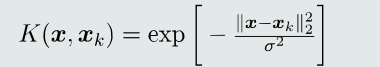《机器学习》第二次作业——第四章学习记录和心得
第四章:线性判据与回归
思维导图

4.1线性判据基本概念
-
生成模型:给定训练样本 {𝒙𝑛}, 直接在输入空间内学习其概率密度函数𝑝(𝒙)。
优点:①可以根据𝑝(𝒙)采样新的样本数据;②可以检测出较低概率的数据,实现离群点检测。
缺点:如果是高维的𝒙,需要大量训练样本才能准确的估计𝑝(𝒙),否则,会出现维度灾难问题。 -
判别模型:给定训练样本 {𝒙𝑛}, 直接在输入空间内估计后验概率𝑝(𝐶𝑖|𝒙)。
优点:快速直接、 省去了耗时的高维观测似然概率估计。 -
线性判据
定义:①如果判别模型𝑓(𝒙)是线性函数,则𝑓(𝒙)为线性判据。
②可以用于两类分类,决策边界是线性的。
③也可以用于多类分类,相邻两类之间的决策边界也是线性的。
优点:计算量少,在学习和分类过程中,线性判据方法都比基于学习概率分布的方法计算量少。适用于训练样本较少的情况。
数学表达:

决策边界:𝑑维空间上的超平面,此时对应 f(x)= 0
𝒘方向:决定了决策边界H的方向
任意样本x到决策边界的距离:r = f(x) / ||w||
4.2线性判据学习概述
-
线性判据:学习和识别过程
监督式学习(训练)过程:基于训练样本{𝒙1,𝒙2,…,𝒙𝑁}及其标签{𝑡1,𝑡2,…,𝑡𝑁},设计目标函数,学习𝐰和𝑤0。
识别过程:将待识别样本𝒙带入训练好的判据方程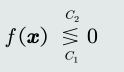
解不唯一:由于训练样本个数通常会远远大于参数个数(𝒘的维度+ 𝑤0的维度),所以线性判据满足条件的解不唯一。学习算法就是要找到一个最优解。如何找到最优解:

目标函数的求解: 最小化/最大化目标函数,涉及优化技术。
解析求解:求关于训练参数的偏导,并设置偏导为0。
迭代求解: 先猜测参数初始值,然后不断的根据当前计算得到的更新值迭代更新参数。
加入约束条件提高泛化能力。
4.3并行感知机算法
- 感知机算法:预处理

几何解释:在几何上,通过在特征空间上增加一个维度,使得决策边界可以通过原点(𝑤0项);翻转𝐶2类的样本:得到一个平面使得所有样本位于该平面同一侧。 - 目标函数:被错误分类的样本最少。
针对所有被错误分类的训练样本(即输出值小于0的训练样本),其输出值取反求和:
J(a) = −ΣaTy,Y={y|aTy<=0} (该目标函数是关于a的一次线性函数)
最小化该目标函数:取目标函数关于 𝒂 的偏导(即梯度):𝜕𝐽(a)/𝜕a = −Σy - 梯度下降法:使用当前梯度值迭代更新参数。
更新的大小: 每个维度的梯度幅值代表参数在该维度上的更新程度。通常加入步长(𝜂𝑘)来调整更新的幅度。每次迭代可以用不同的步长。
参数更新过程:
4.4串行感知机算法
-
串行感知机:训练样本一个一个串行给出。
目标函数:如果当前训练样本被错误分类,最小化其输出值取反:J(a)=−aTyn,ifaTyn<=0
目标函数求解:
-
感知机:收敛性:如果训练样本是线性可分的,感知机(并行和串行)算法理论上收敛于一个解。
步长与收敛性:步长决定收敛的速度、以及是否收敛到局部或者全局最优点。
感知机变体:当样本位于决策边界边缘时,对该样本的决策有很大的不确定性。
解决方法:加入margin约束

