我眼中的机器学习(三) 如何寻找模型的最优解
前面两篇文章, 我们先是通过三个非常简单的数学例子了解了机器学习的基本流程(训练, 预测). 接着为大家解释了为什么大家早就学会解方程了, 还需要用到机器学习技术. 我们接下来要讲的是机器学习算法怎样为我们在无数个可能的模型中找出最有可能正确的(最优的)那个模型.
首先在上一篇文章中, 有朋友提问 "为什么认为找出来的模型是最优的,怎么判断它是不是最优的,依据是什么"
机器学习没办法为我们找到百分百正确的模型, 但是机器学习可以帮我们找到出错概率最低的模型, 或者说将该模型应用回历史数据时, 该模型能够保证他的误差比其它模型小, 或者说误差小到你可以接受的程度.
对于这一类的问题, 在机器学习任务集里有一个单独的任务类别, 我们称之为回归任务(Regression). 在统计分析中也被称之为回归分析(Regression_analysis). 关于回归分析专业解释可以参考 Wikipedia的 回归分析(Regression_analysis)词条 或者智库百科的 回归分析预测法 词条.
回归分析通常依据数据的特性(最终得到的数学模型是线性的还是非线性的)又分为线性回归与非线性回归. 不过很多复杂的社会现象或者金融模型都是基于非线性的回归计算.
线性与非线性的区别就是线性方程式与非线性方程式的区别(再通俗点就是 在二维平面中, 直线就是线性的, 抛物线就是非线性的, 在三维空间中, 桌面就是线性的, 篮球的表面就是非线性的). 通常来说, 线性回归比非线性回归拟合起来会更容易一些.
回归计算最早使用的是最小二乘法(least squares)来计算的, 而且直到现在最小二乘法仍然是最流行的分析方法之一. 最小二乘法不仅能够用于线性回归的拟合(性线最小二乘法也称为普通最小二乘法 ordinary least squares (OLS) or ordinary least squares), 同样能够用于非线性回归的拟合(non-linear least squares). 最小二乘法的思路是最小化所有样本在最终模型下的错误平方差之和 (minimizes the sum of the squares of the errors made in the results of every single equation) . 换句话说, 最小二乘法的原理就是保证得到的最终的模型在无数个可能的模型中的误差是最小的.
接下来我们来先通过一个简单的例子 来使用最小平方差原理寻找最优解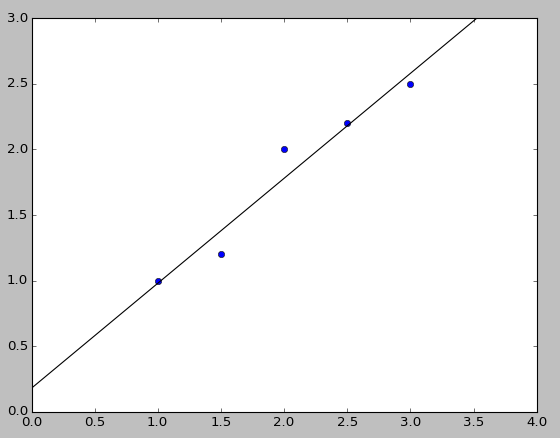
假设
已知有一种植物,经过3年时间的观察
第1年时, 植物高度到1米
第1.5年时, 植物高度为1.2米
第2年时, 植物高度为2米
第2.5年时, 植物高度为2.2米
第3年时, 植物高度为2.5米,
现在需要预测植物在第四年的高度为有多少米
将年限看作X轴, 将植物高度看作Y轴我们可得历史坐标点 (1,1), (1.5,1.2), (2,2), (2.5,2.2), (3,2.5)
直接从图中也可以发现, 无法作一条直接同时通过五个点
从方程组的角度,
当我们把五个点整理成方程组时, 由方程1与方程2联立也可知该方程无解
x-y=0 ---------------(1)
1.5x-1.2y=0---------(2)
2x-2y=0-------------(3)
2.5x-2.2y=0---------(4)
3x-2.5y=0-----------(5)
因此, 常规的解方程思路在这里走不通.
