
数据库分库分表中间件MyCat的安装和mycat配置详解
一、mycat的安装
环境准备:准备一台虚拟机192.168.152.128
1. 下载mycat
cd /software wget http://dl.mycat.io/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz

2. 解压mycat
tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz


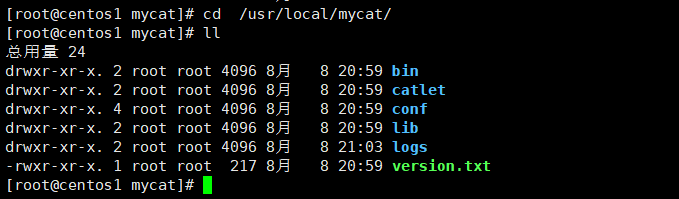
3. 剪切mycat到/usr/local目录下
mv /software/mycat /usr/local
4. 启动mycat
/usr/local/mycat/bin/mycat start 启动 /usr/local/mycat/bin/mycat status 查看启动状态

说明:这里有个小插曲,启动一会mycat又会自己停止

通过查看日志
vim /usr/local/mycat/logs/wrapper.log
报:Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=64M; support was removed in 8.0
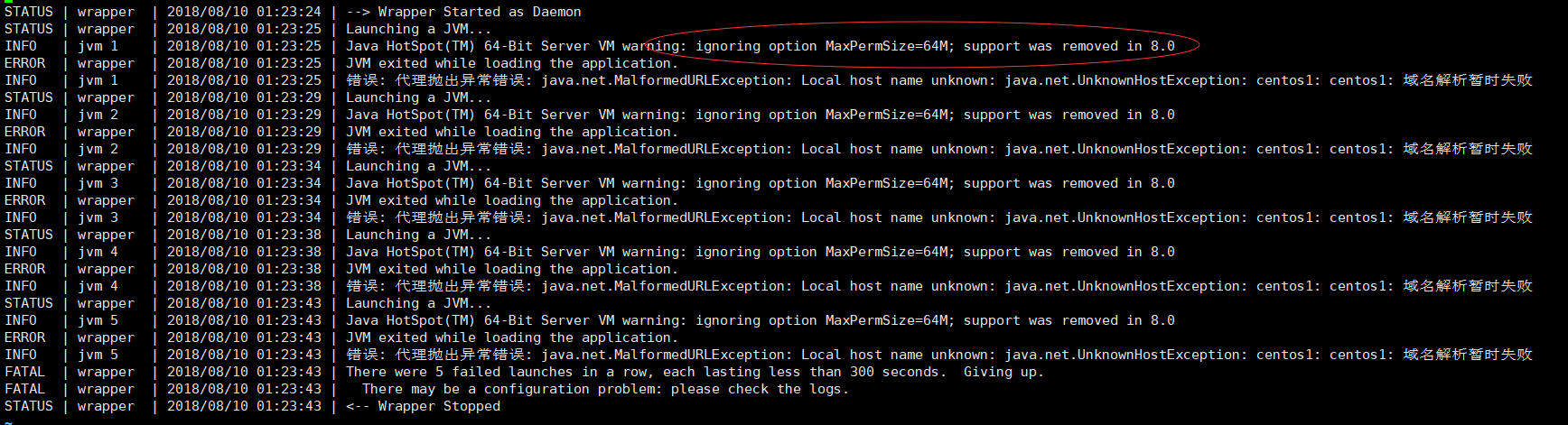
这是因为使用的是jdk8的版本,jdk8以后就没有永久代了,而mycat的wrapper.conf里面配置了jdk8以前的永久代的内存大小,我们只需要注释这个配置就可以了
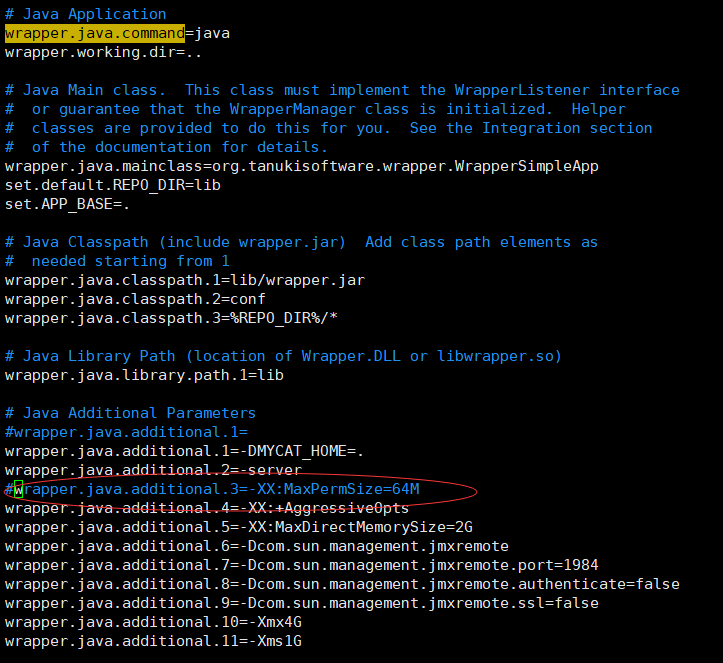
重新启动mycat:
/usr/local/mycat/bin/mycat start
就不会出现启动一会又自己停止的问题了
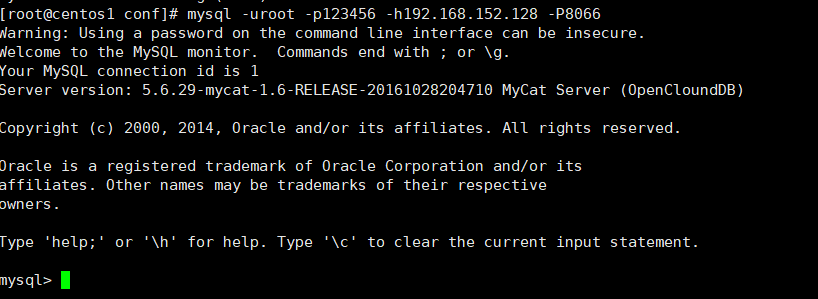
连接mycat:
mysql -uroot -p123456 -h192.168.152.128 -P8066
可以看到mycat连接成功
5. linux下mycat常用命令
/usr/local/mycat/bin/mycat start 启动 /usr/local/mycat/bin/mycat stop 停止 /usr/local/mycat/bin/mycat console 前台运行 /usr/local/mycat/bin/mycat restart 重启服务 /usr/local/mycat/bin/mycat pause 暂停 /usr/local/mycat/bin/mycat status 查看启动状态
二、mycat配置详解
1. 首先查看mycat的文件目录
mycat的主要配置文件都在conf目录下,核心的配置文件是schema.xml、server.xml、rule.xml这3个配置文件,下面我们来对这3个配置文件进行详细介绍
2. schema.xml
是Mycat最重要的配置文件之一。主要管理Mycat逻辑库、逻辑表、表、分片规则、DataSource。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
schema标签:指定Mycat的逻辑库(mycat的Schema,可以指定多个schema标签)
checkSQLschema属性:
False 过滤schema定义。
select * from testdb.company;=> select * from company;
True 不过滤schema定义,当我们把testdb输错了或者没有设置大小写敏感就会报错
sqlMaxLimit属性:
Limit 自动加入limit,查询语句如果没有加入分页参数,当数据量很大的时候,mycat认为会有问题时就启用这个参数只返回100条。例如:select * from company。
