
MIT 6.S081 学习记录
MIT 6.S081 学习记录
环境配置:
- MIT6.S081实验环境配置 - 陪你倒数's blog (zhouliqi.github.io)
- MIT 6S081 qemu-gdb debug调试新手指南!!!! - 知乎 (zhihu.com)
学习资料:
- MIT 6.S081 Lecture Notes - Xiao Fan's Personal Page (fanxiao.tech)
- MIT6.828/6.S081操作系统课程教程_哔哩哔哩
- MIT6.S081 课程翻译 (gitbook.io)
- [《xv6 中文文档》 - 书栈网 · BookStack](https://www.bookstack.cn/read/xv6-chinese/content-chapter0.md#I/O 和文件描述符)
- Mit6.S081学习记录_解析Ta的博客-CSDN博客_6.s081
- 《给操作系统捋条线》Rand_CS 的个人主页 - 文章 - 掘金 (juejin.cn)
Lec01 Introduction and Examples
操作系统应该提供的功能:1. 多进程支持 2. 进程间隔离 3. 受控制的进程间通信
-
xv6:一种在本课程中使用的类UNIX的教学操作系统,运行在RISC-V指令集处理器上,本课程中将使用QEMU模拟器代替
-
kernel(内核):为运行的程序提供服务的一种特殊程序。每个运行着的程序叫做进程,每个进程的内存中存储指令、数据和堆栈。一个计算机可以拥有多个进程,但是只能有一个内核
每当进程需要调用内核时,它会触发一个system call(系统调用),system call进入内核执行相应的服务然后返回。
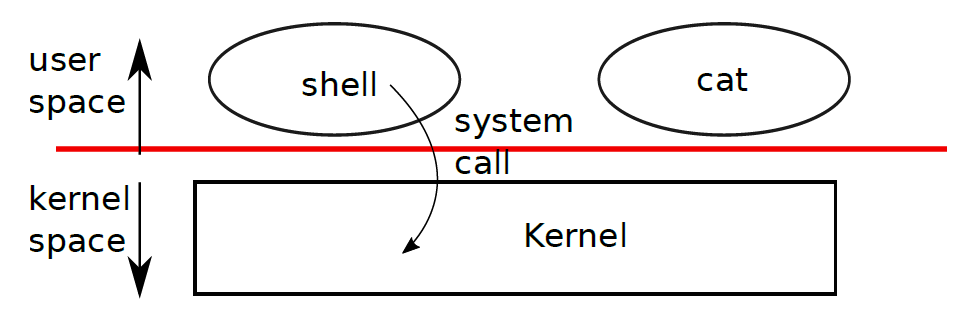
-
shell:一个普通的程序,其功能是让用户输入命令并执行它们,shell不是内核的一部分【如果shell是内核的一部分的话,那么那么频繁的shell与用户交互将产生极大的开销】
- shell中执行某个命令,实际上是要求shell执行这个命令所对应文件。具体操作是shell用
fork创建出一个新的进程,并在这个新的进程中使用exec执行这个命令。这样shell本身不会受影响,能够保持控制权。
- shell中执行某个命令,实际上是要求shell执行这个命令所对应文件。具体操作是shell用
xv6系统调用流程
Lab中对system call的使用很简单,看起来和普通函数调用并没有什么区别,但实际上的调用流程是较为复杂的。我们很容易产生一些疑问:系统调用的整个生命周期具体是什么样的?用户进程和内核进程之间是如何切换上下文的?系统调用的函数名、参数和返回值是如何在用户进程和内核进程之间传递的?
当你运行C语言并执行例如open或者write的系统调用时,从技术上来说,open是一个C函数,但是这个函数内的指令实际上是机器指令,也就是说我们调用的open函数并不是一个C语言函数,它是由汇编语言实现,组成这个系统调用的汇编语言实际上在RISC-V中被称为
ecall。这个特殊的指令将控制权转给内核。之后内核检查进程的内存和寄存器,并确定相应的参数。
1.用户态调用
在用户空间,所有system call的函数声明写在user.h中,调用后会进入usys.S执行汇编指令:将对应的系统调用号(system call number)置于寄存器a7中,并执行ecall指令进行系统调用,其中函数参数存在a0~a5这6个寄存器中。ecall指令将触发软中断,cpu会暂停对用户程序的执行,转而执行内核的中断处理逻辑,陷入(trap)内核态。
2.上下文切换
中断处理在kernel/trampoline.S中,首先进行上下文的切换,将user进程在寄存器中的数据save到内存中(保护现场),并restore(恢复)kernel的寄存器数据。内核中会维护一个进程数组(最多容纳64个进程),存储每个进程的状态信息,proc结构体定义在proc.h,这也是xv6对PCB(Process Control Block)的实现。用户程序的寄存器数据将被暂时保存到proc->trapframe结构中。
3.内核态执行
完成进程切换后,调用trap.c/usertrap(),接着进入syscall.c/syscall(),在该方法中根据system call number拿到数组中的函数指针,执行系统调用函数。函数参数从用户进程的trapframe结构中获取(a0~a5),函数执行的结果则存储于trapframe的a0字段中。完成调用后同样需要进程切换,先save内核寄存器到trapframe->kernel_*,再将trapframe中暂存的user进程数据restore到寄存器,重新回到用户空间,cpu从中断处继续执行,从寄存器a0中拿到函数返回值。
至此,系统调用完成,共经历了两次进程上下文切换:用户进程 -> 内核进程 -> 用户进程,同时伴随着两次CPU工作状态的切换:用户态 -> 内核态 -> 用户态。
1.1 Processes and memory
每个进程拥有自己的用户空间内存以及内核空间状态,当进程不再执行时xv6将存储和这些进程相关的CPU寄存器直到下一次运行这些进程。kernel将每一个进程用一个PID(process identifier)指代。
常用syscall
-
fork:形式:int fork()。其作用是让一个进程生成另外一个和这个进程的内存内容相同的子进程。在父进程中fork的返回值是子进程的PID,在子进程中返回值是0,返回值小于0表示fork失败-
子进程会继承父进程的资源,可以认为除了fork的返回值不同,其余都相同【实际就是将父进程的内存镜像拷贝给子进程】。
-
fork存在的问题:fork会拷贝整个父进程的所有内容,因此如果父进程很大,则会非常耗时。优化方法是实现copy-on-write fork,这种方法只会拷贝执行exec所需要的内存。
-
-
exit:形式:int exit(int status)。让调用它的进程停止执行并且将内存等占用的资源全部释放。需要一个整数形式的状态参数,0代表以正常状态退出,1代表以非正常状态退出 -
wait:形式:int wait(int *status)。等待当前进程的子进程退出,返回子进程PID,子进程的退出状态存储到int *status这个地址中。如果调用者没有子进程,wait将返回-1-
unix系统中没有直接的方法让子进程等待父进程
-
如果一个进程调用
fork两次,如果它想要等两个子进程都退出,它需要调用wait两次。每个wait会在一个子进程退出时立即返回。且wait返回了子进程的进程号,所以你就可以知道是哪个子进程退出了。
-
-
exec:形式:int exec(char *file, char *argv[])。加载一个文件,获取执行它的参数,将当前进程的内存替换为该文件,执行该文件内中的内容。如果执行错误(文件不存在)返回-1,执行成功则不会返回,而是开始从文件入口位置开始执行命令,这个被执行的命令可能会有返回值。文件必须是ELF格式。
xv6 shell使用以上四个system call来为用户执行程序。在shell进程的main中主循环先通过getcmd来从用户获取命令,然后调用fork来运行一个和当前shell进程完全相同的子进程。父进程调用wait等待子进程exec执行完(在runcmd中调用exec)
