

【noip模拟】Div.2
11.17 字符串
把 \(C\) 记为 \(1\),\(T\) 记为 \(-1\)。考虑暴力贪心:从前往后扫一遍,若前缀和 \(<0\) 就删掉当前字符,然后在从后往前扫一边。
直接想不太能做,考虑把它数学化。记区间 \([l,r]\) 的前后缀和为 \(pre,suf\),第一次扫删掉的数就是 \(-\min\{pre\}\),第二次扫时后缀和 \(suf'_{j}=suf_{j}+(-\min\{pre\}+\min_{i<j}\{pre_{i}\})\),最终答案为 \(-\min\{pre\}-\min\{suf'\}=-\min_{i<j}\{pre_{i}+suf_{j}\}\),即为区间和减最大字段和,线段树维护即可
11.16 棋盘
发现转移是个矩阵且具有可加性(\([r,i,j]\) 记录从第 \(1\) 行第 \(i\) 列到第 \(r\) 行第 \(j\) 的方案数),直接用线段树维护可以做到 \(O(qn^{2}\log q)\)。注意转移有跳两行的情况,因此还要多维护一个矩阵。
题目的 push,pop 操作本质上是个队列,可以使用双栈模拟队列的 trick。路径可逆,记录前缀积即可。时间复杂度 \(O(qn^{2})\)
code
char readc() { char c; while(!isupper(c=getchar())); return c; }
const int N = 25, Q = 1e5+5, mod = 998244353;
int n,q,l=1,mid,r,a[Q][N][N],b[Q][N][N];
// [l,mid] [mid,r]; a: mid->l,r; b: mid-1->l,mid+1->r;
bool s[Q][N];
void ckadd(int &x,int y) { x = x+y<mod ? x+y : x+y-mod; }
bool input() { char c; while((c=getchar())!='.'&&c!='#'); return c=='.'; }
void init(int f[][N][N],int u) { For(i,1,n) f[u][i][i] = s[u][i]; }
void tran(int f[][N][N],int u,int x,int y) {
memset(f[u],0,sizeof f[u]);
For(i,1,n) if( s[u][i] ) For(j,1,n) {
if( i > 2 ) ckadd(f[u][i][j],f[x][i-2][j]);
if( i+2 <= n ) ckadd(f[u][i][j],f[x][i+2][j]);
if( i > 1 ) ckadd(f[u][i][j],f[y][i-1][j]);
if( i+1 <= n ) ckadd(f[u][i][j],f[y][i+1][j]);
}
}
void rebuild() {
mid = r;
memset(a[r],0,sizeof a[r]), init(a,r);
rFor(i,r-1,l) tran(a,i,i+1,i+2<=r?i+2:0);
if( l == r ) return;
memset(b[r-1],0,sizeof b[r-1]), init(b,r-1);
rFor(i,r-2,l) tran(b,i,i+1,i+2<r?i+2:0);
}
signed main() {
freopen("chess.in","r",stdin);
freopen("chess.out","w",stdout);
read(n,q);
while( q-- ) {
char op = readc();
if( op == 'A' ) {
++r; For(i,1,n) s[r][i] = input();
if( mid < l ) rebuild();
else {
if( r == mid+1 ) tran(a,r,r-1,0), init(b,r);
else tran(a,r,r-1,r-2), tran(b,r,r-1,r-2>mid?r-2:0);
}
} else if( op == 'D' ) {
if( ++l > mid && l <= r ) rebuild();
} else {
