

假期python复习2
装饰器后续
获取函数名:
def wahaha():
print('哇哈哈')
print(wahaha.__name__)
获取函数内的注释:
print(wahaha.__doc__)
当使用装饰器后这样获取函数名是装饰器内函数的名字,不是被装饰的函数名
解决办法可在装饰器里面加一个@wraps(函数名)#带参数的装饰器
同时调用wraps库里的functools
也就是form functools import warps
之后利用前面方法可以正常获取函数名和注释
装饰器练习:
#1、编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件)
#要求登入成功一次,后续的函数无需再输入用户名和密码
FLAG = False
def login(func):
def inner(*args,**kwargs):
global FLAG
'''登入程序'''
if FLAG:
ret = func(*args, **kwargs)
return ret
username = input("username :")
password = input('password :')
if username == 'zhouyuhan' and password == '20181235':
FLAG =True
ret = func(*args,**kwargs)
return ret
else :
print('登入失败')
return inner
@login
def shoplist_add():
print('增加一件物品')
@login
def shoplist_del():
print('删除一个物品')
2、编写装饰器,为多个函数加上记录调用功能,要求每次调用函数都将被调用的函数名称写入文件
def log(func):
def inner(*args,**kwargs):
with open('log','a',encoding='utf-8')as f:
f.write(func.__name__+'\n')
ret = func(*args,**kwargs)
return ret
return inner
@log
def fun1():
print('函数1')
@log
def fun2():
print('函数2')
fun1()
fun1()
fun2()
fun1()
3、编写下载页面内容的函数,要求功能是:用户传入一个url,函数返回下载页面的结果:
from urllib.request import urlopen
def get(url):
code = urlopen(url).read
return code
ret = get('https://www.baidu.com')
print(ret)
4、为题目3编写装饰器,实现缓存网页内容的功能:
具体:实现下载的页面存放于文件中,如果文件内有值(文件大小不为0),就优先从文件中读取网页内容,否则,就去下载,然后
from urllib.request import urlopen
import os
def cache(func):
def inner(*args,**kwargs):
if os.path.getsize("webcache"):
with open('webcache', 'rb', )as f:
return f.read()
ret = func(*args,**kwargs)
with open('webcache','wb',)as f:
f.write(ret)
return ret
return inner
@cache
def get(url):
code = urlopen(url).read()
return code