但是, 这么简单的问题, 无数位前辈们早已将其研究烂了, 所以直接给这类 普通最小二乘法给总结了公式出来了
方法一: 使用普通二乘法计算公式
(这不是我们接下去的重点, 因为这算是特例, 公式在非线性方程时就不适用了, 之所有介绍这种计算方式是因为, 在计算二元线性回归时, 这么计算很方便很直接)
首先假设最终的模型为
$$\hat{Y}=aX+b$$
第一步: 计算x与y的平均值(也叫期望)
$$ N =5$$
$$\sum{x} = (1+1.5+2+2.5+3)=10$$
$$\sum{y} = (1+1.2+2+2.2+2.5)=8.9$$
$$\bar{X} = \frac{\sum{x}}{N}=(1+1.5+2+2.5+3)/5 = 2$$
$$\bar{Y} = \frac{\sum{y}}{N}=(1+1.2+2+2.2+2.5)/5 = 1.78$$
第二步: 计算模型中的斜率(slop) a
$$slop =\frac{Covariance(x,y)}{variance(x)}=\frac{\sum\limits_{i=1}^n(x_i-\bar{x}_i)(y_i-\bar{y}_i)}{\sum\limits_{i=1}^n(x_i-\bar{x})^2}=\frac{0.4}{0.5}=0.8$$
第三步: 计算模型中的截距(y-intercept) b
$$b=\bar{Y}-a\bar{X}=1.78-0.8\times2=0.18$$
利用得到的斜率与截距, 我们就能够得到我们想要的数学模型了
$$\hat{Y}=0.8X+0.18$$
所以第四年的植物高度为 将x=4代入 数学模型中我们可以得到第四年的 植物高度为3.38
方法二: 使用最小化误差的思想
前文提到的最小二乘法的思路是最小化所有样本在最终模型下的错误平方差之和, 那么这次重点要讲的方法就是根据这个思路进行建模的
首先, 需要明确的是, 什么是误差
在这个例子中, 单个点的误差最直接的想法就是通过我们估算出来的数学模型, 将x值代进去时, 计算出来的与真实Y的差,
但是因为这样子计算的话, 差有可能是正数, 也可能是负数. 所以通常情况下我们使用的差的平方作为单个点的误差.
$$e_i=(\hat{Y_i}-Y_i)^2$$
因此数学模型的整体误差为
$$ e= \sum\limits_{i=1}^n(\hat{Y_i}-Y_i)^2$$
定了误差以后, 我们还得明确我们可以容忍的多大的误差, 因为最终的数学模型不一定可以做到零误差(很少可以找到完美的零误差模型, 因为零误差的模型本身就可能是不存在的, 即便是方法一得出的结果也是有误差的)
假设我们现在可以容忍的误差为 0.5
在已知最终的模型为线程方程的情况下,
$$Y=aX+b$$
我们可以开始我们的第一步
第一步: 碰运气
没错, 就是碰运气, 随便假设一下a 与b的值. 然后计算一下误差哈
让我们假设a=1, b=1
则我们的最终模型为
$$\hat{Y}=X+1$$
因此我们可以得到该数学模型的总误差为7.63
$$ e= \sum\limits_{i=1}^n(\hat{Y_i}-Y_i)^2= (2-1)^2+(2.5-1.2)^2+(3-2)^2+(3.5-2.2)^2+(4-2.5)^2=7.63$$
明显目前的误差离我们可以容忍的误差还有很大的差距
所以我们需要进入第二步: 接着猜
我们先尝试调整b的值, 假设a仍为1, b=2(原来为1, 现在加上1), 可得误差 24.83
通过误差比对, 可以发现, 我们的方向可能错了, 因为误差变大了, 所以这个时候我们重新假设 a=1, b=0(原来为1, 现在减去1)的情况, 可得误差0.43
这回误差明确小了一大截了, 而且已经小于我们可以容忍的误差范围了(±0.5)
所以我们得到了第一个满足我们条件的数学模型
$$\hat{Y}=X$$
然而人总是贪心的, 当我们得到想到的东西时, 还会想要其它更好的东西.
所以类似得, 当我们找到满足我们要求的模型时, 我们就会想得到更好的更精确的数学模型.