1.2 I/O and File descriptors
-
file descriptor(fd):文件描述符,用来表示一个被内核管理的、可以被进程读/写的对象的一个整数,表现形式类似于字节流,通过打开文件、目录、设备等方式获得。一个文件被打开得越早,文件描述符就越小。
每个进程都拥有自己独立的文件描述符列表,在 POSIX 语义中,0,1,2 这三个 fd 值已经被赋予特殊含义,分别是标准输入( STDIN_FILENO ),标准输出( STDOUT_FILENO ),标准错误( STDERR_FILENO )。shell将保证这3个文件描述符是可用的【shell会自动打开这三个文件,并且将0连接到标准输入,1连接到标准输出】
- 因此I/O重定向就是通过改变输入输出的文件描述符来实现的
-
read和write:形式int write(int fd, char *buf, int n)和int read(int fd, char *bf, int n)。从(向)文件描述符fd读(写)n字节bf的内容,返回值是成功读取(写入)的字节数。每个文件描述符有一个offset,offset会自动累加,即read会从这个offset开始读取内容,读完n个字节之后将这个offset后移n个字节,下一个read将从新的offset开始读取字节。write也有类似的offset。 -
close。形式是int close(int fd),将打开的文件fd释放,使该文件描述符可以被后面的open、pipe等其他system call使用。使用
close来修改文件描述符表能够实现I/O重定向父进程的fd table将不会被子进程fd table的变化影响,但是文件中的offset将被共享。
-
dup。形式是int dup(int fd),复制一个新的fd指向的I/O对象,返回这个新fd值,两个I/O对象(文件)的offset相同除了
dup和fork之外,其他方式不能使两个I/O对象的offset相同,比如同时open相同的文件
1.3 Pipes
-
pipe:管道,管道建立时会创建一对文件描述符,一个文件描述符用来读,另一个文件描述符用来写,将数据从管道的一端写入,将使其能够被从管道的另一端读出。写入的数据将被缓存在内核中,读出时也是从内核中读取。
pipe是一个system call,形式为int pipe(int p[]),p[0]为读取使用的文件描述符,p[1]为写入使用的文件描述符。管道关闭时,只需要用close()分别关闭这两个文件描述符。管道通信的数据是无格式的字节流
匿名管道 命名管道 只能由创建这个管道的进程访问 可以由任意进程访问 只能用于有亲缘关系的进程间通信(父子进程、兄弟进程) 通信双方不要求亲缘关系 是一种特殊的文件,可以使用 read()/write(),但不是普通的文件,不属于文件系统,只存在于内存中管道文件在文件系统中可见 半双工方式,有固定的读端和写端 严格遵守先进先出(FIFO)规则 生命周期随着进程创建而建立,随着进程终止而消失
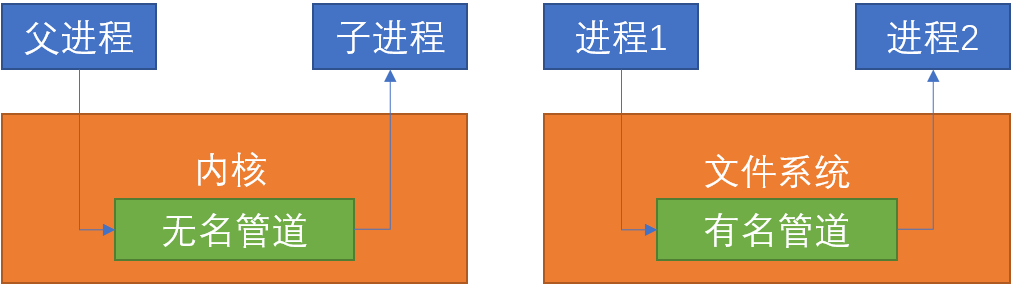
注意:
- 管道中一有空闲区域,写进程就会试图向管道写入数据,如果读进程不读取管道缓冲区内的数据,则写操作会阻塞。
- 同理,管道中一旦有数据,则读进程就会试图从管道中读出数据,如果写进程不继续写了,则空管道会导致读操作阻塞。
实现父子进程间的单工通信:创建好管道后,将一个进程的读端关闭、写端打开,将另一个进程的写端关闭、读端打开。写端写入的数据存放到内存缓冲区,等待读端的读取。
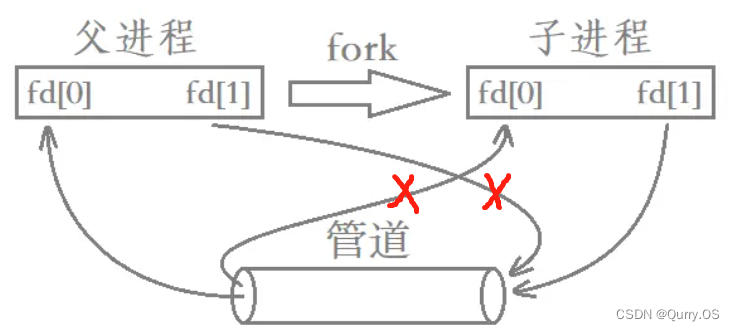
使用无名管道:先在父进程中创建管道,然后fork出子进程,这样子进程继承父进程前面创建的管道。
使用有名管道:
1.4 File system
xv6文件系统包含了文件(byte arrays)和目录(对其他文件和目录的引用)。目录生成了一个树,树从根目录/开始。对于不以/开头的路径,认为是是相对路径
mknod:创建设备文件,一个设备文件有一个major device #和一个minor device #用来唯一确定这个设备。当一个进程打开了这个设备文件时,内核会将read和write的system call重新定向到设备上。- 一个文件的名称和文件本身是不一样的,文件本身,也叫inode,可以有多个名字,也叫link,每个link包括了一个文件名和一个对inode的引用。一个inode存储了文件的元数据,包括该文件的类型(file, directory or device)、大小、文件在硬盘中的存储位置以及指向这个inode的link的个数
fstat:形式为int fstat(int fd, struct stat *st),将inode中的相关信息存储到st中。link:创建一个指向同一个inode的文件名。unlink则是将一个文件名从文件系统中移除,只有当指向这个inode的文件名的数量为0时这个inode以及其存储的文件内容才会被从硬盘上移除
注意:Unix提供了许多在用户层面的程序来执行文件系统相关的操作,比如mkdir、ln、rm等,而不是将其放在shell或kernel内,这样可以使用户比较方便地在这些程序上进行扩展。但是cd是一个例外,它是在shell程序内构建的,因为它必须要改变这个调用者shell本身指向的路径位置,如果是一个和shell平行的程序,那么它必须要调用一个子进程,在子进程里起一个新的shell,再进行cd,这是不符合常理的。
1.5 Lab 1: Xv6 and Unix utilities
添加新的命令程序,需要在根目录下的Makefile中添加相应的编译规则,并重新编译xv6。如:

sleep
#include "kernel/types.h"
#include "user/user.h"
int main(int argc, char* argv[]) {
if (argc == 1) {
fprintf(2, "ERROR: sleep time required!\n");
exit(1); // 记得写这种返回状态
}
sleep(atoi(argv[1])); // 注意是第二个参数,第一个参数是程序名
exit(0);
}
pingpong
题意:父进程向子进程发送1个字节,子进程回应"ping";子进程向父进程发送1个字节,父进程回应"pong"。
开两个pipe,一个pipe负责子进程写父进程读,另一个pipe负责父进程写子进程读。注意最后要把所有的pipe fd关闭掉。
#include "kernel/types.h"
#include "user/user.h"
enum { RD, WR };
int main(void) {
int p_p2c[2], p_c2p[2]; // pipes
char d_p2c[81], d_c2p[81]; // data
pipe(p_p2c), pipe(p_c2p); // inital pipes
int pid, status;
if ((pid = fork()) < 0) {
fprintf(2, "fork error\n");
exit(1);
} else if (pid == 0) { // child
// close(p_p2c[WR]), close(p_c2p[RD]);
read(p_p2c[RD], d_p2c, sizeof(d_p2c));