ret = get('http://www.baidu.com')
print(ret)
ret = get('http://www.baidu.com')
print(ret)
ret = get('http://www.baidu.com')
print(ret)
迭代器
维基百科解释道:
在Python中,迭代器是遵循迭代协议的对象。使用iter()从任何序列对象中得到迭代器(如list, tuple, dictionary, set等)。另一种形式的输入迭代器是generator(生成器)。
很多容器诸如列表、字符串可以用for循环遍历对象。for 语句会调用容器对象中的 iter()函数, 该函数返回一个定义了 next() 方法的迭代器对象,该方法将逐一访问容器中的元素。
所以说:python中,任意对象,只要定义了__next__方法,它就是一个迭代器。因此,python中的容器如列表、元组、字典、集合、字符串都可以用于创建迭代器。
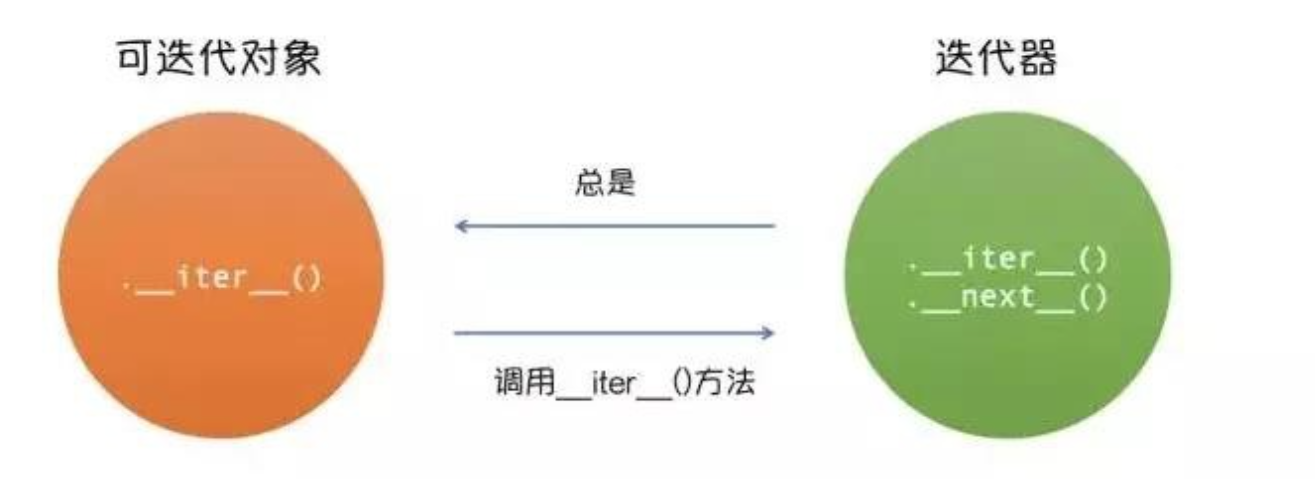
讲完迭代器后,迭代就比较好理解了,迭代就是从迭代器中取元素的过程。
比如我们用for循环从列表[1,2,3]中取元素,这种遍历过程就被称作迭代。
# 列表是迭代器
for element in [1, 2, 3]:
print(element)
# 元组是迭代器
for element in (1, 2, 3):
print(element)
# 字典是迭代器
for key in {'one':1, 'two':2}:
print(key)
# 字符串是迭代器
for char in "123":
print(char)
# 打开的text同样是迭代器
for line in open("myfile.txt"):
print(line, end='')
如果你不想用for循环迭代呢?这时你可以:
-
先调用容器(以字符串为例)的iter()函数
-
再使用 next() 内置函数来调用 next() 方法
-
当元素用尽时,next() 将引发 StopIteration 异常
>>> s = 'abc' >>> it = iter(s) >>> it <iterator object at 0x00A1DB50> >>> next(it) 'a' >>> next(it) 'b' >>> next(it) 'c' >>> next(it) Traceback (most recent call last): File "<stdin>", line 1, in <module> next(it) StopIteration
生成器
生成器的本质还是迭代器
生成器函数
只要含有yield关键字的函数都是生成器函数
yield和return不能共用且需要写在函数内
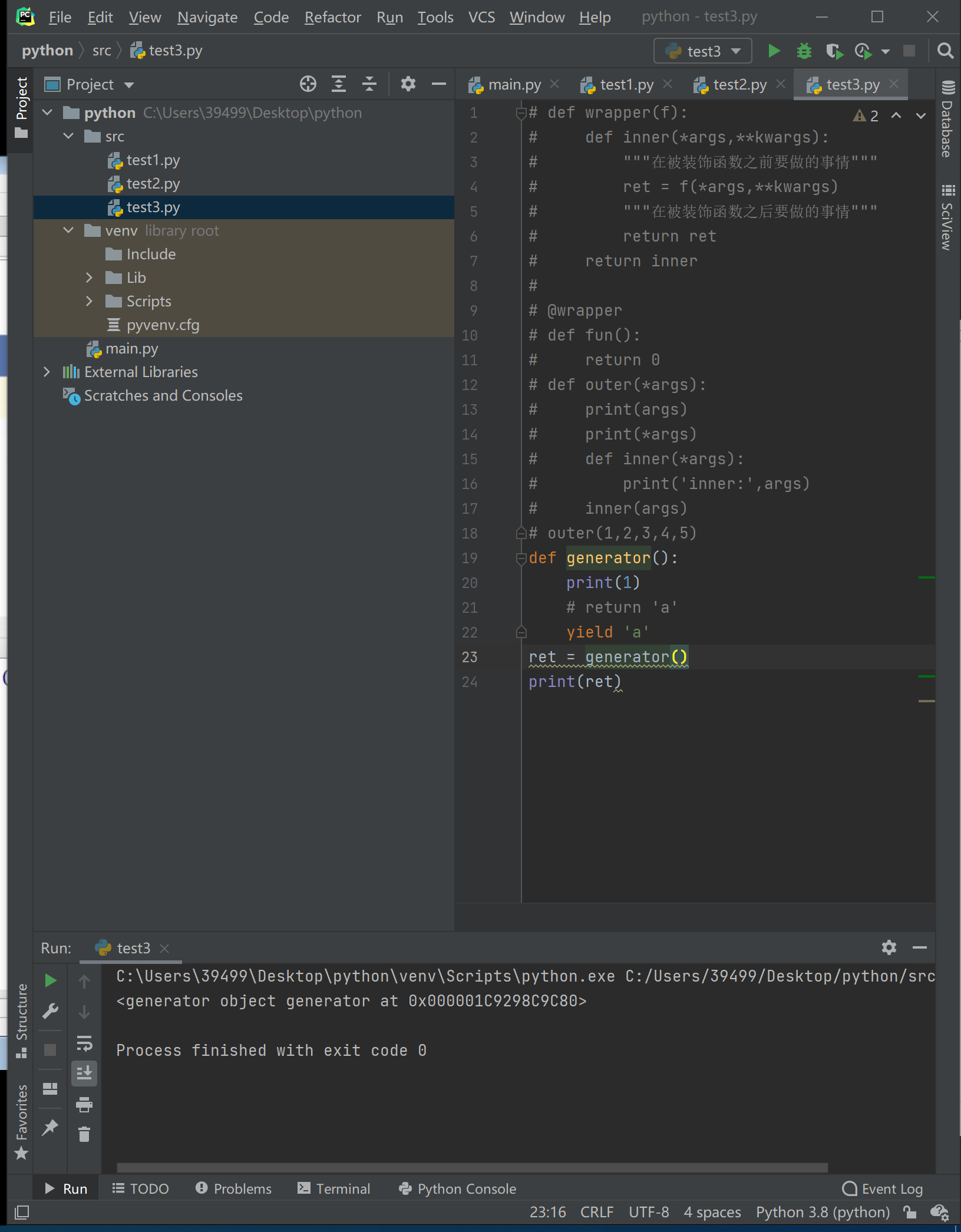
生成器函数执行之后会得到一个生成器作为返回值
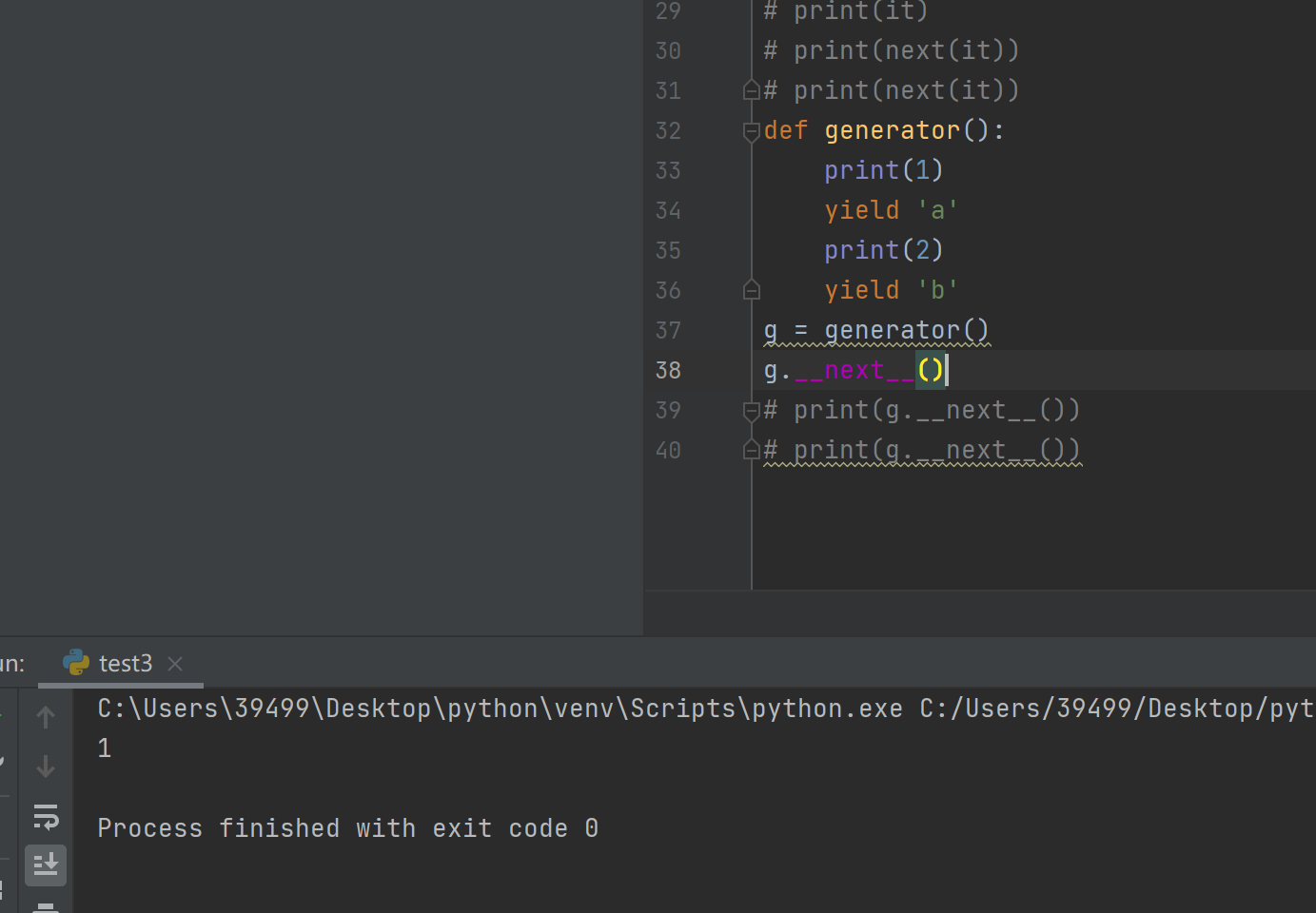
yield和return的区别
return后就结束
yield使用一次__ next __只会执行到第一个yield
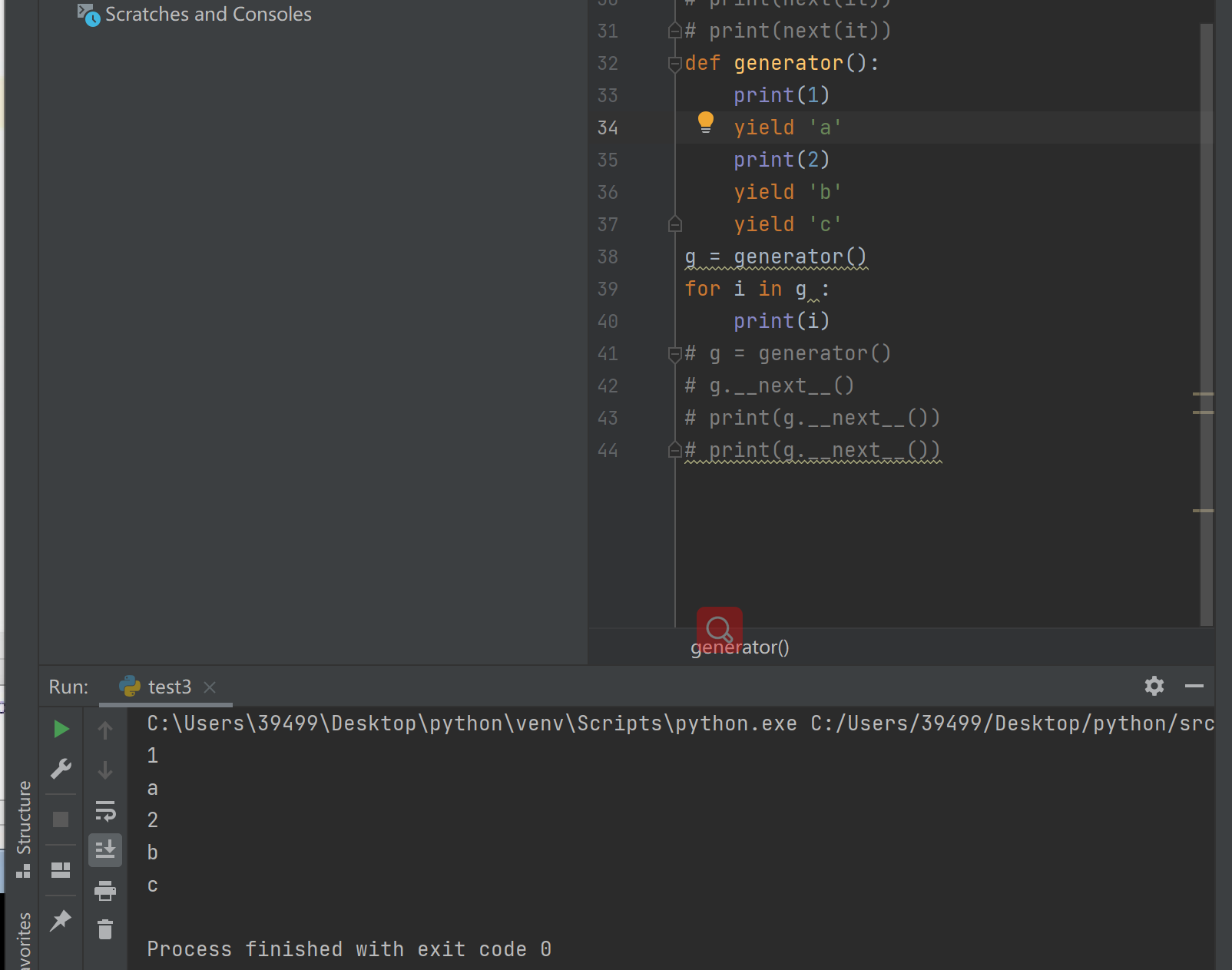
可利用for循环对生成器里的进行迭代和next效果一样
监听文件的输入:
def taill(filename):
f = open('file',encoding='utf-8')
while True:
line = f.readline()
if line.strip():
yield line.strip()
g = taill('file')
for i in g :
if 'python' in i:
print(i)