于是假设我们现在需要误差小于0.1的更为精确的数学模型
让我们可以接着刚才的想法, 继续调整一下b的取值 假设 a=1, b=-1可得误差3.23
可以发现误差这次不仅没有变小反而又变大了,
因此, 可以断定b的更好的取值可能是-1到1之间,
因为误差的计算可以很容易的通过程序来代表人工计算, 所以让我们来编写一段简单的python循环来愉快的盲目的寻找更好的b值吧
1 # -*- coding: utf-8 -*-
2 # regressionv1.py
3 import numpy
4
5 a = 1
6 x = [ 1 , 1.5 , 2 , 2.5 , 3 ]
7 y = [ 1 , 1.2 , 2 , 2.2 , 2.5 ]
8 minimumError = 1000000
9 minParameter = []
10
11 for b in numpy.arange( - 1 , 1 , 0.05 ):
12 soe = 0 #sum of error
13 for i in range ( len (x)):
14 soe += (a * x[i] + b - y[i]) * (a * x[i] + b - y[i])
15 if soe<minimumError:
16 minimumError = soe
17 minParameter = [a,b]
18 print "当a=1,b=" + str (b), "时, 可得误差" ,soe
19 print "最小误差为" ,minimumError, "出现于minParameter" ,minParameter
输出的结果如下:
当a=1,b=-1.0 时, 可得误差 3.23 当a=1,b=-0.95 时, 可得误差 2.8525 当a=1,b=-0.9 时, 可得误差 2.5 当a=1,b=-0.85 时, 可得误差 2.1725 当a=1,b=-0.8 时, 可得误差 1.87 当a=1,b=-0.75 时, 可得误差 1.5925 当a=1,b=-0.7 时, 可得误差 1.34 当a=1,b=-0.65 时, 可得误差 1.1125 当a=1,b=-0.6 时, 可得误差 0.91 当a=1,b=-0.55 时, 可得误差 0.7325 当a=1,b=-0.5 时, 可得误差 0.58 当a=1,b=-0.45 时, 可得误差 0.4525 当a=1,b=-0.4 时, 可得误差 0.35 当a=1,b=-0.35 时, 可得误差 0.2725 当a=1,b=-0.3 时, 可得误差 0.22 当a=1,b=-0.25 时, 可得误差 0.1925 当a=1,b=-0.2 时, 可得误差 0.19 当a=1,b=-0.15 时, 可得误差 0.2125 当a=1,b=-0.1 时, 可得误差 0.26 当a=1,b=-0.05 时, 可得误差 0.3325 当a=1,b=8.881784197e-16 时, 可得误差 0.43 当a=1,b=0.05 时, 可得误差 0.5525 当a=1,b=0.1 时, 可得误差 0.7 当a=1,b=0.15 时, 可得误差 0.8725 当a=1,b=0.2 时, 可得误差 1.07 当a=1,b=0.25 时, 可得误差 1.2925 当a=1,b=0.3 时, 可得误差 1.54 当a=1,b=0.35 时, 可得误差 1.8125 当a=1,b=0.4 时, 可得误差 2.11 当a=1,b=0.45 时, 可得误差 2.4325 当a=1,b=0.5 时, 可得误差 2.78 当a=1,b=0.55 时, 可得误差 3.1525 当a=1,b=0.6 时, 可得误差 3.55 当a=1,b=0.65 时, 可得误差 3.9725 当a=1,b=0.7 时, 可得误差 4.42 当a=1,b=0.75 时, 可得误差 4.8925 当a=1,b=0.8 时, 可得误差 5.39 当a=1,b=0.85 时, 可得误差 5.9125 当a=1,b=0.9 时, 可得误差 6.46 当a=1,b=0.95 时, 可得误差 7.0325 最小误差为 0.19 出现于minParameter [1, -0.19]
可以发现点我们, 在步长为0.05时, 当b的取值为-1到1之间时, 最小的误差为0.19, 出现在b=-0.2时
而误差0.19虽然已经开始接近我们可以容忍的程度, 但是总归还是差了点, 不过还好, 我们还有一个参数还没有参与"调试"
姑且先让我们假设b=-0.2, 继续使用小程序来调整a的值跑一下误差
