
第03次作业-栈和队列
1.学习总结
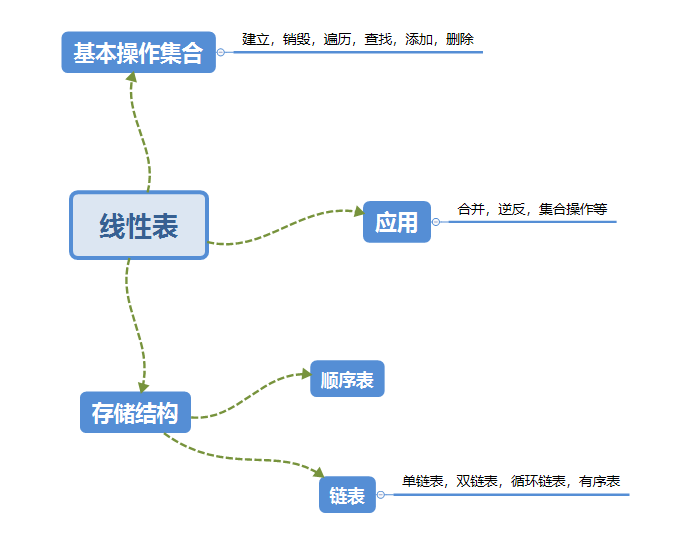
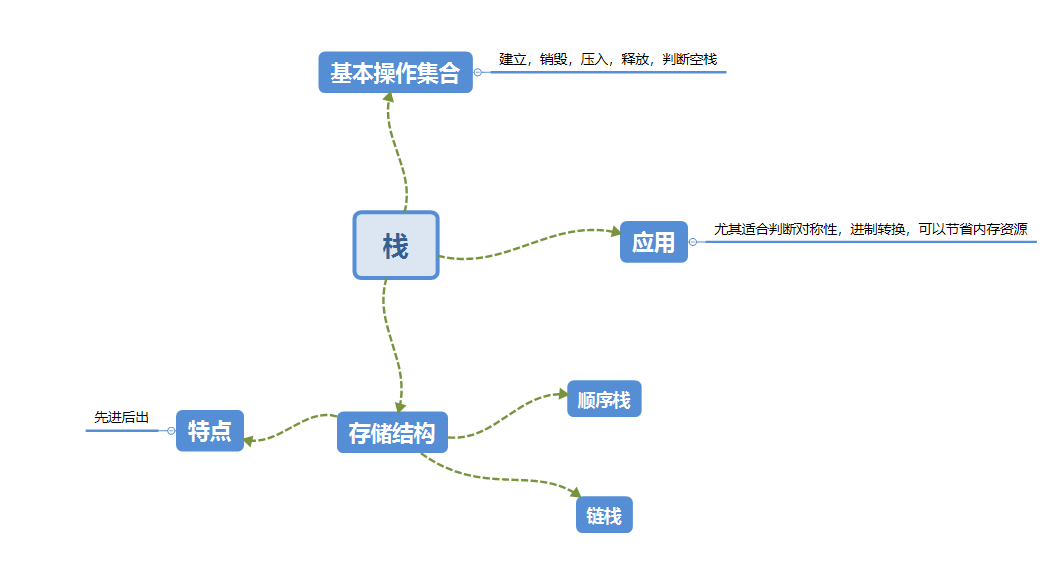
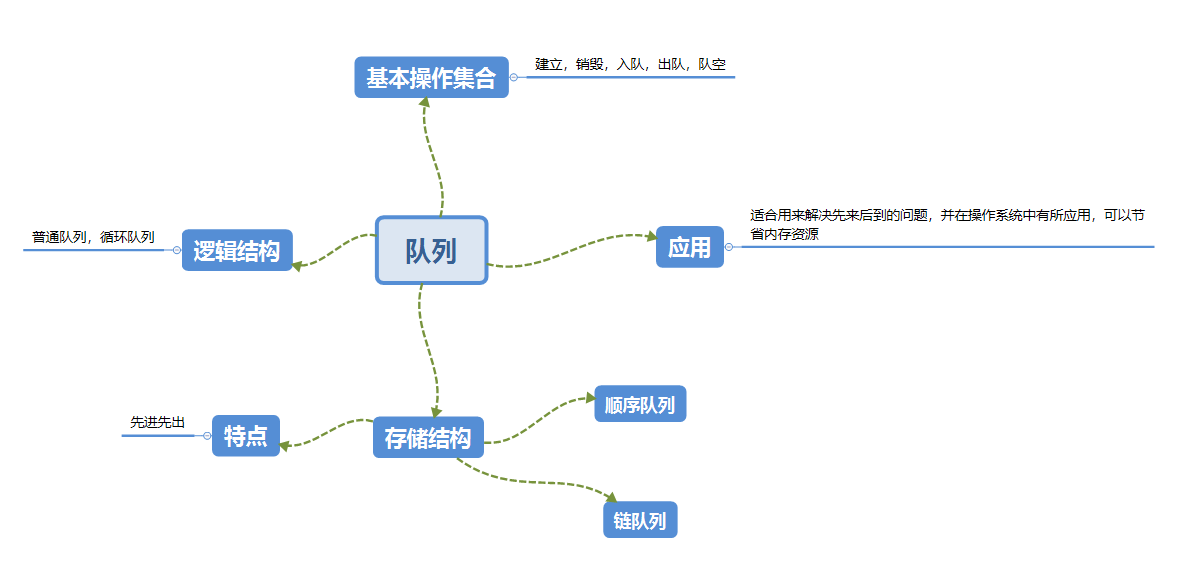
2.1
7-3 表达式转换(25 分)
2.2 设计思路(伪代码或流程图)
int main() { 定义字符串a保存输入 定义栈s1 读入字符串a 定义计数用变量fu,判断一次循环结束后要不要加空格 for(i=0;i!=size(a);i++) { if a[i]是数字或小数点 直接输出 end if else if 当a[i]是减号或加号,判断栈是否为空,或上一个字符是否是左括号 是则直接输出,且fu++ end if else if 判断是否为括号 左括号直接入栈 ,遇见右括号则输出左括号之后所有的元素 end if else if 判断是否是正常符号 如果是,输出直至栈内的优先级不高于自己 end if if 是符号且fu==0 输出空格 } 输出数据,不表 }
2.3 代码截图(注意,截图、截图、截图。代码不要粘贴博客上。不用用···语法去渲染)



