
答题判题程序题目集 1~3 的总结性 Blog
- 前言
1.1 题目集概述
答题判题程序 - 1:
字符串解析:题目内容和答题内容都是按照特定格式给出的字符串,程序需要能正确地拆分和解析这些字符串,然后进行匹配。
对象和类的使用:为了更好地管理题目和答题信息,我们可以设计合适的类。每个题目可以作为一个对象,存储它的编号、内容、标准答案,以及对应的答题者答案,方便后续的判题和处理。
逻辑判断:程序需要根据答卷中的答案和标准答案逐一对比,判断答对与否,并输出结果(比如 true/false)。
处理输入顺序和题号不一致的情况:有时候输入的题目顺序可能不是按照题号排列的,为了保证判题结果准确,程序需要先根据题号排序,然后再进行匹配和判断。
题量与难度的灵活性:
题量可调:程序必须具备处理任意数量题目和答案的能力,不管是几道题都要能正常工作。
实现难度:整体实现难度适中,主要考察你在字符串处理、数据结构使用和逻辑判断方面的能力。虽然不会特别复杂,但需要你在细节上做到严谨,比如输入的解析和判题逻辑的准确性。
总结一下,这部分内容强调的是字符串操作、合理使用类来管理数据,以及灵活应对不同题量的能力。虽然不算特别难,但也需要认真考虑题目排序和答案匹配等细节。
答题判题程序 - 2:
在答题判题程序1的基础上引入了试卷编号、题目编号和分值的关联,这就要求我们用一个合适的数据结构来保存这些信息。这样就需要使用List列表或者哈希表来存储试卷号和试卷中的题目及其分值。这样做的好处是,当我们需要查询某张试卷的题目和分值时,能快速定位和处理。