当a=-1.0,b=-0.2时, 可得误差 87.39 当a=-0.95,b=-0.2时, 可得误差 83.01625 当a=-0.9,b=-0.2时, 可得误差 78.755 当a=-0.85,b=-0.2时, 可得误差 74.60625 当a=-0.8,b=-0.2时, 可得误差 70.57 当a=-0.75,b=-0.2时, 可得误差 66.64625 当a=-0.7,b=-0.2时, 可得误差 62.835 当a=-0.65,b=-0.2时, 可得误差 59.13625 当a=-0.6,b=-0.2时, 可得误差 55.55 当a=-0.55,b=-0.2时, 可得误差 52.07625 当a=-0.5,b=-0.2时, 可得误差 48.715 当a=-0.45,b=-0.2时, 可得误差 45.46625 当a=-0.4,b=-0.2时, 可得误差 42.33 当a=-0.35,b=-0.2时, 可得误差 39.30625 当a=-0.3,b=-0.2时, 可得误差 36.395 当a=-0.25,b=-0.2时, 可得误差 33.59625 当a=-0.2,b=-0.2时, 可得误差 30.91 当a=-0.15,b=-0.2时, 可得误差 28.33625 当a=-0.1,b=-0.2时, 可得误差 25.875 当a=-0.05,b=-0.2时, 可得误差 23.52625 当a=8.881784197e-16,b=-0.2时, 可得误差 21.29 当a=0.05,b=-0.2时, 可得误差 19.16625 当a=0.1,b=-0.2时, 可得误差 17.155 当a=0.15,b=-0.2时, 可得误差 15.25625 当a=0.2,b=-0.2时, 可得误差 13.47 当a=0.25,b=-0.2时, 可得误差 11.79625 当a=0.3,b=-0.2时, 可得误差 10.235 当a=0.35,b=-0.2时, 可得误差 8.78625 当a=0.4,b=-0.2时, 可得误差 7.45 当a=0.45,b=-0.2时, 可得误差 6.22625 当a=0.5,b=-0.2时, 可得误差 5.115 当a=0.55,b=-0.2时, 可得误差 4.11625 当a=0.6,b=-0.2时, 可得误差 3.23 当a=0.65,b=-0.2时, 可得误差 2.45625 当a=0.7,b=-0.2时, 可得误差 1.795 当a=0.75,b=-0.2时, 可得误差 1.24625 当a=0.8,b=-0.2时, 可得误差 0.81 当a=0.85,b=-0.2时, 可得误差 0.48625 当a=0.9,b=-0.2时, 可得误差 0.275 当a=0.95,b=-0.2时, 可得误差 0.17625 当a=0.951,b=-0.2时, 可得误差 0.1754225 当a=0.952,b=-0.2时, 可得误差 0.17464 当a=0.953,b=-0.2时, 可得误差 0.1739025 当a=0.954,b=-0.2时, 可得误差 0.17321 当a=0.955,b=-0.2时, 可得误差 0.1725625 当a=0.956,b=-0.2时, 可得误差 0.17196 当a=0.957,b=-0.2时, 可得误差 0.1714025 当a=0.958,b=-0.2时, 可得误差 0.17089 当a=0.959,b=-0.2时, 可得误差 0.1704225 当a=0.96,b=-0.2时, 可得误差 0.17 当a=0.961,b=-0.2时, 可得误差 0.1696225 当a=0.962,b=-0.2时, 可得误差 0.16929 当a=0.963,b=-0.2时, 可得误差 0.1690025 当a=0.964,b=-0.2时, 可得误差 0.16876 当a=0.965,b=-0.2时, 可得误差 0.1685625 当a=0.966,b=-0.2时, 可得误差 0.16841 当a=0.967,b=-0.2时, 可得误差 0.1683025 当a=0.968,b=-0.2时, 可得误差 0.16824 当a=0.969,b=-0.2时, 可得误差 0.1682225 当a=0.97,b=-0.2时, 可得误差 0.16825 当a=0.971,b=-0.2时, 可得误差 0.1683225 当a=0.972,b=-0.2时, 可得误差 0.16844 当a=0.973,b=-0.2时, 可得误差 0.1686025 当a=0.974,b=-0.2时, 可得误差 0.16881 当a=0.975,b=-0.2时, 可得误差 0.1690625 当a=0.976,b=-0.2时, 可得误差 0.16936 当a=0.977,b=-0.2时, 可得误差 0.1697025 当a=0.978,b=-0.2时, 可得误差 0.17009 当a=0.979,b=-0.2时, 可得误差 0.1705225 当a=0.98,b=-0.2时, 可得误差 0.171 当a=0.981,b=-0.2时, 可得误差 