
bridge
1 . 前言
本文是参考附录上的资料整理而成,以帮助读者更好的理解kernel中brdige 模块代码。
2. 网桥的原理
2.1 桥接的概念
简单来说,桥接就是把一台机器上的若干个网络接口“连接”起来。其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去。以使得网口之间的报文能够互相转发。
交换机就是这样一个设备,它有若干个网口,并且这些网口是桥接起来的。于是,与交换机相连的若干主机就能够通过交换机的报文转发而互相通信。
如下图:主机A发送的报文被送到交换机S1的eth0口,由于eth0与eth1、eth2桥接在一起,故而报文被复制到eth1和eth2,并且发送出 去,然后被主机B和交换机S2接收到。而S2又会将报文转发给主机C、D。

交换机在报文转发的过程中并不会篡改报文数据,只是做原样复制。然而桥接却并不是在物理层实现的,而是在数据链路层。交换机能够理解数据链路层的报文,所以实际上桥接却又不是单纯的报文转发。
交换机会关心填写在报文的数据链路层头部中的Mac地址信息(包括源地址和目的地址),以便了解每个Mac地址所代表的主机都在什么位置(与本交换机的哪个网口相连)。在报文转发时,交换机就只需要向特定的网口转发即可,从而避免不必要的网络互。这个
就是交换机的“地址学习”。但是如果交换机遇到一个自己未学习到的地址,就不会知道这个报文应该从哪个网口转发,则只好将报文转发给所有网口(接收报文的那个网口除外)。比如主机C向主机A发送一个报文,报文来到了交换机S1的eth2网口上。假设S1刚刚启
动,还没有学习到任何地址,则它会将报文转发给eth0和 eth1。同时,S1会根据报文的源Mac地址,记录下“主机C是通过eth2网口接入的”。于是当主机A向C发送报文时,S1 只需要将报文转发到 eth2网口即可。而当主机D向C发送报文时,假设交换机S2将报文转发
到了S1的eth2网口(实际上S2也多半会因为地址学习而不这么做),则S1会 直接将报文丢弃而不做转发(因为主机C就是从eth2接入的)。然而,网络拓扑不可能是永不改变的。假设我们将主机B和主机C换个位置,当主机C发出报文时(不管发给谁),交换机S1的
eth1口收到报文,于是交换机 S1会更新其学习到的地址,将原来的“主机C是通过eth2网口接入的”改为“主机C是通过eth1网口接入的”。但是如果主机C一直不发送报文呢?S1将一直认为“主机C是通过eth2网口接入的”,于是将其他主机发送给C的报文都从eth2转
发出去,结果报文就发 丢了。所以交换机的地址学习需要有超时策略。对于交换机S1来说,如果距离最后一次收到主机C的报文已经过去一定时间了(默认为5分钟),则S1需要忘记 “主机C是通过eth2网口接入的”这件事情。这样一来,发往主机C的报文又会被转发到
所有网口上去,而其中从eth1转发出去的报文将被主机C收到。
2.2 linux的桥接实现
linux内核支持网口的桥接(目前只支持以太网接口)。但是与单纯的交换机不同,交换机只是一个二层设备,对于接收到的报文,要么转发、要么丢弃。小型的交换机里面只需要一块交换芯片即可,并不需要CPU。而运行着linux内核的机器本身就是一台主机,有可
能就是网络报文的目的地。其收到的报文除了转 发和丢弃,还可能被送到网络协议栈的上层(网络层),从而被自己消化。
linux内核是通过一个虚拟的网桥设备来实现桥接的。这个虚拟设备可以绑定若干个以太网接口设备,从而将它们桥接起来。如下图(摘自ULNI):
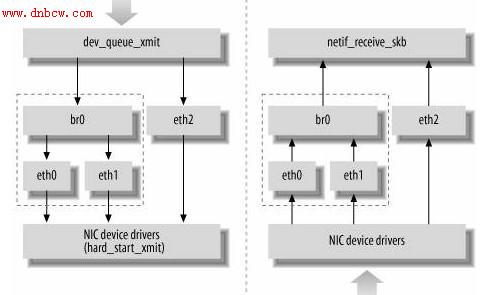
网桥设备br0绑定了eth0和eth1。对于网络协议栈的上层来说,只看得到br0,因为桥接是在数据链路层实现的,上层不需要关心桥接的细节。于是协议栈上层需要发送的报文被送到br0,网桥设备的处理代码再来判断报文该被转发到eth0或是eth1,或者两者皆是;反
过来,从eth0或从eth1接收到的报文被提交给网桥的处理代码,在这里会判断报文该转发、丢弃、或提交到协议栈上层。而有时候eth0、eth1也可能会作为报文的源地址或目的地址,直接参与报文的发送与接收(从而绕过网桥)。
2.3 网桥的功能
a. MAC学习:学习MAC地址,起初,网桥是没有任何地址与端口的对应关系的,它发送数据,还是得想HUB一样,但是每发送一个数据,它都会关心数据包的来源MAC是从自己的哪个端口来的,由于学习,建立地址-端口的对照表(CAM表)。
b. 报文转发:每发送一个数据包,网桥都会提取其目的MAC地址,从自己的地址-端口对照表(CAM表)中查找由哪个端口把数据包发送出去。
3. 网桥的配置
在Linux里面使用网桥非常简单,仅需要做两件事情就可以配置了。其一是在编译内核里把CONFIG_BRIDGE或CONDIG_BRIDGE_MODULE编译选项打开;其二是安装brctl工具。第一步是使内核协议栈支持网桥,第二步是安装用户空间工具,通过一系列的ioctl调用
来配置网桥。下面以一个相对简单的实例来贯穿全文,以便分析代码。
Linux机器有4个网卡,分别是eth0~eth4,其中eth0用于连接外网,而eth1, eth2, eth3都连接到一台PC机,用于配置网桥。只需要用下面的命令就可以完成网桥的配置:
Brctl addbr br0 (建立一个网桥br0, 同时在Linux内核里面创建虚拟网卡br0)
Brctl addif br0 eth1
Brctl addif br0 eth2
Brctl addif br0 eth3 (分别为网桥br0添加接口eth1, eth2和eth3)
其中br0作为一个网桥,同时也是虚拟的网络设备,它即可以用作网桥的管理端口,也可作为网桥所连接局域网的网关,具体情况视你的需求而定。要使用br0接口时,必需为它分配IP地址。为正常工作,PC1, PC2,PC3和br0的IP地址分配在同一个网段。
4. 网桥数据结构
网桥最主要有三个数据结构:struct net_bridge,struct net_bridge_port,struct net_bridge_fdb_entry,他们之间的关系如下图:
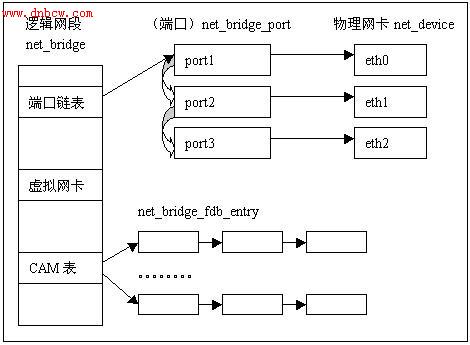
展开来如下图:

说明:
a. 其中最左边的net_device是一个代表网桥的虚拟设备结构,它关联了一个net_bridge结构,这是网桥设备所特有的数据结构。
b. 在net_bridge结构中,port_list成员下挂一个链表,链表中的每一个节点(net_bridge_port结构)关联到一个真实的网口设备的net_device。网口设备也通过其br_port指针做反向的关联(那么显然,一个网口最多只能同时被绑定到一个网桥)。
c. net_bridge结构中还维护了一个hash表,是用来处理地址学习的。当网桥准备转发一个报文时,以报文的目的Mac地址为key,如果可以在 hash表中索引到一个net_bridge_fdb_entry结构,通过这个结构能找到一个网口设备的net_device,于是报文就应该从这个
网 口转发出去;否则,报文将从所有网口转发。
各个结构体具体内容如下:
网桥私有数据:net_bridge{}
虚拟的网桥本身对于Kernel也是一个网络设备,自然拥有net_device{},而网桥操作相关的信息保存在net_bridge{}中。net_bridge{}作为(对dev而言)私有信息附属在net_device{}之后。创建网桥类型设备的时候net_bridge{}作为附属信息由alloc_netdev()一起分配。
struct net_bridge
{
spinlock_t lock;
struct list_head port_list; // net_bridge_port{}链表
struct net_device *dev; // 指向网桥设备的net_device{}
struct pcpu_sw_netstats __percpu *stats; // 统计值,TX/Rx Packet Byte之类
spinlock_t hash_lock;
struct hlist_head hash[BR_HASH_SIZE]; // 转发数据库(FDB)哈希表
其中端口设备由port_list连接,FDB是per-bridge的数据库(而且per-vlan),而非Per-port的,故保存在br结构中。考虑到FDB条目数量会比较多,查询频繁,使用Hash表保存。
IGMP Snooping和Netfilter相关的不关注。
