python 内置模块
 python内置模块,超级超级详细!re模块,time模块,datatime模块···10分钟get(小白必看)!
python内置模块,超级超级详细!re模块,time模块,datatime模块···10分钟get(小白必看)!

python 内置模块
取消转义的两种方法:
由于\加字符有很多的特殊含义,比如\n是换行符,我们不想让它换行可以用以下两种方法取消转义
- \ \n
- r\n
*单独写正则表达式的时候在转义字符前加 r 一般不识别,在python中推荐使用加 r 的方法,单独写正则推荐使用双*
1、re模块(重点)
上篇介绍了正则表达式,在python中想要使用正则表达式,一般和内置模块re一块使用,下面介绍以下re模块的基本使用方法
1、re 模块的基本操作方法
re模块常用的方法
-
findall():根据正则匹配所有符合条件的数据,匹配成功返回list,如果没有匹配到返回空列表。
-
search():根据正则匹配到一个符合条件的就结束,查看结果需要用group()方法,如果没有符合条件的数据,那么返回None,没有符合条件的数据再使用group()会报错。
-
match():根据正则从头开始匹配,相当于正则表达式中的^,文本内容必须在开头匹配上,如果没有符合条件的数据,那么match返回None,并且使用group会直接报错
-
split():根据匹配的字符串进行分割
-
sub():替换正则匹配到的内容,如果不写替换的个数默认替换所有,返回替换之后的字符串
-
subn():和sub方法功能一样,结果返回元组,并提示换了几处
-
compile():在需要匹配相同正则表达式情况下, 事先定义一个compile可以简化代码量,可以多次多次调用compile()返回的结果
-
finditer():和findall方法一样,返回的结果是一个iterator,需要遍历输出
2、re 模块方法示例:
1.findall()方法
-
定义:findall根据正则匹配所有符合条件的数据,匹配成功返回list,如果没有匹配到返回空列表。
-
格式:findall(pattern, string, flags=0)
示例如下:
import re
# findall示例:
# 有匹配结果
res = re.findall('a.','abcaaa,ccc,abcd123')
print(res)
# 无匹配结果
res1 = re.findall('z','abc,123,df,eg,edg,456qqq')
print(res1)
# 结果
['ab', 'aa', 'a,', 'ab']
[]
2、search()方法
-
定义:search根据正则匹配到一个符合条件的就结束,查看结果需要用group()方法,如果没有符合条件的数据,那么返回None,没有符合条件的数据再使用group()会报错。
-
格式:search(pattern, string, flags=0)
示例如下:
import re
# search示例:
# 有匹配结果
res = re.search('a','Hammer,Alien,Tony')
print(res) # 返回match对象<_sre.SRE_Match object; span=(1, 2), match='a'>
print(res.group()) # 匹配到一个就结束,Hammer中的a
# 无匹配结果
res1 = re.search('b','Hammer,Alien,Tony')
print(res1) # 返回None
print(res1.group()) # 报错
# 结果
<_sre.SRE_Match object; span=(1, 2), match='a'>
a
None
AttributeError: 'NoneType' object has no attribute 'group'
3、match()方法
-
定义:match根据正则从头开始匹配,相当于正则表达式中的^,文本内容必须在开头匹配上,如果没有符合条件的数据,那么match返回None,并且使用group会直接报错
-
格式:match(pattern, string, flags=0)
示例如下:
import re
# match示例:
# 有匹配结果
res = re.match('a','abc,bcd,efg')
print(res)
print(res.group())
# 无匹配结果
res1 = re.match('b','zxc,vbn,nmk')
print(res1)
print(res1.group()) # 没有匹配结果使用group报错
# 结果
<_sre.SRE_Match object; span=(0, 1), match='a'>
a
None
4、split()方法
- 定义:split根据匹配的字符串进行分割
- 格式:split(pattern, string, maxsplit=0, flags=0)
示例如下:
import re
# split示例:
# 有匹配结果
res = re.split('ab','ab,abc,abcd') # 会根据待匹配字符中的ab切分成不同的空字符串
print(res)
# 无匹配结果:原样返回,组织成列表
res1 = re.split('zq','ab,abc,abcd') # 会根据待匹配字符中的ab切分成不同的空字符串
print(res1)
# 结果
['', ',', 'c,', 'cd']
['ab,abc,abcd']
5、sub()方法
-
定义:替换正则匹配到的内容,如果不写替换的个数默认替换所有,返回替换之后的字符串
-
格式:sub(pattern, repl, string, count=0, flags=0)
示例如下:
import re
# sub示例:
# 有匹配结果
res = re.sub('\d','Ze','HammerZe9854') # 将数字替换成Ze
print(res)
# 更改替换个数
two_change = re.sub('\d','Ze','HammerZe9854',2) # 替换两个数字
print(two_change)
# 无匹配结果
res1 = re.sub('\d','Ze','HammerZe') # 将数字替换成Ze
print(res1) # 没有可匹配的数字,原样输出
# 结果
HammerZeZeZeZeZe
HammerZeZeZe54
HammerZe
6、sunb()方法
- 定义:替换正则匹配到的内容,如果不写替换的个数默认替换所有,返回替换之后的字符串
- 格式: subn(pattern, repl, string, count=0, flags=0)
示例如下:
import re
# subn示例:
# 有匹配结果
res = re.subn('\d','Ze','HammerZe9854') # 将数字替换成Ze
print(res)
# 更改替换个数
two_change = re.subn('\d','Ze','HammerZe9854',2) # 替换两个数字
print(two_change)
# 无匹配结果
res1 = re.subn('\d','Ze','HammerZe') # 将数字替换成Ze
print(res1) # 没有可匹配的数字,原样输出
# 结果
('HammerZeZeZeZeZe', 4)
('HammerZeZeZe54', 2)
('HammerZe', 0)
7、compile()方法
-
定义:在需要匹配相同正则表达式情况下, 事先定义一个compile可以简化代码量,可以多次多次调用compile()返回的结果
-
格式:compile(pattern, flags=0)
示例如下:
# compile示例
re_exp = re.compile('\d*') # 编写公用正则公式
res = re.match(re_exp, '1aa,2bb,3cc') # 返回开头数字
print(res.group())
res1 = re.findall(re_exp, '1aa,2bb,3cc')
print(res1)
res2 = re.search(re_exp, '1aa,2bb,3cc') # 遇到一个符合的就结束
print(res2.group())
# 结果
1
['1', '', '', '', '2', '', '', '', '3', '', '', '']
1
8、finditer()方法
-
定义:和findall方法一样,返回的结果是一个iterator,需要遍历输出
-
格式:finditer(pattern, string, flags=0)
示例如下:
import re
res = re.finditer('\d+','HammerZe123,HammerZe456,HammerZE789')
print([i.group() for i in res])
res1 = re.findall('\d+','HammerZe123,HammerZe456,HammerZE789')
print(res1)
# 结果,一毛一样,前者会节省资源,遍历才能输出
['123', '456', '789']
['123', '456', '789']
3、无名分组、有名分组
刚才描述的案例基本没有分组,下面的内容介绍分组后,通过正则匹配是有先后展示顺序的,分组可以通过小括号分组!