为了确保程序的稳健性,加入了一些异常情况的处理。比如,如果试卷的总分不等于100分,程序会给出一个警告提示“alert: full score of test paper1 is not 100 points”反之当试卷总分等于100分时不提示消息。此外,如果答卷中使用的试卷号根本不存在,程序也会给出相应的错误提示“The test paper number does not exist”。这个过程需要额外的验证和检测,确保所有输入数据都是合理的。
其次,在第二题中,答卷里的答案数量可以和试卷上的题目数量不一致。比如,如果答卷上的答案少于题目数量,程序需要输出 answer is null,表示这道题没有答案,当然该输出会根据答卷的输入顺序来输出结果。如果答案超过题目的数量,程序会自动忽略多余的答案。这个逻辑需要对答题的长度进行检查,并根据情况灵活处理。
每道题现在有了分值,所以在判题的时候,答对了要加上相应的分数。如果题目数量较多,总分的计算就会更复杂,程序需要小心处理。此外,输出的格式也有了更多要求,除了正确与否的判断,还需要把分数和总分按要求展示出来,这部分涉及到如何拼接和格式化输出字符串。
总结下来,第二题增加的要求让程序在数据管理、异常处理和逻辑判断上更加复杂,但也更考验程序的灵活性和稳健性。
答题判题程序 - 3:
第三次答题判题程序比前两次增加了众多内容,增加了学生信息(学号-姓名);答卷信息增加与学生学号的关联,每个答卷对应一个学生,若有多个学生学号,可以存在若干学生没有答卷,只需要将存在的答卷信息进行输出。当然答卷信息中还有需要处理的难题,“#A:2-3”便是答卷中的答案,其中2对应的时试卷题目的顺序号,3对应的是该顺序号对应的题号的答案。
