
正则表达式入门
一、正则表达式为何物
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具,换句话说,正则表达式就是记录文本规则的代码。
二、元字符
常用的元字符如下:
. 匹配除换行符以外的任意单个字符 例:i.ation匹配isation、ization等
\w匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\S 匹配任意不是空白的字符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
* 代表的不是字符,也不是位置,而是数量,指定*前边的内容可以连续重复使用任意次(包括0次)以使整个表达式得到匹配 例:ca*t匹配ct、cat、caat、caaat等
+ 代表匹配重复1次或更多次 例:ca+t匹配cat、caat、caaat等,但不匹配ct
? 指定?前边的内容可以重复0次或1次 例:cn?blog只匹配cblog和cnblog
Demo
1)找到一个字符串中字符串“hi”出现的次数以及位置
string myText = "This hit Lucy his high icon hiLucy hi morning Lucy"; string myPattern = "hi"; MatchCollection myMatches = Regex.Matches(myText, myPattern, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture); Console.WriteLine($"Total found: {myMatches.Count}"); foreach (Match match in myMatches) { myIndex = match.Index; string myResult = myText.Substring(myIndex, myPattern.Length); Console.WriteLine($"Index: {match.Index} Text:{myResult}"); }
运行结果如下:
Total found: 6
Index: 1 Text:hi
Index: 5 Text:hi
Index: 14 Text:hi
Index: 18 Text:hi
Index: 28 Text:hi
Index: 35 Text:hi
2)找到一个字符串中单词“hi”出现的次数以及位置
string myText = "This hit Lucy his high icon hiLucy hi morning Lucy"; string myPattern = @"\bhi\b";//加@为了防止转义 MatchCollection myMatches = Regex.Matches(myText, myPattern, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture); Console.WriteLine($"Total found: {myMatches.Count}"); foreach (Match match in myMatches) { int myIndex = match.Index; string myResult = myText.Substring(myIndex, 2); Console.WriteLine($"Index: {match.Index} Text:{myResult}"); }
运行结果如下:
Total found: 1
Index: 35 Text:hi
3)正则表达式\bhi\b.*\bLucy\b分析:
.*连在一起就意味着任意数量的不包含换行的字符
\bhi\b.*\bLucy\b的意思就很明显了:先是一个单词hi,然后是任意个任意字符(但不能是换行),最后是Lucy这个单词。
string myText = "This hit Lucy his himorLucy high icon hiLucy hi morning Lucy test hi mo Lucy"; string myPattern = @"\bhi\b.*\bLucy\b";//加@为了防止转义 MatchCollection myMatches = Regex.Matches(myText, myPattern, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture); Console.WriteLine($"Total found: {myMatches.Count}"); foreach (Match match in myMatches) { int myIndex = match.Index; string myResult = match.Value; Console.WriteLine($"Index: {match.Index} Text:{myResult}"); }
运行结果如下:
Total found: 1
Index: 46 Text:hi morning Lucy test hi mo Lucy
在测试字符串中加入换行符\n,测试观察结果
string myText = "This hit Lucy his himorLucy high icon hiLucy hi morning Lucy test hi mo \n Lucy";
运行结果如下:
Total found: 1
Index: 46 Text:hi morning Lucy
4)正则表达式010-\d{2}-\d{3}分析:
首先是010三个数字开头,然后跟着一个中划线(-),然后是连续的两个数字,紧跟着一个中划线(-),然后是连续的三个数字
string myText = "101-1021-89010-87-5101212010-98-369"; string myPattern = @"010-\d{2}-\d{3}";//加@为了防止转义 MatchCollection myMatches = Regex.Matches(myText, myPattern, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture); Console.WriteLine($"Total found: {myMatches.Count}"); foreach (Match match in myMatches) { int myIndex = match.Index; string myResult = match.Value; Console.WriteLine($"Index: {match.Index} Text:{myResult}"); }
运行结果如下:
Total found: 2
Index: 11 Text:010-87-510
Index: 25 Text:010-98-369
5)\ba\w*\b匹配以字母a开头的单词---先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
6)\d+匹配1个或更多连续的数字。
7)\b\w{6}\b 匹配刚好6个字符的单词。
8)^\d{5,12}$匹配5到12位数字的整个字符串。
三、字符转义
有时候我们需要在字符串中查找“.”或者“*”等元字符,如果直接查找,就会出现问题,因为它们是元字符,会被解释成其他意思。
这时候我们就需要用“\”来取消这些字符的特殊意义。
例如:youku\.com匹配youku.com,C:\\Windows匹配C:\Windows。
四、重复
如下是正则表达式中表示重复的限定符

例:
Cnblog\d*配Cnblog后面跟0个或更多数字
Cnblog\d+匹配Cnblog后面跟1个或更多数字
Cnblog\d?匹配Cnblog后面跟0个或1个数字
Cnblog\d{3}匹配Cnblog后面跟3个数字
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
五、字符类
通过上面的学习,我们已经知道,要想查找数字、字母等是很简单的,因为已经有了对应这些字符集合的元字符。
但是如果我们想匹配没有预定义元字符的字符集合(如英文元音字母a,e,i,o,u)的时候,我们应该怎么办?