无名分组:
- 没有分组的情况,返回的就是正则匹配的结果
- 有分组的情况,优先返回分组的内容
- 无名分组的取值方式可以通过group(n),n为输出第几组的值
- 取消分组优先展示,只需在括号首位添加?:
示例如下:
import re
# 匹配身份证号的案例
# findall针对分组优先展示 无名分组
res = re.findall("^[1-9]\d{14}(\d{2}[0-9x])?$",'110105199812067023')
print(res) # ['023']
# 取消分组优先展示 无名分组
res1 = re.findall("^[1-9](?:\d{14})(?:\d{2}[0-9x])?$",'110105199812067023')
print(res1)
# 结果
['023']
['110105199812067023']
只有findall有分组优先展示
有名分组:
- 格式:(?P
正则表达式) - 可以通过group(name)方法按名字标签输出
示例如下:
import re
# 匹配身份证号的案例
# 有名分组
res = re.search('^[1-9](?P<name1>\d{14})(?P<name2>\d{2}[0-9x])?$','110105199812067023')
print(res)
print(res.group()) # 110105199812067023
print(res.group(1)) # 10105199812067 无名分组的取值方式(索引取)
print(res.group('name1'))
print(res.group('name2'))
# 结果
<_sre.SRE_Match object; span=(0, 18), match='110105199812067023'>
110105199812067023
10105199812067
10105199812067
023
re 模块实战(爬虫)
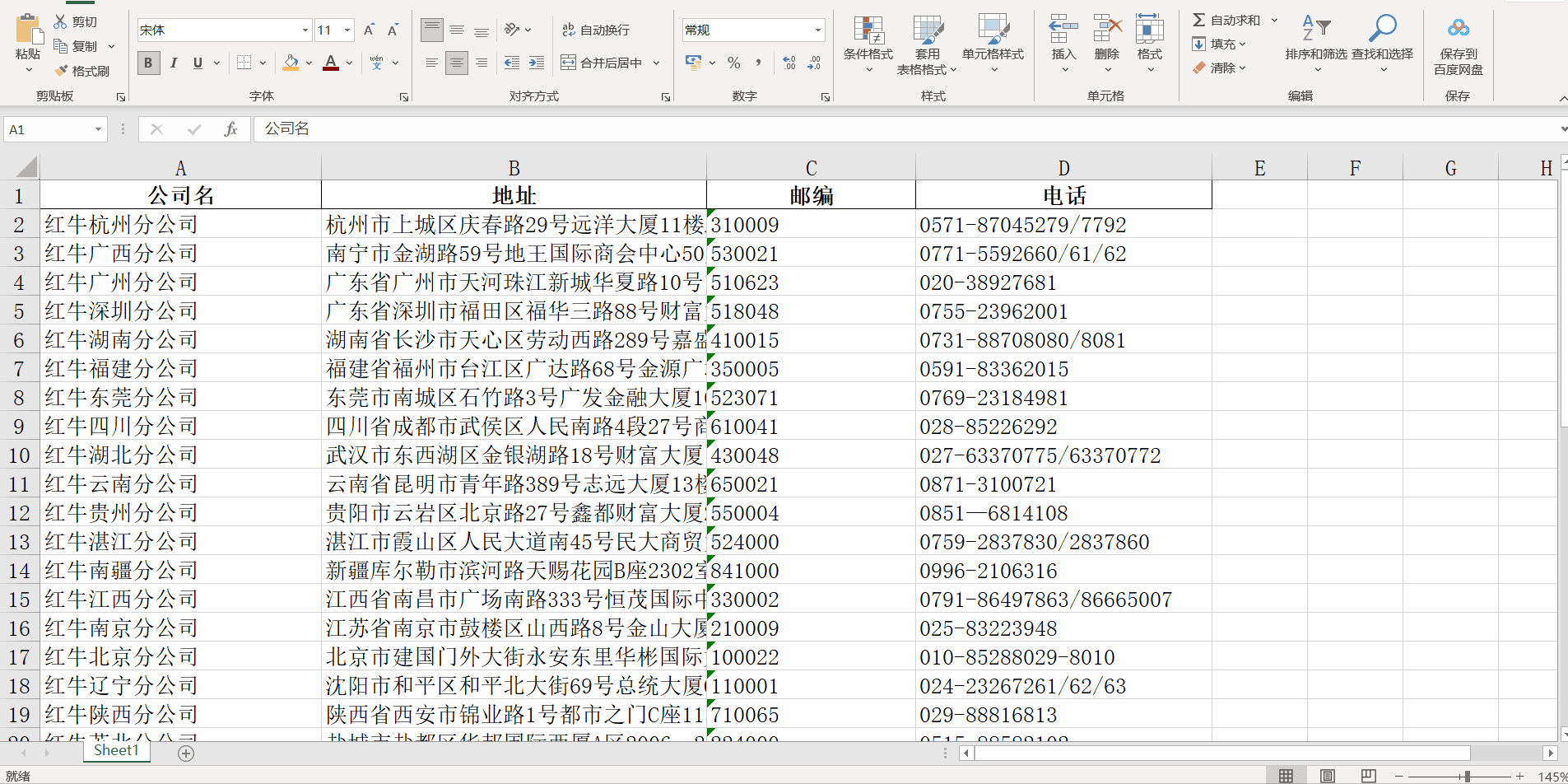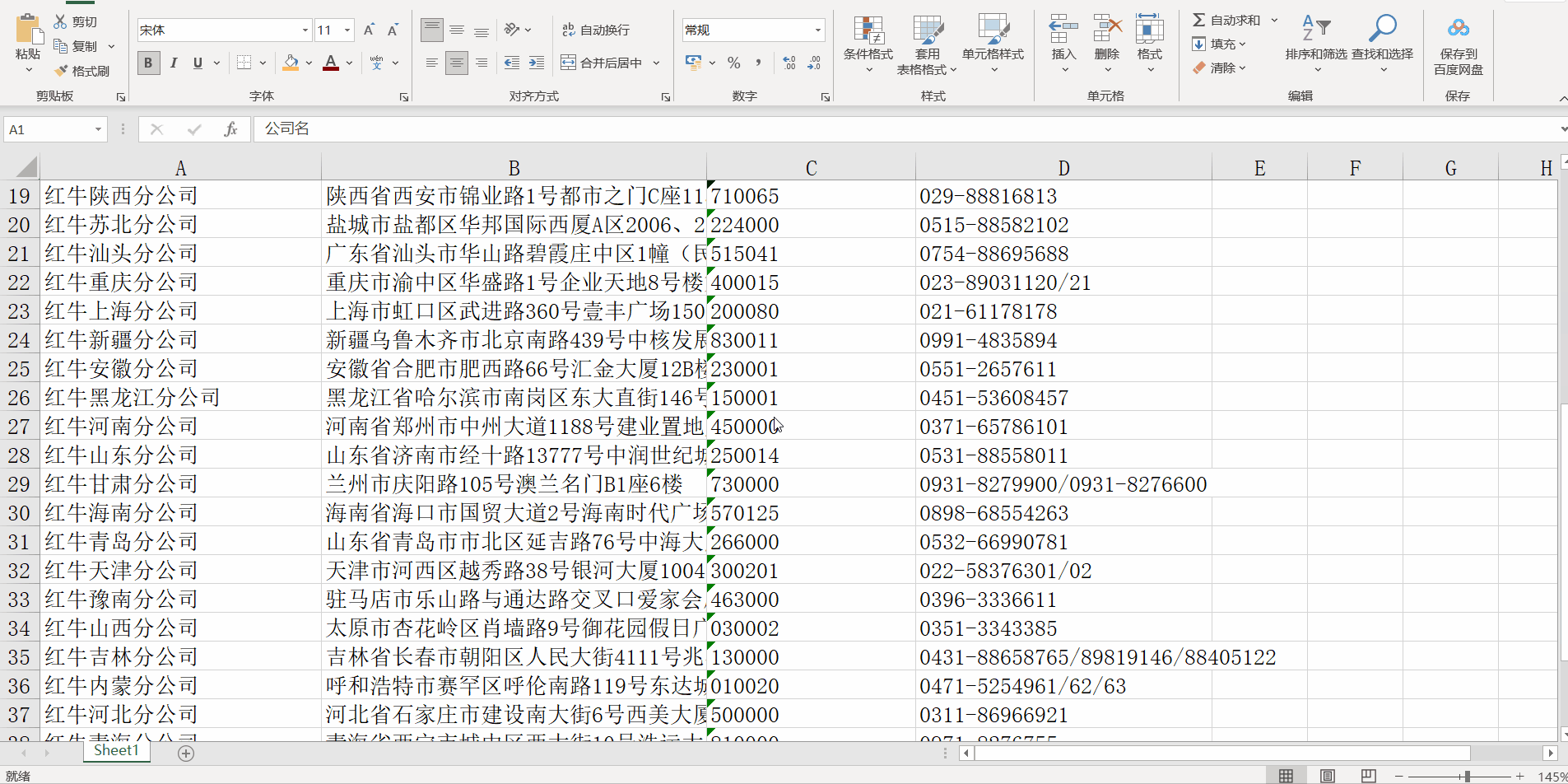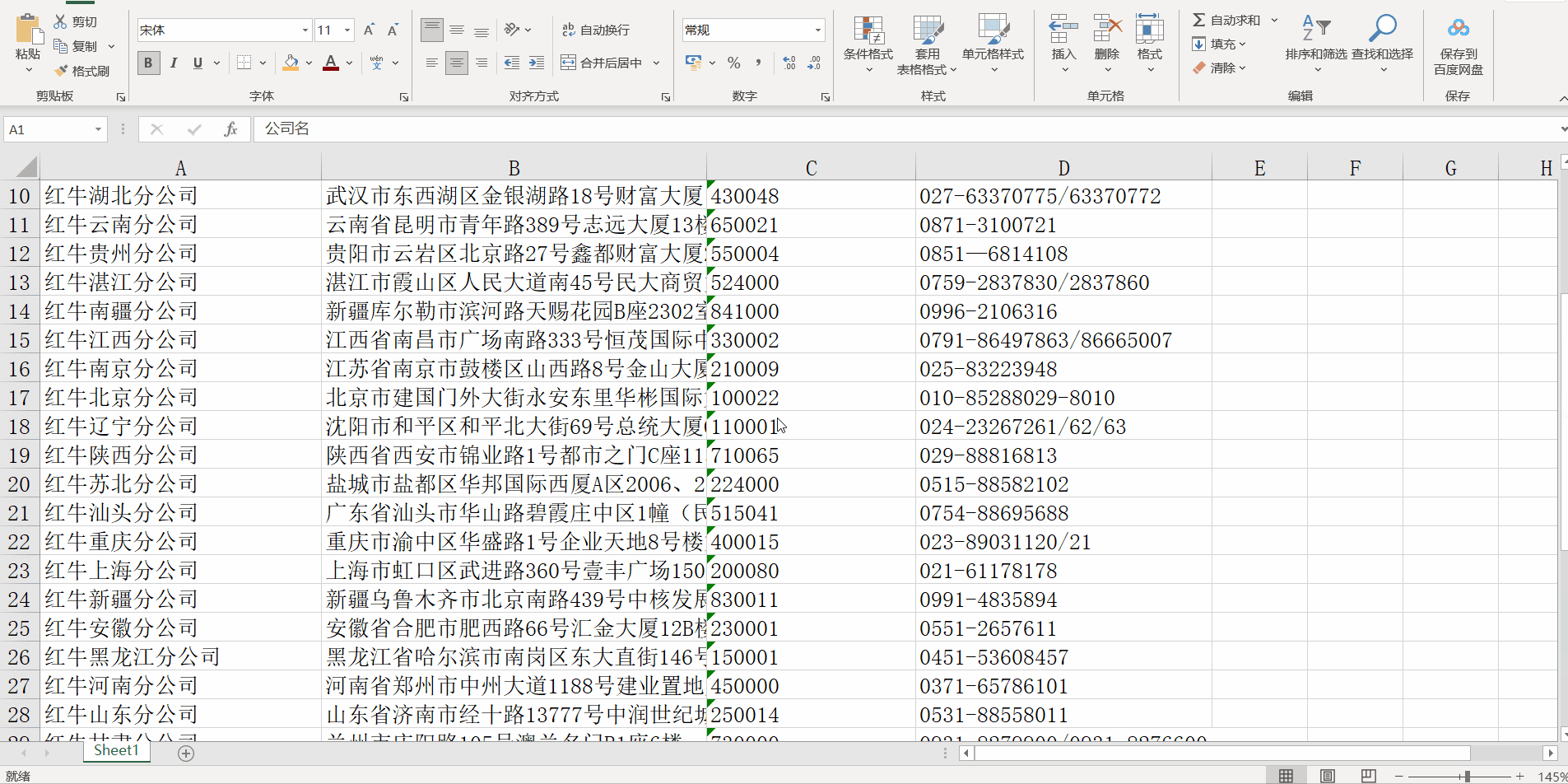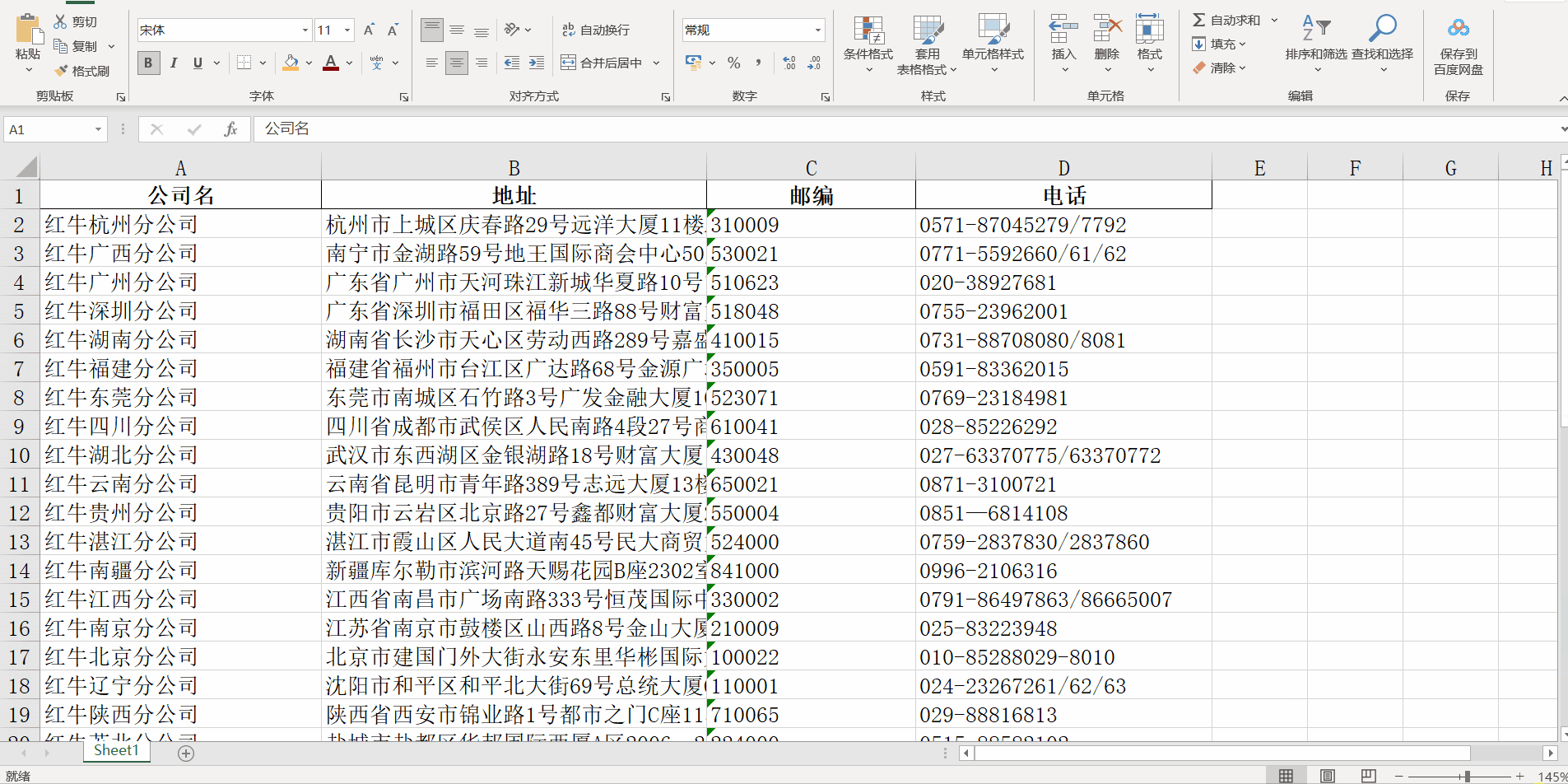
爬取红牛分公司信息案例:
