
kube-controller-manager反复重启解决
背景
某环境,kube-controller-manager反复重启,尝试重建kube-controller-manager的pod,但是过一会问题复现。

如上图,kube-controller-manager反复重启了200多次了。
排查
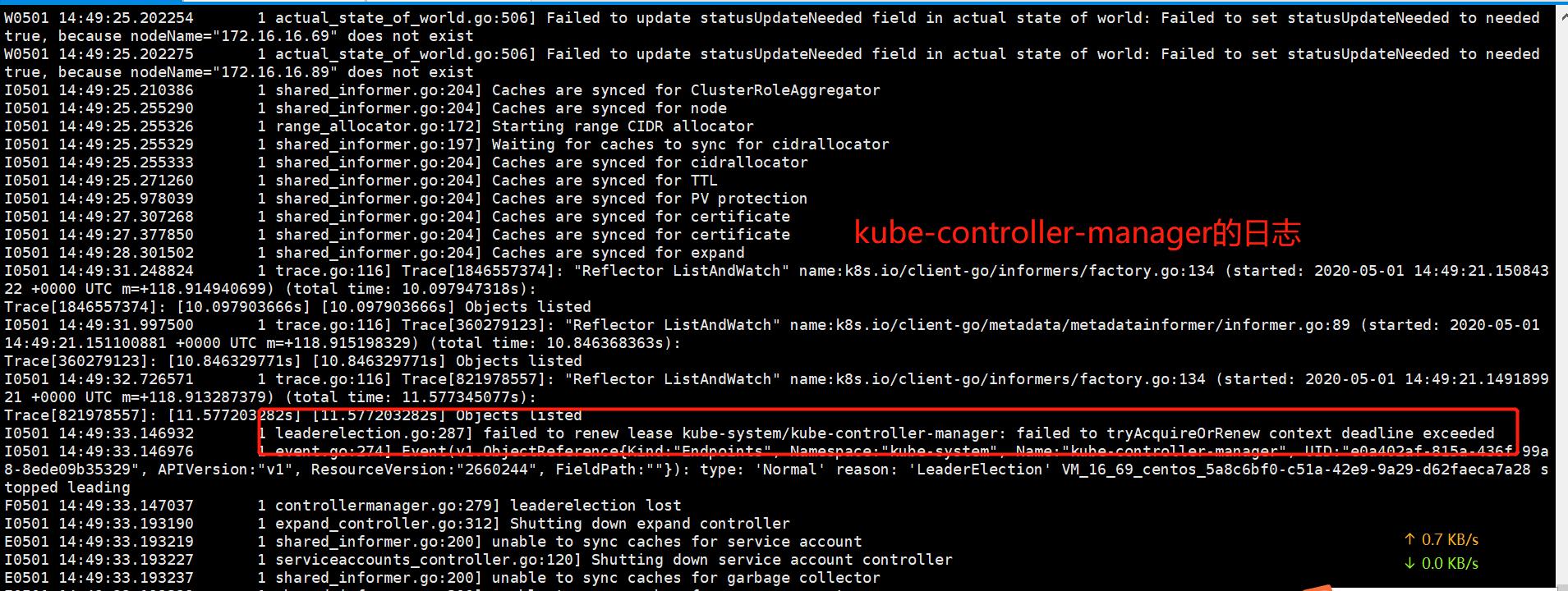
1.通过kubectl logs -n kube-system kube-controller-manager-xxx查看kube-controller-manager日志,日志显示“failed to renew lease kube-system/kube-controller-manager: failed to tryAcquireOrRenew context deadline exceeded”
2.参考一次kube-controller-manager的bug导致的线上无法调度处理过程,通过kubectl get --raw /api/v1/namespaces/kube-system/endpoints/kube-controller-manager | jq .|grep resource对比正常环境和此异常环境的resourceVersion,异常环境确实kube-controller-manager的endpoint,resourceVersion一直维持不变。
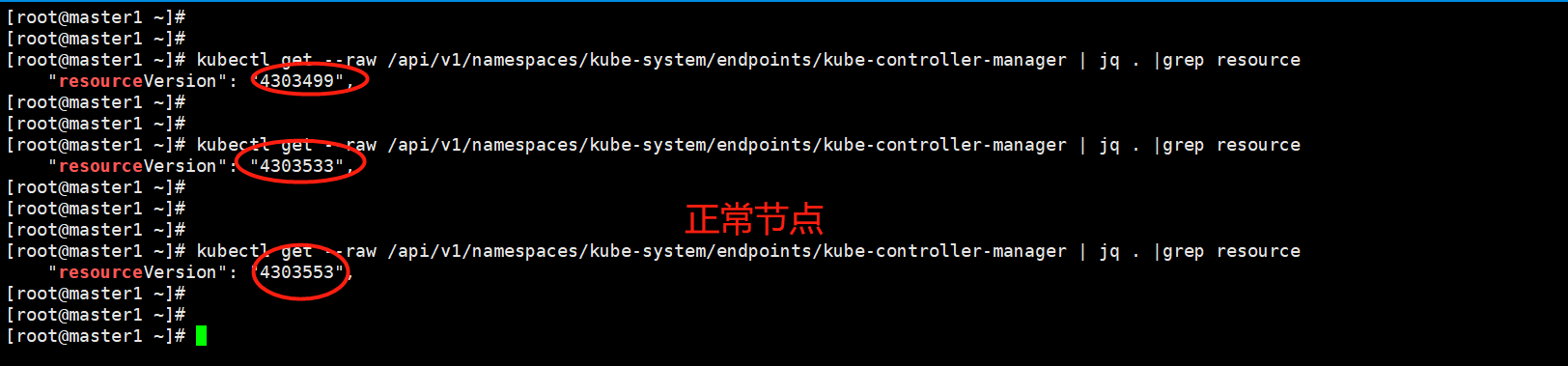

3.通过kubectl delete endpint -n kube-system kube-controller-manager ,删除此endpoint, 发现kube-controller-manager启动成功,同时此endpoint的resourceVersion开始更新,初始以为问题解决,后发现kube-controller-manager反复重启问题依旧,日志报错仍和之前一样。

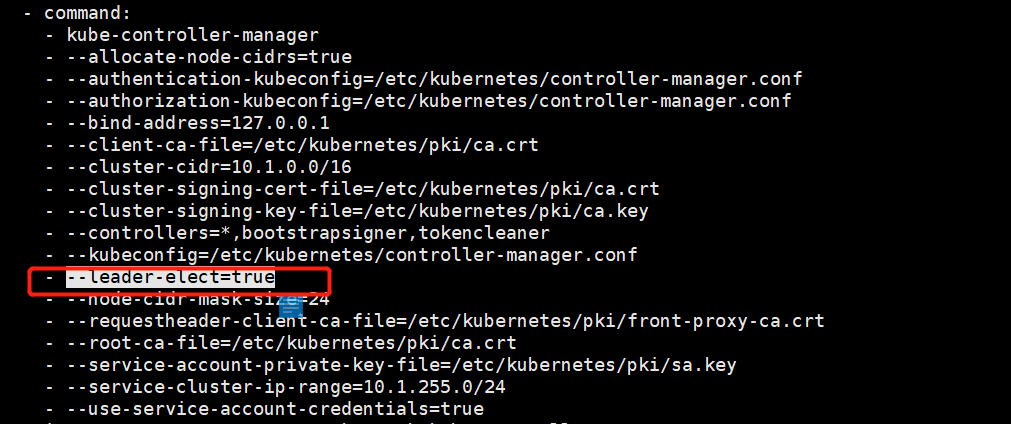
4.分析kube-controller-manager启动参数,leader-elect设置为true,此为高可用场景下多个kube-controller-manager实例竞争选举哪个实例为leader角色的开关,开启时kube-controller-manger实例启动时会连接kube-api竞争创建名为kube-controller-manager的endpoint,创建成功的kube-controller-manger实例为leader,其他实例为backup,同时leader实例需要定期更新此endpoint,维持leader地位。
5.分析kube-controller-manager日志,显示更新此endpoint超时,初始怀疑kube-api异常,检查kube-api日志未发现异常,同时kubectl操作流畅,通过curl调用kube-api 6443端口也正常响应,排除kube-api本身问题。
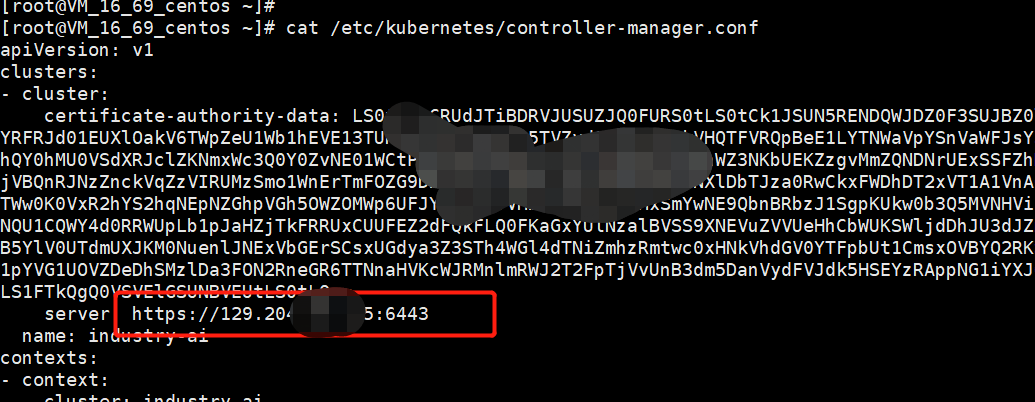
6.综上,排除kube-api问题后,怀疑kube-controller-manager实例连接kube-api的网络异常,检查/etc/kubernetes/controller-manager.conf发现,发现问题所在,环境配置了kube-controller-manager通过公网IP去连接kube-api,环境为公有云环境,有内外网IP,通过自动化部署工具创建集群时指定了公网IP,导致kube-controller-manager和kube-scheduler都是通过kube-api所在节点的公网IP去连接,导致连接不稳定。修改相关地址为内网IP后,问题未复现。
总结
1.“failed to renew lease kube-system/kube-controller-manager: failed to tryAcquireOrRenew context deadline exceeded”问题,一般从kube-api和网络链接入手。
2.此环境为非高可用环境,修改leader-elect为false避免kube-controller-manager定期去连接kube-api更新endpoint,理论也可以避免renew超时退出问题。
3.如果特定场景,kube-controller等组件必须通过公网连接kube-api,如果有相关参数配置连接kube-api超时时间也是一种解决思路,笔者搜索kube-controller-manager启动参数,暂未发现与此有关参数,待代码确认是否写死了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号