Python 常用模块
本节内容
-
模块介绍
- os 模块
-
sys 模块
-
time & datetime模块
-
random 模块
-
json & picle
-
shutil 模块
-
shelve 模块
-
xml 模块
-
configparser 模块
-
hashlib 模块
1 模块介绍
模块,用一堆代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
2 os模块
提供对操作系统进行调用的接口


#!/usr/bin/env python # -*- coding:utf-8 -*- import os print(os.getcwd()) #获取当前工作目录,即当前python脚本工作的目录路径 print(os.chdir('dirname')) #改变当前脚本的工作目录,相当于shell下的cd print(os.curdir) # 返回当前目录:('.') print(os.pardir) # 返回当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') # 可生成多层递归目录 os.removedirs('dirname1/dirname2') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推(删除多级空目录) os.mkdir('dirname') # 生成单级空目录,相当于shell中的mkdir dirname os.rmdir('dirname') # 删除单级空目录,如目录不为空则无法删除,报错;相当于shell中的rmdir dirname print(os.listdir('homework')) # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove('test') # 删除一个文件,文件不存在报错 os.rename('homework','homework1') # 重命名文件/目录 os.renames('homework/贺磊','homework/贺磊1') # 批量重命名 print(os.stat('homework')) # 获取文件/目录属性信息 print(r'%s'%os.sep) # 输出操作系统特定的路径分隔符,win下为'\\',linux下为'/' print(os.linesep) # 输出当前平台使用的行终止符,win下为'\r\n',linux下为'\n' print(os.name) # 输出字符串指示当前使用平台。win=>'nt';linux=>'posix' os.system('ipconfig') # 运行shell命令,直接显示 print(os.environ) # 获取系统的环境变量 print(os.path.isabs('homework')) # 判断给定路径是否为觉得路径 print(os.path.abspath('homework')) # 返回绝对路径 print(os.path.split('day/homework')) # 把绝对路径分为两部分... print(os.path.dirname('day/homework')) # 返回path的目录。其实就是os.path.split(path)的第一个元素 print(os.path.basename('day/homework')) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 print(os.path.exists('day/homework')) # 如果path存在,返回True;如果path不存在,返回False print(os.path.isfile('homework/目录')) # 判断给定的path是不是一个目录 print(os.path.isdir('homework')) # 判断给定的path是不是一个目录 print(os.path.join('homework','Python.py')) # 拼接地址,可以根据系统自动选择正确的路径分隔符"/"或"\" # 文件的三个时间 print(os.path.getatime('homework')) print(os.path.getctime('homework')) print(os.path.getmtime('homework'))
3 sys模块
import sys sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.version # 返回python解释程序的版本信息 sys.maxsize # 返回最大的int值 sys.path # 返回模块的搜索路径,初始化时使用python环境变量的值 sys.platform # 返回操作系统平台名称,"win32" "linux2" sys.builtin_module_names # 返回python中的所有内建模块的名称 sys.modules # 返回已导入的模块 sys.exit(num) # 退出程序,正常退出时exit(0) sys.stdout sys.stderr sys.stdin # 处理标准输出/输入 # 输出重定向 # 错误输出重定向 # 后期补充吧,我也不知道怎么用
4 time & datetime模块
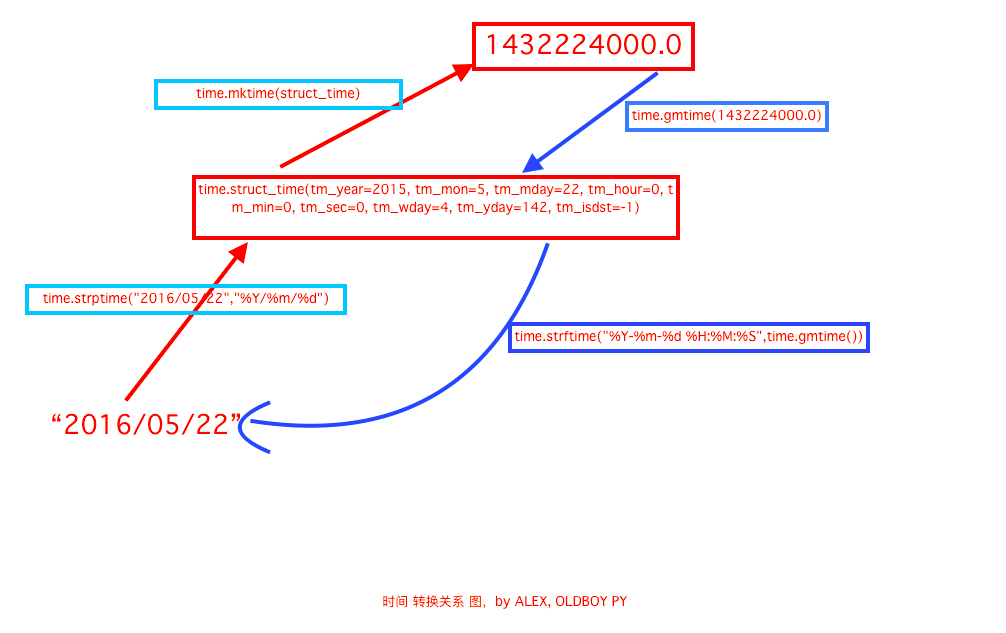