- 打开url查看网页源码分析标签规律:
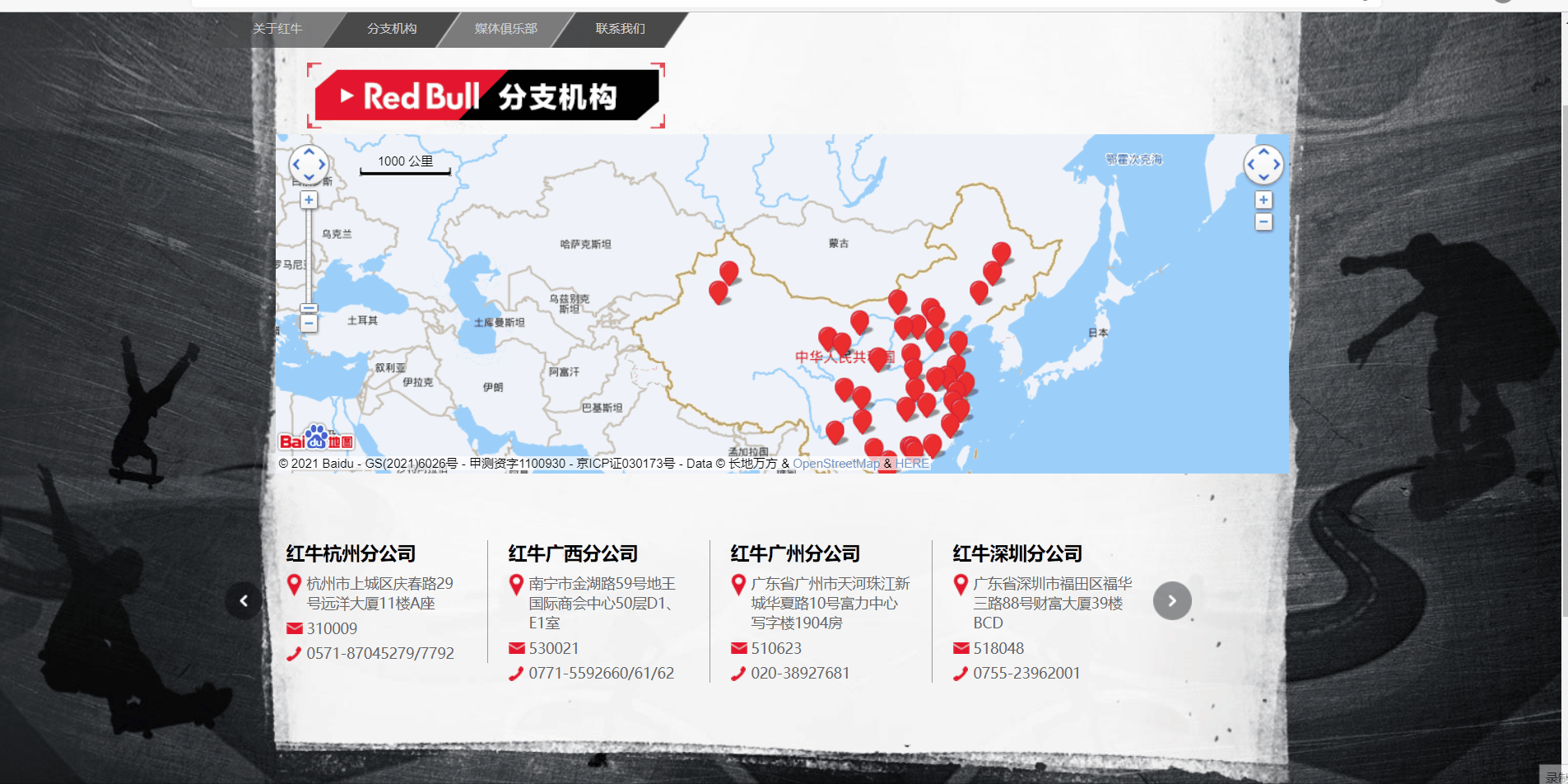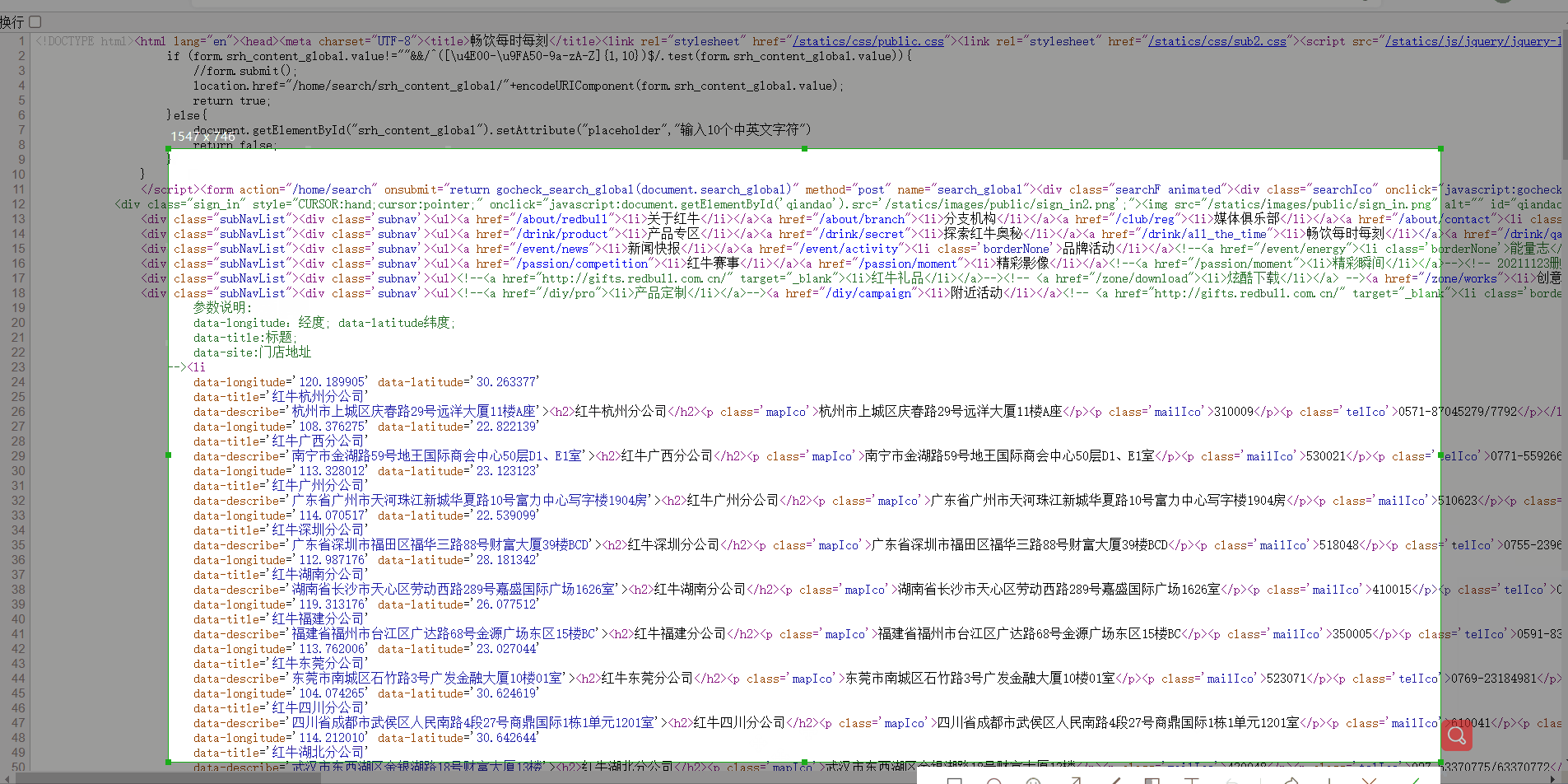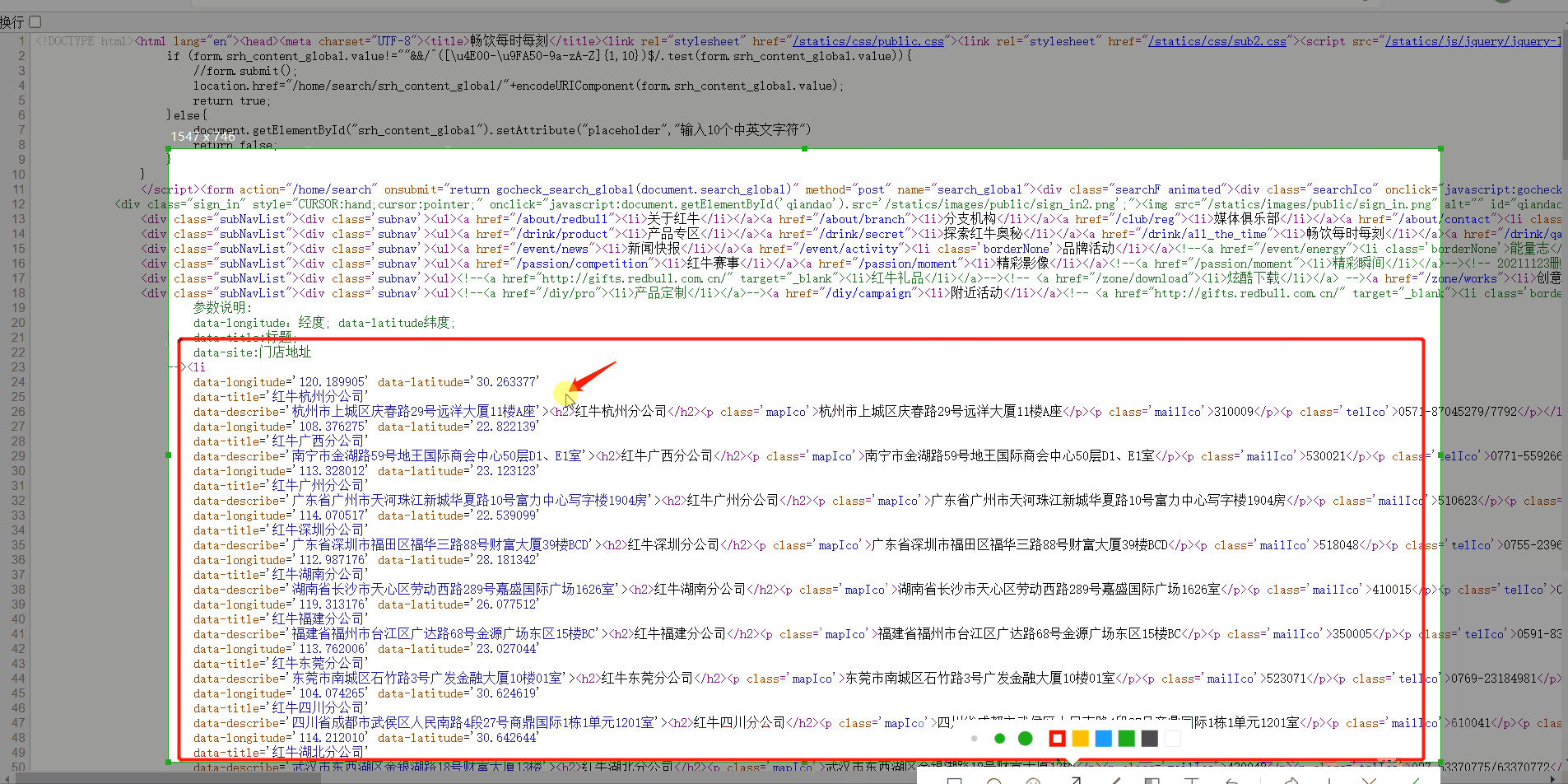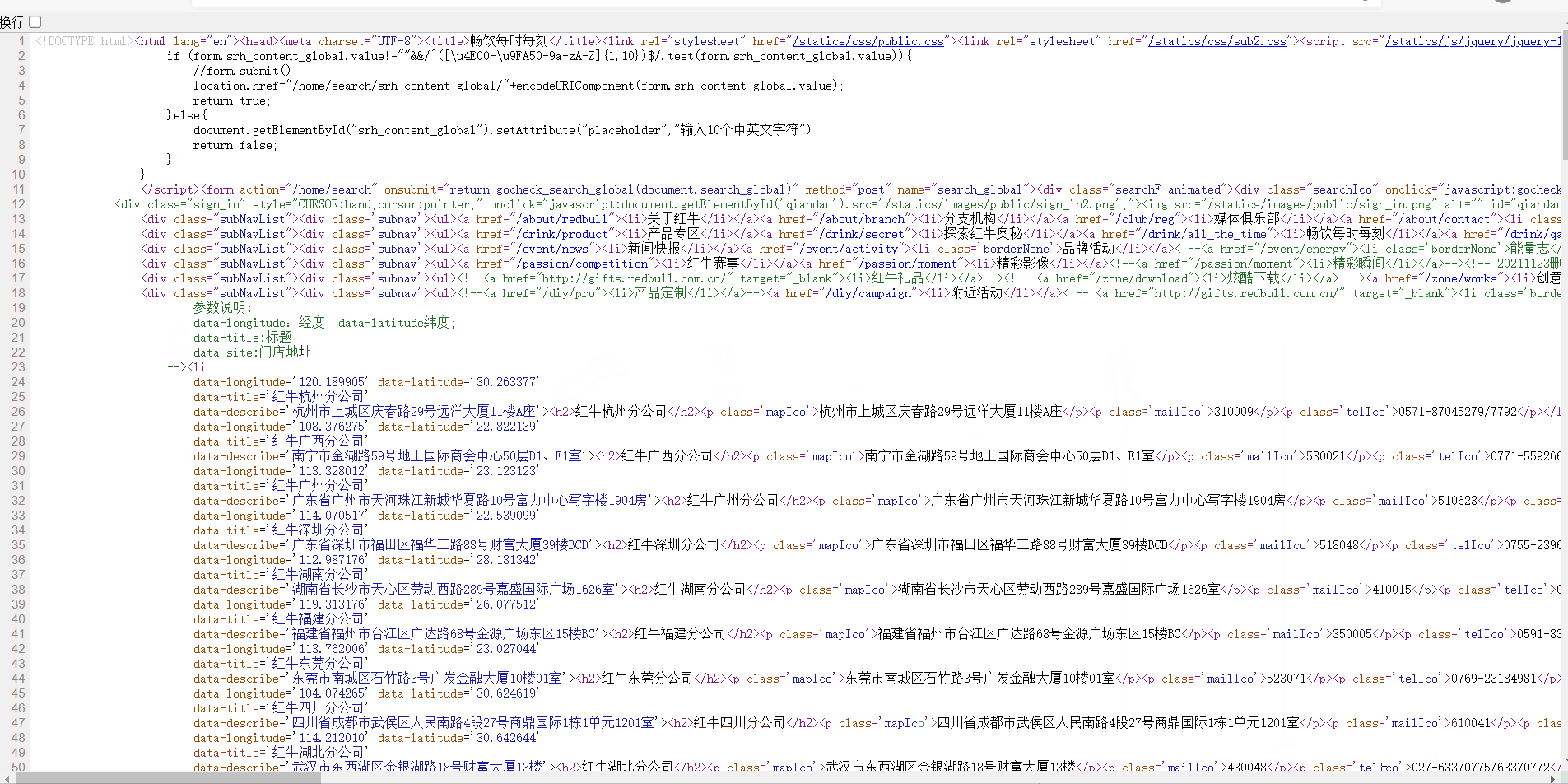
- 代码实现:
import re
import pandas as pd
import requests
url = 'http://www.redbull.com.cn/about/branch'
response = requests.get(url)
# print(response) <Response [200]>
# 分公司名称,页面源码<h2>红牛杭州分公司</h2>
get_company_name = re.findall('<h2>(.*?)</h2>', response.text)
# 地址:<p class='mapIco'>杭州市上城区庆春路29号远洋大厦11楼A座</p>
get_company_addre = re.findall("<p class='mapIco'>(.*?)</p>", response.text)
# 邮编:<p class='mailIco'>310009</p>
get_company_post = re.findall("<p class='mailIco'>(.*?)</p>", response.text)
# 电话:<p class='telIco'>020-38927681</p>
get_company_telephone = re.findall("<p class='telIco'>(.*?)</p>", response.text)
# 调整爬取的信息结构
company_info = pd.DataFrame({'公司名': get_company_name, '地址': get_company_addre,
'邮编': get_company_post, '电话': get_company_telephone})
# 存到excel表里
company_info.to_excel(excel_writer=r"db\redbull_info.xlsx", index=None)