... Netfilter 相关... u16 group_fwd_mask; /* STP */ bridge_id designated_root; bridge_id bridge_id; u32 root_path_cost; unsigned long max_age; unsigned long hello_time; unsigned long forward_delay; unsigned long bridge_max_age; unsigned long ageing_time; unsigned long bridge_hello_time; unsigned long bridge_forward_delay; u8 group_addr[ETH_ALEN]; u16 root_port; enum { BR_NO_STP, /* no spanning tree */ BR_KERNEL_STP, /* old STP in kernel */ BR_USER_STP, /* new RSTP in userspace */ } stp_enabled; unsigned char topology_change; unsigned char topology_change_detected; ... IGMP Snooping ... struct timer_list hello_timer; struct timer_list tcn_timer; struct timer_list topology_change_timer; struct timer_list gc_timer;
指定端口、网桥ID,路径成本,之类都能在STP协议中找到。我们从stp_enabled标识中看到STP(802.1D)的实现仍然放在Kernel中,而RSTP(Rapid STP)的实现被放在了UserSpace(Kernel以前也没有RSTP的实现)。RSTP的实现可以在这里找到:
git://git.kernel.org/pub/scm/linux/kernel/git/shemminger/rstp.git。事实上把某些数据量不大但逻辑相对复杂的控制协议放到应用层的例子还是比较多的,例如IPv6的ND,DHCPv4/DHCPv6,以及未来某些nftables的某些部分。RSTP需要Kernel和Userspace“合作”完成。
struct kobject *ifobj; u32 auto_cnt; #ifdef CONFIG_BRIDGE_VLAN_FILTERING u8 vlan_enabled; __be16 vlan_proto; u16 default_pvid; struct net_port_vlans __rcu *vlan_info; // 网桥设备和网桥端口设备一样,也可视为一个(对L3的)端口,也需要VLAN信息 #endif };
网桥端口:net_bridge_port{}
struct net_bridge_port {
首先是Layout信息,
struct net_bridge *br; // 所属网桥(反向引用)
struct net_device *dev; // 网桥端口自己的net_device{}结构。
struct list_head list; // 同一个Bridge的各个Port组织在链表dev.port_list中。
STP相关信息。STP中定义了端口的优先级,STP的各个状态(Disabled,Blocking,Learning,Forwarding)。还有“指定端口”,“根端口”,“指定网桥”的概念。同时还定义了几个定时器。这里保存了这写信息。这里不再复述STP。
/* STP */ u8 priority;// 端口优先级 u8 state; // 端口STP状态:Disabled,Blocking,Learning,Forwarding u16 port_no; // 端口号,每个Bridge上各个端口的端口号不能改变(不能配置) unsigned char topology_change_ack;// TCA ? unsigned char config_pending; port_id port_id; // 端口ID:Prio+端口号 port_id designated_port; bridge_id designated_root; bridge_id designated_bridge; u32 path_cost; u32 designated_cost; unsigned long designated_age; struct timer_list forward_delay_timer;// 转发延迟定时器,默认15s struct timer_list hold_timer; // 控制BPDU发送最大速率的定时器 struct timer_list message_age_timer;// BPDU老化定时器
Kernel通用信息
struct kobject kobj; // Kernel为了方便一些常用对象操作(添加删除等)建立的基本对象 struct rcu_head rcu; unsigned long flags; // 是否处于Flooding,是否Learning,是否被管理员设置了cost等 ... IGMP Snooping & Netpoll ... struct net_port_vlans __rcu *vlan_info;// 在此端口上配置的VLAN信息,例如PVID,VLAN Bitmap, Tag/Untag Map };
网桥端口设备本身对应的net_device{}结构中有一些字段会指示此设备为网桥端口,原先是br_port(v2.6.11)指针,新版的内核则看priv_flag是否设置 IFF_BRIDGE_PORT。如果是网桥端口的话,rx_handler_data指向net_bridge_port{}。这么做的原因自然是尽量让net_device不要放入功能特定的字段。
struct net_device { ... ... // 如果是网桥端口IFF_BRIDGE_PORT会被设置。 unsigned int priv_flags; /* Like 'flags' but invisible to userspace. * See if.h for definitions. */ ... ... rx_handler_func_t __rcu *rx_handler;// 创建网桥设备的时候注册为br_handle_frame() void __rcu *rx_handler_data; // 如果是网桥端口,指向net_bridge_port{} ... ... };
rx_handler是各个per-net_device的入口帧特殊处理的hook点,dev向协议栈(L3)递交skb过程,即netif_receive_skb()的处理过程中,在查询ptype_base完成L2/L3递交前,先检查各个net_device的rx_handler是不是被设置,设置的话会先调用rx_handler。而网桥端口设备的rx_handler是被设置的。
这个是虚拟网桥如何通过端口设备收包的方式。
转发数据库条目:net_bridge_fdb_entry{}
Bridge维护一个转发数据库(Forwarding Data Base),包含了端口号,在此端口上学习到的MAC地址等信息,用于数据转发(Forwarding)。整个数据库使用Hash表组织,便于快速查找。每个网桥设备的FDB保存在其 net_bridge->hash中。每个学到(或静态配置)的MAC由一个数据库的条目,即
net_bridge_fdb_entry{}结构表示。FDB是per-vlan的,因为不同的VLAN的数据转发路径(可由STP生成)可能是不一样的,FDB需要记录VLAN信息。is_local表示MAC地址来自本地某个端口,is_static表示MAC地址是静态的(由用户配置或来自本地端口),这些地址不会老化。且所有本地的
MAC(is_local为1)的MAC总是“静态的”。
struct net_bridge_fdb_entry { struct hlist_node hlist; // 哈希表冲突链表节点,头是&net_bridge.hash[i] struct net_bridge_port *dst; // 条目对应的网桥端口 unsigned long updated; unsigned long used; // 引用计数 mac_addr addr; __u16 vlan_id; // MAC属于哪个VLAN unsigned char is_local:1, // 是否是来自某个本地端口的MAC,本地端口总是is_static is_static:1, // 是否是静态配置的MAC added_by_user:1, // 用户配置 added_by_external_learn:1; // 外部学习 struct rcu_head rcu; };
5. 网桥初始化
5.1 bridge init
桥接部分初始化和退出的代码定义在net/bridge/br.c中,这还有一些事件处理函数。Bridging作为一个内核模块进行初始化。
module_init(br_init) static int __init br_init(void) { ... ... err = stp_proto_register(&br_stp_proto); ... ... err = br_fdb_init(); ... ... err = register_pernet_subsys(&br_net_ops); ... ... err = br_netfilter_init(); ... ... err = register_netdevice_notifier(&br_device_notifier); ... ... err = br_netlink_init(); ... ... brioctl_set(br_ioctl_deviceless_stub); ... ATM 相关 ... return 0; ... 出错处理 ... }