import time print(time.altzone/(60*60)) # 返回与utc时间差,以秒计算 print(time.asctime()) # 返回时间格式'Thu Mar 2 21:55:29 2017' print(time.localtime()) # #返回本地时间 的struct time对象格式 print(time.gmtime()) # 返回utc时间的struc时间对象格式 print(time.asctime(time.localtime())) # 返回时间格式'Thu Mar 2 21:55:29 2017' print(time.ctime()) # 返回时间格式'Thu Mar 2 21:55:29 2017' # 日期字符串 转成 时间戳 string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式 print(string_2_struct) struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳 print(struct_2_stamp) # 将时间戳转为字符串格式 print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式 print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
import time import datetime print(datetime.datetime.now()) # 返回现在时刻,格式'2017-03-02 22:04:26.032785' print(datetime.date.fromtimestamp(time.time())) # 时间戳直接转成日期格式 '2017-03-02' print(datetime.datetime.now() ) print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) # 时间替换
更多可以看这里http://www.runoob.com/python/python-date-time.html
5 random模块
随机数
import random print(random.randint(1,10)) print(random.randrange(1,20,2)) print(random.sample(range(100),5))
生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
import random
import string
print(string.ascii_uppercase)
print(string.ascii_letters)
print(string.ascii_lowercase)
print(string.digits)
soure = string.ascii_uppercase + string.ascii_letters + string.ascii_lowercase + string.digits
print(''.join(random.sample(soure,4)))
6 json & pickle
之前我萌用过的eval内置方法可以将一个字符串转成python对象,不过eval方法有局限性,eval只能对普通的数据类型(数字,字典,元组,列表,集合[我猜的,仅供参考])进行对象和字符串之间转换,当遇到特殊的类型时eval就不灵了,而且eval的重点是用来执行一个字符串表达式,并返回表达式的值。怎么办呢,还好我们有json和pickle序列化模块。
6.1 什么是序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。
6.2 为什么要序列化
1.持久保存当前状态
2.跨平台数据交互
6.3 josn模块
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便
json的使用方法如下:
import json
# json的序列化
date = {'name':'40kuai','age':24}
f = open('test.json','w',encoding='utf-8')
f.write(json.dumps(date))
# json.dump(date,f) # 序列化文件的另一种方式
f.close()
# json的反序列化
f = open('test.json',encoding='utf-8')
date = json.loads(f.read())
# date = json.load(f) # 反序列化文件的另一种方式
print(date)
f.close()
import json #dct="{'1':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}' print(json.loads(dct)) #conclusion: # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
6.4 pickel模块
和json差不多(差到哪儿,下面说),直接来看使用,自己去多撸几遍吧。
import pickle
date = {'name':'40块','age':24}
# pickle的序列化
f = open('test.pickle','wb')
f.write(pickle.dumps(date))
# pickle.dump(date,f) # pickle的另一种方法
f.close()
# pickle的反序列化
f = open('test.pickle','rb')
date = pickle.loads(f.read())
# date = pickle.load(f) # pickle的另一种方法
print(date)
f.close()
6.5 Json 和 Pickle的区别(欢迎指导错误)
1.使用场景
json支持不同语言之间的数据传递,pickle是python中特有的,仅支持python。
2.支持的转换类型
json可以转换普通的数据类型[数字,元组,列表,字典,集合[我猜的,经供参考]],pickle可以序列化python中的任何数据类型。
3.保存的格式
json把数据序列化为字符串,pickle把数据序列化为bytes格式。所有在dump和load时json可以指定文件的编码方式,pickle读写文件为bytes方式。
...