# 查看部分公司信息
line = company_info.head(10)
print(line)
# 结果查看elcel表格
2、time模块
在python中与时间相关的模块主要有time模块和datatime模块,下面分别介绍一下这两个模块
1、调用模块之前需要掌握的理论知识:
-
时间戳:时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
-
世界标准时间:全球24个时区,中国所在为东八区,UTC+8,夏令时DST。
- 👉[24时区划分](世界时区划分时差在线查询计算_时间换算器 (beijing-time.org))
- 👉[夏令时DST](夏令时_百度百科 (baidu.com))
-
元组方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。
2、时间三种表现形式
- 时间戳:timestamp
- 结构化时间:strut_time
- 格式化时间:format time
注·三种时间可以相互转换

结构化表现常用格式:
- 年-月-日:%Y-%m-%d
- 时:分:秒:%H:%M:%S 或 %X
实例如下:
import time
# 获取时间戳
print(time.time()) # 1637838298.6971347
# 结构化时间戳
print(time.mktime(time.localtime())) # 1637838298.0
# 格林威治时间
time.gmtime()
print(time.gmtime(time.time()))
# 原地阻塞1秒
time.sleep(1)
# 格式化时间表现形式
# 年-月-日
print(time.strftime('%Y-%m-%d')) # 2021-11-25
# 年-月-日 时:分:秒
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2021-11-25 19:00:37
# 时分秒可以简写为%X
print(time.strftime('%Y-%m-%d %X')) # 2021-11-25 19:00:37
print(time.strftime('%Y-%m-%d %X',time.localtime())) # 等价结构化时间
# 格式化转结构化时间
print(time.strptime('2021-11-25 19:00:37','%Y-%m-%d %X'))
