开源语音代码eSpeak1.06 的移植到单片机的过程(二)之分析下speak.c 文件
1. 下面的分析speak.c 文件,不是很理解speak.c 和 espeak.c 的区别,
speak.c 说的是有 text to speech engine. It does not use the libespeak library.
espeak.c 说的是用的是 libespeak library
我理解libespeak library 说的是它
如果不使用库的话,应该用的是它
但是为啥要搞两个?疑惑
第一个看到的是,说是
char path_home[N_PATH_HOME]; // this is the espeak-data directory
决定使用 espeak.c, 因为库也是C写的,应该也能整的进去。下一个问题,怎么把数据文件放到UIS8910里面?先提单问问。
2. 看下面的代码
sprintf(name2, "%s ", voicename);
if(strstr(voices_europe, voicename) != NULL)
voice_dir = "europe";
else if(strstr(voices_asia, voicename) != NULL)
voice_dir = "asia";
else
voice_dir = "other";
看下对比的是什么
static const char *voices_asia = "az bn fa fa-pin hi hy hy-west id ka kn ku ml ms ne pa ta te tr vi vi-hue vi-sgn zh zh-yue ";
static const char *voices_europe = "an bg bs ca cs cy da de el en en-us es et fi fr fr-be ga hr hu is it lt lv mk nl no pl pt-pt ro ru sk sq sr sv ";
那么 az an是什么,也就是说选择声音的时候,指定的 zh 就是中文,zh-yue 是粤语,那么其他的是 外国的各种语言吗? 其中在
其中 europe 是欧洲, asia 是亚洲,根据选择的字典不同,选择不同的 地区?
3. 查了下不同缩写是不是对应的国家语音,果然是的。
aa Afar
ab Abkhazian
af Afrikaans
am Amharic
ar Arabic
as Assamese
ay Aymara
az Azerbaijani
ba Bashkir
be Byelorussian
bg Bulgarian
bh Bihari
bi Bislama
bn Bengali; Bangla
bo Tibetan
br Breton
ca Catalan
co Corsican
cs Czech
cy Welsh
da Danish
de German
dz Bhutani
el Greek
en English
eo Esperanto
es Spanish
et Estonian
eu Basque
fa Persian
fi Finnish
fj Fiji
fo Faroese
fr French
fy Frisian
ga Irish
gd Scots Gaelic
gl Galician
gn Guarani
gu Gujarati
ha Hausa
he Hebrew (formerly iw)
hi Hindi
hr Croatian
hu Hungarian
hy Armenian
ia Interlingua
id Indonesian (formerly in)
ie Interlingue
ik Inupiak
is Icelandic
it Italian
iu Inuktitut
ja Japanese
jw Javanese
ka Georgian
kk Kazakh
kl Greenlandic
km Cambodian
kn Kannada
ko Korean
ks Kashmiri
ku Kurdish
ky Kirghiz
la Latin
ln Lingala
lo Laothian
lt Lithuanian
lv Latvian, Lettish
mg Malagasy
mi Maori
mk Macedonian
ml Malayalam
mn Mongolian
mo Moldavian
mr Marathi
ms Malay
mt Maltese
my Burmese
na Nauru
ne Nepali
nl Dutch
no Norwegian
oc Occitan
om (Afan) Oromo
or Oriya
pa Punjabi
pl Polish
ps Pashto, Pushto
pt Portuguese
qu Quechua
rm Rhaeto-Romance
rn Kirundi
ro Romanian
ru Russian
rw Kinyarwanda
sa Sanskrit
sd Sindhi
sg Sangho
sh Serbo-Croatian
si Sinhalese
sk Slovak
sl Slovenian
sm Samoan
sn Shona
so Somali
sq Albanian
sr Serbian
ss Siswati
st Sesotho
su Sundanese
sv Swedish
sw Swahili
ta Tamil
te Telugu
tg Tajik
th Thai
ti Tigrinya
tk Turkmen
tl Tagalog
tn Setswana
to Tonga
tr Turkish
ts Tsonga
tt Tatar
tw Twi
ug Uighur
uk Ukrainian
ur Urdu
uz Uzbek
vi Vietnamese
vo Volapuk
wo Wolof
xh Xhosa
yi Yiddish (formerly ji)
yo Yoruba
za Zhuang
zh Chinese
zu Zulu
代码继续向下查,可以看到最终会读文件 /espeak-data\voices\asia/zh,所以其他的文件可能是无用的,只需要中文和英文。
sprintf(buf,"%s%s%c%s", path_voices,voice_dir,PATHSEP,voicename);
if(GetFileLength(buf) <= 0)
{
// if not found, look in "test" sub-directory
sprintf(buf,"%stest%c%s",path_voices,PATHSEP,voicename);
}
}
}
}
f_voice = fopen(buf,"r");
这个language_type 看不懂什么意思?