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--
table标签:指定Mycat中的逻辑表。最后要做数据分片的表。mycat中的表,可以和实体有具体映射关系,也可以没有具体映射关系(如果没有映射关系会报错)。
dataNode属性:数据节点,把相应的表存到对应的DB中。
rule属性:分片规则。对应rule.xml中的规则。
ruleRequired属性:指定该属性的表是否需要分片规则。True 必须制定,如果没有制定,就会报错。 primaryKey属性:值为具体的物理表的主键id,如果使用非主键进行分片,那么Mycat会缓存主键和具体dataNode的信息,如果下次再使用非主键进行查询的时候,就不用广播所有dn。
type属性:逻辑表的类型。普通表和全局表,全局表不需要分片,是为了解决跨库join的,全局表一般是数据量比较小、基本不会增长的表
autoIncrement属性:Mycat根据last_insert_id()返回结果。这个需要和mysql自增长主键配合。
needAddLimit属性:是否自动在每一条SQL语句后面加上limit限制。
-->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!--
dataNode标签:定义数据节点
dataHost属性: 主机的名称
database属性: 数据库
-->
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<!--
dataHost标签:主要定义和Mysql集群有关的信息,数据实例、读写分离配置和心跳检测语句。
balance属性:读操作负载均衡配置
0 代表不开启读写分离,所有的读操作都发送到writeHost上。
1 writeHost和readHost都要参与select语句的负载均衡。例如:双主双从模式 M1->S1, M2->S2, M1和M2互为主备。M2/S1/S2都要参与select语句的负载均衡。
2 所有读操作都随机分配给writeHost/readHost
3 所有的读操作随机分发到writeHost下面的readHost上执行。
writeType属性:写操作负载均衡配置
0 所有的写操作都分发到第一个writeHost。如果第一个挂了,分发到第二个。
1 所有的写操作都要随机分发到所有配置的writeHost上。1.5以后不推荐。
dbType属性:支持的数据库类型,mycat支持多种db类型:mysql、oracle等
switchType属性:切换类型,主备切换,主主切换。
-1 代表不自动切换
1 默认值,自动切换。对应的心跳检测语句select user();
2 基于Mysql主从同步的状态决定是否切换。对应的心跳检测语句show slave status;
3 基于MySQL Galera Cluster切换机制。对应的心跳检测语句show status like ‘wsrep%’;
maxCon属性:单个writeHost/readHost节点的最大连接数
minCon属性:单个writeHost/readHost节点的最小连接数
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
3. server.xml
主要用于管理Mycat的用户名,权限,黑白名单等等设置。这个文件主要和Mycat Server运行环境有关。
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<!--
Firewall标签:全局SQL防火墙设置
定义访问控制策略:如白名单/黑名单
-->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<!--
User标签:定义可访问mycat的用户名称/密码/是否只读
-->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!--