# time.struct_time(tm_year=2021, tm_mon=11, tm_mday=25, tm_hour=19, tm_min=0, tm_sec=37, tm_wday=3, tm_yday=329, tm_isdst=-1)
# 生成固定格式的时间表现形式:
print(time.asctime(time.localtime())) #Thu Nov 25 19:22:39 2021
print(time.ctime(time.time())) # Thu Nov 25 19:22:39 2021
# 时间加减
res = time.time()
print(time.ctime(res+1)) # Thu Nov 25 19:23:27 2021
print(time.ctime(res-1)) # Thu Nov 25 19:22:38 2021
下面表格参考博文:[time模块]((20条消息) python time模块和datetime模块详解_weixin_34162629的博客-CSDN博客)
struct_time元组元素结构
属性 值
tm_year(年) 比如2011
tm_mon(月) 1 - 12
tm_mday(日) 1 - 31
tm_hour(时) 0 - 23
tm_min(分) 0 - 59
tm_sec(秒) 0 - 61
tm_wday(weekday) 0 - 6(0表示周日)
tm_yday(一年中的第几天) 1 - 366
tm_isdst(是否是夏令时) 默认为-1
3、datatime模块
datatime模块是time的优化模块,功能更加强大
常用方法示例如下:
# datetime 模块
import datetime
# 获取当天年月日
print(datetime.date.today()) # 2021-11-25
# 获取当天精确时间
print(datetime.datetime.today()) # 2021-11-25 19:30:08.967812
# 分别输出年月日周
res = datetime.datetime.today()
print(res.year) # 2021
print(res.month) # 11
print(res.day) # 25
