|
| 格式:arry[] | arry[0]=hammer arry[1]=ze | print arry[0] arry[1] | |
| 批量输出数组内容 | for(i in arry) | print i (i是数组下标) print arry[i] (这样是打印数组内容) |
|
| 文件用数组统计 | arry[$列号]++ | for (i in arry) print i,arry[i] |
arry[]++,统计什么就写到[]内,如果统计出现次数,arry[i]代表次数,i代表内容 |
[root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";print a[0],a[1]}'
hammer ze
# 注意,数组赋值字母要用引号,不然会被认为是变量,数字没事
# 批量输出
# 打印i显示行号
[root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print i }'
0
1
# 打印a[i]显示数组内容
[root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print a[i]}'
hammer
ze
# 整体显示
[root@localhost ~]# awk 'BEGIN{a[0]="hammer";a[1]="ze";for (i in a) print i,a[i]}'
0 hammer
1 ze
# 数组统计出现次数,看前五行
[root@localhost log]# awk '{a[$NF]++;}END{for(i in a) print i,a[i]}' messages |sort -rnk2|head -n5
0 1220
lint[0x1]) 1152
disabled) 1143
0x1000] 756
registered 450
区别shell数组
| shell数组 | 形式 | 使用 |
|---|---|---|
| 格式:arry[] | arry[0]=hammer arry[1]=ze | echo $ |
awk 的 判断、循环
if循环#
-
格式:
- 单分支:if(条件){执行命令}
- 双分支:if(条件){执行命令}else{}
- 多分支: if(){}else if(){}else{}
[root@localhost /]# awk '{if(NR%2==1)print NR,$0}' /root/a.sh
[root@localhost /]# awk 'NR%2==1{print NR,$0}' /root/a.sh
1 asdfgdghgf aadadadad
3 asd adas sdasdas asdasdahgf
5 baaaaaaaaaaaaaaaaaaaabbbbbbbb
7 ppppp
9 das1231423434gfdgfgfdgdf
11 s1111ssss asdsgfh
13 sagdfg3356fff
循环#
-
for循环和while循环
-
格式:
-
for循环格式:
for(i="初始值";条件判断;游标){} -
while格式:
while(条件判断){}
-
# for循环示例
[root@localhost log]# awk 'BEGIN{for (i=1;i<=100;i++)sum+=i;print sum}'
5050
[root@localhost ~]# awk -F: '{for(i=10;i>0;i--){print $0}}' /etc/passwd
# while循环示例
[root@localhost ~]# awk -F: '{i=1; while(i<10){print $0, i++}}' /etc/passwd
总体练习
# -F参数的使用,打印/etc/passwd第1列
[root@localhost ~]# awk -F":" '{ print $1 }' /etc/passwd
# 打印/etc/passwd的第1列和第三列
[root@localhost ~]# awk -F":" '{ print $1 $3}' /etc/passwd
# 打印/etc/passwd的第一列和第三列,列中间输出'-'
[root@localhost ~]# awk -F":" '{ print $1 "-" $3 }' /etc/passwd
# 格式化输出用户名和uid
[root@localhost ~]# awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd|column -t
#知识补充:column -t 格式化,美化输出,打印几行看看效果
[root@localhost ~]# awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd|column -t | head -n 5
username: root uid:0
username: bin uid:1
username: daemon uid:2
username: adm uid:3
username: lp uid:4
# 要求打印属组ID大于属主ID的行
[root@localhost ~]# awk -F: '$4 > $3{print $0}' /etc/passwd
# 结尾包含bash
[root@localhost ~]# awk -F: '$NF ~ /bash/{print $0}' /etc/passwd
# 结尾不包含bash
[root@localhost ~]# awk -F: '$NF !~ /bash/{print $0}' /etc/passwd
内置变量示例如下:
# $0与NR变量的使用,$0代表当前行
[root@localhost ~]# awk -F: 'NR == 2{print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
# $n的使用
[root@localhost ~]# awk -F: '{print $1}' /etc/passwd|head -n 5
root
bin
daemon
adm
lp
# NF的使用
[root@localhost ~]# awk -F: '{print NF}' /etc/passwd|head -n5
7
7
7
7
7
[root@localhost ~]# awk -F: 'NF==7{print $1}' /etc/passwd|head -n5
root
bin
daemon
adm
lp
# NR的使用
[root@localhost ~]# awk -F: '{print NR}' /etc/passwd|head -n5
1
2
3
4
5
[root@localhost ~]# awk -F: 'NR==5{print $0}' /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# FS的使用(指定冒号,但是优先级比-F的高)
[root@localhost ~]# awk 'BEGIN{FS=":"}{print $NF, $1}' /etc/passwd|head -n5
/bin/bash root
/sbin/nologin bin
/sbin/nologin daemon
/sbin/nologin adm
/sbin/nologin lp
# OFS的使用
[root@localhost ~]# awk -F: 'BEGIN{OFS=" 嘿"}{print $1, $2}' /etc/passwd|head -n5
root 嘿x
bin 嘿x
daemon 嘿x
adm 嘿x
lp 嘿x
易错点:
- 字段分隔符要指定,单个字符的时候有时候可以不指定,比如冒号;
- {}外单引号内要用双引号;
-F如果不指定分隔符建议不要写FS指定分隔符建议不要写-F,防止冲突- 三剑客中是对行操作,不要混淆
- 数组赋值字母要用引号,不然会被认为是变量,数字没事





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!