
MySQL主从复制原理
1.主从复制的含义
在 MySQL 多服务器的架构中,至少要有一个主节点(master),跟主节点相对的,我们把它叫做从节点(slave)。主从复制,就是把主节点的数据复制到一个或者多个从节点。主服务器和从服务器可以在不同的 IP 上,通过远程连接来同步数据,这个是异步的过程。
2.主从复制的形式
![]()
![]()
![]()
![]()
- 一主一从/一主多从
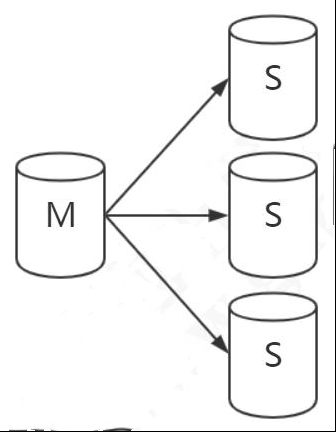
- 多主一从
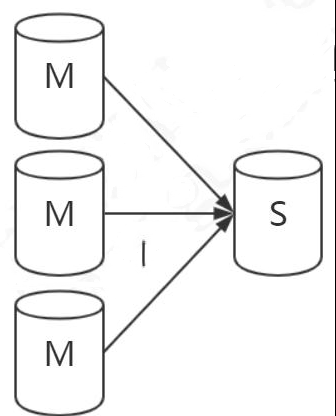
- 双主复制
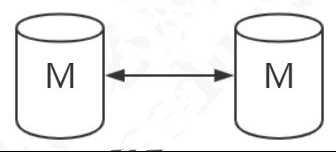
- 级联复制
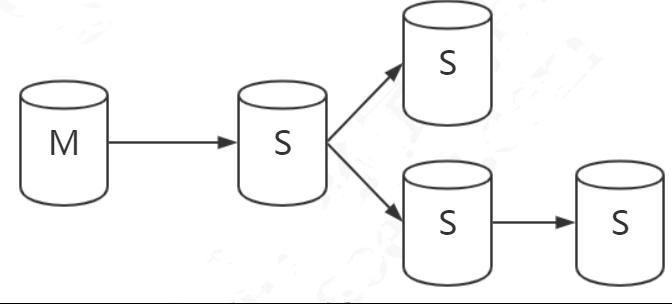
3.主从复制的用途
数据备份:把数据复制到不同的机器上,以免单台服务器发生故障时数据丢失。
读写分离:让主库负责写,从库负责读,从而提高读写的并发度。
高可用 HA:当节点故障时,自动转移到其他节点,提高可用性。
扩展:结合负载的机制,均摊所有的应用访问请求,降低单机 IO。
主从复制是怎么实现的呢?
- binlog
客户端对 MySQL 数据库进行操作的时候,包括 DDL 和 DML 语句,服务端会在日志文件中用事件的形式记录所有的操作记录,这个文件就是 binlog 文件(属于逻辑日志,跟 Redis 的 AOF 文件类似)。
基于 binlog,我们可以实现主从复制和数据恢复。
Binlog 默认是不开启的,需要在服务端手动配置。注意有一定的性能损耗。
- binlog 配置
编辑 /etc/my.cnf:
log-bin=/var/lib/mysql/mysql-bin server-id=1
重启 MySQL 服务 :
service mysqld stop service mysqld start ## 如果出错查看日志 3 vi /var/log/mysqld.log cd /var/lib/mysql
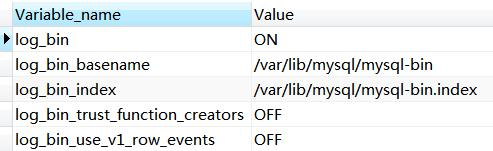
是否开启
binlog show variables like 'log_bin%';
- binlog 格式
STATEMENT:记录每一条修改数据的 SQL 语句(减少日志量,节约 IO)。
ROW:记录哪条数据被修改了,修改成什么样子了(5.7 以后默认)。
MIXED:结合两种方式,一般的语句用 STATEMENT,函数之类的用 ROW。
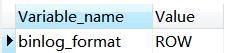
- 查看 binlog 格式:
show global variables like '%binlog_format%';
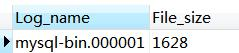
- 查看 binlog 列表:
show binary logs;
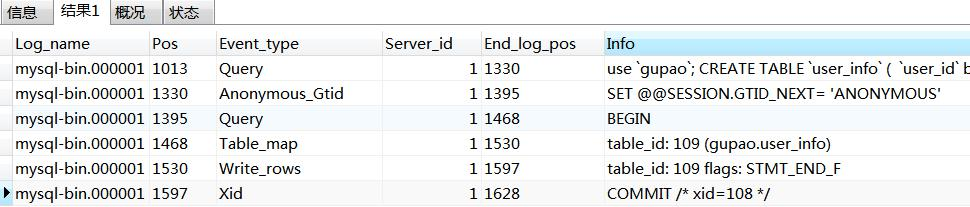