这时候,我们可以在方括号([ ])里列出他们。
如:[aeiou]就匹配任何一个英文元音字母;[.?!]匹配标点符号(.或?或!)。
同时,我们也可以指定一个字符范围,像[0-9]代表的含意与\d完全相同:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)。
下面是一个更复杂的表达式:
\(?0\d{2}[) -]?\d{8}
"("和")"也是元字符,所以在这里需要使用转义\。
这个表达式可以匹配几种格式的电话号码,如(010)84328618,或024-13572468,或(024-12345678等。
下面我们对该表达式进行分析:
首先是一个转义字符\(,它表示(可以出现0次或1次(?元字符表示前面的字符出现0次或1次),
然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
六、分枝条件
遗憾的是,刚才那个表达式也能匹配010)66668888或(024-12345678这样的“不正确”的格式。
要解决这个问题,我们需要用到分枝条件。
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。
请看如下例子:
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。
之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。
如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
七、反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义
常用的反义代码如下:
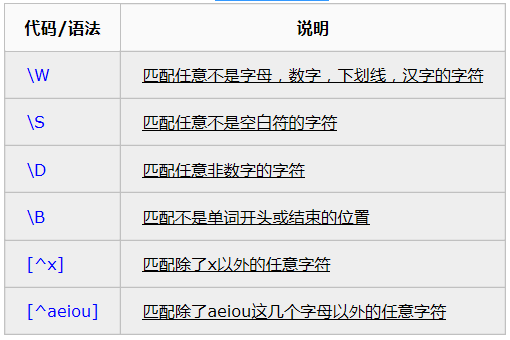
例:
\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
八、分组
通过前面的知识,我们已经了解到如何重复单个字符(直接在字符后面加上限定符就行了),
但有时候我们需要重复多个字符,这时候,我们可以用小括号来指定子表达式(也叫做分组),然后就可以指定这个子表达式的重复次数了。
例:
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。
分析:\d{1,3}匹配1到3位的数字,(\d{1,3}\.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
不幸的是,它也将匹配256.300.888.666这种不可能存在的IP地址。
如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:
((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
Demo:
在一个正则表达式中,如果要提取出多个不同的部分(子表达式项),需要用到分组功能。
在 C# 正则表达式中,Regex 成员关系如下,其中 Group 是其分组处理类。

