
使用zookeeper管理远程MyCat配置文件、MyCat监控、MyCat数据迁移(扩容)
一、使用zookeeper管理远程Mycat配置文件
环境准备:
虚拟机192.168.152.130:
zookeeper,具体参考前面文章 搭建dubbo+zookeeper+dubboadmin分布式服务框架(windows平台下)
虚拟机192.168.152.128:
安装好Mycat,具体参考前面文章数据库分库分表中间件mycat的安装和mycat配置详解
本机:
搭建好zookeeper的客户端工具ZooInspector ,具体参考这个人的文章Zookeeper数据查看工具ZooInspector简介
1. 启动ZK
./zkServer.sh start

2. 修改/usr/local/mycat/conf/myid.properties
vim /usr/local/mycat/conf/myid.properties
loadZk=true zkURL=192.168.152.130:2181 clusterId=mycat-cluster-1 myid=mycat_fz_01 clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_04 #server booster ; booster install on db same server,will reset all minCon to 1 type=server boosterDataHosts=dn2,dn3
myid.properties配置说明:
loadZk:默认值false。代表mycat集群是否使用ZK,true表示使用
zkURL:zk集群的地址
clusterId:mycat集群名字
myid:当前的mycat服务器名称
clusterNodes:把所有集群中的所有mycat服务器罗列进行以逗号隔开,比如:clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_03
3. 使用Mycat脚本初始化mycat在ZK中的节点数据
/usr/local/mycat/bin/init_zk_data.sh


4. 启动mycat
/usr/local/mycat/bin/mycat start
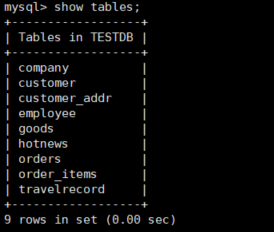
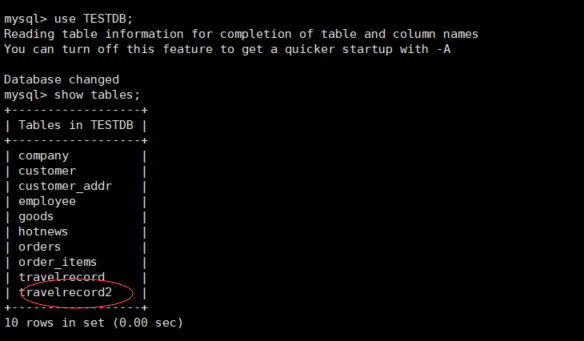
5. 连接mycat,查看当前数据库中表的情况
mysql -uroot -pdigdeep -P8066 -h192.168.152.128 use TESTDB; show tables;
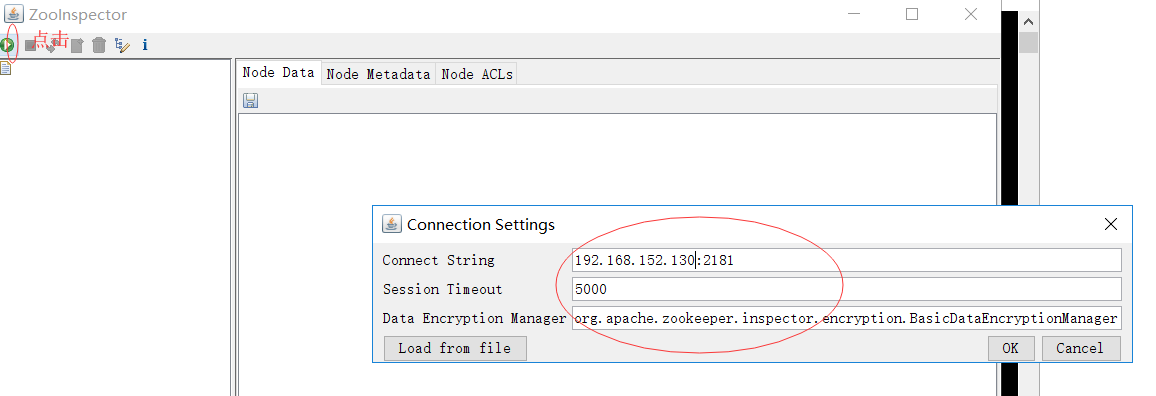
6. 使用zookeeper的客户端工具ZooInspector连接zookeeper修改mycat配置文件
6.1 进入目录E:\software\devtools\ZK\ZooInspector\build,运行zookeeper-dev-ZooInspector.jar;

java -jar zookeeper-dev-ZooInspector.jar
连接远程zookeeper
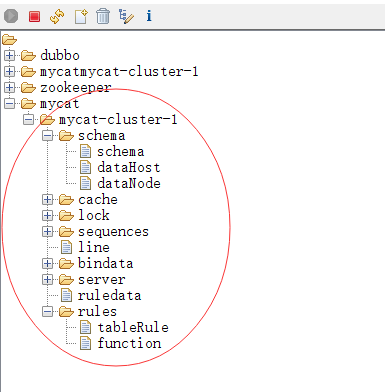
连接成功以后可以看到mycat的树节点和mycat的安装后的conf目录下的schema.xml和rule.xml文件是对应的
6.2 在zookeeper管理工具里面动态修改schema配置文件新增一张逻辑表travelrecord2
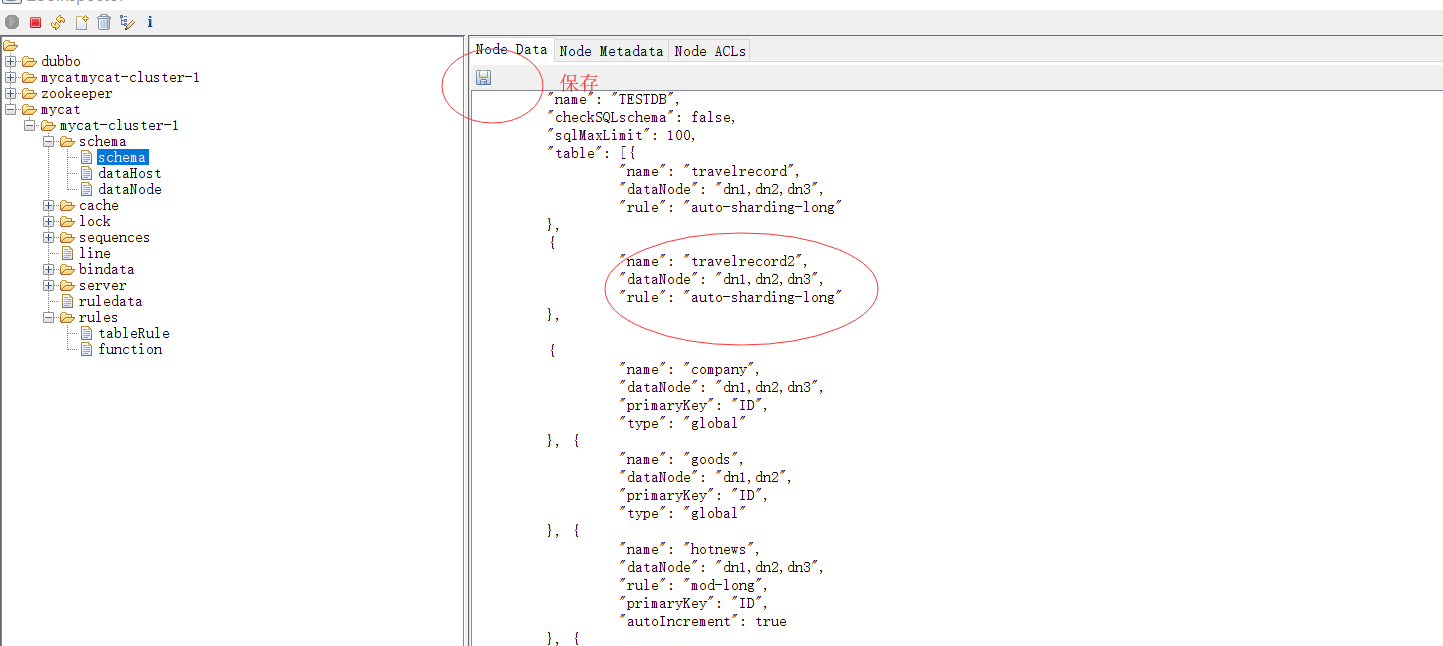
保存修改,查看mycat的schema.xml配置文件,可以看到修改已经同步过来了
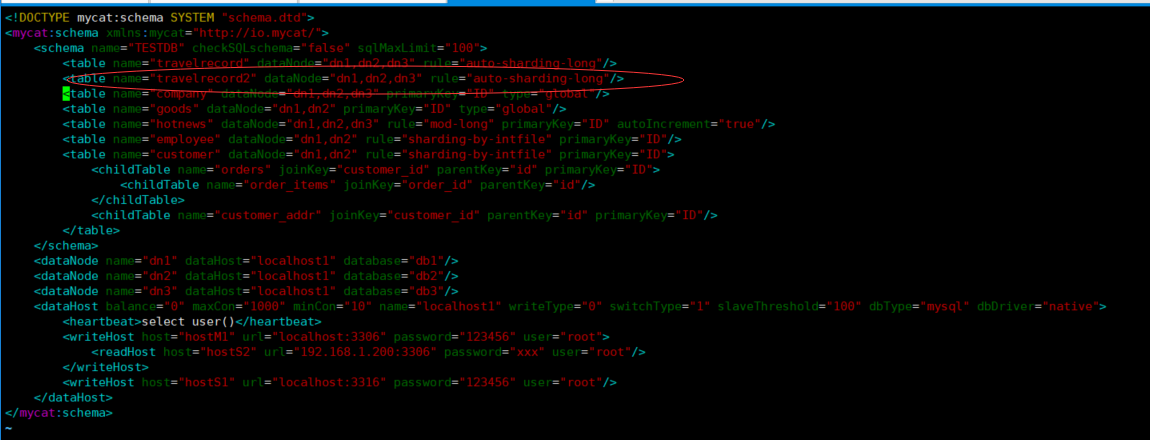
重启mycat,可以看到TESTDB里面有新配置的travelrecord2表
/usr/local/mycat/bin/mycat restart
二、Mycat监控
1. 下载Mycat-web上传到虚拟机中
http://dl.mycat.io/mycat-web-1.0/


2. 解压Mycat-web
tar -zxvf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz

3 修改mycat-web项目下/WEB-INF/classes/mycat.properties中zookeeper属性
vim /software/mycat-web/mycat-web/WEB-INF/classes/mycat.properties
#Mon Jan 16 15:37:36 CST 2012
show.period=3000000
zookeeper=192.168.152.130:2181
mycat_warn_mail=[{"cc"\:"sohudo@mycat.io","index"\:1,"mangerPort"\:"465","smtpHost"\:"smtp.139.com","smtpPassword"\:"123456","smtpProtocol"\:"smtp","smtpUser"\:"agile_louie@139.com","to"\:"9183838@qq.com"}]
##sql\u4E0A\u7EBF\u76F8\u5173\u914D\u7F6E
sqlonline.server=192.168.80.128
sqlonline.user=root
sqlonline.passwd=123456
4. 启动mycat-web
/software/mycat-web/start.sh

5. 访问mycat-web
访问地址:http://192.168.152.128:8082/mycat/

6. 在Mycat管理界面手动初始化Mycat配置
6.1 Mycat-配置管理。增加mycat服务器配置
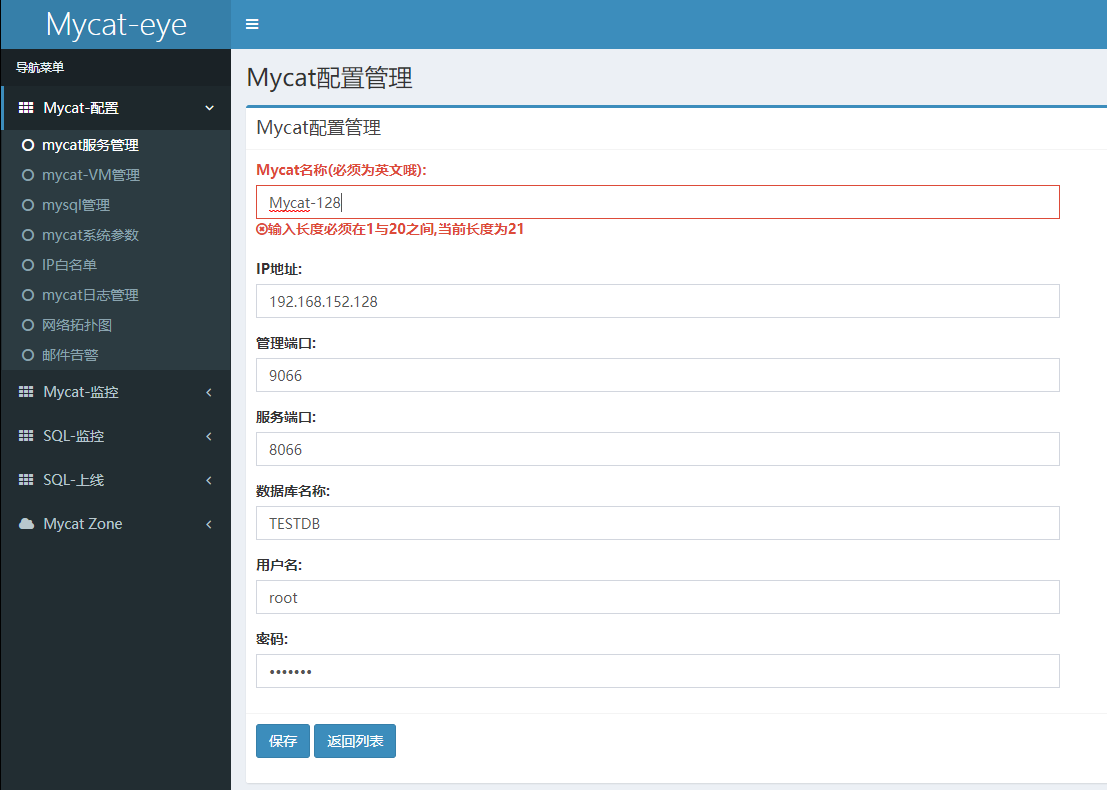
保存,新增成功