7 shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
import shutil
# 将文件内容拷贝到另一个文件中(操作的是文件对象)
shutil.copyfileobj(open('old.txt',encoding='utf-8'),open('new.txt','w',encoding='utf-8'))
shutil.copyfile(src, dst)
# 将文件内容拷贝到另一个文件中(操作的是文件)
shutil.copyfile('old.txt','new.txt')
shutil.copymode(src, dst)
# 仅拷贝权限,内容、组、用户均不变
shutil.copymode('old.txt','new.txt')
shutil.copystat(src, dst)
仅拷贝状态信息,包括mode bits,atime,mtime,flags
shutil.copystat('old.txt','new.txt')
shutil.copy(src, dst)
# 拷贝文件和权限
shutil.copy('old.txt','new.txt')
shutil.copy2(src, dst)
# 拷贝文件和状态
shutil.copy2('old.txt','new.txt')
shutil.copytree(src, dst, symlinks=False, ignore=None)
# 递归拷贝文件夹
shutil.copytree('homework','test') # 目标文件夹不能存在
# 拷贝软连接
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
'''
通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件
'''
shutil.ignore_patterns(*patterns)
# 拷贝时排除匹配到的文件和文件名
shutil.copytree('homework','test',ignore=shutil.ignore_patterns('a*'))
shutil.rmtree(path, ignore_errors=False, onerror=None)
# 递归的去删除文件夹
# shutil.rmtree('test')
shutil.move(src, dst)
# 递归的去移动,类似mv命令,其实就是重命名
shutil.move('old.txt','new.txt')
shutil.make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, dry_run=0, owner=None, group=None, logger=None)
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir:压缩的根目录。默认为当前目录
- base_dir:开始压缩的目录。默认为当前目录
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
# 常用方法如下:
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
#将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
import shutil
shutil.make_archive('homework','zip',root_dir='homework/atm/')
shutil.make_archive('homework','zip',base_dir='homework/atm/')
# 顺便看下root_dir和base_dir的区别吧
shutil对压缩的处理调用的是zipfile和tarfile两个模块进行的,详细:
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall(path='.') z.close()
import tarfile # 压缩 tar = tarfile.open('your.tar','w') tar.add('/Users/wupeiqi/PycharmProjects/bbs2.log', arcname='bbs2.log') tar.add('/Users/wupeiqi/PycharmProjects/cmdb.log', arcname='cmdb.log') tar.close() # 解压 tar = tarfile.open('your.tar','r') tar.extractall() # 可设置解压地址 tar.close()
8 shelve 模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
shelve.open(filename,flag='c',protocol=None,writeback=False)
打开一个保存字典对象方式储存的文件,返回字典对象。参数filename是要保存或打开的文件名称;参数flag与dbm.open()函数里的参数一样;参数protocol是pickle协议的版本;参数writeback是指定是否缓存在内存,如果设置为True则缓存在内存里。
open函数关于打开dbm的方式有三种标志用法:
C打开文件对其读写,必要时创建该文件
W打开文件对其读写,如果文件不存在,不会创建它
N打开文件进行读写,但总是创建一个新的空白文件
Shelf.sync()
如果打开文件时选择参数writeback为True时,调用本函数就会把缓存在内存里的数据写入文件。
# shelve序列化文件并存储
import shelve
s1 = {'name':'40kuai','names':'40块','age':19}
s2 = {'name':'alex','names':'艾利克斯','age':39}
lis = [1,2,3,4,5,6]
f = shelve.open('shelvedate')
f['40kuai'] = s1
f['alex'] = s2
f['lis'] = lis
f.close()
# shelve文件读取
f = shelve.open('shelvedate',flag='w')
lis = f['lis']
print(lis)
f.close()
# 输出 [1, 2, 3, 4, 5, 6]
9 xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
自己创建xml文档:
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式
10 configparser模块
来看一个好多软件的常见文档格式如下:
1 [DEFAULT] 2 ServerAliveInterval = 45 3 Compression = yes 4 CompressionLevel = 9 5 ForwardX11 = yes 6 7 [bitbucket.org] 8 User = hg 9 10 [topsecret.server.com] 11 Port = 50022 12 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser config = configparser.ConfigParser() # 第一种方式 config['default'] = { 'servername':'40kuaiserver', 'server_setting':'/etc/server/config', 'server_port': 8080 } # 第二种方式 config['bitbucket.org'] = {} config['bitbucket.org']['User'] = 'hg' # 第三种方法 config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = 50022 topsecret['ForwardX11'] = 'no' config['DEFAULT']['ForwardX11'] = 'yes' with open('config.ini','w')as config_file: config.write(config_file)
写完之后要怎么读呢?