//分组 数组下标访问 string myText = "1Aac3 23456B 3z46tC 45678a 5tfee80 #800080"; string myPatten = @"((\d+)([a-z]))\s+";//匹配一个或者多个数字,后面跟一个英文字母,然后是一个或者多个空格 Regex rex = new Regex(myPatten, RegexOptions.IgnoreCase); MatchCollection matches = rex.Matches(myText); //提取匹配项 foreach (Match match in matches) { GroupCollection groups = match.Groups; Console.WriteLine(string.Format("{0} 共有 {1} 个分组:{2}>", match.Value.Replace(' ','*'), groups.Count, myPatten)); //提取匹配项内的分组信息 for (int i = 0; i < groups.Count; i++) { //用*代替空格,方便在显示的时候查看空格的个数,几个*表示几个空格 Console.WriteLine(string.Format("分组 {0} 为 {1},位置为 {2},长度为 {3}>", i, groups[i].Value.Replace(' ','*'), groups[i].Index, groups[i].Length)); } Console.WriteLine(); }
运行结果: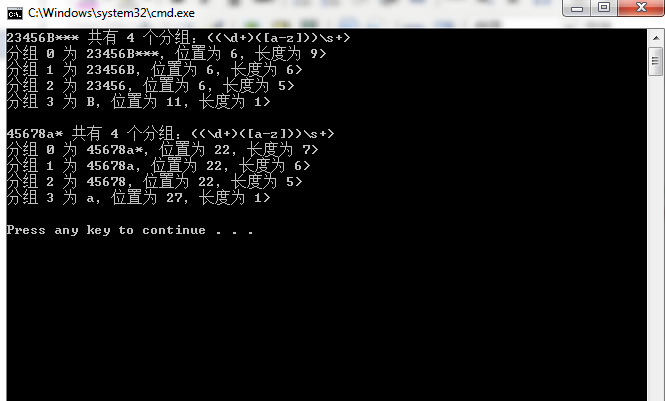
string text = "I've found an interesting URL at https://www.cnblog.com, and then find ftp://ftp.youku.com."; string pattern = @"\b(?<protocol>\S+)://(?<address>\S+)\b"; //string text = "This is just for testingdemo an interesting3435 demo."; //string pattern = @"(?<=ing)(\w+)"; MatchCollection matches = Regex.Matches(text, pattern); foreach (Match match in matches) { GroupCollection groups = match.Groups; for(int i = 0; i < groups.Count; i++) { Console.WriteLine($"Group{i}: {groups[i].Value}"); } Console.WriteLine(string.Format("URL: {0} Protocol: {1} Address: {2}" , match.Value, groups["protocol"].Value, groups["address"].Value)); Console.WriteLine(); }
运行结果: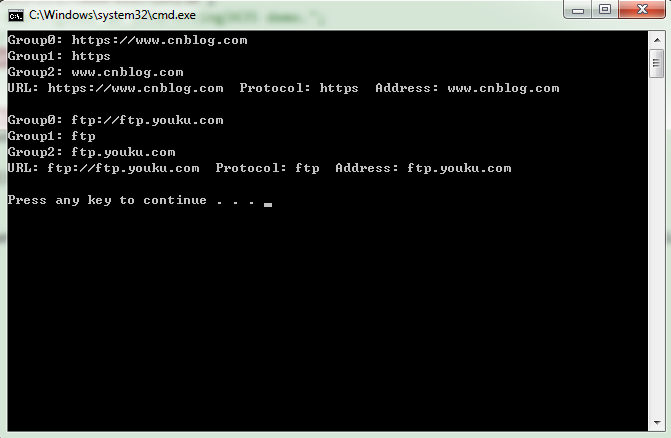
九、后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号。
组号的一般规则如下:
1)分组0对应整个正则表达式;
2)实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号;
3)你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权。
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。
这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
我们也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。