6.2 mycat-VM管理。配置JMX服务项

保存新增成功

6.3 MySQL配置管理
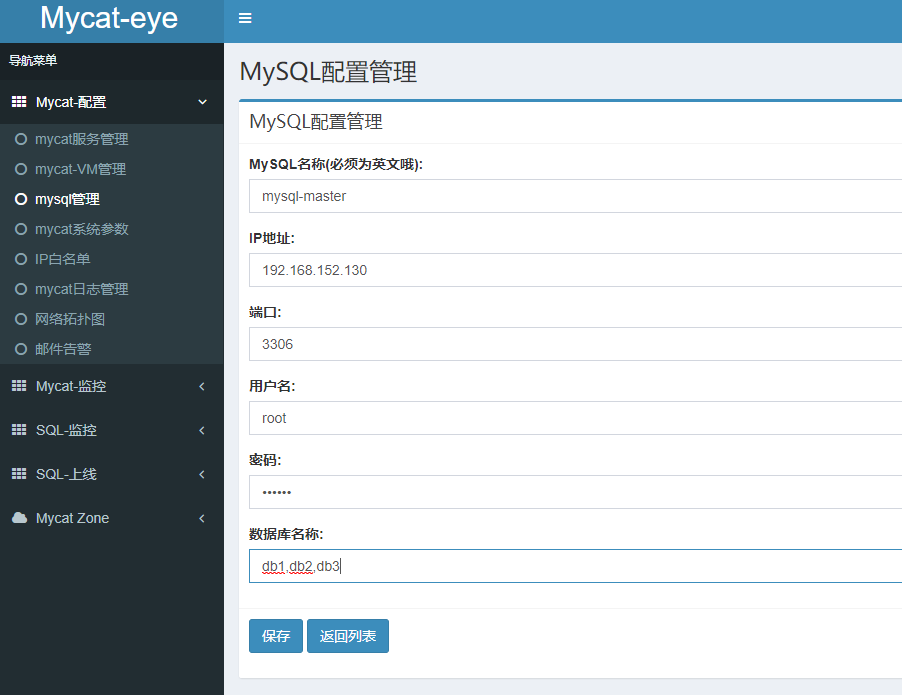

分别保存,新增成功

初始化完前面的三步,就可以对Mycat进行监控了
三、Mycat数据迁移(扩容)
以employee表作数据迁移
1. 准备工作:
1)修改employee表的分片规则为一致性hash,vim schema.xml
<table name="employee" dataNode="dn1,dn2" rule="sharding-by-murmur" primaryKey="ID"/>
2)修改分布式全局唯一id方式为本地文件方式,vim server.xml
<property name="sequnceHandlerType">0</property>
3)关掉ZK配置,vim myid.properties
loadZk=false zkURL=192.168.152.130:2181 clusterId=mycat-cluster-1 myid=mycat_fz_01 clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_04 #server booster ; booster install on db same server,will reset all minCon to 1 type=server boosterDataHosts=dn2,dn3
4) 重启mycat
../bin/mycat restart
5) 连接mycat,并创建employee表,并插入数据
mysql -uroot -pdigdeep -P8066 -h192.168.152.128
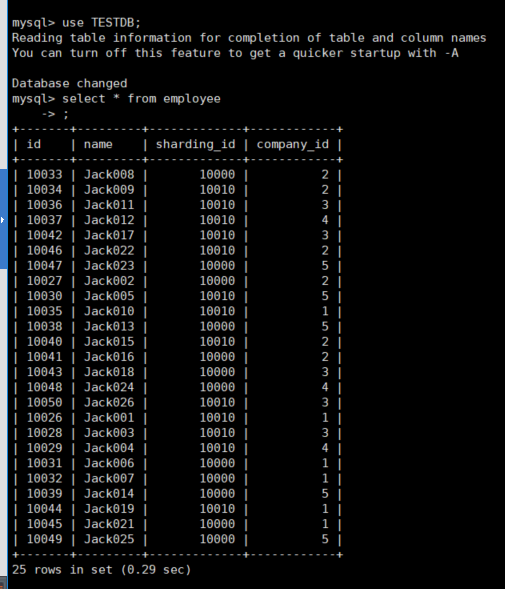
use TESTDB; create table employee( id bigint(20) not null primary key auto_increment, name varchar(20), sharding_id bigint(20), company_id bigint(20) ); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack001', 10010, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack002', 10000, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack003', 10010, 3); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack004', 10010, 4); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack005', 10010, 5); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack006', 10000, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack007', 10000, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack008', 10000, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack009', 