// close(p_p2c[RD]);
printf("%d: received %s\n", getpid(), d_p2c);
write(p_c2p[WR], "pong", sizeof(int));
// close(p_c2p[WR]);
exit(0);
} else { // parent
// close(p_p2c[RD]), close(p_c2p[WR]);
write(p_p2c[WR], "ping", sizeof(int));
// close(p_p2c[WR]);
read(p_c2p[RD], d_c2p, sizeof(d_c2p));
// close(p_c2p[RD]);
printf("%d: received %s\n", getpid(), d_c2p);
wait(&status);
close(p_p2c[WR]), close(p_c2p[RD]);
close(p_p2c[RD]), close(p_c2p[WR]);
exit(0);
}
}
总结
- 需要2个pipe,因为如果只用一个pipe的话,就会造成自己写自己读了
- 注意最后要把所有的pipe fd关闭掉,因为文件描述符是系统资源,不能一直占用
- 先写才能读,否则读端将一直阻塞(因为管道空时,读操作被阻塞)
- read/write的第二个参数是数据的存放地址,第三个参数是数据字节总数,从这个地址开始读取/写入这么多个字节的数据
primes
质数筛法:将一组数feed到一个进程里,先print出最小的质数,然后用其他剩下的数feed到下一个进程,依次尝试整除刚刚print出来的质数,如果可以整除,则将其print,不能整除则将其feed到下一个进程中,直到最后打印出所有的质数。
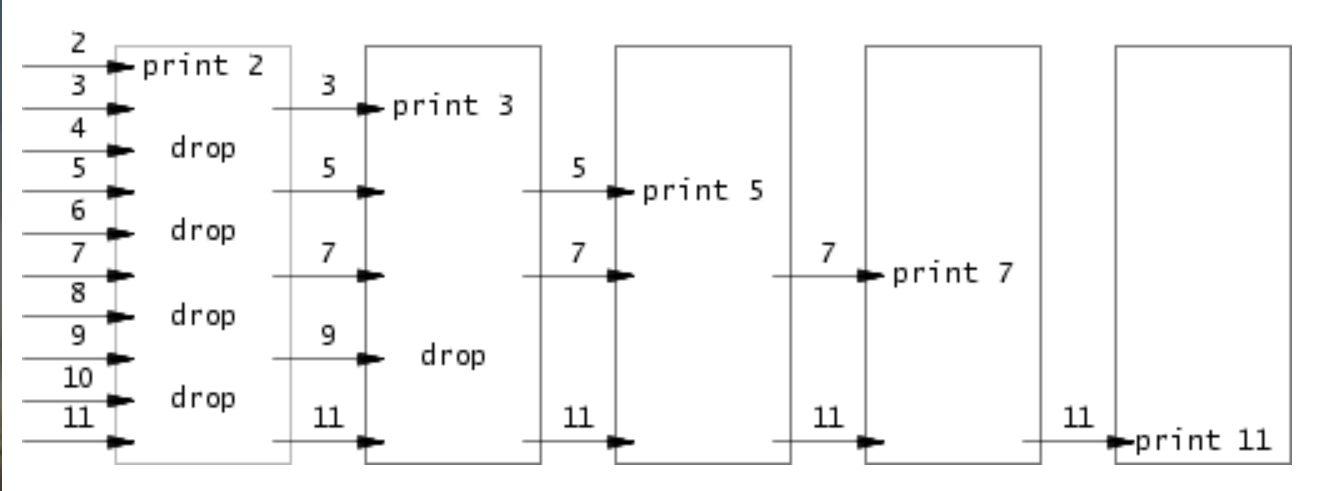
注意最开始的父进程要等待所有子进程exit才能exit
解决思路:采用递归,每次先尝试从左pipe中读取一个数,如果读不到说明已经到达终点,exit,否则再创建一个右pipe并fork一个子进程,将筛选后的数feed进这个右pipe。
#include "kernel/types.h"
#include "user/user.h"
enum { RD, WR };
#define PRIME_NUM 35
void child(int*);
// main process : to boost the primes
int main() {
// new a pipe
int p_main[2];
pipe(p_main);
int pid;
// fork the first child, and feed the first child
if ((pid = fork()) < 0) {
fprintf(2, "fork error\n");
} else if (pid == 0) { // child
child(p_main);
} else { // parent
close(p_main[RD]); // 读端用不到
// write the num list to child, wait for child's work
for (int i = 2; i <= PRIME_NUM; i++) {
write(p_main[WR], &i, sizeof(int));
}
close(p_main[WR]);
// main process need to wait all the child process to exit
wait(0); // 相当于wait(NULL);
}
exit(0);
}
// child process : to printf primes
// need a pipe connect parent and child
inline void child(int* p_c2c) {
int p_cc2cc[2];
pipe(p_cc2cc);
close(p_c2c[WR]); // 写端用不到
int n;
if (read(p_c2c[RD], &n, sizeof(int)) == 0) { // 读不到数据了,说明是最后一个子进程,回收资源
close(p_c2c[RD]);
close(p_cc2cc[WR]);
close(p_cc2cc[RD]);
exit(0);
}
// 要创建子进程,这样才能从父进程管道发,然后从子进程收
if (fork() == 0) {//child
child(p_cc2cc);
} else {//parent、
close(p_cc2cc[RD]);// 读端用不到
// 一边读,一边写
int prime = n;
while (read(p_c2c[RD], &n, sizeof(int)) != 0) { // 这里体现出read系统调用的offset指针递增性
if (n % prime != 0) { // 写入所有待筛的数
write(p_cc2cc[WR], &n, sizeof(int));
}
}
//回收资源
close(p_c2c[RD]);
printf("prime %d\n", prime); // 要放在读写完毕后输出,否则会多输出一个 "primes 0"
close(p_cc2cc[WR]);
wait(0); // 父进程要等待(这里体现出wait是等待当前进程的所有子进程的特性)
exit(0);
}
}
总结
-
read读取后,文件位置指针会相应递增 -
wait会等待当前进程的所有子进程结束。在父进程中使用wait等待子进程完成命令。 -
管道使用前后需要及时关闭:如果数据没有准备好,那么对管道执行的
read会一直等待,直到有数据了或者其他绑定在这个管道写端口的描述符都已经关闭了。在后一种情况中,read会返回 0,就像是一份文件读到了最后。读操作会一直阻塞直到不可能再有新数据到来了,这就是为什么我们在执行wc之前要关闭子进程的写端口。- 文件描述符溢出: xv6限制fd的范围为0~15,而每次pipe()都会创建两个新的fd,如果不及时关闭不需要的fd,会导致文件描述符资源用尽。可以使用重定向到标准I/O的方式来避免生成新的fd,首先close()关闭标准I/O的fd,然后使用
dup()复制所需的管道fd(会自动复制到序号最小的fd,即关闭的标准I/O),随后对pipe两侧fd进行关闭(此时只会移除描述符,不会关闭实际的file对象)。 - pipeline关闭: 在完成素数输出后,需要依次退出pipeline上的所有进程。在退出父进程前关闭其标准输入fd,此时read()将读取到eof(值为0),此时同样关闭子进程的标准输入fd,退出进程,这样进程链上的所有进程就可以退出。
- 文件描述符溢出: xv6限制fd的范围为0~15,而每次pipe()都会创建两个新的fd,如果不及时关闭不需要的fd,会导致文件描述符资源用尽。可以使用重定向到标准I/O的方式来避免生成新的fd,首先close()关闭标准I/O的fd,然后使用
-
相同的工作,使用递归
find
用递归方式找到指定的文件夹下符合某个名字(精确查找)的文件。使用open()打开当前fd,用fstat()判断fd的type,如果是文件,则与要找的文件名进行匹配;如果是目录,则循环read()到dirent结构,得到其子文件/目录名,拼接得到当前路径后使用进入递归调用。注意对于子目录中的.和..不要进行递归。