int x,y; read(x,y);
if( l > r || !s[l][x] || !s[r][y] ) { write(0); continue; }
if( l == r ) { write(x==y); continue; }
LL ans = 0;
For(i,1,n) (ans += (LL)a[l][x][i] * a[r][y][i]) %=mod; // -> mid ->
if( l < mid && mid < r ) For(i,1,n) { // -> mid-1 -> mid+1 ->
if( i > 1 ) (ans += (LL)b[l][x][i] * b[r][y][i-1]) %=mod;
if( i < n ) (ans += (LL)b[l][x][i] * b[r][y][i+1]) %=mod;
}
write(ans);
}
}
return ocl();
}
11.16 军队
难点在于矩形加,预处理每行值 \(<10\) 的元素个数。
考虑扫描线,扫到每一行时统计该行答案。朴素的想法是记录区间最大值和最小值并用此剪枝,但很容易被卡到 \(O(nm)\)。
考场上的想法是每次修改打时间戳,如果一个节点的时间戳小于当前修改的时间,那么可以它对应区间的答案不变,不需要再次计算,否则递归下去。看上去很玄学但跑得很快(并且空间是 \(O(n)\) 的),求证明时间复杂度/hack。
正解是记录每个区间最小的 \(10\) 个值及其出现次数,归并合并,时间复杂度 \(O(n\log n)\),空间复杂度 \(O(20n)\)
另:题解说询问可以 \(O(1)\),求做法
11.11 树上路径
如果树上两条路径没有点交,那么一定存在一条边能将这两条路径分到两边。除了这点考场上全想到了。。。
枚举这条边,换根 DP 求出两边的直径,那么小于这两边直径的方案都可行,以 \(L(a,b),L(c,d)\) 建坐标系,就是类似矩形并的东西,求后缀 \(\max\) 之和即可
换根 DP 时需要求出不同子树深度前三大值,记一个比较妙的写法:
void ckmax(int a[],int n,int x) { Rep(i,0,n) if( x > a[i] ) swap(x,a[i]); }
11.11 第 k 大查询
考场上想了一车 \(\log\) 做法,试图魔改单调栈失败。。。
先看对题,要求第 \(k\) 大,不要想当然写成第 \(k\) 小(甚至能过小样例)
难点是 \(O(nk)\) 处理每个数前后第 \(i\in[1,k]\) 个比它大的数的位置。
元素是一个排列,因此不存在相等的情况,考虑从大到小枚举元素,用链表便于删除的特性维护比它大的元素位置(即未枚举到的数),对于每个数直接在链表对应位置上向前后跳 \(k\) 下,然后删除该元素即可。
注意空间是 \(O(n+k)\) 的
11.8 NOIP 2018
考场上一直想的是二分答案/三分其中一种换多少个,问题在于值域过大和不一定单峰
考虑二分 \(mid\) 表示把 \(\le mid\) 的货币全部兑换,解下方程可以 \(O(1)\) 计算需要多少花费和能兑换的货币数量,需要特判边界。
由于值域过大,二分的上界不能为 \(n\),我的做法是先通过 long double 二分出只换某种货币是最多能换多少个,从而得到更紧的上界。也有其他做法
code
LL a,b,c,d,n;
LL maxx(LD k, LD b) {
LD l = 0, r = sqrt(2*n/k)+1;
while( l+1e-9 < r ) {
LD x = (l+r)/2;
k*x/2+b-k/2<n/x ? l=x : r=x;
}
return ceil(k * l + b);
}
pair<LL,LL> calc(LL b,LL k,LL x) {
LL i = (x-b+k)/k;
return i>0 ? MP(k*i*i/2+b*i-k*i/2,i) : MP(0ll,0ll);
}
bool check(LL mid) { return calc(a,b,mid).fi+calc(c,d,mid).fi <= n; }
void MAIN() {
read(a,b,c,d,n);
LL l = 0, r = min(min(maxx(b,a),maxx(d,c))+1,n);
while( l < r ) {