0.1715225 当a=0.982,b=-0.2时, 可得误差 0.17209 当a=0.983,b=-0.2时, 可得误差 0.1727025 当a=0.984,b=-0.2时, 可得误差 0.17336 当a=0.985,b=-0.2时, 可得误差 0.1740625 当a=0.986,b=-0.2时, 可得误差 0.17481 当a=0.987,b=-0.2时, 可得误差 0.1756025 当a=0.988,b=-0.2时, 可得误差 0.17644 当a=0.989,b=-0.2时, 可得误差 0.1773225 当a=0.99,b=-0.2时, 可得误差 0.17825 当a=0.991,b=-0.2时, 可得误差 0.1792225 当a=0.992,b=-0.2时, 可得误差 0.18024 当a=0.993,b=-0.2时, 可得误差 0.1813025 当a=0.994,b=-0.2时, 可得误差 0.18241 当a=0.995,b=-0.2时, 可得误差 0.1835625 当a=0.996,b=-0.2时, 可得误差 0.18476 当a=0.997,b=-0.2时, 可得误差 0.1860025 当a=0.998,b=-0.2时, 可得误差 0.18729 当a=0.999,b=-0.2时, 可得误差 0.1886225 当a=1.0,b=-0.2时, 可得误差 0.19
可以发现, 不管我们现在如何尝试, 误差最小也只能达到0.168 出现于a=0.969,b=-0.2时
莫非, 最小的误差是0.168?
抱着怀疑的心态, 在有点暴力的办法似乎走不通的情况下, 让我们来尝试更加暴力一些的方法,
写一个regressionv2.py 脚本, 设定a,b每次增加的步长为0.05, 同时循环不同的a和b的取值来寻找最优解
1 # -*- coding: utf-8 -*-
2 #regressionv2.py
3 import numpy
4 x=[1,1.5,2,2.5,3]
5 y=[1,1.2,2,2.2,2.5]
6 minimumError=1000000
7 minParameter=[]
8 for a in numpy.arange(-2, 2, 0.05):
9 for b in numpy.arange(-2,2,0.05):
10 soe=0 #sum of error
11 for i in range(len(x)):
12 soe+=(a*x[i]+b-y[i])*(a*x[i]+b-y[i])
13 if soe<minimumError:
14 minimumError=soe
15 minParameter=[a,b]
16 #print "当a="+str(a)+",b="+str(b)+"时, 可得误差",soe
17 print "最小误差为",minimumError,"出现于minParameter",minParameter
这点计算量, 对于程序来说还是很easy的, 我们的程序很快也给我们快跑结果了
最小误差为 0.09 出现于minParameter [0.8, 0.2]
终于误差是我们可以容忍的了(小于0.1),
于是我们得到了第二个符合条件更加精准的数学模型
这个时候让我们回头对比一下 方法一的结果,
让我们也计算一下方法一得到的误差, 当a=0.8, b=0.18, 它的误差为0.88
可以发现我们当前的误差已经离方法一的误差(0.088)很接近了, 如果想得到方法一的结果, 我们就必须在之前的脚本中使用更小的步长
比如0.01
接着来我们实验一下, 当我们把步长设为0.01时, 发现脚本帮我们找到了与方法一一样的结果,
不过,
等一下!
好像我们跑脚本的时候似乎变长了?
对的, 当我们把步长变小时, 程序的计算量就变大了, 于是性能问题就显示出来了
为了计算这个最优解, 我的脚本在我的电脑上跑了差不多5秒, 计算了160000个不同的取值才得到这个结果.
而之前步长为0.05时, 计算用的时间不会超过1秒, 总共也才计算了6400种不同的取值. 计算的状态空间(不同的取值)扩大了25倍
可以想象, 如果我们的方程不是二元一次方程, 而是十元一次方法时, 我们的状态空间势必将变的更大! 计算所消耗的时间也将会更久!
又或者当我们的取值范围不是-2到2之间 而是-10000 到10000之间时, 我们的程序还能跑得动吗?
于是问题来了, 有没有又快又准的找到最优解的方法?
答案是有的!
终于, 我们可以引出下一章的标题了- 快速寻找最优解!
REF:http://hotmath.com/hotmath_help/topics/line-of-best-fit.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号