5. 在其他地方看到,意思是 中文,女声2
// 设置中文
espeak_SetVoiceByName("zh+f2");
应该在这个地方,f1-f5 是女声,m1m7 是男生,whisper 是耳语,whisperf 是低语。
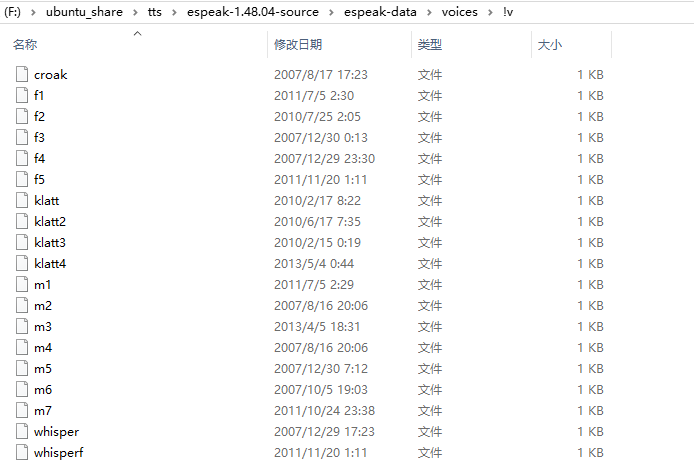
对应的代码在这里
if(variant_num > 0)
{
if(variant_num < 10)
sprintf(variant_name,"%sm%d",variant_prefix, variant_num); // male
else
sprintf(variant_name,"%sf%d",variant_prefix, variant_num-10); // female
}
奇怪,为啥 europe 文件夹里面为啥没有en, en文件反而在上一级目录中???
6. 接下来需要把所有的文件操作换成本地的函数
第一个似乎是写LOG 的函数,开始往下查找,最后是,难道不用?
static FILE *fopen_log(const char *fname,const char *access)
static FILE *fopen_log(const char *fname,const char *access)
compile_dictrules
CompileDictionary
espeak_CompileDictionary
if(flag_compile)
{
// This must be done after the voice is set
espeak_CompileDictionary("", stderr, flag_compile & 0x1);
exit(0);
}
case 0x102: // --compile
strncpy0(voicename,optarg2,sizeof(voicename));
flag_compile = c;
quiet = 1;
break;
int main (int argc, char **argv)
这个文件可能用不到,去掉
接下来是,读字段的
int LoadDictionary(Translator *tr, const char *name, int no_error)
{//===============================================================
int hash;
char *p;
int *pw;
int length;
//FILE *f;
unsigned int size;
// f = fopen(fname,"rb");
// if((f == NULL) || (size <= 0))
// {
// if(no_error == 0)
// {
// fprintf(stderr,"Can't read dictionary file: '%s'\n",fname);
// }
// return(1);
// }
//qhq 修改 *** begin
int fd = vfs_open(fname, O_RDONLY);
if (fd < 0)
return 1;
//qhq 修改 **** end
tr->data_dictlist = Alloc(size);
// size = fread(tr->data_dictlist,1,size,f);
// fclose(f);
//qhq 修改 *** begin
ssize_t read_len = vfs_read(fd, tr->data_dictlist, size);
vfs_close(fd);
//qhq 修改 **** end
接下来是 klatt.c,似乎是网上的一种语音合成工具,有一个宏定义#ifdef INCLUDE_KLATT
遇到一个麻烦的问题,static char *fgets_strip(char *buf, int size, FILE *f_in), 每次读取一行?
还要实现qsort函数,都是linux 里面的?