# 获取星期(weekday星期是0-6) 0表示周一
print(res.weekday()) # 3,表示周四
# 获取星期(weekday星期是1-7) 1表示周一
print(res.isoweekday()) # 4
# 时间差 ---timedelta
ctime = datetime.datetime.today()
time_tel = datetime.timedelta(days=3)
print(ctime) # 2021-11-25 19:33:24.800420
print(ctime-time_tel) # 2021-11-22 19:34:18.376427
print(ctime+time_tel) # 2021-11-28 19:34:18.376427
'''日期对象 = 日期对象 +/- timedelta对象'''
'''timedelta对象 = 日期对象 +/- 日期对象'''
ret = ctime + time_tel
print(ret - ctime) # 3 days, 0:00:00
print(ctime - ret) # -3 days, 0:00:00
# 小练习1:
'''输出东八区时间'''
print(datetime.datetime.now()) # 2021-11-25 19:38:51.478786
'''输出utc时间'''
print(datetime.datetime.utcnow()) # 2021-11-25 11:38:51.478786
# 扯淡小练习2:
'''计算活了多少天了'''
bir_days = datetime.date(1998,5,4)
now_data= datetime.date.today()
live_days = now_data - bir_days
print(f'活了{live_days}') # 活了8606 days, 0:00:00
4、collections 模块
该模块内部提供了一些高阶的数据类型
1、namedtuple(具名元组)
- 格式:
- namedtuple('名称',[名字1,名字2,...])
- namedtuple('名称','名字1 名字2 ...')
示例如下:
from collections import namedtuple
point = namedtuple('坐标',['x','y'])