br_init()函数完成的工作有:
-
注册STP协议处理函数br_stp_rcv:在net/802/stp.c中实现了个通用的STP框架,这个框架又是建立在llc之上(net/llc/),LLC显然是用来处理802.2 LLC层的,我们知道Ethernet II Packet常用于数据传输(尤其是PC端)而802.3 with 802.2 LLC协议通常用来承载STP等控制协议。LLC本身的处理和其他Ethernet PacketType(ARP, IP, IPv6..)没有不同,都是通过dev_add_pack()向netdev的ptype_base注册rcv函数。
netif_receive_skb + |- llc_rcv <= ptype_base[ETH_P_802_2] + |- br_stp_rcv <= llc_sap->rcv_func
-
转发数据库初始化为了效率的考虑net_bridge_fdb_entry{}的分配会在kernel cache中进行。这里使用kmem_cache_create()初始化一个br_fdb_cache。另外,之前提到FDB Etnry保存在net_bridge.hash,为了防止DoS攻击,计算Hash的时候引入一个随机因子让其计算不可预测。该因子也在此处初始化。
-
注册pernet_operationspernet_operation只注册了.exit函数,作用是在某个网络实例清理的时候,将所有"net"内的的bridge设备、相关Port结构、VLAN结构、Timer和FDB等清理干净。
-
初始化桥接Netfilter:略。
-
注册通告链netdev_chain网桥设备是建立其他网络设备之上的,那些设备的状态(UP/DOWN),地址改变等消息会影响网桥设备(内部数据结构,如端口表,FBD等)。因此需要关注netdev_chain。对这些Event的处理由br_device_event()完成。
-
netlink操作初始化Bridging注册了两组Netlink的Operations,分别是AF(AF_BRIDGE)和Link级别的ops。
5.2 bridge create
一般创建一个新的网络设备分成2个基本步骤:
- 分配net_device{}并setup
也就是调用alloc_netdev_mqs(SIZE, NAME, xxx_setup)。其中 SIZE 是附着在net_device{}内存后面的特定数据,对于网桥设备而言就是net_bridge{}的大小。xxx_setup则是特有设备的初始化过程。NAME作为创建接口名的模板,如"eth%d"、"br%d"等,稍后由
register_netdevice()生成eth1, br0等设备名,也可直接指定。alloc_netdev()是alloc_netdev_mqs的wrapper,创建TX/RX队列各一个。分配时注册的xxx_setup会在alloc_netdev_mqs中被立即调用,用来初始化设备特定数据,我们之前见过ether_setup。 网桥对应的setup函数为br_dev_setup()。
和ether_setup简单设置一些ethernet参数不同,br_dev_setup完成了许多对网桥设备至关重要的工作,例如为设备指定netdev_ops(即"dev->ndo_xxx",用于后续的open/close/xmit)等。稍后会详细介绍。
- 注册网络设备
函数register_netdevice()生成dev->name、dev->ifindex, 调用dev.netdev_ops.ndo_init()初始化设备,初始化输入输出队列,将设备添加到全局(net{})设备列表,一个name为key的Hash net.dev_name_head,一个ifindex为key的Hash net.dev_index_head和,全局链表
net.dev_base_head。
而创建网桥设备同样遵循上面的步骤
在网桥的初始化函数中,注册了网桥操作的ioctl 函数br_ioctl_deviceless_stub ,当添加网桥的时候,通过该函数调用br_add_bridge来实现网桥的创建 。
br_dev_setup()函数
不论使用netlink还是传统的ioctl都会调用alloc_netdev_mqs,后者会调用setup函数br_dev_setup。它的实现在net/bridge/br_device.c中。
void br_dev_setup(struct net_device *dev) { struct net_bridge *br = netdev_priv(dev); eth_hw_addr_random(dev); //生成一个随机的MAC地址 ether_setup(dev);// 虚拟的Bridge是Ethernet类型,进行ethernet初始化(type, MTU,broadcast等)。 dev->netdev_ops = &br_netdev_ops; // 网桥设备的netdev_ops dev->destructor = br_dev_free; dev->ethtool_ops = &br_ethtool_ops; SET_NETDEV_DEVTYPE(dev, &br_type);// br_type.name = "bridge" dev->tx_queue_len = 0; dev->priv_flags = IFF_EBRIDGE;// 标识此设备为Bridge dev->features = COMMON_FEATURES | NETIF_F_LLTX | NETIF_F_NETNS_LOCAL | NETIF_F_HW_VLAN_CTAG_TX | NETIF_F_HW_VLAN_STAG_TX; dev->hw_features = COMMON_FEATURES | NETIF_F_HW_VLAN_CTAG_TX | NETIF_F_HW_VLAN_STAG_TX; dev->vlan_features = COMMON_FEATURES; br->dev = dev; spin_lock_init(&br->lock); INIT_LIST_HEAD(&br->port_list);//初始化网桥端口链表和锁 spin_lock_init(&br->hash_lock); br->bridge_id.prio[0] = 0x80; // 默认优先级 br->bridge_id.prio[1] = 0x00; // STP相关初始化 ether_addr_copy(br->group_addr, eth_reserved_addr_base);// 802.1D(STP)组播01:80:C2:00:00:00 br->stp_enabled = BR_NO_STP;// 默认没有打开STP,不阻塞任何组播包。 br->group_fwd_mask = BR_GROUPFWD_DEFAULT; br->group_fwd_mask_required = BR_GROUPFWD_DEFAULT; br->designated_root = br->bridge_id; br->bridge_max_age = br->max_age = 20 * HZ; // 20sec BPDU老化时间 br->bridge_hello_time = br->hello_time = 2 * HZ;// 2sec HELLO定时器时间 br->bridge_forward_delay = br->forward_delay = 15 * HZ;// 15sec 转发延时(用于Block->Learning->Forwardnig) br->ageing_time = 300 * HZ;// FDB 中保存的MAC地址的老化时间(5分钟) br_netfilter_rtable_init(br); // Netfilter (ebtables) br_stp_timer_init(br); br_multicast_init(br);// 多播转发相关初始化 }
先为网桥设备生成一个随机的MAC地址,当bridge的第一个接口被binding的时候,bridge的MAC字段自动转为第一个接口的地址。虚拟网桥设备上ethernet类型,因此会调用ether_setup()。
每个net_device有一组netdev_ops用来处理设备打开、关闭,传输等,Bridge的net_device_ops内容则更丰富一些,需要ndo_add_save, ndo_fdb_add稍后详细介绍。ethtool可用来查看链接是否UP,以及设备的信息(驱动类型,版本,固件版本,总线等)。
开始的时候网桥总是认为自己是根网桥,所有designeated_root设置成自己网桥ID。而一些STP的定时器也需要设置成默认值。有些定时器是双份的,原因是STP的Timer是由Root Bridge通告,而不是使用自己的值。但是自己也可能会成为Root,所以要维护一份自己的定时器值。
5.3 bridge port create
和创建网桥设备一样,为网桥设备添加端口设备,也可以使用ioctl和netlink两种方式。两种方式最终会调用br_add_if()。
br_add_if()函数
int br_add_if(struct net_bridge *br, struct net_device *dev)
端口资格检查,有几类设备不能作为网桥端口:
- loopback设备
- 非Ethernet设备
- 网桥设备,即不支持“网桥的网桥”
- 本身是另一个网桥设备端口。每个设备只能有一个Master,否则数据去哪里呢
- 配置为IFF_DONT_BRIDGE的设备
/* Don't allow bridging non-ethernet like devices */ if ((dev->flags & IFF_LOOPBACK) || dev->type != ARPHRD_ETHER || dev->addr_len != ETH_ALEN || !is_valid_ether_addr(dev->dev_addr)) return -EINVAL; /* No bridging of bridges */ if (dev->netdev_ops->ndo_start_xmit == br_dev_xmit) return -ELOOP; /* Device is already being bridged */ if (br_port_exists(dev)) return -EBUSY; /* No bridging devices that dislike that (e.g. wireless) */ if (dev->priv_flags & IFF_DONT_BRIDGE) return -EOPNOTSUPP;
如果新的端口设备没有问题,就可以进行分配和初始化net_bridge_port{},这些工作由new_nbp()完成。
- 分配一个net_bridge_port{}结构;
- 分配端口ID。
- 初始化端口成本(协议规定万兆、千兆,百兆和十兆的默认成本为2, 4, 19和100),
- 设置端口默认优先级,
- 初始化端口角色(dp)状态(blocking)。
- 启动STP定时器等。
网桥设备需要接收所有的组播包,原来此处调用的是 dev_set_promiscuity(dev, 1)让网桥端口(可能是实际设备)工作在混杂模式,这样才能接收目的MAC非此设备的Unicast以及(未join的)所有的Multicast。
p = new_nbp(br, dev); if (IS_ERR(p)) return PTR_ERR(p); call_netdevice_notifiers(NETDEV_JOIN, dev); err = dev_set_allmulti(dev, 1); if (err) goto put_back;
sysfs和kobj
Kernel为所有的网桥端口建立一个kobj,这样一来可以方便的使用sysfs_ops设置sysfs参数,以及其他对象操作(例如删除对象的时候,release_nbp被调用以删除net_bridge_port结构。通过,kobject_init_and_add/br_sysfs_addif实现p->kobj的初始化和注册等。一旦注册,就可以
在/sys/class/net//brif//找到它相应的目录。
err = kobject_init_and_add(&p->kobj, &brport_ktype, &(dev->dev.kobj), SYSFS_BRIDGE_PORT_ATTR); if (err) goto err1; err = br_sysfs_addif(p); if (err) goto err2;
既然是网桥端口那么dev->priv_flags被设置上IFF_BRIDGE_PORT。同时网桥端口不支持LRO,原因是LRO(Large Receive Offload)适用于目的为Host的Packet,而网桥端口可能会转发数据到其他端口,自然就不能启用这个功能(启用了还会影响GSO)。
dev->priv_flags |= IFF_BRIDGE_PORT;
dev_disable_lro(dev);
添加端口设备到网桥设备端口列表新建完一个新的端口设备,该初始化的也初始化了,现在可以加入到网桥中了。
list_add_rcu(&p->list, &br->port_list);
更新FDB,初始化VLAN
网桥设备端口的MAC需要“静态”配置到FDB中,is_local和is_static同时置1。这回答了网桥端口是否有MAC地址的问题
if (br_fdb_insert(br, p, dev->dev_addr, 0)) netdev_err(dev, "failed insert local address bridge forwarding table\n");
初始化网桥端口的VLAN配置,如果Bridge设备有“Default PVID",就将默认PVID设置为端口的PVID并且Untag。
if (nbp_vlan_init(p)) netdev_err(dev, "failed to initialize vlan filtering on this port\n");
重新计算网桥MAC,Bridge ID
当一个网桥设备(不是端口设备)刚刚创建的时候,其MAC地址是随机的(见 br_dev_setup,旧实现是空MAC),这也会影响网桥ID(Prio+MAC),没有端口时网桥ID的MAC部分为0。当有个设备作为其端口后,是个合适的机会重新为网桥选一个MAC,并重新计算网桥ID。前提是如果这个端口的
MAC合适的话,例如不是0,长度是48Bits,并且值比原来的小(STP中ID小好事,因为其他因素一样的情况下MAC愈小ID愈小,优先级就越高),就用这个端口的MAC。
changed_addr = br_stp_recalculate_bridge_id(br); ... ... if (changed_addr) call_netdevice_notifiers(NETDEV_CHANGEADDR, br->dev);
设置设备状态,MTU
如果网桥端口设备是UP的,就使能它,设置状态等(如果STP没打开就没有这些步骤了)。
- 状态设置为Blocking,
- 认为自己是Designated Port(暂时)
- 对所有端口重新进行端口角色选择
- 创建端口ID 这些通过br_stp_enable_port完成,
if (netif_running(dev) && netif_oper_up(dev) && (br->dev->flags & IFF_UP)) br_stp_enable_port(p);
接下来为新的端口设置MTU,将它设置为整个Bridge设备各个端口的最小MTU;将新端口的MAC地址记录到bridge的FDB中(per VLAN)。通过函数br_fdb_insert插入的fdb表项的is_local和is_static都是1(本地端口嘛)。
dev_set_mtu(br->dev, br_min_mtu(br)); kobject_uevent(&p->kobj, KOBJ_ADD); return 0; ... 出错处理,各种rollback ... }
br_del_if基本上是br_add_if的逆过程,就不再细说了。注意一下一个端口从Bridge移走的话Bridge的ID也需要重新计算。
5.4 打开关闭网桥
现在已经知道创建、删除网桥设备以及添加、删除网桥端口时内核都发生了什么。接下来再看看打开关闭网桥设备(例如ifconfig xxx up或ip link set up)时都有哪些动作发生。网桥设备也是网络设备,也有dev->ndo_open/close,所以不管是ioctl(brctl)还是netlink(ip),最终被调用的是之前在
br_netdev_ops里面所注册的br_dev_open和br_dev_close。其实Bridge的net_device_ops很多函数都已经看过了。
static const struct net_device_ops br_netdev_ops = { .ndo_open = br_dev_open, // 本节讲这个 .ndo_stop = br_dev_stop, // 本节讲这个 .ndo_init = br_dev_init, // 本节讲这个 .ndo_start_xmit = br_dev_xmit, // 数据传输 .ndo_get_stats64 = br_get_stats64, // 统计,好理解 .ndo_set_mac_address = br_set_mac_address,// 这个好理解 .ndo_set_rx_mode = br_dev_set_multicast_list, .ndo_change_mtu = br_change_mtu, .ndo_do_ioctl = br_dev_ioctl, // 已经提过了 ... netpoll 相关... .ndo_add_slave = br_add_slave, // 已经提过了 .ndo_del_slave = br_del_slave, // 已经提过了 .ndo_fix_features = br_fix_features, // 已经提过了,见br_add_if .ndo_fdb_add = br_fdb_add, .ndo_fdb_del = br_fdb_delete, .ndo_fdb_dump = br_fdb_dump, .ndo_bridge_getlink = br_getlink, .ndo_bridge_setlink = br_setlink, .ndo_bridge_dellink = br_dellink, };
br_dev_open自然是用户“up”了这个设备后被调用的。netdev_update_features之前遇到过。netif_start_queue打开输出队列,这个和普通设备没有区别(具体参考《UNLI》)。然后是Multicast和STP部分,这就不细说了。br_dev_close是br_dev_open的反过程。
static int br_dev_open(struct net_device *dev) { struct net_bridge *br = netdev_priv(dev); netdev_update_features(dev); netif_start_queue(dev); br_stp_enable_bridge(br); br_multicast_open(br); return 0; }
6. 网桥数据转发
6.1 网桥数据包入口
网桥是一种2层网络互连设备,而不是一种网络协议。它在协议结构上并没有占有一席之地,因此不能通过向协议栈注册协议的方式来申请网桥数据包的处理。相 反,网桥接口(如上述的eth1)的数据包和一般接口(如eth0)在格式上完全是一样的,不同之处是网桥在2层上就对它进行了转了,而一
般接口要在3层 才能根据路由信息来决定是否要转发,如何转发。那么一个网络接口,在驱动处理完数据包后,怎么才知道该接口分配在一个网桥里面呢?其实很简单,当 brctl工具通过ioctl系统调用时,kernel为该添加的设备生成一个bridge_port结构并放到port_list链中,同时将该 bridge_port的值赋
予设备net_device的br_port指针。因此,要识别接口是否属于某个网桥,只需判断net_device的 br_port指针是否不为空即可。
现假设PC1向PC2发送其个数据包,数据首先会由eth1网卡接收,此后网卡向CPU发送接收中断。当CPU执行当前指令后(如果开中断的话),马上跳 到网卡的驱动程去。Eth1的网卡驱动首先生成一个skb结构,然后对以太网层进行分析,最后驱动将该skb结构放到当前CPU的输入队列中,唤醒软中
断。如果没有其它中断的到来,那么软中断将调用netif_receive_skb函数。代码和分析如下所述:
int netif_receive_skb(struct sk_buff *skb) { //当网络设备收到网络数据包时,最终会在软件中断环境里调用此函数 //检查该数据包是否有packet socket来接收该包,如果有则往该socket //拷贝一份,由deliver_skb来完成。 list_for_each_entry_rcu(ptype, &ptype_all, list) { if (!ptype->dev || ptype->dev == skb->dev) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } // 先试着将该数据包让网桥函数来处理,如果该数据包的入口接口确实是网桥接口, // 则按网桥方式来处理,并且handle_bridge返回NULL,表示网桥已处理了。 // 如果不是网桥接口的数据包,则不应该让网桥来处理,handle_bridge返回skb, // 后面代码会让协议栈来处理上层协议。 skb = handle_bridge(skb, &pt_prev, &ret, orig_dev); if (!skb) goto out; skb = handle_macvlan(skb, &pt_prev, &ret, orig_dev); if (!skb) goto out; //对该数据包转达到它L3协议的处理函数 type = skb->protocol; list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&15], list) { if (ptype->type == type && (!ptype->dev || ptype->dev == skb->dev)) { if (pt_prev) ret = deliver_skb(skb, pt_prev, orig_dev); pt_prev = ptype; } } }
6.2 网桥处理逻辑
static inline struct sk_buff *handle_bridge(struct sk_buff *skb, struct packet_type **pt_prev, int *ret, struct net_device *orig_dev) { struct net_bridge_port *port; //如果该数据包产生于本机,而目标同时为本机。 if (skb->pkt_type == PACKET_LOOPBACK || //如果该数据包的输入接口不是网桥接口 (port = rcu_dereference(skb->dev->br_port)) == NULL) // 以上两种情况都需要让上层协议进行处理 return skb; if (*pt_prev) { *ret = deliver_skb(skb, *pt_prev, orig_dev); *pt_prev = NULL; } //数据包的入口接口是网桥接口。下面将按网桥逻辑进行处理。 //如假包换,数据包转达到真正的网桥处理函数 //br_handle_frame_hook在网桥模块的init函数被初始化为 //br_handle_frame return br_handle_frame_hook(port, skb); }
这里回调了br_handle_frame_hook()函数,这个是一个钩子函数。Br_handle_frame_hook()函数在Linux2.6.34\net\bridge\Br_input.c中,br_handle_frame_hook=br_handle_frame,所以实际函数为br_handle_frame.
6.3 br_handle_frame
好,现在我们看看bridge端口的处理函数 br_handle_frame如何处理skb和指示后续操作。该函数位于br_input.c中。
if (!is_valid_ether_addr(eth_hdr(skb)->h_source)) goto drop;
网桥端口不打算处理回环数据;源地址必须为合法Ethernet地址:源MAC地址不能是全0,不能是MAC广播和多播,是的话就丢弃。
skb = skb_share_check(skb, GFP_ATOMIC); if (!skb) return RX_HANDLER_CONSUMED;
如果skb是共享的,考虑的网桥端口会修改skb,将它clone一份。
接下来数据被分为两类:目的地址是Link Local MAC层多播的数据包括了STP的BPDU,和普通数据。
STP帧(BPDU)和其他保留多播帧
首先是Link Local MAC多播的处理。802.1D有组保留的 Link Local 多播MAC地址,他们用于控制协议,如STP。如果接收到了STP但网桥没有开STP协议,就视为普通数据处理;换句话说,就是本网桥当作自己是不认识STP的网桥,例如Hub或不支持STP的Switch。这时需要Flood STP报文到其他端
口,而保证那些支持STP网桥则看不到不支持STP设备的存在。对于其他Kernel不支持的管理帧处理方式类似。
最后能够在此函数直接递交到Local Host的只能STP功能打开情况下收到的STP帧。递交的时候经过Netfilter的NF_BR_LOCAL_IN的 HOOK点,然后是br_handle_local_finish。br_handle_local_finish的处理实际上不如说是“不处理”,它只是在端口处于Learning的情况下学习个skb的源MAC,并且
总是返回0指示包 RX_HANDLER_PASS,由netif_receive_skb继续根据ptype_base处理(STP报文)。
所有这段代码对于STP的处理也只是学了个源MAC,然后继续有netif_receive_sbk处理。并没有处理STP帧(BPDU).
if (unlikely(is_link_local_ether_addr(dest))) { // MAC Link Local地址通常是管理帧 ... ... switch (dest[5]) { case 0x00: /* Bridge Group Address */// 看看STP要怎么弄法,如果真要处理的话不是在这,而是稍后的protocol dipatching(ptype_base)的地方 /* If STP is turned off, then must forward to keep loop detection */ if (p->br->stp_enabled == BR_NO_STP) goto forward;// 没开STP,那STP帧就和普通数据帧一样处理 break; case 0x01: /* IEEE MAC (Pause) */ goto drop; // MAC Control帧不能通过网桥 default:// 其他的保留MAC多播和普通数据帧一样处理 /* Allow selective forwarding for most other protocols */ if (p->br->group_fwd_mask & (1u << dest[5])) goto forward; } //如果能到达这,只有一种情况:STP功能打开的情况下,收到了STP帧 /* Deliver packet to local host only */ if (NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN, skb, skb->dev, NULL, br_handle_local_finish)) { // br_hanle_local_finishq其实只是在Learning状态下学习MAC并返回0 return RX_HANDLER_CONSUMED; /* consumed by filter */ } else { // 通常,NF_HOOK(br_handle_local_finish)返回0,于是STB BPDU到此处“pass”,最后由netif_receive_skb根据ptype_base分发到STP协议层。 *pskb = skb; return RX_HANDLER_PASS; /* continue processing */ } }
记住,这个函数不会进行STP BPDU的处理!
普通数据帧
走到这里的帧要么是普通数据帧,要么是被视为普通数据的控制帧。它们的处理都是一样的,就是当作普通数据处理。 普通数据帧(非STP帧BPDU), 没有打开STP功能情况下的STP帧,那么就和普通帧一样处理 要么就是其他的保留多播(非MAC Control),那么就和普通帧一样处理
如果目的MAC和网桥设备(而不是网桥端口)的MAC相同,标记为
PACKET_HOST skb->pkt_type = PACKET_HOST;
br_handle_frame分析完了,我们留下两个问题, STP为什么在该函数中没有被处理,并且还去向了ptype_base的流程。 br_handle_frame_finish是做什么的 第一个问题其实好理解,STP作为一种特殊类型的Ethernet packet type,注册了自己的packet_type{}。在br_handler_frame的STP处理只是
分流一下不该处理的情况(netif_receive_skb的流程做不到这种分流)。正经的STP处理的方法是在稍后查询ptype_base,找到相应的处理函数。
// net/llc/llc_core.c static struct packet_type llc_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_802_2), .func = llc_rcv, };
反观普通数据流量,普通NIC收到这些数据时应递交到协议栈,即查询ptype_base然后递交。但设备一旦作为网桥端口,就不能这么处理了,可能需要转发的其他端口什么的,所以才要走br_handler_frame及后续函数。我们看看第二个问题,br_handle_frame_finish接下来是怎么处理普通数据流量
(或当作普通数据处理的保留多播流量)的 。
6.4 数据帧处理:br_handle_frame_finish
接着br_handle_frame讨论数据帧的处理,这里的数据帧代表非(STP等)控制帧,当然也包括“视为数据帧”的控制帧(例如STP功能关闭的情况下,BPDU就视为普通数据帧处理)。后面就不再罗嗦了,统一称为“数据帧”或“数据流量”。
如果数据来自 br_handle_frame,那么 br_handle_frame_finish被调用的时候端口只能处于两种状态:Learning和Frowarding。STP端口如果处于Learning和Forwarding状态,就需要学习新的源MAC(更新FDB)
br_fdb_update(br, p, eth_hdr(skb)->h_source);
如果端口是Learning就说明不是Forwarding,学个MAC就行了,不能继续接收数据。
if (p->state == BR_STATE_LEARNING) goto drop;
接下来是链路层广播、多播和单播的处理,这段代码出现两个skb指针:skb2和原来的skb。理解这段代码,只需要时刻明白,skb2代表递交本地host, skb代表需要转发。抓住这个关键即可。
// skb2指针表明,有数据要发往本机的网络接口,即p->br->dev接口。 58 skb2 = NULL; 59 60 // 如果应用程序要dump本机接口的数据,那么该数据包应往主机发一份, 61 // 一个明显的例子就是在用户在运行tcpdump –I br0或类似的程序。 62 if (br->dev->flags & IFF_PROMISC) 63 skb2 = skb; 64 65 dst = NULL; 66 67 if (is_multicast_ether_addr(dest)) { 68 //如果该报文是一个L2多播报文(如arp请求),那么它应该转发到 69 //该网桥的所有接口。 70 //这同样是网桥的一个特点,广播和组播报文要转发到它的所有接口。 71 br->dev->stats.multicast++; 72 skb2 = skb; 73 } else if ((dst = __br_fdb_get(br, dest)) && dst->is_local) { 74 //__br_fdb_get函数先查MAC-端口映射表,这一步是网桥的关键。 75 // 这个报文应从哪个接口转发出去就看它了。 76 //如果这个报文应发往本机,那么skb置空。不需要再转发了, 77 skb2 = skb; 78 /* Do not forward the packet since it's local. */ 79 skb = NULL; 80 }
决定完是不是要转发,是不是要递交到Host,就可以正在的干活了。如果需要转发(skb不为NULL),又在FBI中找到了目的端口,就转发到改端口。否则就flooding。如果需要递交,就调用br_pass_frame_up。
if (skb) { if (dst) { dst->used = jiffies; br_forward(dst->dst, skb, skb2);// 数据转发到FDB查询到的端口 } else br_flood_forward(br, skb, skb2, unicast);// 数据Flood到所有端口 } if (skb2) return br_pass_frame_up(skb2);// 数据递交到本地Host ... ...
顺便提一下,目前为止skb->dev还么有改变,因为不能确定要交换的skb->dev是哪个,如果是本地递交,就会被替换成网桥设备,如果是转发或者flooding则需要换成对应端口设备,而且skb可能还需要再clone。
6.5 本地递交:br_pass_frame_up
进入br_pass_frame_up的skb是打算经由Bridge设备,输入到本地Host的。数据包从网桥端口设备进入,经过网桥设备,然后再进入协议栈,其实是“两次经过net_device”,一次是端口设备,另一次是网桥设备。现在数据包离开网桥端口进入网桥设备,需要修改skb->dev字段。
indev = skb->dev;
skb->dev = brdev;
skb->dev 起初是网桥端口设备,现在离开网桥端口进入网桥的时候,被替换为网桥设备的net_device。如果设备是TX,或者从一个端口转发的另一个skb->dev也会相应改变。不论数据的流向如何,skb->dev总是指向目前所在的net_device{}。
递交的最后一步是经过NF_BR_LOCAL_IN钩子点,然后是我们熟悉的netif_receive_skb,只不过这次进入该函数的时候skb->dev已经被换成了Bridge设备。这可以理解为进入了Bridge设备的处理。
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_LOCAL_IN, skb, indev, NULL, netif_receive_skb);
Bridge Local In的数据被修改skb->dev后再次进入netif_receive_skb,原来那个netif_receive_skb因为rx_handler返回CONSUMED而结束。
6.6 数据转发到端口:br_forward
我们再看看 br_handle_frame_finish的另一个支流,转发支流,首先是转发到单个端口的情况,出现这种精确的转发,意味着FDB里面有目的MAC对应的条目,找到了目的端口。直接转发的某个端口通过函数br_forward。
转发前需要做几个检查,必须同时满足以下条件:
a.不能转发给自己 (ingress/egress端口 不能相同)除非目的端口设置了HAIRPIN模式。
b.如果出口端口的状态不是Forwarding,则不能转发出去。如果一个网桥没有启用STP功能,并且网络接口的状态为UP,那么它网桥端口的状态为Forwarding。如果启用STP,每个端口都有一个严格的状态,规定那些端口在什么情况下才能成为Forwarding状态,否则容易造成环路,产生网络风暴。
以上检查由should_deliver()完成。
接着调用函数_br_forward(),_br_forward函数也没干什么,就是调用了br_forward_finish()函数。Br_forward_finish()函数调用了br_dev_queue_push_xmit()函数。
34 int br_dev_queue_push_xmit(struct sk_buff *skb) 35 { 36 /* drop mtu oversized packets except gso */ 37 if (packet_length(skb) > skb->dev->mtu && !skb_is_gso(skb)) 38 kfree_skb(skb); 39 else { 40 /* ip_refrag calls ip_fragment, doesn't copy the MAC header. */ 41 if (nf_bridge_maybe_copy_header(skb)) 42 kfree_skb(skb); 43 else { 44 skb_push(skb, ETH_HLEN); 45 46 dev_queue_xmit(skb); 47 } 48 } 49 50 return 0; 51 }
该函数主要完成如下工作:
1.做些必要的检查工作。例如,报文的长度比出口端口的MTU还大,则丢掉该报文。
2. 网桥在处理数据包里,只需拆包来获得目标MAC地址,而不需要 更改数据包的任何内容。但在入口网卡的驱动中已将以太网头部 剥掉,现在需要将它套上。Skb_push函数实现这一功能。
3. 放到网卡输出队列里,该网卡驱动将它送出去。
6.7 Flooding到各个端口:br_flood_forwards
br_flood_forwards只是函数br_flood的包裹函数。br_flood()遍历每个网桥端口,如果可以的话(满足刚刚说过的should_deliver的要求),就用__packet_hook( __br_forward())转发之。不过函数实现的时候用了一个小技巧,判断为能不能转发后先不急着转发,而是看看下一个端口,如果
下一个端口也需要转发,才把数据转发到上次那个要转发到端口。这么做的原因也是减少一次clone。如果没有后续可以转发的端口,就不需要clone了。
111 struct net_bridge_port *p; 112 struct net_bridge_port *prev; 113 114 prev = NULL; 115 116 list_for_each_entry_rcu(p, &br->port_list, list) { 117 if (should_deliver(p, skb)) { 118 if (prev != NULL) { 119 struct sk_buff *skb2; 120 121 if ((skb2 = skb_clone(skb, GFP_ATOMIC)) == NULL) { 122 br->dev->stats.tx_dropped++; 123 kfree_skb(skb); 124 return; 125 } 126 127 __packet_hook(prev, skb2); 128 } 129 130 prev = p; 131 } 132 } 133 134 if (prev != NULL) { 135 __packet_hook(prev, skb); 136 return; 137 }
此外br_flood也会使用__br_forward最终转发数据帧,和br_forward一样。
6.8 网桥数据流小节
两次经过net_device{}小节
再谈谈skb经过两次net_device{}这事。 输入路径经过两次net_device{}分别是网桥端口的和网桥设备的,也就是两次调用netif_receive_skb。 和输入路径一样,输出的帧同样会经过两次net_device,即先网桥设备后网桥端口,对输出而言的函数是两次调用dev_queue_xmit; 如果将这个概
念扩展,其实对于转发(forward)的数据帧也是两次经过net_device,两次都是网桥端口的net_device{},函数的话,一次是netif_receive_skb,一次是dev_queue_xmit)。
7. 转发数据库
转发数据库用于记录MAC地址端口映射。网桥通过地址学习,将学习到的MAC地址和相应端口加入该数据库;网桥端口本身的MAC会被永久的加入到FDB中(br_add_if());用户还可以配置静态的映射。FDB和是否打开STP无关,只不过打开STP后,只有Learning/Forwardnig才会学习。
记录下的MAC地址(数据库条目)会被更新,并且有老化时间(默认是300秒,也就是5min),如果使用旧STP算法,拓扑变化的时候该老化时间被设置成15秒,如果使用RSTP,FDB中,某端口相关所有条目会被清除。虽然之前已经介绍过net_device_fdb_entry{},我们还是罗列一下.
struct net_bridge_fdb_entry {
struct hlist_node hlist; // FDB的各个Entry使用哈希表组织,这个是bucket冲突元素链表节点 ;
struct net_bridge_port *dst; // 条目对应的网桥端口(没有直接使用端口ID);
struct rcu_head rcu; unsigned long updated; // 最后一次更新的时间,会与Bridge的老化定时器比较。 unsigned long used; mac_addr addr; // 条目对应的MAC地址 unsigned char is_local; // 是否是本地端口的MAC unsigned char is_static; // 是否是静态配置的MAC __u16
这里重申一下FDB是网桥的属性,因此保存在net_bridge{}中,保存的方式是一个Hash表。
struct net_bridge { ... ... struct hlist_head hash[BR_HASH_SIZE]; ... ... };
FDB条目的添加、删除,查询,更新操作本身想必不会太复杂,无非是哈希表链表操作。关键是搞弄清楚FDB访问和修改的场景。
7.1 FDB初始化,查找
FDB的初始化非常简单,为net_bridge_fdb_entry{}结构初始化一个cache以便快速分配条目。另外还以随机值生成一个salt,这个salt在hash的时候使用,引入随机值可以分散各个Hash键,并且防止DoS攻击。
33 int __init br_fdb_init(void) 34 { 35 br_fdb_cache = kmem_cache_create("bridge_fdb_cache", 36 sizeof(struct net_bridge_fdb_entry), 37 0, 38 SLAB_HWCACHE_ALIGN, NULL); 39 if (!br_fdb_cache) 40 return -ENOMEM; 41 42 get_random_bytes(&fdb_salt, sizeof(fdb_salt)); 43 return 0; 44 }
7.2 地址老化
我们知道网桥学到地址都有一个老化的过程。网桥维护了几个超期时间值,包括老化时间br->ageing_time,默认300秒;和转发延迟br->foward_delay,默认15秒。FDB中的每个地址如果自上次跟新(记录于net_bridge_fdb_entry->updated)以来,流逝的时间超过了“保持时间”(由
hold_time(),返回可能是老化时间或者短老化时间),地址就需要被删除。hold_time()在正常情况下返回老化时间br->ageing_time,但是如果检测到了拓扑变化,这将老化时间缩短为br->forward_delay,后者也称为“短老化定时器(short aging timer)”。
7.2.1 注册、打开垃圾收集定时器
网桥在什么时候检查FDB中的各个地址是否老化、并将老化的地址从FDB中移除呢?Kernel将这个工作交由“垃圾收集定时器”来完成。gc_timer保存在net_bridge{}中。
struct net_bridge { ... ... struct timer_list gc_timer; ... ... };
网桥设备被创建并初始化的时候,具体说来是br_dev_setup的时候,通过br_stp_timer_init初始化STP相关的几个定时器,其中包括了垃圾收集定时器。
br_add_bridge + |- alloc_netdev + |- br_dev_setup + |- br_stp_timer_init + |- ... HELLO Timer ... |- ... TCN Timer ... |- ... Topology Change Timer ... - setup_timer(&br->gc_timer, br_fdb_cleanup, (unsigned long) br);
setup_timer函数将timer->function和timer->data设置为:br_fdb_cleanup和net_bridge{}。要注意的是,不论STP协议是否运行,地址老化(垃圾收集)都是必要的。这里只是设置各个timer的回调函数和私有数据。并没有启动Timer。
在网桥设备打开的时候,br_stp_enable_bridge会把各个timer打开,包括gc_timer,
br_dev_open + |- br_stp_enable_bridge + |- ... |- mod_timer(&br->gc_timer, jiffies + HZ/10); // gc_timer第一次启动的地方 |- ...
第一次打开的时候,在1/10秒后br_fdb_cleanup被调用;此后回调函数br_fdb_cleanup将timer自己设置为每br->aging_time或者“最近的一个条目到期时间”调用。这个timer的实现是值得学习的,因为它不是完全周期性的timer,而是根据条目中需要检查的时间结合一个最大默认周期来进行。
7.2.2 地址老化处理
我们看看br_fdb_cleanup()是怎么实现的,顺便也提一下hold_time()。
void br_fdb_cleanup(unsigned long _data) { struct net_bridge *br = (struct net_bridge *)_data; unsigned long delay = hold_time(br);// 地址老化时间,MIN {ageing_time, forward_delay} unsigned long next_timer = jiffies + br->ageing_time;// 预设下次收集时间为 ageing_time秒后,稍后
可能调整 int i;
spin_lock(&br->hash_lock); for (i = 0; i < BR_HASH_SIZE; i++) {// 遍历所有FDB Hash Bucket struct net_bridge_fdb_entry *f; struct hlist_node *n; hlist_for_each_entry_safe(f, n, &br->hash[i], hlist) { // 遍历所有FDB Hash冲突链表 unsigned long this_timer; if (f->is_static)// 静态条目,包括端口地址和用户设置的条目,不会老化、删除。 continue; this_timer = f->updated + delay;// 条目老化到期的时间 if (time_before_eq(this_timer, jiffies))// 已经到期(到期时间在当前时间之前),就把它删除 fdb_delete(br, f); // 这就是清除到期FDB Entry的地方 else if (time_before(this_timer, next_timer)) next_timer = this_timer;// 如果FDB中的某个条目中默认的下次检查时间之前,就将下次收集时间提前 } } spin_unlock(&br->hash_lock); mod_timer(&br->gc_timer, round_jiffies_up(next_timer));// 设置下次垃圾收集的时间
7.3 “本地”FDB条目
网桥设备、网桥端口设备的MAC地址作为“Local”条目添加到FDB表,其is_local和is_static都需要置1,不会老化。这类FDB Entry通过fdb_insert添加,并且在地址改变的时候,需要做相应的更新。
从下图我们发现,并没有添加“网桥设备”MAC FDB的地方,这是因为网桥的MAC因默认情况下是其端口之一的地址,因此无需加入FDB。但是如果网桥端口地址改变时则需要更新。
对于网桥的地址加入,或者不加入FDB对于入口流量的影响,我们应该了解到, 只要帧的目的MAC是网桥或者各个网桥端口的MAC之一,帧就是要被递交到本地Host的。
了解了何时“插入”本地且静态的网桥端口、网桥的地址后,我们看看fdb_insert的实现,
static int fdb_insert(struct net_bridge *br, struct net_bridge_port *source, const unsigned char *addr, u16 vid) { struct hlist_head *head = &br->hash[br_mac_hash(addr, vid)];// FDB是Per-VLAN的,addr和vid都作为Hash键 struct net_bridge_fdb_entry *fdb;
if (!is_valid_ether_addr(addr))// 要插入的地址必须是合法的Ethernet地址 return -EINVAL; fdb = fdb_find(head, addr, vid);// 在某个VLAN中,地址是否已经存在 if (fdb) { // 地址已经存在? /* it is okay to have multiple ports with same * address, just use the first one. */ if (fdb->is_local) // 并且是Local的 return 0; // 允许多个端口用于同一个地址 br_warn(br, "adding interface %s with same address " "as a received packet\n", source ? source->dev->name : br->dev->name); fdb_delete(br, fdb);// 但如果地址和分本地地址冲突,就需要将非本地地址的条目删除 } fdb = fdb_create(head, source, addr, vid);// 创建新的net_bridge_fdb_entry{},并插入FDB(br->hash)中 if (!fdb) return -ENOMEM; fdb->is_local = fdb->is_static = 1;// “插入”的地址一定是本地且静态的 fdb_notify(br, fdb, RTM_NEWNEIGH); return 0;
7.4 地址学习
除了网桥端口和网桥的MAC地址,用户还能手动添加静态(通过netlink套接字),已经网桥字段学习地址的过程,
fdb_create的实现也不难理解,
static struct net_bridge_fdb_entry *fdb_create(struct hlist_head *head, struct net_bridge_port *source, const unsigned char *addr,
__u16 vid)
{ struct net_bridge_fdb_entry *fdb;
fdb = kmem_cache_alloc(br_fdb_cache, GFP_ATOMIC); if (fdb) { memcpy(fdb->addr.addr, addr, ETH_ALEN); fdb->dst = source; fdb->vlan_id = vid; fdb->is_local = 0; fdb->is_static = 0; fdb->updated = fdb->used = jiffies; hlist_add_head_rcu(&fdb->hlist, head); } return fdb;
参考资料:
https://github.com/beacer/notes/blob/master/kernel/bridging.md
https://www.ibm.com/developerworks/cn/linux/kernel/l-netbr/
http://tjlxy.lofter.com/post/335f69_10a48df
http://blog.csdn.net/robin_fj/article/details/50082027
http://blog.chinaunix.net/uid-26675482-id-3995078.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号