win7安装python3.6.1及scrapy
---恢复内容开始---
第一篇博客,记录自己自学python的过程及问题。
首先下载python3.6.1及所需资料
百度云:https://pan.baidu.com/s/1geOEp6z
密码:1fuw
文件列表如下:

先安装 python-3.6.1-amd64.exe。
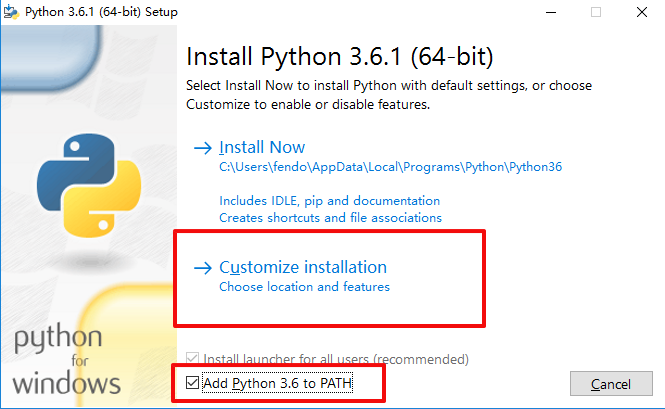
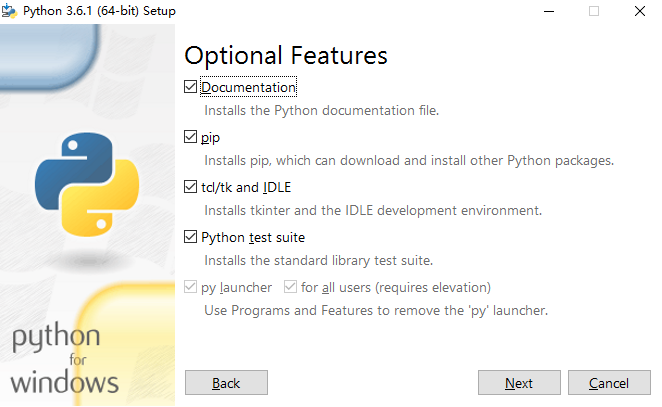
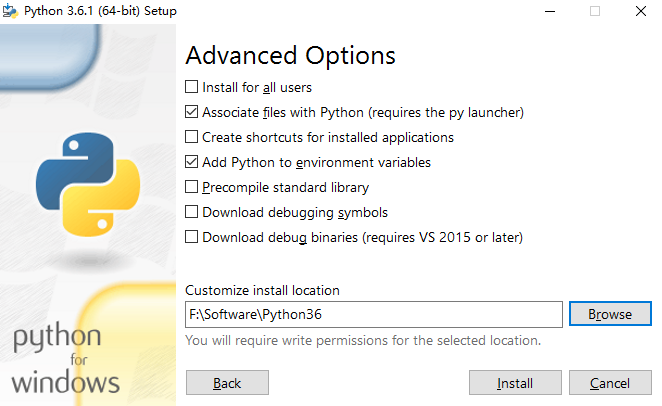
安装完成后进入cmd,输入python
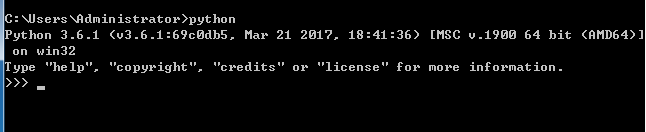
安装成功。
下面安装scrapy依赖插件。
通过命令:pip install xxxx 安装以下文件
安装lxml-3.7.3-cp36-cp36m-win_amd64.whl
安装zope.interface-4.3.3-cp36-cp36m-win_amd64.whl
安装pywin32-221-cp36-cp36m-win_amd64.whl
安装Twisted-17.1.0-cp36-cp36m-win_amd64.whl
通过pip安装OpenSSL: pip install pyOpenSSL
安装之后验证scrapy依赖项是否安装成功的方法:
cmd执行python进入python控制台
● 执行import lxml,如果没报错,则说明lxml安装成功。
● 执行import twisted,如果没报错,则说明twisted安装成功。
● 执行import OpenSSL,如果没报错,则说明OpenSSL安装成功。
● 执行import zope.interface,如果没报错,则说明zope.interface安装成功。
下面安装scrapy
pip install scrapy==1.1.0rc3
安装完成后验证是否安装成功,cmd输入下面命令
scrapy version
返回
Scrapy 1.1.0rc3
安装成功。
然后安装 Microsoft Visual Studio,本人安装的是2015专业版,安装的时候要选上编程环境。
成功后就可以就可以新建我们的爬虫项目测试了。
下面以爬取百度的标题为例:
进入控制台输出 scrapy startproject baidu
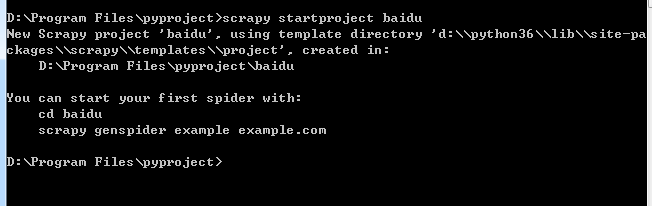
创建一个爬虫文件

使用pyCharm进入项目,修改代码如下
items.py
import scrapy class BaiduItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field()
first.py
import scrapy from baidu.items import BaiduItem class FirstSpider(scrapy.Spider): name = 'first' allowed_domains = ['baidu.com'] start_urls = ['http://www.baidu.com/'] def parse(self, response): item = BaiduItem() item["title"] = response.xpath('/html/head/title/text()').extract() print(item["title"])
settings.py修改下面代码,不遵守robots协议
ROBOTSTXT_OBEY = False
cmd执行下面命令返回 --nolog表示不打印日志

所有环境安装成功。
若是执行的时候报错
TypeError: 'float' object is not iterable
则是因为scrapy版本太低,建议手动下载高版本到本地安装,上面分享的网盘资料有下好的文件。
进入cmd,进入文件保存目录,执行 pip install Scrapy-1.4.0-py2.py3-none-any.whl
返回success 就OK了。
本人初学python,第一次写博客,如果有什么说的不准确的地方欢迎大家一起来讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号