先来看看用法吧。
-read(filename) 直接读取ini文件内容
-sections() 得到所有的section,并以列表的形式返回
-options(section) 得到该section的所有option
-items(section) 得到该section的所有键值对
-get(section,option) 得到section中option的值,返回为string类型
-getint(section,option) 得到section中option的值,返回为int类型
import configparser config = configparser.ConfigParser() config.read('example.ini') print(config.sections()) print(config['bitbucket.org']['user']) topsecret = config['topsecret.server.com'] print(topsecret['forwardx11']) print(topsecret['host port']) for key in config['bitbucket.org']: print(key)
configparser增删改查语法
import configparser config = configparser.ConfigParser() #---------------------------------------------查 print(config.sections()) #[] config.read('example.ini') print(config.sections()) #['bitbucket.org', 'topsecret.server.com'] print('bytebong.com' in config)# False print(config['bitbucket.org']['User']) # hg print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no for key in config['bitbucket.org']: print(key) # user # serveraliveinterval # compression # compressionlevel # forwardx11 print(config.options('bitbucket.org'))#['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'] print(config.items('bitbucket.org')) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] print(config.get('bitbucket.org','compression'))#yes #---------------------------------------------删,改,增(config.write(open('i.cfg', "w"))) config.add_section('yuan') config.remove_section('topsecret.server.com') config.remove_option('bitbucket.org','user') config.set('bitbucket.org','k1','11111') config.write(open('i.cfg', "w"))
configparser的详细用法:http://blog.csdn.net/gexiaobaohelloworld/article/details/7976944
11 hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
MD5 算法三个特点:
1.内容相同则hash运算结果相同,内容稍微改变则hash值则变
2.不可逆推
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
import hashlib hash = hashlib.md5() # help(hash.update) # hash.update(bytes('admin', encoding='utf-8')) # hash.update('admin'.encode('utf-8')) # hash.update(bytes('admin',encoding='utf8')) hash.update(b'admin') print(hash.hexdigest()) print(hash.digest()) ''' 注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样 但是update多次为校验大文件提供了可能。 '''
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # ######## 256 ######## hash = hashlib.sha256('898oaFs09f'.encode('utf8')) hash.update('alvin'.encode('utf8')) print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac # 第一种方式 h = hmac.new(bytes('天王盖地虎', encoding="utf-8")) h.update('宝塔镇河妖'.encode(encoding='utf-8')) print(h.hexdigest()) # 第二种方式 h = hmac.new('天王盖地虎'.encode(encoding='utf-8'), '宝塔镇河妖'.encode(encoding='utf-8')) print(h.hexdigest())
12.
suprocess
13. logging模块
拍桌子! logging很重要, 来整理下。 回炉重学
logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别
最简单的用法
import logging
logging.debug('debug ....')
logging.info('info ....')
logging.warning('warning ....')
logging.critical("server is down")
# 输出
WARNING:root:warning ....