LL mid = l+r+1>>1;
check(mid) ? l=mid : r=mid-1;
}
auto x = calc(a,b,l), y = calc(c,d,l);
write(x.se+y.se+(n-x.fi-y.fi>=min(b*x.se+a,d*y.se+c)));
} signed main() {
freopen("money.in","r",stdin);
freopen("money.out","w",stdout);
int T; read(T); while( T-- ) MAIN();
return ocl();
}
11.5 校门外歪脖树上的鸽子
考场正解,结果 \(1\)h 没冲完爆 \(0\) 了。。。
添加两个点 \([0,0],[n+1,n+1]\),然后每次操作可以看成对一条链上每个点的左/右兄弟操作(类似 zkw 线段树),用树剖+两颗线段树分别维护左/右兄弟。时间复杂度 \(O(m\log^{2}n)\)
这题带来两个启示:
- 学 DS 时注重它的思想、复杂度由什么保证/拖累、如果有特殊性质能不能优化,在考场上能省很多时间/避免写假做法,但切记不要钻牛角尖,实在想不通就跳出来
- 考场上写 DS 前三思,写的时候心态一定要平和。这题考场上想的就是 rush,结果细节上一堆 bug
11.4 排水系统
设原图设 \(u\) 的流量为 \(f\),出度 \(out\),\((u,v)\) 堵塞的概率为 \(p\)
考虑整体计算。发现如果 \((u,v)\) 堵塞,那么 \(u\) 的流量不变,\(v\) 的减少,\(u\) 的其他出边增加,且转移不变。
可以看作 \(v\) 的流量凭空减少 \(p(\frac{f}{out}+\frac{f}{out(out-1})\),\(u\) 的流量凭空增加 \(p\frac{f}{out-1}\)(即原本流到 \(v\) 的 \(\frac{f}{out}\) 流到了其他 \(out-1\) 条出边)
等价于每个点初始有流量,对所有边进行类似的处理,然后拓扑排序即可。时间复杂度 \(O(n+k)\)
11.4 子集
每连续 \(k\) 个数一定是每个子集一个,因此可以映射到 \([1,k]\)
分类讨论:
-
\(\frac{n}{k}\) 为偶数:将 \((1,k),(2,k-1)\cdots(k,1)\) 配对,均分给每个子集
-
\(\frac{n}{k}\) 为奇数:
- \(k\) 是偶数:考虑每个子集拿出 \(3\) 个元素转化成 \(\frac{n}{k}\) 是偶数的情况。拿出的 \(3\) 个元素如下
第 \(1\) 个 第 \(2\) 个 第 \(3\) 个 \(1\) \(\frac{k}{2}+1\) \(k\) \(\frac{k}{2}+2\) \(1\) \(k-1\) \(2\) \(\frac{k}{2}+2\) \(k-2\) \(\frac{k}{2}+3\) \(2\) \(k-3\) \(\cdots\) \(\cdots\) \(\cdots\) \(k\) \(\frac{k}{2}\) \(2\) \(\frac{k}{2}+1\) \(k\) \(1\) 关键是构造出两个元素和为等差数列。对于相邻两个子集,令其中一个元素相等,另一个差 \(1\) 即可。
- \(k\) 是奇数:每个子集的元素和 \(\frac{n(n+1)}{2k}\) 为小数,无解
10.20 色球
显然的双向链表维护栈,问题是翻转时需要改变链表的前后,当时的想法是像 LCT 一样打标记。T3 推出了矩阵的式子,随便维护就有 70pts,想着 rush 完去想 T3,结果一调就是 2h。。。
调完发现 T 的厉害,仔细一想了 LCT 的复杂度由 Splay 树高 \(\log\) 保证,可以每次暴力下放翻转标记。gg
sol 1
直接上平衡树 \(O(n\log n)\)/块链 \(O(n\sqrt{n})\) 维护序列
sol 2
启发式合并栈 \(O(n\log n)\)
sol 3
双向链表,通过和上一个元素比较可以知道哪个指针是指下一个的,因此不需要打翻转标记,\(O(n)\)
10.19 光线追踪
可见我思维之僵化,一张图秒懂
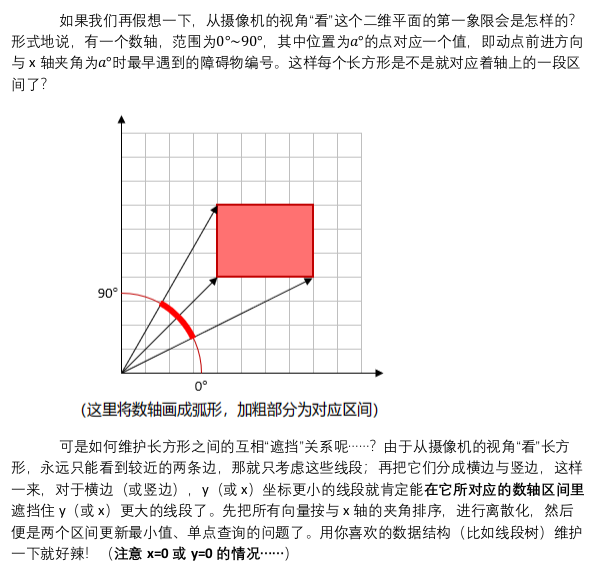
10.16 o
考场用暴力艹过去了,正解暂鸽