#include "kernel/fs.h" //文件夹索引结构体
#include "kernel/stat.h" //文件信息结构体,我们要用文件信息判断是文件还是文件夹
#include "kernel/types.h"
#include "user/user.h"
/* 参考和修改(copy)自user/ls.c */
void find(char* path, char* filename) {
int fd; // 用于操作文件的文件描述符
char buf[512]; // 存储完整的文件路径
char* p; // 用于不断增长buf的工作指针
struct dirent de; // 文件夹索引结构体
struct stat st; // 文件信息结构体
// 打开当前的文件路径path(unix系统一切皆文件),获取这个DIR的fd
if ((fd = open(path, 0)) < 0) { // 打开文件路径,
fprintf(2, "find: cannot open %s\n", path);
return;
}
// fstat通过已经打开的文件描述符来获取文件信息结构体st
if (fstat(fd, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
// 现在我们有了一个有DIR_path指明的fd
// 解析DIR_path, path 是当前文件路径, de.name 是当前文件名
while (read(fd, &de, sizeof(de)) == sizeof(de)) { // 一次读取一个DIR信息
strcpy(buf, path); // 更新当前路径buf
// 更新p指针
p = buf + strlen(buf); // 使其指向路径buf末尾("\0"之前)
*p++ = '/'; // buf末尾添加/,向system call说明其是DIR
if (de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ); // 将当前读取到的DIR的name字段拷贝到当前的p指针出,不断増长buf串
p[DIRSIZ] = 0; // 将buf末尾字符置为'\0',以便API识别(后面就要用了)
// 通过stat打开当前buf路径(因为还未打开,所以用stat)
if (stat(buf, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", buf);
continue;
}
switch (st.type) {
case T_FILE: // 如果是文件,则可以直接检查文件名是否相等
if (strcmp(filename, de.name) == 0)
printf("%s\n", buf);
break;
case T_DIR: // 如果是目录,则需要递归深入下一层次
// 题目hints中提示对于"."和".."无需深入
if (strcmp(de.name, ".") != 0 && strcmp(de.name, "..") != 0)
find(buf, filename);
break;
}
}
close(fd);
}
int main(int argc, char* argv[]) {
if (argc != 3) {
fprintf(2, "arguments need 2!\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
总结
- 指令在命令行给出的参数,实际上第一个参数是命令名本身,因此
find x实际上有2个参数:find 和 x - 学会从例程和先有代码学习用法并应用
xrags
就是实现将标准输入作为参数一起输入到xargs后面跟的命令中
如果标准输入有多行,那么也要执行多次命令
使用fork创建一个子进程,在子进程中用exec执行相应的命令。父进程wait。对标准输入每次读一个char,若读到\n需要执行命令。注意在执行xargs这个命令行的时候,最后肯定要按一个回车,这时标准输入最后会有一个回车,所以在EOF前是会有一个回车的!
#include "kernel/param.h"
#include "kernel/types.h"
#include "user/user.h"
// 参数的长度肯定有限制,这里选1024字节
#define MAX_LEN 1024
enum { stdin, stdout, stderr };
int main(int argc, char* argv[]) {
if (argc < 2) {
fprintf(stderr, "argument at least 2\n");
exit(0);
}
char* args[MAXARG]; // 所有参数的内容
char arg[MAX_LEN]; // 一条参数的内容(用来交给exec执行)
int pid;
int n;
int cmd_idx = 0;
char cmd;
// 读取第一个参数xrags之后的参数
for (int i = 1; i < argc; i++) {
args[i - 1] = argv[i];
}
// 读取xrags指令的参数
while ((n = read(stdin, &cmd, sizeof(char)) > 0)) {
if (cmd == '\n') { // 碰到\n,则要执行一条指令
arg[cmd_idx] = 0; // 末尾加'\0'
if ((pid = fork()) < 0) {
fprintf(stderr, "fork err\n");
exit(0);
} else if (pid == 0) {
args[argc - 1] = arg; // 将读取到的整条指令arg赋给args,注意args的第一条是xargs
args[argc] = 0; // 指令字符串末尾置0
/* ====debug: 输出获取到的参数==== */
for (int i = 0; i < argc; i++) {
printf("%c", *args[i]);
}
printf("\n");
/* ====debug: 输出获取到的参数==== */
exec(args[0], args);
} else {
wait(0); // 记得等待
cmd_idx = 0; // 重置指针
}
} else arg[cmd_idx++] = cmd; // 读取指令的字符
}
exit(0);
}
总结
- 熟悉
exec()系统调用的用法 - 指令的参数中,第一个参数是默认的,必须是该命令本身的名字
- 熟悉C语言指针、数组指针、指针数组的用法
- 记得
fork后要wait
Lec03 OS organization and system calls
本节相关的源文件:
- The user-space code for systems calls is in
user/user.handuser/usys.pl. - The kernel-space code is
kernel/syscall.h, kernel/syscall.c. - The process-related code is
kernel/proc.handkernel/proc.c.