还有增加的输入格式——删除题目信息“#D:N-2”;一行删除信息仅可删除一题,但可有多条删除信息分多行输入。如何处理要删除题目的呢,我的思路是将需要删除的题目号和其他题目号一起存入试卷中,但是要删除的题目号对应的题目是"the question " + num + " invalid",在输出时遍历试卷中的所有题目号,进行判断是否与该content匹配,如果匹配直接输出the question num invalid~0。
这些都是在前两题的基础上增加的输入格式,当然这题还要求程序进行对输入内容的格式检查,我就想到对每个匹配的内容进行正则表达式匹配,如果匹配成功才进行下一步的拆分存储各Group内容。如何进行匹配呢,首先第一个就是对题目的配对格式必须是”#N: +... #Q: +... #A +...”对应的三部分内容题号、题目内容、标准答案,题号必须是整数,其他两部分可以任意不为空的内容。第二个是对试卷的处理,#T:1 1-5 3-8,以”#T”开头,其他都是\d+的的组合,表示都是整数的内容。第三个是对学生信息的处理,"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名 ,第四个是对学生答卷的处理,"#S:"+试卷号+" "+学号+" "+("#A:"+试卷题目的顺序号+"-"+答案内容)该内容可以出现多次即一张试卷会有多个题目。
第五个是对删除题目信息的处理,"#D:N-"+题目号,只需匹配"#D:N-"开头内容和整数题目号即可。
2. 设计与分析
2.1 源码结构分析
2.1.1 类图与架构设计(使用 PowerDesigner 绘制)
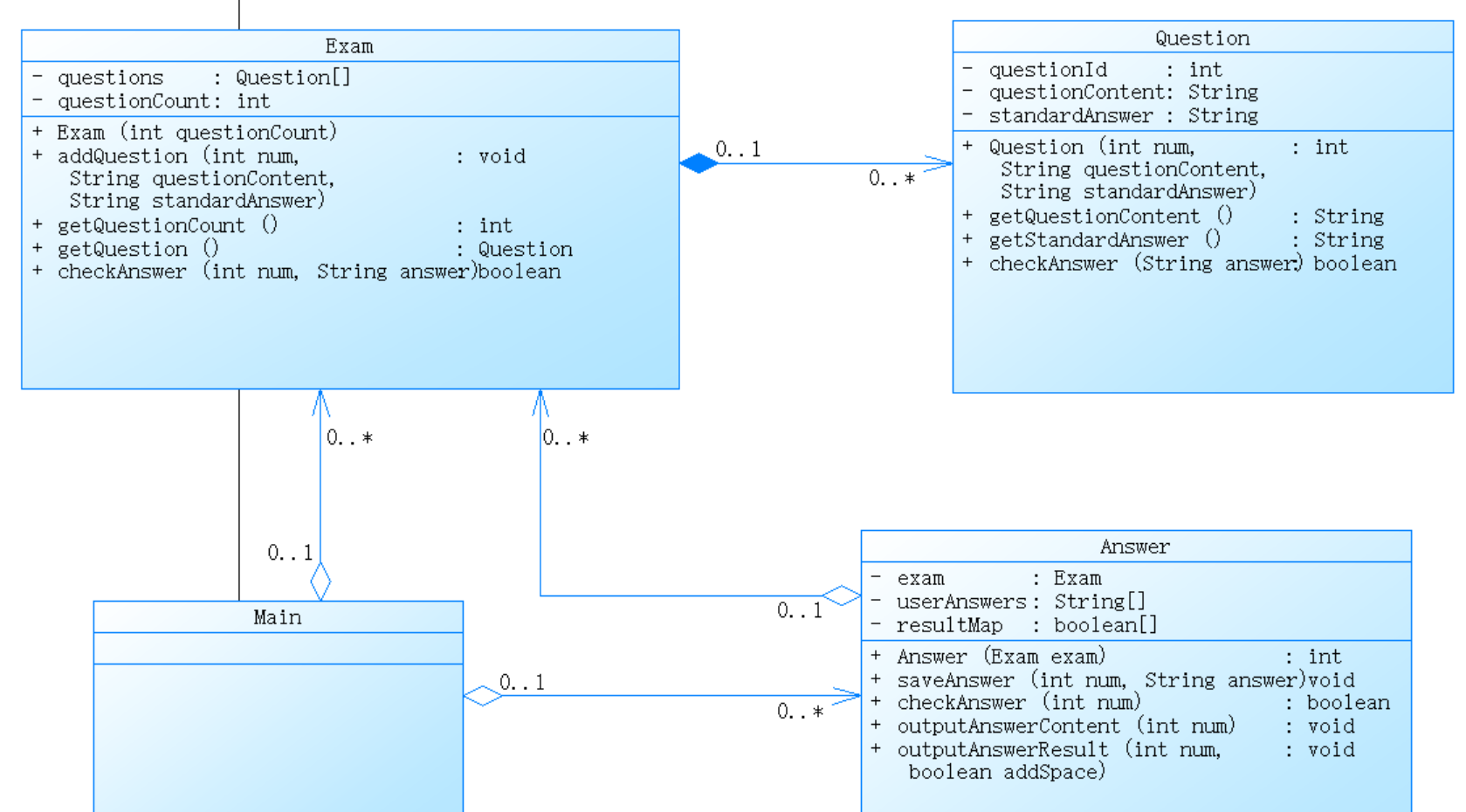