10.12 小说
记修改的袋子为 \(p\),\(res_p\) 为用 \(i\ne p\) 的袋子可以拼出的容量数
显然将 \(v_p\leftarrow\sum_{i\ne p}v_i+1\) 可以使答案变为 \(2res_p+1\),问题变为找最大的 \(res_p\)
暴力想法是枚举 \(p\),用其他袋子背包,bitset 优化一下可以做到 \(O(\frac{n^3v}{\omega})\),能艹过去
正解是先对 \(n\) 个袋子背包(记录方案数),然后对当前枚举的 \(p\) 退背包。问题是方案数可能爆 long long,发现我们只想知道某个容量的方案数是否非 \(0\),可以把方案数对一个或多个大质数取模。时间复杂度 \(O(n^2v)\)
修改后的值 \(v_p'\) 满足原来能拼成的容量 \(x\),\(x+v_p'\) 不能拼成时答案最小,用 \(v_i,-v_i\ (i\ne p)\) 做 \(0/1\) 背包,取不能拼出的最小值即可
10.9 T1 出了个大阴间题
花费中的 \(b_1+b_2\) 与合并顺序无关,由方案数可以直接算,考虑 DP 出合并最大值的方案数和花费中的 \(a\)。
记 \(mx[s]\) 为 \(\max_{i\in s}\{a_i\}\),发现集合 \(s\) 能合并出的最大值最多为 \(mx[s]+1\),因此可以设 \(f[s,i]\) 为集合 \(s\) 合并出最大值 \(mx[s]+i\) 的花费,\(g[s,i]\) 为方案数。
转移时枚举下一个合并的元素,判断 \(a\) 能否 \(+1\) 即可
时间复杂度 \(O(2^{n}n)\)
10.7 朝鲜时蔬
这是一道传统题
简述题意:
设 \(sum(S)=\sum_{x\in S}x,f_k(S)=\sum_{T\subseteq S,|T|=k}[sum(T)|sum(S)]\)
给定集合 \(S=\{1,2,3,\cdots,n\}\),求 \(\sum_{T\subseteq S,|T|=m}[f_k(T)=\max\{f_k(T),T\subseteq S,|T|=m\}]\)
sol 写的很清楚了,核心是考虑 \(\max\{f_k(T),T\subseteq S,|T|=m\}\) 是多少,合法的 \(T\) 有哪些性质,通过推不等式、整除分块来加速计算。
一些 trick:
- \(a<b\Rightarrow b\nmid a\Rightarrow b\nmid(a+b)\)
- 计数 \(a,b>0,a+b\le n,a\ne b\):枚举 \(a+b\) 再拆分
对于更多数的情况容斥即可
- \(a|b\),设 \(xa=a+b\)
注意细节
// nn = n%mod
LL Pow(LL x,LL y=mod-2)
{ LL res=1; for(;y;y>>=1,x=x*x%mod)if(y&1)res=res*x%mod; return res; }
LL s(LL n) { n %=mod; return n * (n+1) %mod * Pow(2) %mod; }
LL s(LL l,LL r) { return (s(r) - s(l-1) +mod) %mod; }
LL s2(LL n) { n %=mod; return n * (n+1) %mod * (2*n+1) %mod * Pow(6) %mod; }
LL s2(LL l,LL r) { return (s2(r) - s2(l-1) +mod) %mod; }
LL cnt(LL n,int x) { return n / x %mod; }
LL cnt(LL l,LL r,int x) { return (cnt(r,x) - cnt(l-1,x) +mod) %mod; }
LL solve11() { return nn; }
LL solve21() {
LL res = 0;
for(LL l = 1, r; l <= n; l = r+1) {
r = min(n,n/(n/l));
(res += cnt(l,r,1) * (n/l %mod)) %=mod;
}
return (res-nn+mod)%mod;
}
LL solve22() { return nn * (nn-1) %mod * Pow(2) %mod; }