2.4 PTA提交列表说明。

一开始打完代码爆出了多种错误,甚至连一个数字的测试点也错了。详细阅读后题目发现了问题所在,补上了小数点和正负的情况。最后发现还有括号嵌套,换了遇到括号算法。
7-4(选做) 列车调度(25 分)
2.2 设计思路(伪代码或流程图)
定义数组cuntt模拟车道 int main() { 定义队列q1以操作 定义n保存列车数量,m保存列车车号 定义t保存列车车道数量 for(int i=0;i!=n;i++) { 读入m,将m入队 } while 队列不为空 { 定义变量p保存二分查找的结果 if p不为0 将队头出队,进入countt[p]中 end if else 在countt中建立新车道,保存队头,t++ 释放队头 end if } 输出t } 二分查找,不是此题重点 int erfen(int x,int t) { 定义high=t,low=0 while low<high 定义mid=(high+low)/2 if x>countt[mid] low++或hig-- end if end while return low }
2.3 代码截图(注意,截图、截图、截图。代码不要粘贴博客上。不用用···语法去渲染)
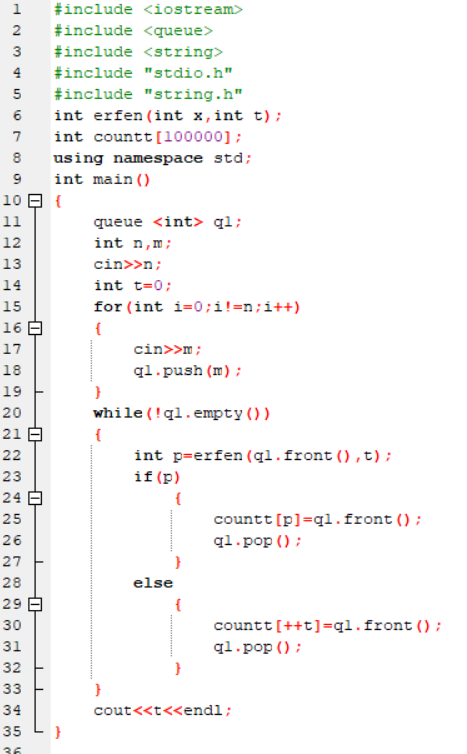