xv6体系结构概述
RISC-V体系结构有3中CPU可以执行指令的模式:machine mode、supervisor mode、user mode。
- 机器模式(M模式):用于配置计算机。CPU在机器模式下启动,执行在机器模式下的指令有全部特权
- 特权模式(S模式):用于运行操作系统内核,为应用程序提供服务
- 用户模式(U模式):用于运行应用程序
ecall 指令:为了实现从用户模式切换到特权模式,CPU提供了 ecall 指令将CPU从用户模式切换为特权模式,并在内核指定的入口处进入内核。一旦CPU切换到特权模式,内核就可以验证系统调用的参数,决定是否允许应用程序执行请求的操作。
xv6中进程的虚拟地址空间结构:
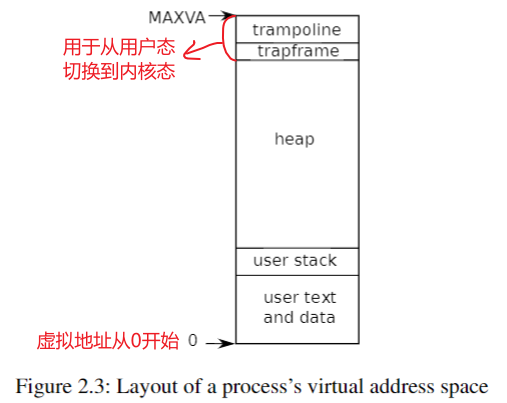
xv6中的结构体 proc 用于保存进程的状态,包括页表、内核堆栈和运行状态,就是PCB。
每个进程有两个堆栈: 一个用户堆栈和一个内核堆栈(p->kstack)。当进程执行用户指令时,只有它的用户堆栈在使用,而它的内核堆栈是空的。当进程进入内核(用于系统调用或中断)时,内核代码在进程的内核堆栈上执行; 当一个进程在内核中时,它的用户堆栈仍然包含保存的数据,但不会被主动使用。进程的线程在主动使用其用户堆栈和内核堆栈之间进行交替。内核堆栈是独立的(并且不受用户代码的保护) ,因此即使进程破坏了其用户堆栈,内核也可以执行。
xv6源码结构
- kernel:xv6是宏内核,因此这里包含了几乎所有的内核文件,该文件夹下的所有文件会被编译为运行在内核态的叫kernel的二进制文件
- user:运行在用户态的所有文件
- mkfs:创建一个空的文件镜像,我们会将这个镜像存在磁盘上,这样我们就可以直接使用一个空的文件系统
xv6中内核源文件各自对应的功能模块如下,其中模块间的接口声明在 kernel/defs.h 中
| 源文件 | 描述 |
|---|---|
| bio.c | 文件系统的磁盘块缓存。 |
| console.c | 连接用户键盘和屏幕的驱动 |
| entry.S | 第一个引导(boot)指令 |
| exec.c | exec() 系统调用 |
| file.c | 文件描述符 |
| fs.c | 文件系统 |
| kalloc.c | 物理页分配器 |
| kernelvec.S | 处理来自内核的陷阱(trap)和定时器中断 |
| log.c | 文件系统的日志和崩溃恢复日志 |
| main.c | 在引导(boot)期间控制其他模块的初始化 |
| pipe.c | 管道 |
| plic.c | RISC-V中断控制器 |
| printf.c | 控制台(console)格式化输出 |
| proc.c | 进程和进程调度 |
| sleeplock.c | 让CPU的锁 |
| spinlock.c | 不让CPU的锁 |
| start.c | 早期机器模式引导(boot)代码 |
| string.c | C字符串和字符数组库 |
| swtch.S | 线程切换 |
| syscall.c | 分发系统调用给相应的函数实现 |
| sysfile.c | 文件相关的系统调用 |
| sysproc.c | 进程相关的系统调用 |
| trampoline.S | 用于在用户态和核心态间切换的汇编代码 |
| trap.c | 处理陷阱和中断并从中返回的C代码 |
| uart.c | 串口控制台设备驱动程序 |
| virtio_disk.c | 磁盘设备驱动程序 |
| vm.c | 管理页表和地址空间 |
xv6启动流程
机器模式下
当 RISC-V 计算机启动时,它会初始化自己并运行一个存储在ROM中的引导加载程序(boot loader)。引导加载程序将xv6内核加载到内存中。然后在机器模式下,CPU 从 _entry (kernel/entry.S)开始执行xv6。RISC-V 首先禁用分页硬件: 虚拟地址直接映射到物理地址。
加载程序将xv6内核加载到物理地址为0x8000000的内存中。之所以将内核放在0x80000000而不是0x0,是因为地址范围 0x0~0x80000000 包含 I/O 设备。
# qemu -kernel loads the kernel at 0x80000000
# and causes each hart (i.e. CPU) to jump there.
# kernel.ld causes the following code to
# be placed at 0x80000000.
.section .text
.global _entry
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spin
xv6在 kernel/start.c 中声明了一个初始化栈 stack0 ,在 _entry 处的指令装载地址为 stack0 + 4096 的栈顶指针寄存器 sp ,以此建立了一个栈以供xv6运行C代码。
特权模式下
kernel/start.c 中的函数 start() 在机器模式下执行一些配置,然后就切换到特权模式。
RISC-V提供指令 mret ,该指令用于从异常处理模式下退出而进入出现异常之前的模式。在这里用于从机器模式进入特权模式,因此需要设置机器模式之前的模式为特权模式。
// entry.S jumps here in machine mode on stack0.
void
start()
{
// 设置之前的模式是特权模式
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x);
// 设置异常程序计数器的值为main的地址
// requires gcc -mcmodel=medany
w_mepc((uint64)main);
// 暂时禁用分页
w_satp(0);
// 将所有中断和异常委托给特权模式
w_medeleg(0xffff);
w_mideleg(0xffff);
w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// 配置物理内存保护以提供管理模式
// 获得访问所有物理内存的权限
w_pmpaddr0(0x3fffffffffffffull);
w_pmpcfg0(0xf);
// 请求时钟中断
timerinit();
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
// 切换到特权模式并跳转 main()
asm volatile("mret");
}
start isn’t returning from such a call, and instead sets things up as if there had
been one: it sets the previous privilege mode to supervisor in the register mstatus, it sets the
return address to main by writing main’s address into the register mepc, disables virtual address
translation in supervisor mode by writing 0 into the page-table register satp, and delegates all
interrupts and exceptions to supervisor mode.
Before jumping into supervisor mode, start performs one more task: it programs the clock
chip to generate timer interrupts. With this housekeeping out of the way, start “returns” to super-
visor mode by calling mret. This causes the program counter to change to main
用户模式下
在 main (kernel/main.c)初始化几个设备和子系统之后,它通过调用 userinit (kernel/proc.c)创建第一个进程。
volatile static int started = 0;
// start() jumps here in supervisor mode on all CPUs.
void
main()
{
if(cpuid() == 0){
consoleinit();
printfinit();
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging
procinit(); // process table
trapinit(); // trap vectors
trapinithart(); // install kernel trap vector
plicinit(); // set up interrupt controller
plicinithart(); // ask PLIC for device interrupts
binit(); // buffer cache
iinit(); // inode table
fileinit(); // file table
virtio_disk_init(); // emulated hard disk
// ===============以上都是设备初始化===============
userinit(); // first user process
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
}
scheduler();
}
这个由userinit (kernel/proc.c)创建的第一个进程是用RISC-V汇编语言写的小程序(user/initcode.S),其二进制形式作为数组直接放在了 kernal/proc.c 中,这是底层C常见的写法:
uchar initcode[] = {
0x17, 0x05, 0x00, 0x00, 0x13, 0x05, 0x45, 0x02,
0x97, 0x05, 0x00, 0x00, 0x93, 0x85, 0x35, 0x02,
0x93, 0x08, 0x70, 0x00, 0x73, 0x00, 0x00, 0x00,
0x93, 0x08, 0x20, 0x00, 0x73, 0x00, 0x00, 0x00,
0xef, 0xf0, 0x9f, 0xff, 0x2f, 0x69, 0x6e, 0x69,
0x74, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00
};
汇编形式:
# Initial process that execs /init.
# This code runs in user space.
#include "syscall.h"
# exec(init, argv)
.globl start
start:
la a0, init
la a1, argv
li a7, SYS_exec
ecall
# for(;;) exit();
exit:
li a7, SYS_exit
ecall
jal exit
# char init[] = "/init\0";
init:
.string "/init\0"
# char *argv[] = { init, 0 };
.p2align 2
argv:
.long init
.long 0
这个进程 initcode 调用 exec 系统调用重新进入内核,并将自己替换为 init(user/init.c)进程,于是当内核完成了 exec 系统调用的工作,将会返回到 init 进程的用户空间。然后 init 进程将创建一个控制台设备,打开文件描述符0、1、2,最后在控制台设备上启动 shell ,至此系统启动完成。
xv6系统调用的过程
RISC-V约定,用户态的程序将使用的系统调用的参数放在寄存器 a0 和 a1 中,系统调用号放在 a7 中,将由 syscall 从PCB的 trapframe 中获取,而系统调用执行后的返回值则放在 a0 中。
然后由 ecall 指令触发 trap 中断进入内核,执行 uservec、usertrap、syscall。
以 fork 系统调用为例:
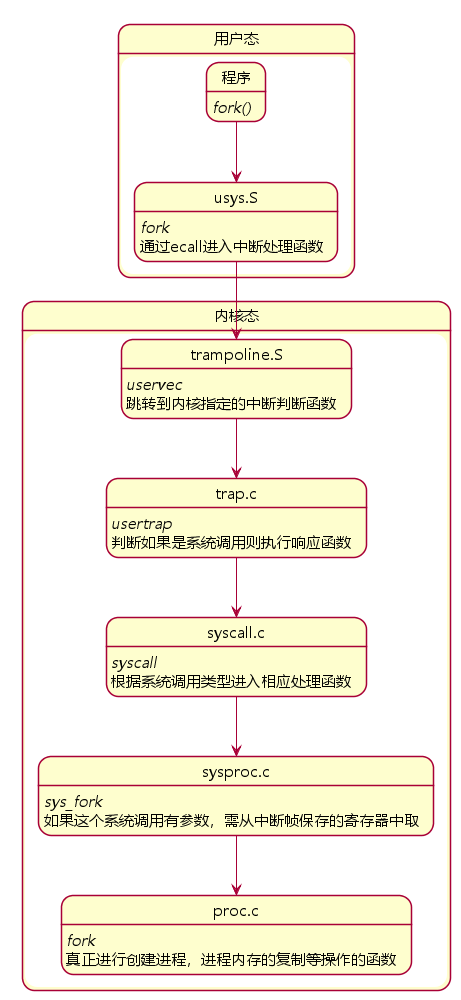
解释一下各文件的作用:
fork()是用户程序在用户态下调用系统调用usys.S是xv6系统用于实现从用户态切换到核心态的ecall的汇编语言文件,由 Perl 语言编写的脚本 usys.pl 生成trampoline.S是用于实现跳转到不同的中断的汇编语言文件trap.c是中断服务程序,调用syscall()syscall.c分发系统调用到其对应的实现函数。核心内容就是最后的syscall()函数,通过函数指针数组,通过存储在a7寄存器中的系统调用号来调用相应的系统调用sysproc.c接收参数并给proc结构体复制proc.c存放着系统调用的真正实现
总结:xv6的系统调用链路如下:
- 在user/user.h做函数声明
- Makefile调用usys.pl生成usys.S,里面写了具体实现,通过ecall进入kernel,通过设置寄存器a7的值,表明调用哪个system call
- ecall表示一种特殊的trap,转到kernel/syscall.c:syscall执行
- syscall.c中有个函数指针数组,即一个数组中存放了所有指向system call实现函数的指针,通过寄存器a7的值定位到某个函数指针,通过函数指针调用函数
- 系统调用返回值存入寄存器a0
Lab 2: system calls
根据实验指导书,首先需要将 $U/_trace 添加到 Makefile 的 UPROGS 字段中。
首先浏览一下源码:
(1)对 kernal/syscall.c 文件的分析:
extern uint64 sys_chdir(void);
...
extern uint64 sys_trace(void);
// 系统调用的函数指针数组,其中 "[下标] 函数指针" 的语法是GCC特有
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
...
[SYS_trace] sys_trace, // 这两个是Lab要求我们写的系统调用,需要注册到这里,使得下面的syscall函数能调用
[SYS_close] sys_close,
};
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
使用 extern 关键字声明函数名,因为在下面引用了这些函数名;使用函数指针数组。
(2)生成的 user/usys.S 内容
user/usys.pl 为每一个系统调用都生成如下的汇编代码:
.global xxx
xxx:
li a7, SYS_xxx
ecall
ret
li a7, SYS_trace 将系统调用号存入 a7 寄存器中,然后使用 ecall 指令进入内核态。在内核态 kernel/syscall.c 的 syscall 函数中,使用 p->trapframe->a7 取出寄存器中的系统调用号,然后查找syscalls数组中的对应的处理函数并调用。
System call tracing
系统调用作用:监控指定的系统调用的调用
第一步:添加系统调用声明和入口
- 可以看到,在 user/trace.c 文件中,使用了 trace 函数,因此需要在 user/user.h 文件中加入函数声明:
int trace(int); - 同时,为了生成进入中断的汇编文件
usys.S,需要在user/usys.pl添加进入内核态的入口函数的声明:entry("trace");,以便使用ecall中断指令进入内核 - 同时在 kernel/syscall.h 中添加系统调用的指令码
#define SYS_trace 22(直接加在最下面就可以),这样就可以编译成功了
第二步:实现系统调用
我们的目的是跟踪程序调用了哪些系统调用函数,因此需要在每个 trace 进程中,添加一个掩码 mask 字段,用来识别是否执行了 mask 标记的系统调用。在执行 trace 进程时,如果进程调用了 mask 所包括的系统调用(进程的系统调用号和 mask 所对应的系统调用匹配),就打印到标准输出中,注意对于创建了子进程的情况,mask 也需要继承到子进程。
-
首先在 kernel/proc.h 中,在
proc结构体中添加mask字段:int mask; -
在 kernel/sysproc.c 中添加之前声明时用到的
sys_trace的实现:// trace the system call from user space uint64 sys_trace(void){ int mask; if(argint(0, &mask) < 0) // get the trace mask return -1; myproc()->syscallnum = mask;//put the trace mask into structure return 0; }其中,
argint()函数从对应的寄存器中取出参数并转成 int 类型。
第三步:打印trace跟踪到的信息
由于trace只能跟踪到截止到调用当前的进程的系统调用使用情况,因此应该在 kernel/syscall.c 中的系统调用分发函数 syscall() 函数中,所有的系统调用都需要通过这个函数来执行,在其他所有系统调用结束后,再输出trace跟踪到的信息:
在 kernel/syscall.c 中添加 extern uint64 sys_trace(void); 和 [SYS_trace] sys_trace, ,并修改 syscall() :
void
syscall(void)
{
int num;
struct proc *p = myproc();
char* syscall_name[23] = {"fork", "exit", "wait", "pipe", "read", "kill", "exec", "fstat", "chdir", "dup", "getpid", "sbrk", "sleep", "uptime", "open", "write", "mknod", "unlink", "link", "mkdir", "close", "trace", "sysinfo"}; //系统调用名
num = p->trapframe->a7; // 从a7寄存器取出系统调用号
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
//使用num查找系统调用函数,并调用num;
//将返回值存储在p->trapframe->a0中
p->trapframe->a0 = syscalls[num]();//通过函数指针调用相应的系统调用
if((1 << num) & (p->mask)) //如果当前进程的系统调用号和 mask 匹配
printf("%d: syscall %s -> %d\n", p->pid, syscall_name[num-1], p->trapframe->a0);
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
Sysinfo
系统调用作用:收集运行时的系统信息,即填充struct sysinfo 这个结构体(see kernel/sysinfo.h)
先去 kernel/sysinfo.h 中查看结构体 struct sysinfo:
struct sysinfo {
uint64 freemem; // 空闲内存大小 (bytes)
uint64 nproc; // 正在运行的进程数目(state is not UNUSED)
};
可见我们要实现的是为这个结构体填充这两个字段的内容。
第一步:添加系统调用入口
同trace的步骤
- 在 user/user.h 文件中加入函数声明:
int sysinfo(struct sysinfo*);,同时在开头添加结构体声明struct sysinfo; - 在
user/usys.pl添加进入内核态的入口函数的声明:entry("sysinfo"); - 同时在 kernel/syscall.h 中添加系统调用的指令码
#define SYS_sysinfo 23
第二步:实现系统调用
(1)获取空闲内存大小以填充freemem
内存分配和销毁的相关内容都在 kernel/kalloc.c 文件中。这个文件中有2个结构体:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;
在xv6中,内存信息以链表形式存储,每个链表结点表示一个物理内存页。从 kfree 函数中可以发现,每次创建一个页时,将其内容初始化为1,然后将它的下一个节点指向当前节点的 freelist,更新 freelist 为这个新创建的页。也就是说,freelist 指向最后一个可以使用的内存页,它的 next 指向上一个可用的内存页。
因此,我们可以通过从后往前遍历所有的 freelist 来获取可用内存页数,然后乘上页大小即可。添加获取内存中剩余空闲内存的函数:
在 kernel/kalloc.c 中实现 free_mem() :
uint64 free_mem(void)
{
//这里可以加锁
//acquire(&kmem.lock);
struct run *r = kmem.freelist;
uint64 cnt = 0;
while (r) {
cnt++;
r = r->next;
}
//release(&kmem.lock);
return cnt * PGSIZE;
}
(2)获取进程数目
所有的进程有关的操作都保存在 /kernel/proc.c 文件中,其中的 proc 数组保存了所有进程。进程有五种状态(UNUSED、SLEEPING、RUNNABLE、RUNNING、ZOMBIE),我们只需要遍历 proc 数组,计算不为 UNUSED 状态的进程数目即可。
在 kernel/proc.c 中实现 n_proc() :
int n_proc(void)
{
struct proc *p;
int cnt = 0;
for (p = proc; p < &proc[NPROC]; p++) {
//这里可以加锁
//acquire(&kmem.lock);
if (p->state != UNUSED)
cnt++;
//release(&kmem.lock);
}
return cnt;
}
(3)声明上述函数
在 kernel/defs.h 添加声明:
// kalloc.c
void* kalloc(void);
void kfree(void *);
void kinit(void);
uint64 free_mem(void);//新增加的2条
int n_proc(void);
(4)实现 sysinfo 系统调用主体
在 kernel/sysproc.c 中实现该系统调用:
uint64 sys_sysinfo(void)
{
struct sysinfo info;
uint64 addr;// address of the sys info structure pointer
struct proc* p = myproc();
if(argaddr(0, &addr) < 0) {
return -1;
}
info.freemem = free_mem();
info.nproc = n_proc();
if (copyout(p->pagetable, addr, (char*)&info, sizeof(info)) < 0) {// copy out the sysinfo struct si from kernel space to user space
return -1;
}
return 0;
}
注意:由于是涉及内核态和用户态的地址转换,所以需要使用copyout函数(kernel/vm.c),将内核空间中相应的地址内容复制到用户空间中。这里就是将 info 的内容复制到进程的虚拟地址内,具体是哪个虚拟地址,由函数传入的参数决定(addr读取第一个参数并转成地址的形式)。