Privileges标签:表级 DML 权限设置
控制DML:insert/update/select/delete
单独给select权限:0010
单独给insert权限:1000
-->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
下面附一个表格说明server.xml的system标签下的各个标签和属性的说明:
| 属性 | 说明 | 备注 |
| useSqlStat | 开启实时统计 | 1为开启,0为关闭 |
| useGlobleTableCheck | 全局表一致性检测 | 1为开启,0为关闭 |
| sequnceHandlerType | Mycat全局ID类型 | 0本地文件方式 1数据库方式 2时间戳序列方式 3分布式ZK ID生成器 4 ZK递增ID生成 |
| useCompression | mysql压缩协议 | 1为开启,0为不开启 |
| fakeMySQLVersion | 伪装的MySQL版本号 | |
| processorBufferChunk | 每次分配Socket Direct Buffer大小 | 默认4096字节 |
| processors | 系统可用线程数 | 默认Runtime.getRuntime().availableProcessors()返回值 |
| processorExecutor | NIOProcessor共享businessExecutor线程池大小 | |
| processorBufferPoolType | 每次分配Socket Direct Buffer大小 | 默认是4096个字节 |
| maxStringLiteralLength | sql解析时最大文本长度 | 默认是65535(即64K) |
| backSocketNoDelay | TCP连接相关属性 | 默认值1 |
| frontSocketNoDelay | TCP连接相关属性 | 默认值1 |
| serverPort | 指定服务端口 | 默认8066 |
| managerPort | 指定管理端口 | 默认9066 |
| idleTimeout | 连接空闲时间 | 默认30分钟,单位毫秒 |
| bindIp | Mycat服务监听的IP地址 | |
| frontWriteQueueSize | 前端连接写队列长度 | 为了让用户知道是否队列过长(SQL结果集返回太多)。当超过指定阀值后,会产生一个告警日志 |
| handleDistributedTransactions | 分布式事务开关 | 0不过滤分布式事务 1过滤分布式事务 2不过滤分布式事务但记录分布式事务日志 |
| useOffHeapForMerge | 是否让Mycat开启非堆内存 | 1 开启,0关闭 |
| memoryPageSize | 内存分页大小 | |
| useStreamOutput | 是否使用流输出 | |
| systemReserveMemorySize | 系统保留内存大小 | |
| useZKSwitch | 是否采用zookeeper协调切换 | true/false |
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!--
tableRule标签:定义table分片策略
-->
<tableRule name="rule1">
<!--
rule标签:策略定义标签
-->
<rule>
<!--
columns标签:对应的分片字段
-->
<columns>id</columns>
<!--
algorithm标签:tableRule分片策略对应的function名称
-->
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<!--
function标签:定义分片函数
-->
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