2.4 PTA提交列表说明。

这一题做起来非常非常痛苦,不是因为题目难度的问题,而是我完全曲解了题目的意思。
在没有梦见一个叫Wikipedia的老头前,我一直以为一条车道只能有一辆火车,所以怎么改simple的答案都是6.
知道这个以后,又因为时间复杂度是n²,只能用二分查找降低时间复杂度。
7-5(选做) 堆栈模拟队列(25 分)
2.2 设计思路(伪代码或流程图)
int main() { 定义n,m分别保存两个栈的大小,并定义并读入s1,s2两个栈 定义变量maxx,minn,其中maxx用来保存m和n里较小的那个,作为满栈标记 do { if ch==A 读入一个数,定义变量shu保存该数 if s1满且s2不为空 输出错误,end if else if s1不满 shu入s1栈 end if else { for(int i=0;i<maxx;i++) { 把s1中的元素全部压入s2中 } shu入s1栈 } end if else if ch==D if s1不为空 { if s2为空 { while(!s1.empty()) { 把s1中的元素全部压入s2中 } 输出并释放s2的栈顶元素 } else 输出并释放s2的栈顶元素 } else 输出空栈错误 end if end if 读入下一个字母 } while(ch!='T') end while }
2.3 代码截图(注意,截图、截图、截图。代码不要粘贴博客上。不用用···语法去渲染)



2.4 PTA提交列表说明。

我已经搞不清楚这是队列题还是栈题了,救命我要用数组……
一开始我对这题有些误解,以为是用两个栈模拟出来一个长度等于s1+s2的队列,结果错的一塌糊涂。经过广哥点播后恍然大悟,从队列的定义入手,成功解决了这题。
3.截图本周题目集的PTA最后排名
本次2个题目集总分:125+215=340分
必做题共:205分
3.1 栈PTA排名