res = point(10,20)
print(res,res.x,res.y)
# 结果:坐标(x=10, y=20) 10 20
point1 = namedtuple('坐标','x y z')
res1 = point1(10,20,30)
print(res1) # 坐标(x=10, y=20, z=30)
print(res1.x) # 10
print(res1.y) # 20
print(res1.z) # 30
2、队列模块-queue
示例如下:
# 队列模块
import queue # 内置队列模块:FIFO
# 初始化队列
q = queue.Queue()
# 队列中添加元素
q.put('first')
q.put('second')
q.put('third')
# 从队列中获取元素
print(q.get())
print(q.get())
print(q.get())
# 只有三个值,获取完就在原地等待
print(q.get())
# 结果
# first
# second
# third
3、双端队列-deque
示例如下
from collections import deque
q = deque([11, 22, 33])
q.append(44) # 从右边添加
print(q) # deque([11, 22, 33, 44])
q.appendleft(55) # 从左边添加
print(q) # deque([55, 11, 22, 33, 44])
print(q.pop()) # 从右边取值
print(q.popleft()) # 从做边取值
4、有序字典
- 字典是无序的,想生成有序的字典,使用OrderedDict
示例如下:
# 生成普通字典
normal_dict = dict([('name', 'Hammer'), ('pwd', 123), ('hobby', 'study')])
print(normal_dict)
# {'name': 'jason', 'pwd': 123, 'hobby': 'study'}
搞成有序的:
# 有序字典
from collections import OrderedDict
order_dict = OrderedDict([('name', 'Hammer'), ('pwd', 123), ('hobby', 'study')])