rule是定义分片规则的
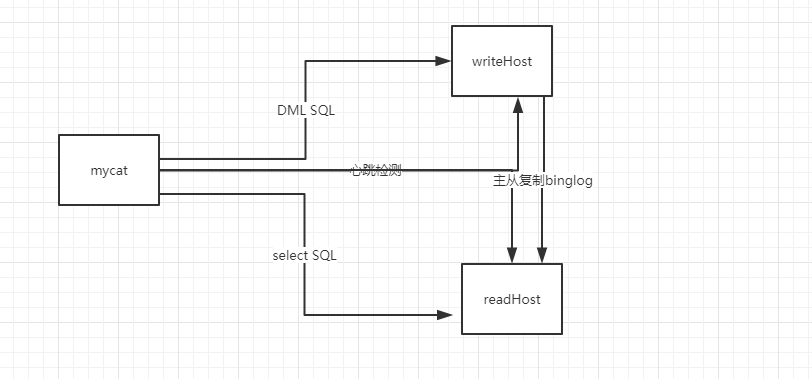
三、mycat工作原理
四、mycat基础概念
1. mycat支持的数据库

2. 逻辑库(Schema)
在实际应用中,业务开发人员并不需要知道中间件的存在,只需要知道数据库的概念,所以数据库中间件可以被看作是一个或者多个数据库集群构成的逻辑库。

3. 逻辑表
在分布式数据库中,读写数据的表就是逻辑表。逻辑表,可以是数据切分后分布在一个或多个分片库中,也可以不做数据切分不分片,只有一个表构成 。
4. DataNode、DataHost、Rule
DataNode:数据切分后,一个大表被分到不同的分片数据库上面,每个分片所在的数据库就是分片节点。
DataHost:数据切分后,每个分片节点(DataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库。一个或多个分片节点(DataNode)所在的机器就是节点主机(DataHost)。
Rule:分片规则,选择合适的分片规则很重要,将极大的避免后续处理数据的难度。
5. myca分片原则
5.1 数据拆分之前的思考
分片规则虽然能解决大表对数据库系统的压力,但它并不是万能的,也有一些不利之处。因此首要问题是:
1)分不分库;
2)分哪些库;
3)什么规则分;
4)分多少片
5.2 mycat数据切分原则
1)达到一定数量级才分,一般是单表达到800万数据就要考虑数据拆分了;
2)不到800万,但跟大表(超800万的表)有关联查询的表也要拆分,在此称为大表关联表;
3)大表关联表如何拆分:小于100万的使用全局表;大于100万小于800万跟大表使用同样的拆分策略;无法跟大表使用相同规则的,可以考虑从java代码上分步骤查询,不用关联查询,或者破例使用全局表;
4)全局表:如品牌表250万,跟大表order关联,又无法跟大表使用同样的拆分策略,也做成了全局表。全局表必须满足的条件:没有太激烈的并发update(如多线程同时update同一条记录);虽有多线程update,但不是操作同一条记录;批量insert没问题;
5)拆分字段是不可修改的;
6)拆分字段只能是一个字段,如果想按照两个字段拆分,必须新建一个冗余字段,冗余字段的值使用两个字段的值拼接而成(如大区+年月拼接成:“区域_年月日” 字段);
7)拆分算法的选择和合理性判断:按照选定的算法拆分后每个库中单表不得超过800万记录;
8)能不拆分的尽量不拆分。如果某个表不跟其他表关联查询,数据量又少、直接不拆分,使用单库即可;
5.3 Mycat分库分表原则
1)能不分就不分,1000万以内的表,不建议分片,通过合适的索引,读写分离等方式,可以很好的解决性能问题;
2)分片数量尽量少,分片尽量均匀分布在多个DataHost上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量;
3)分片规则需要慎重选择,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性Hash分片,这几种分片都有利于扩容;
4)尽量不要在一个事物中的SQL跨越多个分片,分布式事物一直是一个不好处理的问题;
5)查询条件尽量优化,尽量避免select * 的方式,大量数据结果集下,会消耗大量的CPU资源和带宽,查询应尽量避免返回大的结果集,并且应尽量为频繁使用的查询语句建立索引。
5.4 mycat常用分片规则
1)时间类:按天分片、自然月分片、单月小时分片;
2)哈希类:Hash固定分片、日期范围Hash分片、截取数字Hash求模范围分片、截取数字Hash分片、一致性Hash分片;
3)取模类:取模分片、取模范围分片、范围求模分片;
4)其他类:枚举分片、范围约定分片、应用指定分片、冷热数据分片。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号