LL solve31() { return n / 3 %mod; }
LL solve32() {
LL res = 0;
for(LL l = 1, r; l <= n; l = r+1) {
r = min(n,n/(n/l));
(res += (s(l,r)-cnt(l,r,1)-cnt(l,r,2)) %mod * (n/l %mod)) %=mod;
}
return (res+mod) * Pow(2) %mod;
}
LL solve33() { return nn * (nn-1) %mod * (nn-2) %mod * Pow(6) %mod; }
LL solve41() {
if( n == 4 || n == 5 ) return 1;
return (n/6 + n/9 + n/10 + n/12 + n/15 + n/21) %mod;
}
LL solve42() {
if( n == 4 || n == 5 || n == 6 ) return 1;
if( n == 7 ) return 3;
if( n == 8 ) return 6;
if( n == 9 ) return 9;
if( n == 10 ) return 10;
return (n/11 + n/29) %mod;
}
LL solve43() {
if( n == 4 ) return 1;
if( n == 5 ) return 5;
LL res = 0;
for(LL l = 1, r; l <= n; l = r+1) {
r = min(n,n/(n/l));
(res += (s2(l,r) - 6*s(l,r) + 5*cnt(l,r,1) + 3*cnt(l,r,2) +
4*cnt(l,r,3)) %mod * (n/l %mod)) %=mod;
}
return (res+mod) * Pow(12) %mod;
}
LL solve44()
{ return nn * (nn-1) %mod * (nn-2) %mod * (nn-3) %mod * Pow(24) %mod; }
9.23 糖果
先考虑 \(a\) 都相同的情况,\(n\le10^{18}\) 提示需要 \(\log n\) 算法,考虑倍增 DP。
设 \(h[i,j]\) 表示前 \(2^i\) 种糖果选出 \(j\) 个排列的方案数,则
\(n\) 种糖果的方案数可以由 \(h\) 合并得到。
如果 \(a\) 不同,可以先将 \(a\) 与 \(m\) 取 \(\min\),这样 \(a\) 的值域变为 \(m\),通过 \(a\) 有循环节,可以 \(O(p+m)\) 时间内算出每个值有多少个品种。
然后对于不同的 \(a\) 分别进行上面的 DP,最后背包合并起来即可。
值得一提的是三处 DP 转移相同,因此可以将代码写的很好看
抄的 std DP 部分
void dp(LL *x,LL *y) {
static LL z[N]; mem(z,0,m);
For(i,0,m) For(j,0,i) z[i] = (z[i] + x[j]*y[i-j]%mod*C[i][j])%mod;
memcpy(x,z,sizeof(LL)*(m+1));
}
signed main() {
f[0] = 1;
For(i,1,m) {
mem(g,0,m), mem(h,0,m); g[0] = 1;
For(j,0,i) h[j] = 1;
if( cnt[i] & 1 ) dp(g,h);
For(j,1,60) {
dp(h,h);
if( cnt[i] & (1ll<<j) ) dp(g,h); // 有cnt[i]个a=i
}
dp(f,g); // g:cnt[i]个i的答案
}
write(f[m]);
}
9.21 舞动的夜晚
二分图最大匹配的可行边
先任意求一组最大匹配,然后建新图:
匹配边 \((i,j)\):\(j\rightarrow i\),非匹配边 \((i,j)\):\(i\rightarrow j\)
左部匹配点 \(i\):\(i\rightarrow s\),右部匹配点 \(i\):\(t\rightarrow i\)
左部非匹配点 \(i\):\(s\rightarrow i\),右部非匹配点 \(i\):\(i\rightarrow t\)