在 kernel/syscall.c 中添加 extern uint64 sys_sysinfo(void); 和 [SYS_sysinfo] sys_sysinfo, ,并修改 syscall() :
char* syscall_name[22] = {"fork", "exit", "wait", "pipe", "read", "kill", "exec", "fstat", "chdir", "dup", "getpid", "sbrk", "sleep", "uptime", "open", "write", "mknod", "unlink", "link", "mkdir", "close", "trace", "sysinfo"}; // 末尾添加上 sysinfo 的名字
Lec04 Page tables
几个接下来要用到的英文缩写:
- 物理页号(Physical Page Numer, PPN)
- 页表项(Page Table Entries, PTE)
- 页表地址寄存器(SATP)
- 内存管理单元(Memory Management Unit, MMU)
这章内容关于页面、虚实地址转换的内容可以看计组课本和王道
每个核都有自己的MMU和TLB。处理器旁边就是DRAM芯片。
关于CPU core的概念有点生疏了,可以参考这篇:如何理解处理器、CPU、多处理器、内核、多核?
4.1 地址空间(Address Spaces)
设置虚拟内存的目的除了解决主存与辅存容量差距的问题,另一个原因之一还有实现进程间的隔离性。
通过虚拟内存机制的页表为进程分配页面,进程的页表中没有的页面该进程就访问不到,因此实现了进程间内存空间的隔离。每个程序都运行在自己的地址空间,并且这些地址空间彼此之间相互独立。
对于一个操作系统来说,CPU只是一部分,I/O设备同样也很重要。所以当你在写一个操作系统时,你需要同时处理CPU和I/O设备,比如你需要向互联网发送一个报文,操作系统需要调用网卡驱动和网卡来实际完成这个工作。
因此为了让内核使用物理内存和硬件资源,内核需要按照一定的规则排布内核地址空间,以能够确定哪个虚拟地址对应自己需要的硬件资源地址。用户地址空间不需要也不能够知道这个规则,因为用户空间不允许直接访问这些硬件资源。
当进程运行在用户态时,使用的是用户页表,运行在内核态时,使用的是内核页表。
当kernel创建了一个进程,针对这个进程的page table也会从Free memory中分配出来。内核会为用户进程的page table分配几个page,并填入PTE。在某个时间点,当内核运行了这个进程,内核会将进程的根page table的地址加载到SATP中。从那个时间点开始,处理器会使用内核为那个进程构建的虚拟地址空间。
4.1.1 内核页表(Kernel Page Table)
主板的设计人员决定了,在完成了虚拟到物理地址的翻译之后,如果得到的物理地址大于0x80000000会走向DRAM芯片;如果得到的物理地址低于0x80000000会走向不同的I/O设备。
因此QEMU会模拟一个地址范围0x80000000(KERNBASE) ~ 0x86400000(PHYSTOP)作为物理内存。QEMU模拟出的IO设备的端口(物理地址)是在0x8000000以下的范围(小于0x8000000),kernel对这些暴露的设备接口控制寄存器的访问是直接和这些设备交互而不是RAM进行交互的。
kernel/memlayout.h 中声明了xv6内核内存布局的常量。
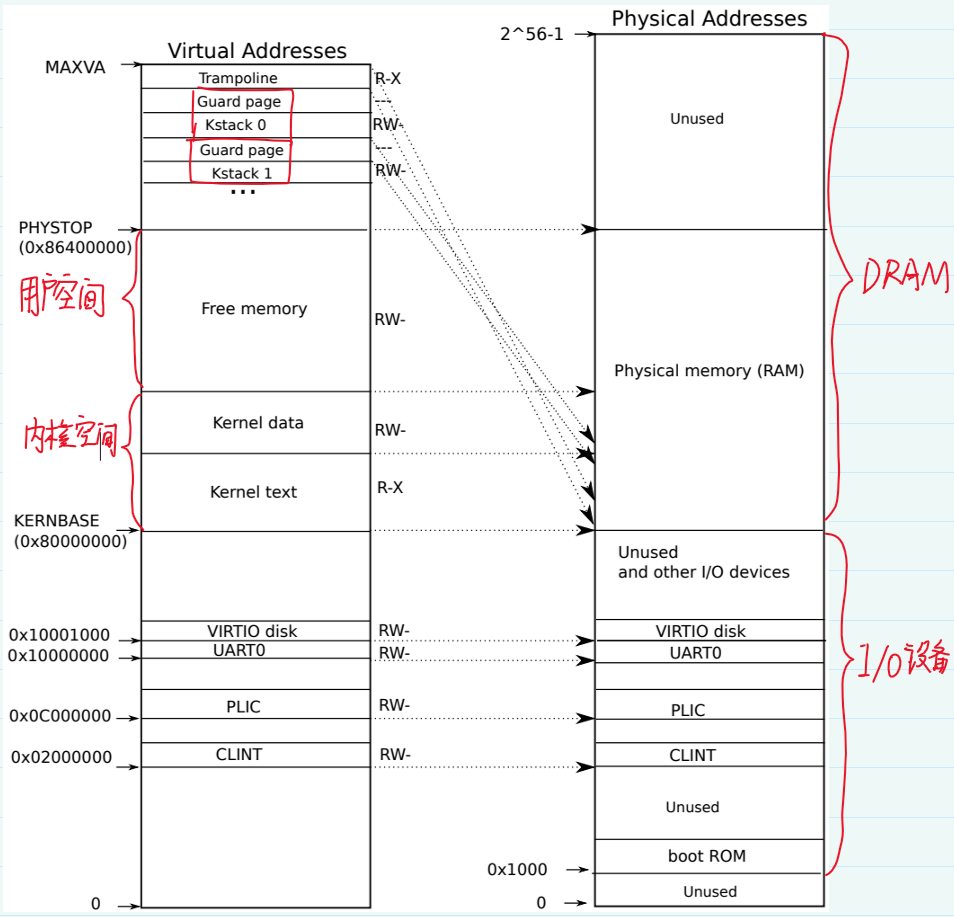
上图是内核中虚实地址的映射关系。左边和右边分别是内核虚拟地址和物理地址的映射关系。在虚拟地址和物理地址中,映射到的位置都是直接相等对应的,是相等映射。
观察上图:
- Kernel text page的权限是R-X,因为可以读取,也可以在这个地址段执行指令,但不能向Kernel text写数据。
- Kernel data的权限是RW-,因为需要能被写入,但不能在这个地址段运行指令。【所以,kernel text用来存代码,代码可以读,可以运行,但是不能篡改,kernel data用来存数据,数据可以读写,但是不能通过数据伪装代码在kernel中运行】
有一些不是直接映射的内核虚拟地址:
- trampoline page(和user pagetable在同一个虚拟地址,以便在user space和kernel space之间跳转时切换进程仍然能够使用相同的映射,真实的物理地址位于kernel text中的
trampoline.S) - kernel stack page:每个进程有一个自己的内核栈kstack,每个kstack下面有一个没有被映射到物理地址的guard page,guard page的作用是,当kstack溢出时,会溢出到guard page,但是guard page的PTE的Valid标志位(PTE_V)未设置,因此会触发page fault,但又不会影响其他kstack。为了不浪费内存,guard page不必映射到物理内存,它只是占据了虚拟地址空间的一段靠后的地址。当进程运行在内核态时使用内核栈,运行在用户态时使用用户栈。注意:还有一个内核线程,这个线程只运行在内核态,不会使用其他进程的kstack,内核线程没有独立的地址空间
4.2 页表(Page Table)
OS为每个进程维护一个页表,用于描述该进程的用户地址空间,还有一个内核地址空间(所有进程共享这一个描述内核地址空间的页表)。
页表本身保存在内存中,CPU指令中的地址是虚拟地址。
页表地址寄存器(SATP)存储着当前运行在内存中的进程的页表在内存中的物理地址。
要解析虚拟地址时,内存管理单元(MMU)从SATP中读取当前分配了CPU的进程的页表的物理地址,从而找到当前页表,然后通过查页表完成虚实地址变换。
由于每个进程都拥有一个页表,因此当OS将CPU切换到另一个进程时,要切换SATP中的内容以指向新进程在内存中的页表的物理地址。
物理内存大小和虚拟内存大小没有直接关系,物理内存可以比虚拟内存更大,虚拟内存也可以比物理内存更大。
多级页表的实现是硬件实现,对于操作系统来说不可见。
| 一级页表 | 多级页表 |
|---|---|
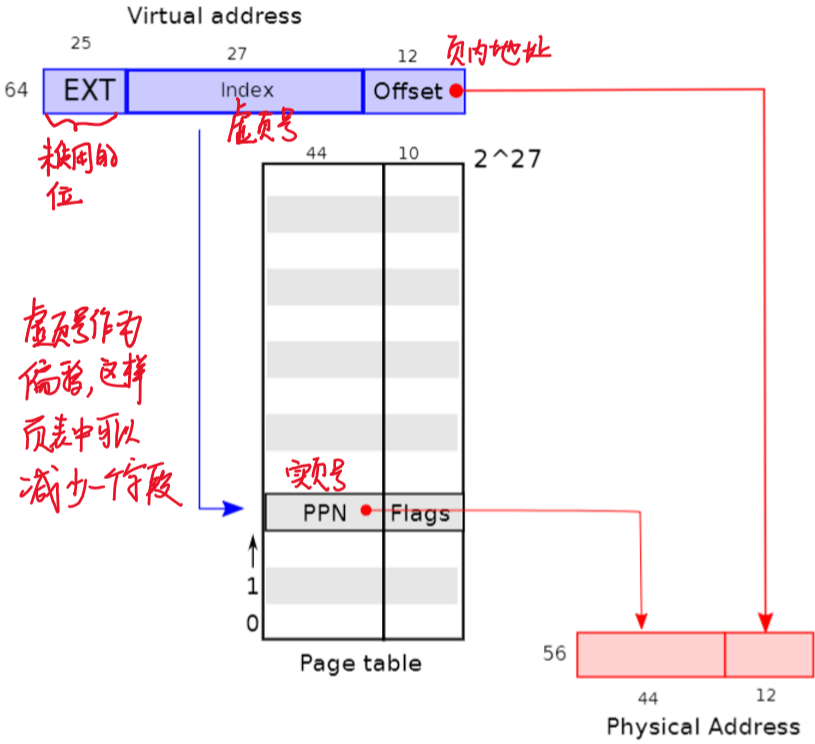 |
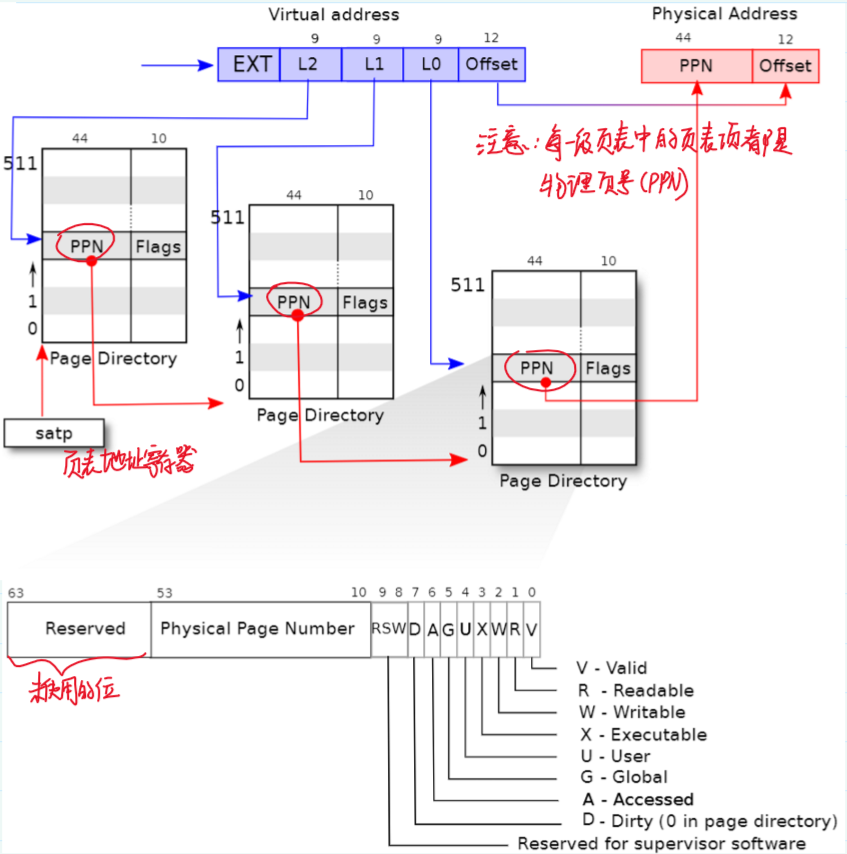 |
为了使分页机构能够正常运行,操作系统必须设置satp寄存器为1级页表的物理地址。
4.4 页表缓存/快表(TLB)
TLB由相联存储器实现,对于操作系统来说不可见。
如果你切换了page table,操作系统需要告诉处理器当前正在切换page table,处理器会清空TLB。因为本质上来说,如果你切换了page table,TLB中的缓存将不再有用,它们需要被清空,否则地址翻译可能会出错。
4.5
int argc, char *argv[]