目标函数求解: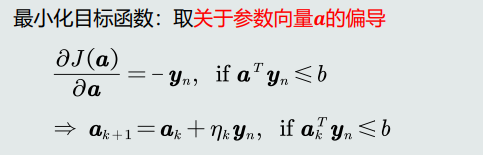
4.5Fisher线性判据
- 设计原理:找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少,从而使分类效果达到最佳。
- 算法训练过程:

- 参数最优解:

4.6支持向量机基本概念
- 设计原理:给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的间隔最大。
- 间隔的数学定义:在两个类的训练样本中, 分别找到与决策边界最近的两个训练样本,记作𝒙+和𝒙−。𝒙+和𝒙−到决策边界的垂直距离叫作间隔,记作𝑑+和𝑑−。
- 总的间隔表达:

- 支持向量机目标:最大化总间隔。最大化间隔,等价于最小化||𝒘||,所以目标函数设计为:

4.7拉格朗日乘数法
- 等式约束:

- KTT条件:

4.8拉格朗日对偶问题
- 主问题:

- 拉格朗日对偶函数:

- 对偶法的优势:无论主问题的凸性如何,对偶问题始终是一个凸优化问题。
凸优化的性质:局部极值点就是全局极值点。
所以,对偶问题的极值是唯一的全局极值点。
对于难以求解的主问题(如非凸问题或者NP难问题),可以通过求解其对偶问题,得到原问题的一个下界估计。
4.9支持向量机学习算法
- 目标函数求解:带不等式约束的优化问题,使用拉格朗日对偶法求解。
- 构建拉格朗日函数:
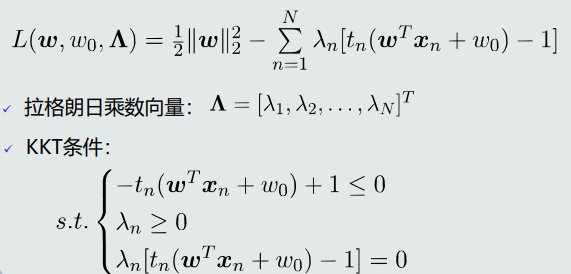
- 构建对偶函数:
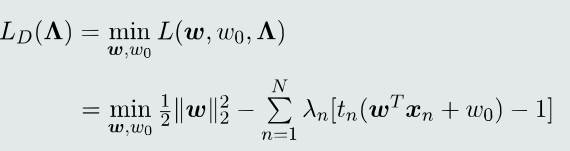
- 如何针对𝑤和𝑤0求解最小化:𝐿对参数𝑤和𝑤0求导,并设偏导等于0。

4.10软间隔支持向量机
- 过拟合:有些训练样本带有噪声或者是离群点,若严格限制所有样本都在间隔区域之外,会使得决策边界过于拟合噪声。
- 克服过拟合:可以将SVM的硬间隔放宽到软间隔,允许一些训练样本出现在间隔区域内,从而具备一定的克服过拟合的能力。
- 目标函数:
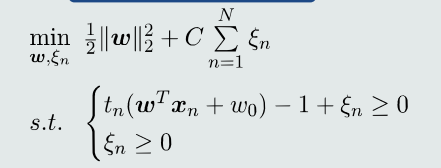
- 最优解:

4.11线性判据多类分类
-
多类分类的本质:非线性
-
实现非线性分类的途径:一个模型:能刻化非线性的决策边界。
多个模型:多个模型(线性/非线性)组合成非线性决策边界。
组合方式:并行组合、串行组合。 -
One-to-all策略:

-
线性机:
假设条件:每个类与剩余类线性可分。
训练:基于one-to-all策略训练𝐾个线性分类器𝑓𝑖,每个分类器对应一个类𝐶𝑖。
决策:使用输出值投票法(max函数)给定测试样本𝒙,其属于所有分类器中输出值最大的那个类。
取输出值最大:该值最大表示属于该类的可能性越大。
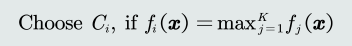
-
one to one:
假设条件:任意两个类之间线性可分, 但每个类与剩余类可能是线性不可分的。
基本思想:
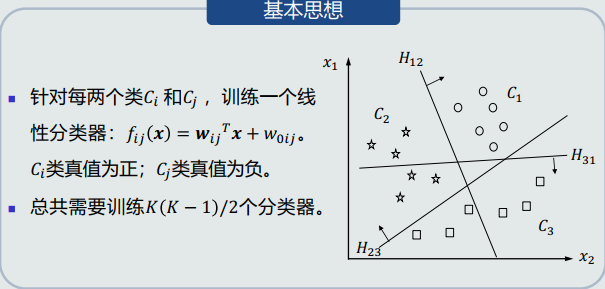
优势:适用于一些线性不可分的情况,从而实现非线性分类。
问题:会出现拒绝选项,即样本不属于任何类的情况。
4.12线性回归
-
输入样本:个数与特征维度的关系。
-
线性回归模型表达:

-
扩展——输出多维度:

-
待学习参数:给定训练样本,学习参数𝑾。

-
目标函数:如果参数𝑾是最优的,意味着对每个样本(𝒙𝑛,𝒕𝑛)而言,模型的输出值𝒚𝑛与标定的输出真值𝒕𝑛之间的差值最小。
-
目标优化:梯度下降法
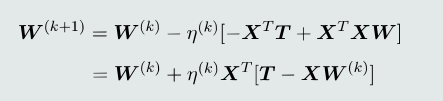
最小二乘法: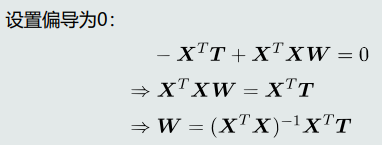
4.13逻辑回归的概念
-
MAP分类器的非线性情况:若两个类别数据分布的协方差矩阵不同(Σ𝑖 ≠ Σ𝑗),则MAP分类器的决策边界是一个超二次型曲面,非线性。相应的,协方差矩阵相同则为线性。
由此看来,MAP分类器等同于一个线性判据。MAP分类器可以在线性和非线性之间切换,为我们将线性模型改进成非线性模型提供了思路。 -
Logit变换:


定义:𝐶1类的后验概率与𝐶2类的后验概率之间的对数比率。对于二类分类,MAP分类器通过比较后验概率的大小来决策。
在每类数据是高斯分布且协方差矩阵相同的情况下,由于Logit变换等同于线性判据的输出,所以在此情况下Logit(z) 是线性的。 -
Sigmoid函数: sigmoid(y)=11+exp(−y)
连接线性模型和后验概率的桥梁
线性模型𝑓(𝒙) + Sigmoid函数 = 后验概率 -
逻辑回归:
定义:线性模型𝑓(𝒙) + sigmoid函数
给定测试样本𝒙, Logistic回归输出其属于𝐶1类的后验概率。
由于后验概率是一个连续值,所以Logistic一般被称作回归。
适用范围:分类
前提:两类之间是线性可分的。
狭义范围:每个类的数据都是高斯分布且分布的协方差矩阵相同。
广义范围:每个类的数据分布可以是非高斯,甚至是多模态分布。
4.14逻辑回归的学习
-
引言:给定训练样本,学习参数𝒘和𝑤0。
-
给定两个类别(正类和负类)共𝑁个标定过的训练样本:
训练样本:正类(𝐶1类)样本的输出真值𝑡𝑛 = 1
负类(𝐶2类) 样本的输出真值𝑡𝑛 = 0(这种真值取值方式与SVM不一样) -
目标函数:由于log是凹函数,所以对目标函数取反。相应的,最大化变为最小化。
因此,基于最大似然估计策略,最终得到的目标函数为:
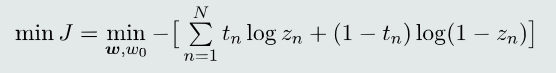
该目标函数其实就是交叉熵的表达式。
目标函数优化: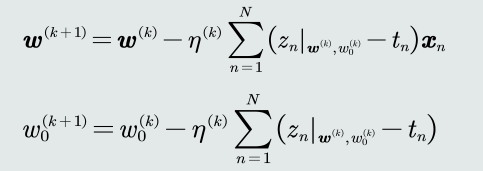
梯度消失:当𝑦 = 𝒘𝑇𝒙 + 𝑤0较大时,sigmoid函数输出𝑧会出现饱和:输入变化量∆𝑦很大时,输出变化量∆z很小。在饱和区,输出量𝑧接近于1,导致sigmoid函数梯度值接近于0,出现梯度消失问题。
迭代停止:如果迭代停止条件设为训练误差为0, 或者所有训练样本都正确分类的时候才停止,则会出现过拟合问题。所以,在达到一定训练精度后,提前停止迭代,可以避免过拟合。
4.15Softmax判据的概念
-
逻辑回归是由Logit变换反推出来的。
-
由Logit变换可知:正负类后验概率比率的对数是一个线性函数。
-
分类𝐾个类,可以构建𝐾个线性判据。第𝑖个线性判据表示𝐶𝑖类与剩余类的分类边界,剩余类用一个参考负类𝐶𝐾来表达。
-
任意正类𝐶𝑖(𝑖 ≠ 𝐾)的后验概率为:

-
任意类的后验概率:
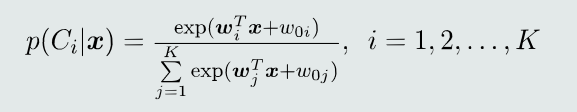
可见,对于多类分类(𝐾>2),𝐾个线性模型也跟每个类对应的后验概率建立起了联系。 -
适用范围:分类-->前提: 每个类和剩余类之间是线性可分的
回归-->范围:可以拟合指数函数(exp) 形式的非线性曲线 -
Softmax判据本身是一个非线性模型。
Softmax判据用于分类: 只能处理多个类别、每个类别与剩余类线性可分的情况。但是, Softmax判据可以输出后验概率。因此,Softmax判据比基于one-to-all策略的线性机向前迈进了一步。
Softmax判据用于拟合:可以输出有限的非线性曲线。
4.16Softmax判据的学习
-
学什么:给定训练样本,学习K组参数
-
目标函数:最大似然估计。针对所有训练样本,最大化输出标签分布的似然函数,以此求得参数的最优值。似然函数为所有训练样本输出概率的乘积。
-
判别式学习是依赖所有类的训练样本来学习参数。
-
目标函数:最大似然估计
如果参数是最优的,意味着对大部分样本(𝒙𝑛, 𝒕𝑛)而言,输出概率𝑝({𝑡𝑛𝑖 }|𝒙𝑛) 应该是较大的。
因此,使用最大似然估计:针对所有训练样本𝒳,最大化输出标签分布的似然函数,以此求得参数{𝒘𝒊, 𝑤0𝑖}𝑖=1,2,…𝐾的最优值。
似然函数为所有训练样本输出概率的乘积。
所以,目标函数表达为: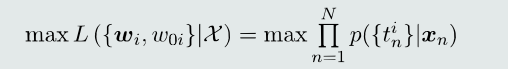
-
参数优化:采用梯度下降法更新所有{𝒘𝒊, 𝑤0𝑖}:设当前时刻为𝑘,下一个时刻为𝑘+1,𝜂为更新步长。
4.17核支持向量机(Kernel SVM)
-
基本思想:如果样本在原始特征空间(X空间)线性不可分,可以将这些样本通过一个函数φ映射到一个高维的特征空间(Φ空间),使得在这个高维空间,这些样本拥有一个线性分类边界。
-
核函数 Kernel Function:在低维X空间的一个非线性函数,包含向量映射和点积功能,即作为X空间两个向量的度量,来表达映射到高维空间的向量之间的点积:
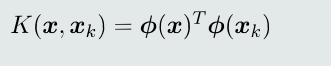
-
Kernel SVM的对偶问题:

-
核函数优缺点:

-
常见的和函数:
多项式核函数:
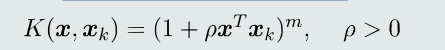
高斯核函数: