Python爬虫学习笔记(一)
 初识python爬虫与简单使用。
初识python爬虫与简单使用。
概念:
使用代码模拟用户,批量发送网络请求,批量获取数据。
分类:
通用爬虫:
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。
主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
简单来讲就是尽可能的把互联网上的所有的网页下载下来,放到本地服务器里形成备分,
在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
聚焦爬虫:
聚焦爬虫是根据指定的需求抓取网络上指定的数据。
例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
增量式爬虫:
增量式是用来检测网站数据更新的情况,且可以将网站更新的数据进行爬取。
Robots协议:
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
简单来说,robots决定是否允许爬虫(通用爬虫)抓取某些内容。
注:聚焦爬虫不遵守robots。
eg:

爬取流程:
大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据。
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
Test:
Test1:


import urllib.request
def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response)
load_data()

Test2:
import urllib.request
def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
print(response)
#读取内容 byte类型
data = response.read()
print(data)
load_data()
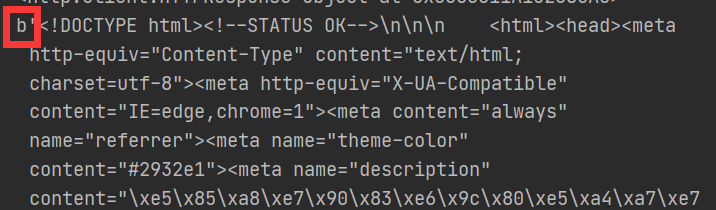
Test3:
import urllib.request
def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
print(str_data)
load_data()
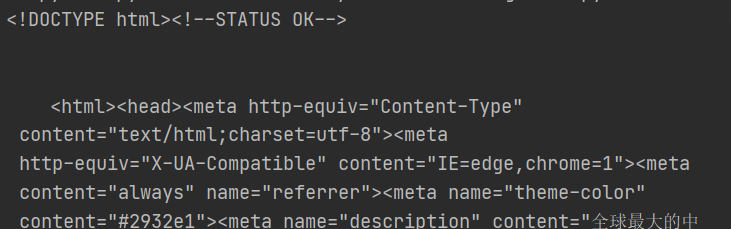
Test4:
import urllib.request
def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
load_data()
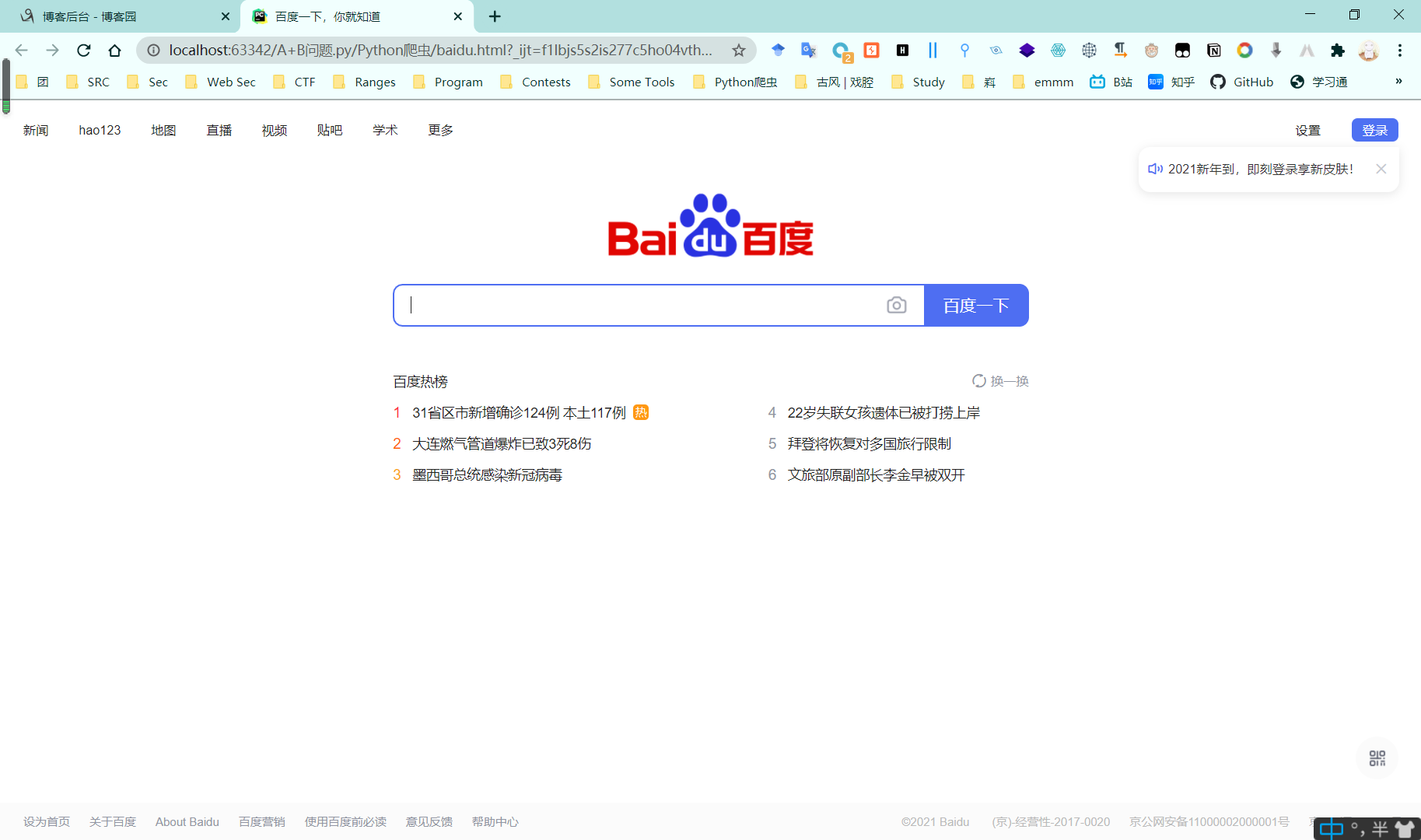
注:
出于安全性,https请求的话将无法打开,而http则可以打开。
Test5:
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name)

注:
python爬取的类型:str,bytes
如果爬取返回的是bytes类型:但写入的时候需要字符串 => decode(“utf-8”);
如果爬取返回的是str类型:但写入的时候需要bytes类型 => encode(“utf-8”).
Test1 ~ Test4代码:
import urllib.request
def load_data():
url = "http://www.baidu.com/"
#GET请求
#http请求
#response:http响应对象
response = urllib.request.urlopen(url)
#print(response)
#读取内容 byte类型
data = response.read()
#print(data)
#将文件获取的内容转换为字符串
str_data = data.decode("UTF-8")
#print(str_data)
#将数据写入文件
with open("baidu.html", "w", encoding="utf-8") as f:
f.write(str_data)
#将字符串类型传唤为bytes
str_name = "baidu"
bytes_name = str_name.encode("utf-8")
print(str_name)
load_data()
Test5:
import urllib.request
import urllib.parse
import string
def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#使用代码发送网络请求
#将包含汉字的网址进行转义
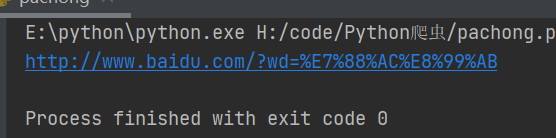
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
#response = urllib.request.urlopen(final_url)
print(encode_new_url)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!!
get_method_params()
import urllib.request
import urllib.parse
import string
def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
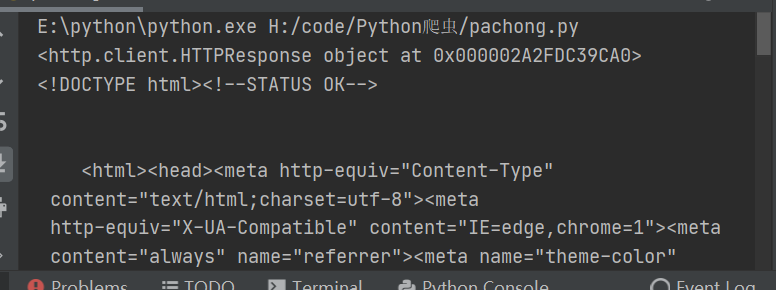
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!!
get_method_params()

import urllib.request
import urllib.parse
import string
def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!!
get_method_params()
import urllib.request
import urllib.parse
import string
def get_method_params():
url = "http://www.baidu.com/?wd="
#拼接字符串(汉字)
name = "爬虫"
final_url = url + name
#print(final_url)
#代码发送了请求
#网址里面包含了汉字;ascii是没有汉字的;URL转义
#将包含汉字的网址进行转义
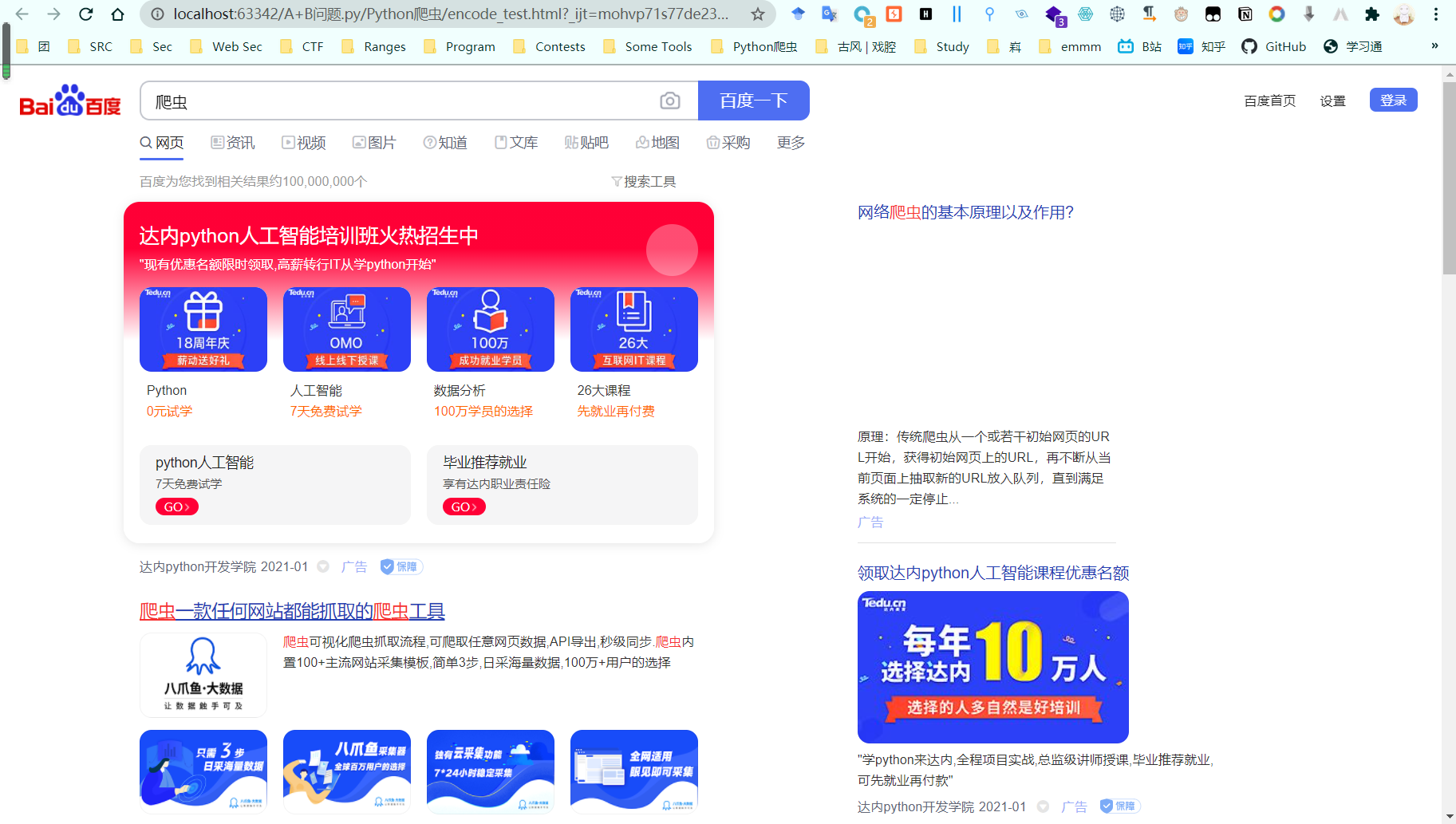
encode_new_url = urllib.parse.quote(final_url, safe=string.printable)
response = urllib.request.urlopen(encode_new_url)
print(response)
#读取内容
data = response.read().decode()
print(data)
#保存到本地
with open("encode_test.html", "w", encoding="utf-8")as f:
f.write(data)
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 15-16: ordinal not in range(128)
#针对报错结合上一条注释的解释:
#python是解释性语言;解释器只支持 ascii 0 - 127,即不支持中文!!!
get_method_params()

参考:
https://www.bilibili.com/video/BV1XZ4y1u7Kv
The Working Class Must Lead!