print(order_dict)
# 结果
# OrderedDict([('name', 'Hammer'), ('pwd', 123), ('hobby', 'study')])
5、默认值字典 -defaultdict
示例如下:
# 默认值字典
from collections import defaultdict
# 大于66的作为k2 的值,小于66的作为k1的值
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>60:
my_dict['k2'].append(value)
else:
my_dict['k1'].append(value)
print(my_dict)
# defaultdict(<class 'list'>, {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 90]})
# 这个例子用列表解析更简单一点
res = {'k1':[i for i in values if i <66],'k2':[i for i in values if i>=66]}
print(res)
# {'k1': [11, 22, 33, 44, 55], 'k2': [66, 77, 88, 99, 90]}
6、计数器 - Counter
示例如下:
# 计数器
res = 'HammerZeHammerZeHammerZe'
# 统计字符串中每个元素出现的次数
# 不用模块实现
new_dict = {}
for i in res:
if i not in new_dict:
new_dict[i] = 1
else:
new_dict[i] += 1
print(new_dict)
# {'H': 3, 'a': 3, 'm': 6, 'e': 6, 'r': 3, 'Z': 3}
# 使用模块实现
from collections import Counter # 计数器
ret = Counter(res)
print(ret)
# Counter({'m': 6, 'e': 6, 'H': 3, 'a': 3, 'r': 3, 'Z': 3})

【待续···】-如有错误欢迎指正,感谢🤞🤞🤞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号