3.2 队列PTA排名
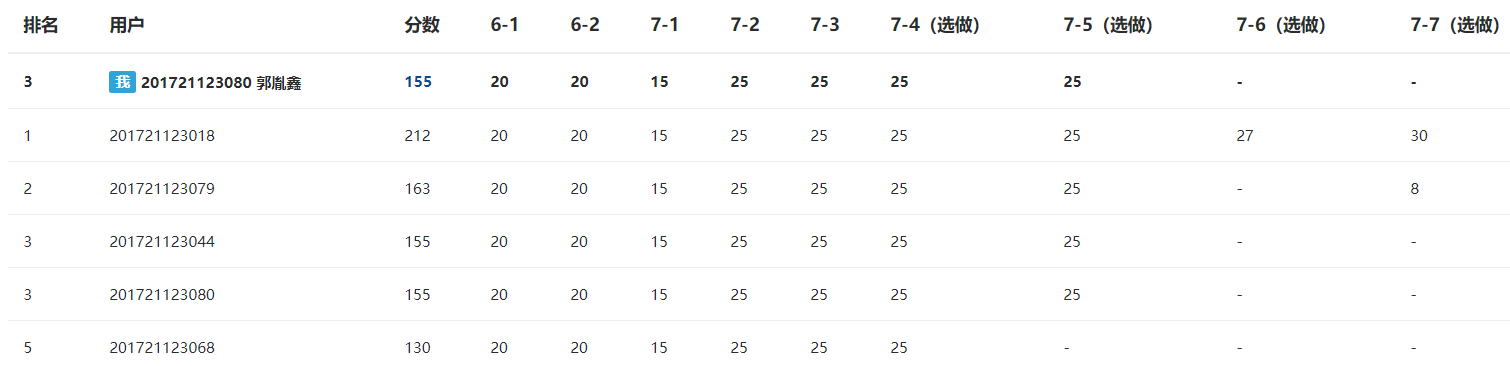
3.3 我的总分:
155+125==280
4. 阅读代码
https://gitee.com/AllElnWen/data_structure_linear_table_02_experimental_report/blob/master/%E9%93%BE%E8%A1%A87-1.cpp
#include<stdio.h> #include<stdlib.h> typedef struct Node* List; struct Node{ int data; struct Node *Next; }; List CreatList(); void print(List L); void read(List L); void combine(List L1,List L2,List L3); int main() { List L1,L2,L3; L1=CreatList(); L2=CreatList(); L3=CreatList(); read(L1); read(L2); combine(L1,L2,L3); print(L3); return 0; } List CreatList() { List L; L=(List)malloc(sizeof(struct Node)); if(!L) return NULL; L->Next=NULL; return L; } void print(List L) { L=L->Next; if(L==NULL) { printf("NULL"); return; } while(L) { if(L->Next==NULL) printf("%d",L->data); else printf("%d ",L->data); L=L->Next; } } void read(List L) { List s; int data; scanf("%d",&data); while(data>0) { s=(List)malloc(sizeof(struct Node)); if(!s) return; s->data=data; s->Next=NULL; L->Next=s; L=s; scanf("%d",&data); } return; } void combine(List L1,List L2,List L3) { L1=L1->Next; L2=L2->Next; while(L1!=NULL&&L2!=NULL) { if(L1->data>L2->data) { L3->Next=L2; L2=L2->Next; } else { L3->Next=L1; L1=L1->Next; } L3=L3->Next; } if(L1==NULL&&L2==NULL) return; if(L1!=NULL) L3->Next=L1; else L3->Next=L2; return; }
很有趣的,这一段代码采用了另一种创建链表的方法:它先用CreatList()函数单单创建了一个表头,之后再调用read()函数真正创造两个链表,在输入的data小于0时结束这个函数。
这样的手法较之普通的创建链表方法,并没有太大优势。
combine()函数不仅仅是将两个链表合并,它更以L->data的大小来对两个链表进行了一次重新排序。即像搭积木一样把两个链表的一个个节点分离,按照data的大小彼此组合,是很精彩的算法。
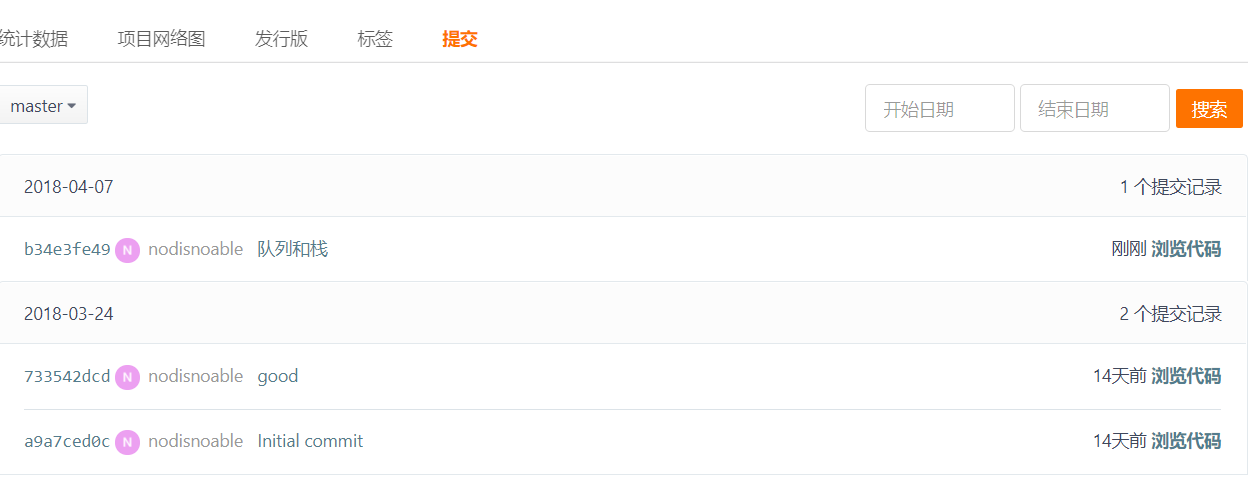
5. 代码Git提交记录截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号