- 查看binlog内容:
show binlog events in 'mysql-bin.000001';
用mysqlbinlog工具,基于时间查看binlog:
(注意这个是Linux命令,不是SQL)
/usr/bin/mysqlbinlog --start-datetime='2019-08-2213:30:00' --stop-datetime='2019-08-2214:01:01'-d test /var/lib/mysql/mysql-bin.000001
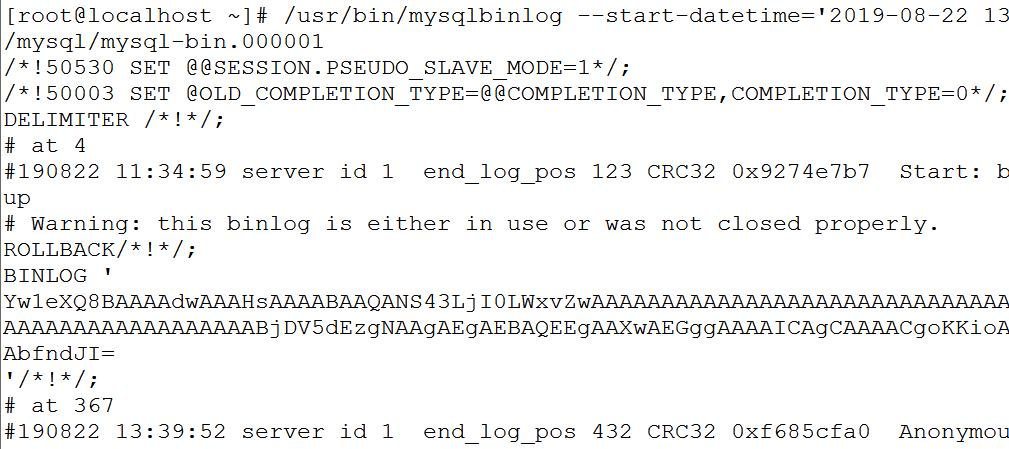
4. 主从复制原理
- 主从复制配置
1、主库开启 binlog,设置 server-id
2、在主库创建具有复制权限的用户,允许从库连接
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'192.168.8.147' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;
3、从库/etc/my.cnf 配置,重启数据库
server-id=2
log-bin=mysql-bin
relay-log=mysql-relay-bin
read-only=1
log-slave-updates=1
log-slave-updates 决定了在从 binlog 读取数据时,是否记录 binlog,实现双主和级联的关键。
4、在从库执行
stop slave;
change master to
master_host='192.168.8.146',master_user='repl',master_password='123456',master_log_file='mysql-bin.000001',
master_log_pos=4;
start slave;
5、查看同步状态
SHOW SLAVE STATUS \G
以下为正常:
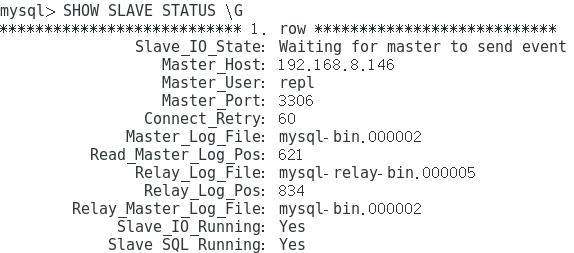
主从复制原理这里面涉及到几个线程:
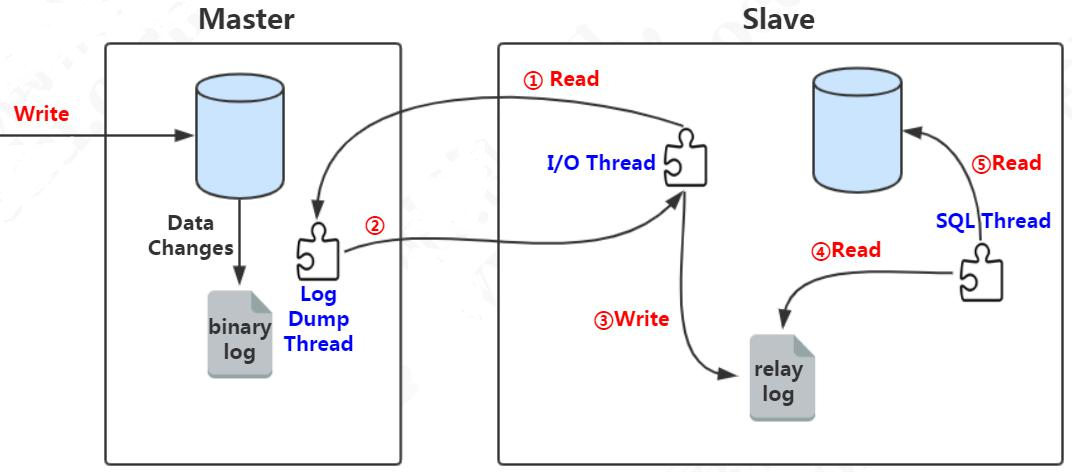
- 1、slave 服务器执行 start slave,开启主从复制开关, slave 服务器的 IO 线程请求从 master 服务器读取 binlog(如果该线程追赶上了主库,会进入睡眠状态)。
- 2、master 服务器创建 Log Dump 线程,把 binlog 发送给 slave 服务器。slave 服务器把读取到的 binlog 日志内容写入中继日志 relay log(会记录位置信息,以便下次继续读取)。
- 3、slave 服务器的 SQL 线程会实时检测 relay log 中新增的日志内容,把 relay log解析成 SQL 语句,并执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号