使用索引优化left join on + where条件查询
首先,贴一个待优化的sql语句
select * from A left join B on A.c = B.c where A.employee_id = 3
需求解读:
- A表left join B表,并且指定A表中的employee_id为一个具体的值
在c字段不是任何索引,A B 表各有1W多条数据的情况下,用explain分析得知,AB表都使用了全表查询,效率极低

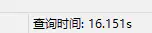
而我们执行这句sql的时间,即使使用的是本地SSD硬盘也达到了惊人的16S
优化 :
- 给AB表都加索引列c
这一点网上都有大片介绍,但网上的说明也就到此为止而已
让我们看看结果
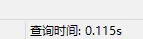
可以看到,确实是使用了索引!我们看看执行分析

16s多的查询,仅用了0.1s!很多人的优化之路到这里就结束了,但真的大功告成了吗?
![]()
![]()
思考:表A和表B中都加了索引,然而查询过程却是表A进行了全表扫描,如果非要全表扫描一个的话,为什么全表扫描的不是表B?
因为Mysql内部的优化,使用小表驱动大表,
它在估算到必须有一个表要全表扫描的话,一定会选择那个数据量更小的表去全表扫描,
也就是说,在这个查询中,因为on以后的where条件列并没有使用到索引,
所以mysql的优化只用到了表B的c索引,没有用到表A的索引!
分析得知,查询看似快了不少,然而表A还是进行了全表查询,而我们的查询中使用了where语句,根本就不需要全表扫描!!
那么问题来了:where条件中employee_id 的索引应该怎么加?
尝试解决:
- 将A表中的索引改为employee_id+c
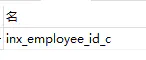
sql分析:

看似没有问题?确实是用到了employee_id+c的索引,但是
思考:sql执行 from中的on应该是优先于where语句的,为什么这里employee_id反而在c之前?有违常理?
结合上面的Mysql优化可知,
这一句Sql在执行的时候首先是选择了使用表B的索引来进行优化,
将表A单独放出来进行后续的操作,
然后,又发现了where语句中A.employee_id有一个聚合索引,
并且employee_id处于索引头,所以这个聚合索引是可用的,
so自然使用了此索引
为了证明这个观点,我们把聚合索引后面的列c删掉试试:
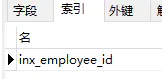
sql分析:

查询结果和刚才的聚合索引没有任何变化,证明我们的猜测是正确的
看看最终的查询时间:
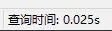
扫描的A表中记录数从10557条缩小到了符合A.employee_id=3的69条,100多倍的差距!
如果数据量不是1万 而是100万,100亿,沿用之前的sql,系统还能稳定运行吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号