10010, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack010', 10010, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack011', 10010, 3); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack012', 10010, 4); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack013', 10000, 5); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack014', 10000, 5); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack015', 10010, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack016', 10000, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack017', 10010, 3); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack018', 10000, 3); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack019', 10010, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack021', 10000, 1); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack022', 10010, 2); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack023', 10000, 5); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack024', 10000, 4); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack025', 10000, 5); insert into employee(id, name, sharding_id, company_id) values(next value for MYCATSEQ_GLOBAL, 'Jack026', 10010, 3);
可以看到插入了25条数据到employee里面
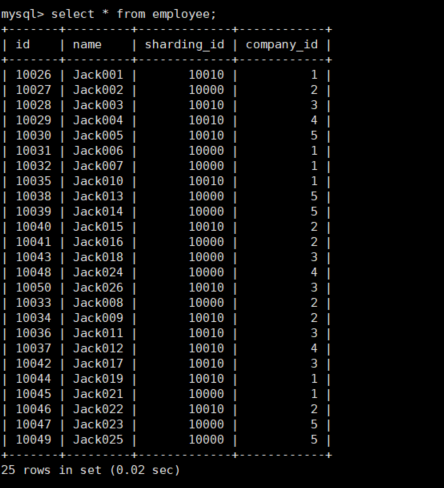
然后在主库(192.168.152.130)的两个分片dn1(db1),dn2(db2)上查看employee的数据
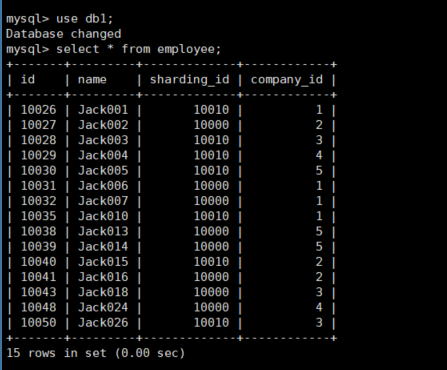
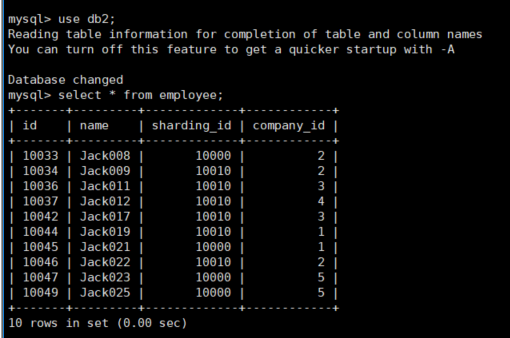
可以看到dn1上有15条数据,dn2上有10条数据
2. 开始做数据迁移
当前employee表的数据分布在dn1,dn2,迁移后要分布在dn1,dn2,dn3
1)生成一个新的schema文件,文件名newSchema.xml,同时修改dataNode="dn1,dn2,dn3"(新的分片定义)
cp schema.xml newSchema.xml vim newSchema.xml
以前的schema.xml文件:

新的newSchema.xml:

2)生成一个新的rule文件,文件名newRule.xml,同时修改分片数为3(新的分片规则)
cp rule.xml newRule.xml vim newRule.xml
以前的rule.xml:

新的newRule.xml:

3)修改/usr/local/mycat/conf/migrateTables.properties文件。写明要迁移的schema和表,多张表用逗号隔开
vim migrateTables.properties
#schema1=tb1,tb2,... #schema2=all(写all或者不写将对此schema下拆分节点变化的拆分表全部进行重新路由) #... #sample #TESTDB=travelrecord,company,goods TESTDB=employee
4)停止mycat(也可以不停止mycat)
5)执行dataMigrate.sh开始迁移(扩容)。
[root@centos1 bin]# ./dataMigrate.sh
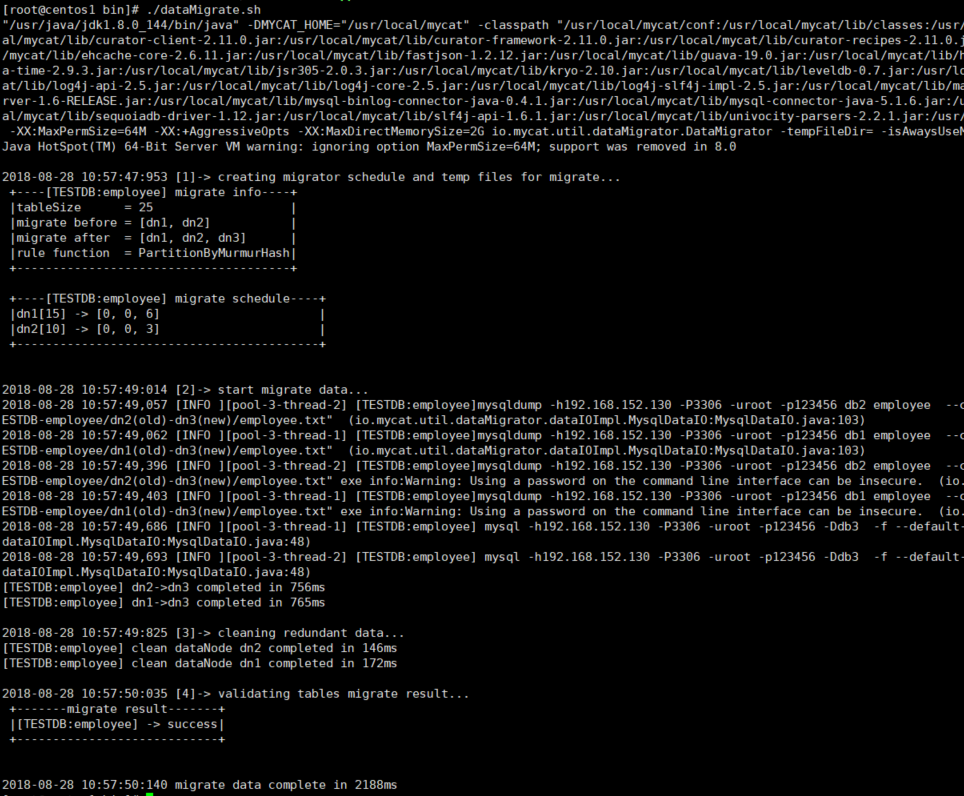
遇到的错误1:
开始执行./dataMigrate.sh 的时候报没有适合的驱动
No suitable driver found for jdbc:mysql://192.168.152.130:3306/db1 java.sql.SQLException: No suitable driver found for jdbc:mysql://192.168.152.130:3306/db1
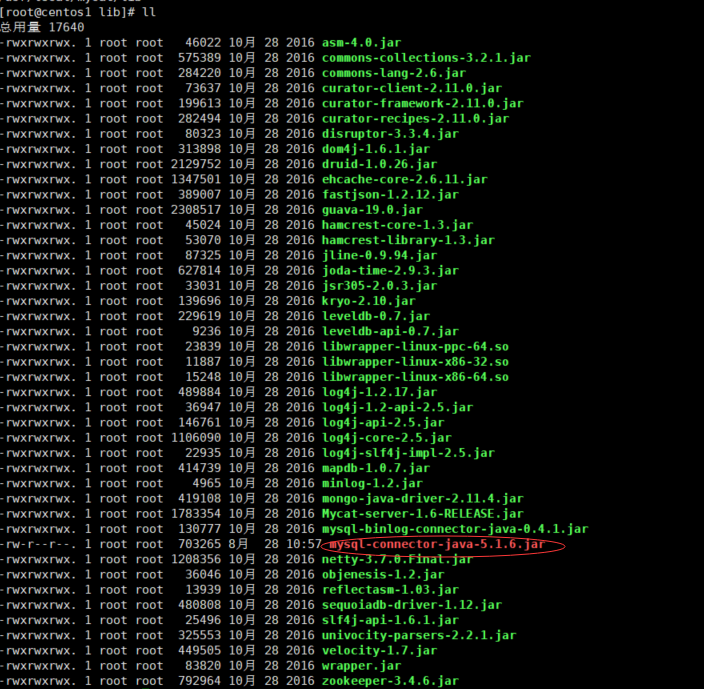
解决方法1:
下载jar包mysql-connector-java-5.1.6.jar,然后上传到/usr/local/mycat/lib
查看主库(192.168.152.130)三个分片dn1(db1),dn2(db2),dn3(db3)上employee表的数据
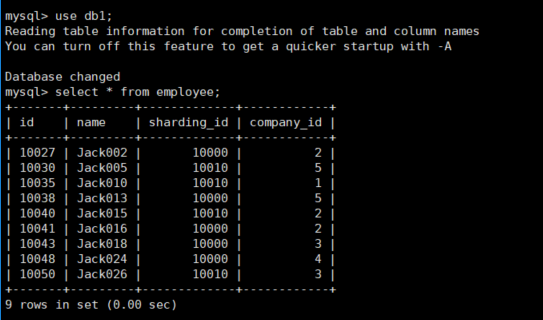
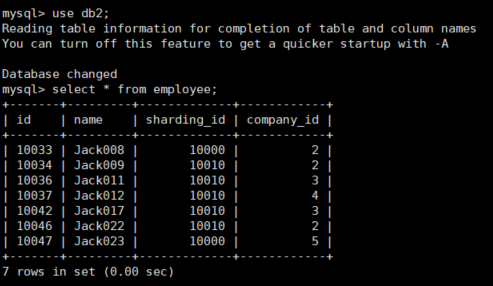
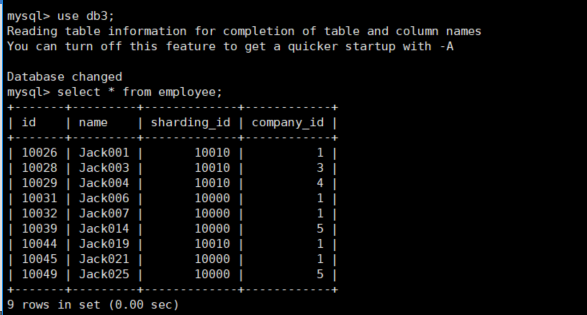
可以看到数据迁移成功
6)修改newRule.xml成为rule.xml,修改newSchema.xml为schema.xml。重启mycat
./bin/mycat restart
连接mycat,查看employee表的数据
mysql -uroot -pdigdeep -P8066 -h192.168.152.128

 浙公网安备 33010602011771号
浙公网安备 33010602011771号