CRITICAL:root:server is down
# 由此可以得到,默认的日志级别为warning
在logging中可以设置日志级别以及日志文件路径等。
import logging
# 在设置level时,可以指定日志级别的关键字,也可以指定日志的数字级别,这里的logging.INFO指定的就是数字级别为20,也可以直接输入20
logging.basicConfig(filename='test.log',level=logging.INFO)
logging.debug('debug ....')
logging.info('info ....')
logging.warning('warning ....')
logging.critical("server is down")
logging.basicConfig函数各个参数:
filename: 指定日志文件名
filemode: 和file函数意义相同,指定日志文件的打开模式,'w'或'a'
format: 指定输出的格式和内容,format可以输出很多有用信息,如下图所示:
datefmt: 指定时间格式,同time.strftime()
level: 设置日志级别,默认为logging.WARNING
stream: 指定将日志的输出流,可以指定输出到sys.stderr,sys.stdout或者文件,默认输出到sys.stderr,当stream和filename同时指定时,stream被忽略
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息
|
若要对logging进行更多灵活的控制有必要了解一下Logger,Handler,Formatter,Filter的概念
logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息)
logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),,设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数
另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
下面我们就用getLogger来看看如何输出日志信息吧。
import logging # 创建两个logger logger = logging.getLogger() # 此为默认的logger logger_test = logging.getLogger('test') logger_test.setLevel(logging.WARNING) # 设置自定义的日志级别 # 创建一个handler,用于写入日志文件 file_handler = logging.FileHandler(filename='file_log') # 创建一个handler,用户输出到控制台 stream_handler = logging.StreamHandler() # 定义日志输出格式 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') file_handler.setFormatter(formatter) stream_handler.setFormatter(formatter) # 定义一个filter # filter = logging.Filter('mylogger.child1.child2') # fh.addFilter(filter) # 给logger添加handler # logger.addFilter(filter) logger.addHandler(file_handler) logger.addHandler(stream_handler) # logger1.addFilter(filter) logger_test.addHandler(file_handler) logger_test.addHandler(stream_handler) # 记录日志 logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message') logger_test.debug('logger1 debug message') logger_test.info('logger1 info message') logger_test.warning('logger1 warning message') logger_test.error('logger1 error message') logger_test.critical('logger1 critical message')
logging之日志回滚
import logging
from logging.handlers import RotatingFileHandler
#################################################################################################
#定义一个RotatingFileHandler,最多备份5个日志文件,每个日志文件最大10M
Rthandler = RotatingFileHandler('myapp.log', maxBytes=10*1024*1024,backupCount=5)
Rthandler.setLevel(logging.INFO)
formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
Rthandler.setFormatter(formatter)
logging.getLogger('').addHandler(Rthandler)
################################################################################################
logging.debug('This is debug message')
logging.info('This is info message')
logging.warning('This is warning message')
从上例和本例可以看出,logging有一个日志处理的主对象,其它处理方式都是通过addHandler添加进去的。
logging的几种handle方式如下:
logging.StreamHandler: 日志输出到流,可以是sys.stderr、sys.stdout或者文件 logging.FileHandler: 日志输出到文件 日志回滚方式,实际使用时用RotatingFileHandler和TimedRotatingFileHandler logging.handlers.BaseRotatingHandler logging.handlers.RotatingFileHandler logging.handlers.TimedRotatingFileHandler logging.handlers.SocketHandler: 远程输出日志到TCP/IP sockets logging.handlers.DatagramHandler: 远程输出日志到UDP sockets logging.handlers.SMTPHandler: 远程输出日志到邮件地址 logging.handlers.SysLogHandler: 日志输出到syslog logging.handlers.NTEventLogHandler: 远程输出日志到Windows NT/2000/XP的事件日志 logging.handlers.MemoryHandler: 日志输出到内存中的制定buffer logging.handlers.HTTPHandler: 通过"GET"或"POST"远程输出到HTTP服务器
由于StreamHandler和FileHandler是常用的日志处理方式,所以直接包含在logging模块中,而其他方式则包含在logging.handlers模块中,
通过logging.config模块配置日志http://blog.csdn.net/yatere/article/details/6655445
14.
re模块
15.
requests
16.
paramiko
未完待续...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号