要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
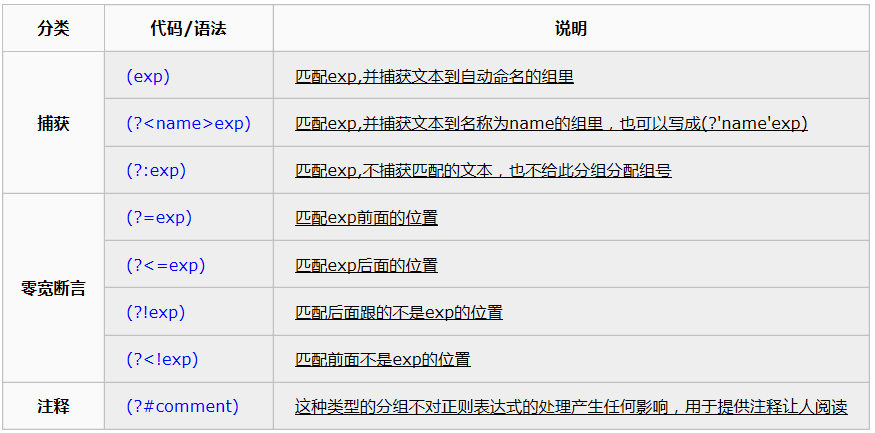
(?=exp) :定义目标字符串结束位置要求,即紧随目标字符串后面出现的字符串需要匹配上exp表达式,该字符串不会被计入目标字符串,表达中出现的括号也不会被视作一个分组;
(?<=exp):定义目标字符串起始位置要求,即紧邻目标字符串前面出现的字符串需要匹配上exp表达式,该字符串不会被计入目标字符串,表达中出现的括号也不会被视作一个分组;
Demo:
string text = "This is just for testingdemo an interesting3435 demo."; string pattern = @"(?<=ing)(\w+)";//目标字符串\w+必须在ing后面,(?<=ing)组占用分组 MatchCollection matches = Regex.Matches(text, pattern); foreach (Match match in matches) { GroupCollection groups = match.Groups; for(int i = 0; i < groups.Count; i++) { Console.WriteLine($"Group{i}: {groups[i].Value}"); } //Console.WriteLine(string.Format("URL: {0} Protocol: {1} Address: {2}" , match.Value, groups["protocol"].Value, groups["address"].Value)); Console.WriteLine(); }
运行结果: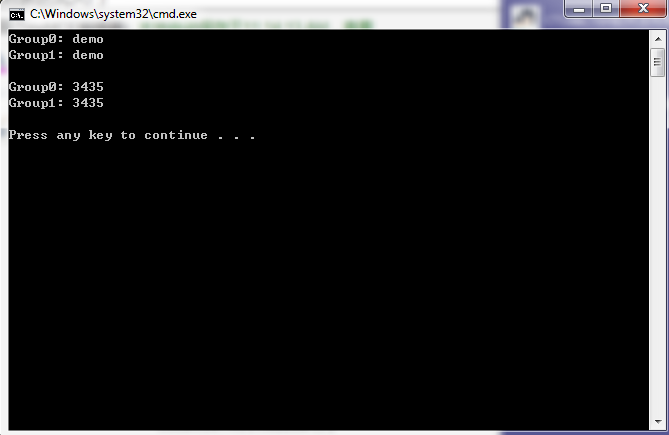
string text = "This is just for testingdemo an interesting3435 demo."; string pattern = @"(\w+)(?=ing)";//目标字符串\w+后必须跟ing,但ing不包含到目标字符串中,(?=ing)不占用分组 MatchCollection matches = Regex.Matches(text, pattern); foreach (Match match in matches) { GroupCollection groups = match.Groups; for(int i = 0; i < groups.Count; i++) { Console.WriteLine($"Group{i}: {groups[i].Value}"); } //Console.WriteLine(string.Format("URL: {0} Protocol: {1} Address: {2}" , match.Value, groups["protocol"].Value, groups["address"].Value)); Console.WriteLine(); }
运行结果: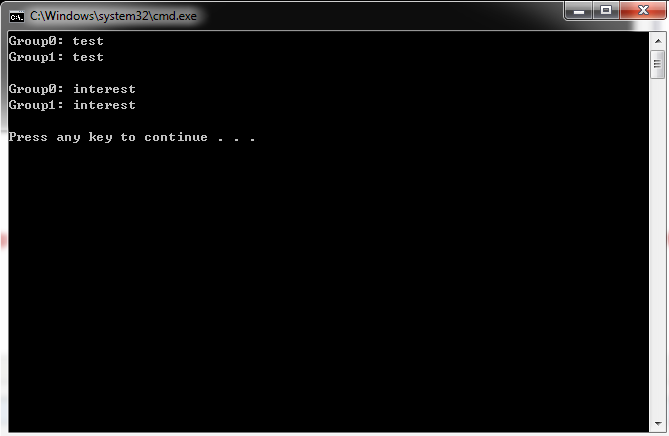
注:本文主要参考自http://www.cnblogs.com/deerchao/archive/2006/08/24/zhengzhe30fengzhongjiaocheng.html#mission

 浙公网安备 33010602011771号
浙公网安备 33010602011771号