则边 \((i,j)\) 是可行边的条件为 \((i,j)\) 在原最大匹配中或 \(i,j\) 在同一 SCC 中
正确性:
考虑匈牙利算法找增广路:从左部点出发,沿非匹配边走到右部点,再沿匹配边走到左部点 \(\cdots\cdots\)
如果在原最大匹配的基础上跑,那么一定会在左部点结束(否则就找到增广路了),将沿途边的匹配情况取反匹配数不变,即其中的非匹配边都是可行边,而这些点形成了 \(s\rightarrow\) 左部点 \(\rightarrow\) 右部点 \(\rightarrow\cdots\rightarrow s\) 的环,一定在同一 SCC 中。
9.21 Lesson5!
DAG 删点最长路
9.20 2D
9.18 底垫
显然要离线询问,从小到大扫右端点。
先计算总爆零题数(即子区间的线段并集长度之和),答案再除以子区间数即可。
用 ODT 维护值域上每个数最后一次出现的时间(相同的相邻数合为一段),设当前扫到了 \(i\),可以快速得出新加入的区间会更新哪些段。
记其中一段的长度为 \(k\),时间为 \(t\),这段的贡献为:
对 \(l\in[t+1,i]\) 贡献 \((i-l+1)(r-i+1)k\)(左端点 \(\in[l,i]\),右端点 \(\in[i,r]\) 的子区间线段并集长度 \(+k\))
对 \(l\in[1,t]\) 贡献 \((i-t)(r-i+1)k\)(左端点 \(\in[1,t]\) 的子区间线段并集中已有这段)
拆一下式子,BIT 维护每个左端点 \(l,r,lr\) 的系数和常数项即可。
时间复杂度 \(O(n\log n)\)
9.14 午餐
9.13 树
根号全家桶:根号分治+分块平衡复杂度+根号重构节省空间
先用 dfs 序把子树转化为区间;将 \(y\) 加上 \(dep[v]\) 把与 \(v\) 距离转化为与根距离
- \(x\le\sqrt n\)
模数、余数只有 \(\sqrt n\) 种,枚举模数后维护每个余数被加了多少,每个询问对每个模数查询一次
需要 \(q\) 次区间加,\(q\sqrt n\) 次单点查询,采用 \(O(\sqrt n)-O(1)\) 的朴素分块
- \(x>\sqrt n\)
每个修改只会对 \(\sqrt n\) 个深度造成影响,枚举深度后进行修改,每个询问只会在枚举到它的深度时查询
如果直接把修改挂在深度上会造成 \(q\sqrt n\) 的空间复杂度,事实上只要每隔 \(\sqrt n\) 个深度算出所有修改对接下来 \(\sqrt n\) 个深度中哪个造成影响即可(显然在连续 \(\sqrt n\) 个深度中每个修改最多对一个造成影响)
需要 \(q\sqrt n\) 次区间加,\(q\) 次单点查询,采用 \(O(1)-O(\sqrt n)\) 的分块维护差分
时间复杂度 \(O((n+q)\sqrt n)\),空间复杂度 \(O(n+q)\)
code
#define MT make_tuple
int _ceil(int x,int y) { return (x+y-1) / y; }
const int N = 3e5+5, B = 547, M = 555;
int n,q;
VI to[N];
int ind,mxd,dfn[N],dep[N],siz[N],ans[N],be[N],le[M],ri[M];
void dfs(int u,int fa) {
dfn[u] = ++ind, dep[u] = dep[fa]+1, ckmax(mxd,dep[u]), siz[u] = 1;
for(int v : to[u]) if( v != fa ) dfs(v,u), siz[u] += siz[v];
}
namespace solve1 {
vector<PII> q;
vector<tuple<int,int,int,int>> a[M];
int dep[N],val[N],add[M][M];
void bf(int l,int r,int d,int x)
{ For(i,l,r) if( dep[i] == d ) val[i] += x; }
void modify(int l,int r,int d,int x) {
int bl = be[l], br = be[r];
if( bl == br ) return bf(l,r,d,x);
bf(l,ri[bl],d,x), bf(le[br],r,d,x);
For(i,bl+1,br-1) add[i][d] += x;
}
int query(int i) { return val[i] + add[be[i]][dep[i]]; }
void main() { For(mod,1,B) {
mem(val,0,n), memset(add,0,sizeof add);
For(i,1,n) dep[dfn[i]] = ::dep[i] %mod;
int i = 0; for(auto j : a[mod]) { int t,u,d,x; tie(t,u,d,x) = j;
for(; i < q.size() && q[i].fi < t; ++i)
ans[q[i].fi] += query(dfn[q[i].se]);
modify(dfn[u],dfn[u]+siz[u]-1,d,x);
}
for(; i < q.size(); ++i) ans[q[i].fi] += query(dfn[q[i].se]);
}}
}
namespace solve2 {
vector<PII> q[N];
vector<tuple<int,int,int,int,int>> a;
vector<tuple<int,int,int>> b[B];
int val[N],sum[M];
void modify(int l,int x) { val[l] += x, sum[be[l]] += x; }
void modify(int l,int r,int x) { modify(l,x), modify(r+1,-x); }
int query(int r) {
int br = be[r], res = 0;
For(i,1,br-1) res += sum[i];
For(i,le[br],r) res += val[i];
return res;
}
void main() { For(d,1,mxd) {
if( d % B == 1 ) {
For(i,0,B-1) b[i].clear();
for(auto i : a) { int t,u,x,y,z; tie(t,u,x,y,z) = i;
int j = _ceil(d-y,x) * x + y;
if( j < d+B ) b[j%B].pb(MT(t,u,z));
}
}
mem(val,0,n), mem(sum,0,be[n]);
int i = 0; for(auto j : b[d%B]) { int t,u,x; tie(t,u,x) = j;
for(; i < q[d].size() && q[d][i].fi < t; ++i)
ans[q[d][i].fi] += query(dfn[q[d][i].se]);
modify(dfn[u],dfn[u]+siz[u]-1,x);
}
for(; i < q[d].size(); ++i) ans[q[d][i].fi] += query(dfn[q[d][i].se]);
}}
}
signed main() {
read(n,q);
For(i,2,n) { int x,y; read(x,y); to[x].pb(y), to[y].pb(x); }
dfs(1,0);
For(i,1,q) {
int op,u,x,y,z; read(op,u);
if( op == 1 ) {
read(x,y,z); y = (y + dep[u]) %x;
if( x <= B ) solve1::a[x].pb(MT(i,u,y,z));
else solve2::a.pb(MT(i,u,x,y,z));
ans[i] = -1;
} else solve1::q.pb(MP(i,u)), solve2::q[dep[u]].pb(MP(i,u));
}
For(i,1,n) be[i] = (i-1)/B+1;
For(i,1,be[n]) le[i] = ri[i-1]+1, ri[i] = ri[i-1]+B; ri[be[n]] = n;
solve1::main(), solve2::main();
For(i,1,q) if( ~ans[i] ) write(ans[i]);
return iocl();
}