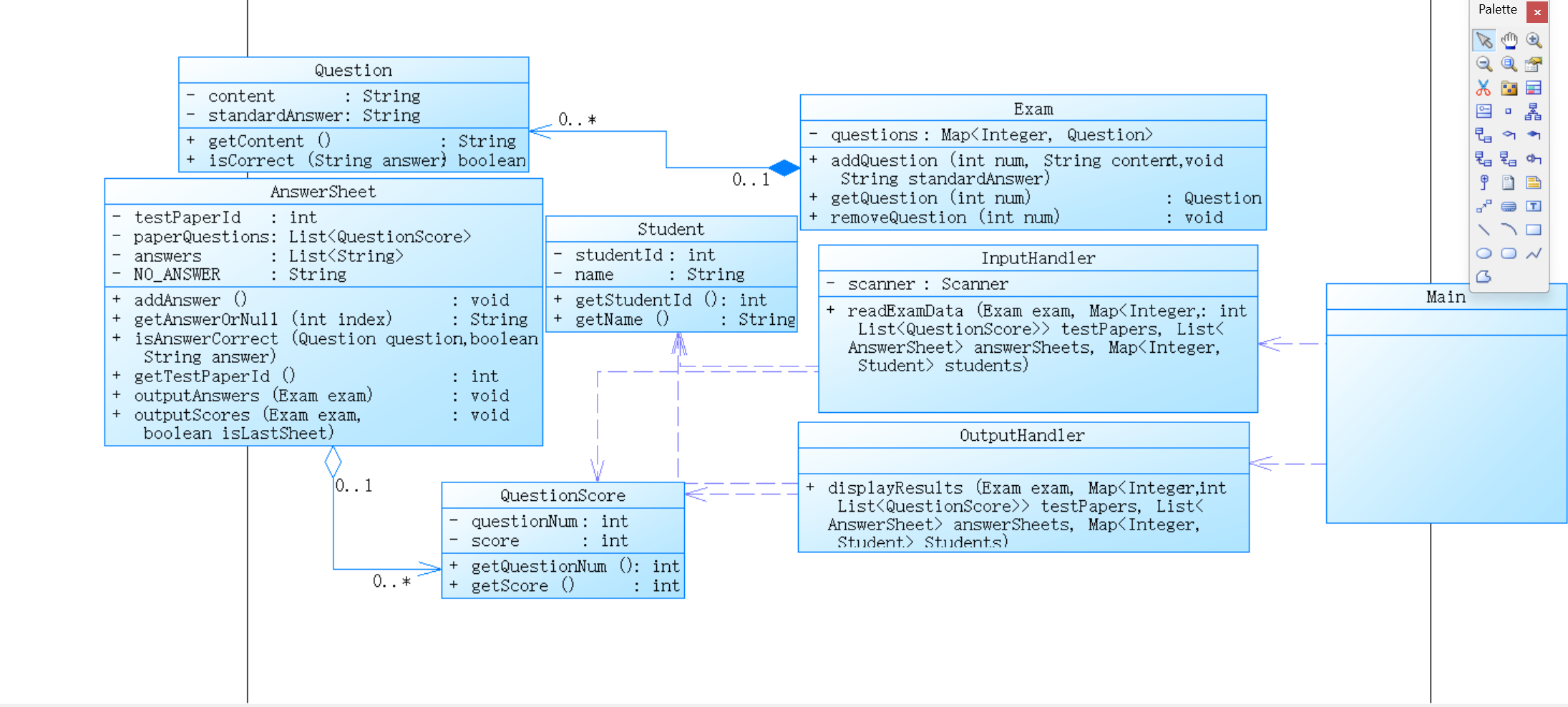
1、答题判题程序1
组合:Exam 类通过组合的方式持有 Question 对象。
关联:Answer 类通过关联方式持有 Exam 对象的引用。
依赖:Main 类依赖 Exam 和 Answer,而 Answer 类依赖 Exam。这使得类之间有一定的耦合关系,但由于职责明确,整体设计较为清晰。
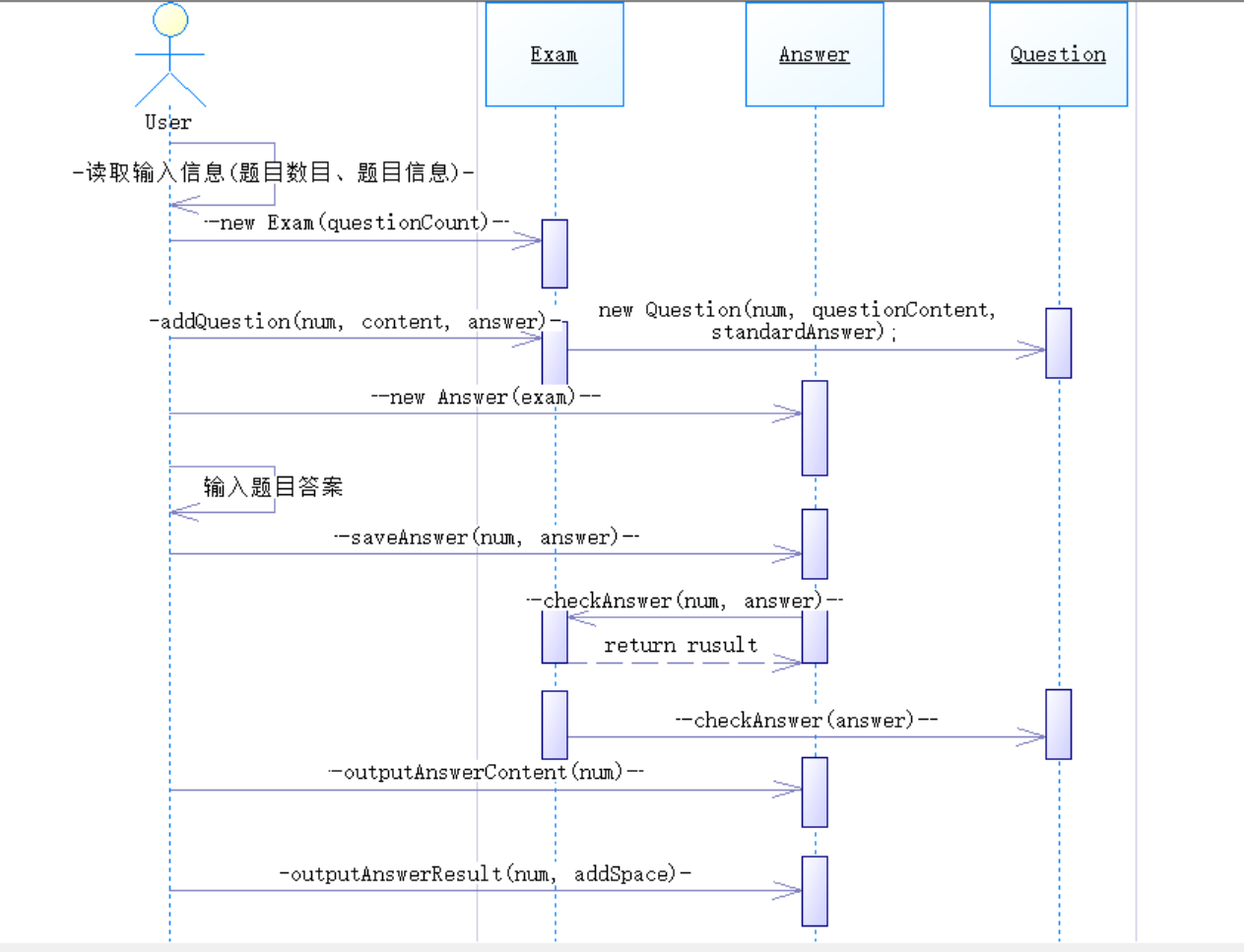
根据各类之间的关系设计了以下顺序图:
2、答题判题程序2
(1)Main 类:
初始化 Exam、testPapers (存储试卷信息) 和 answerSheets (存储答卷信息)。
使用 InputHandler 来处理输入数据,使用 OutputHandler 来处理结果输出。
(2)InputHandler 类:
解析题目信息 (#N: 开头),并将其存储在 Exam 对象中。
解析试卷信息 (#T: 开头),并存储试卷题号和对应的分数。还会检查试卷总分是否为 100 分。
解析答卷信息 (#S: 开头),并根据试卷中的题目,构建 AnswerSheet 对象。
(3)OutputHandler 类:
遍历所有答卷,输出每道题的答题情况(是否正确),以及计算并显示答卷的总分。
(4)辅助类:
QuestionScore:封装题目编号和分数。
Exam:存储题目列表,每道题包括内容和标准答案。
Question:包含题目的内容和标准答案。
AnswerSheet:存储答卷的题号、用户作答、以及输出题目答案和分数。
根据各类之间的关系设计了以下顺序图:
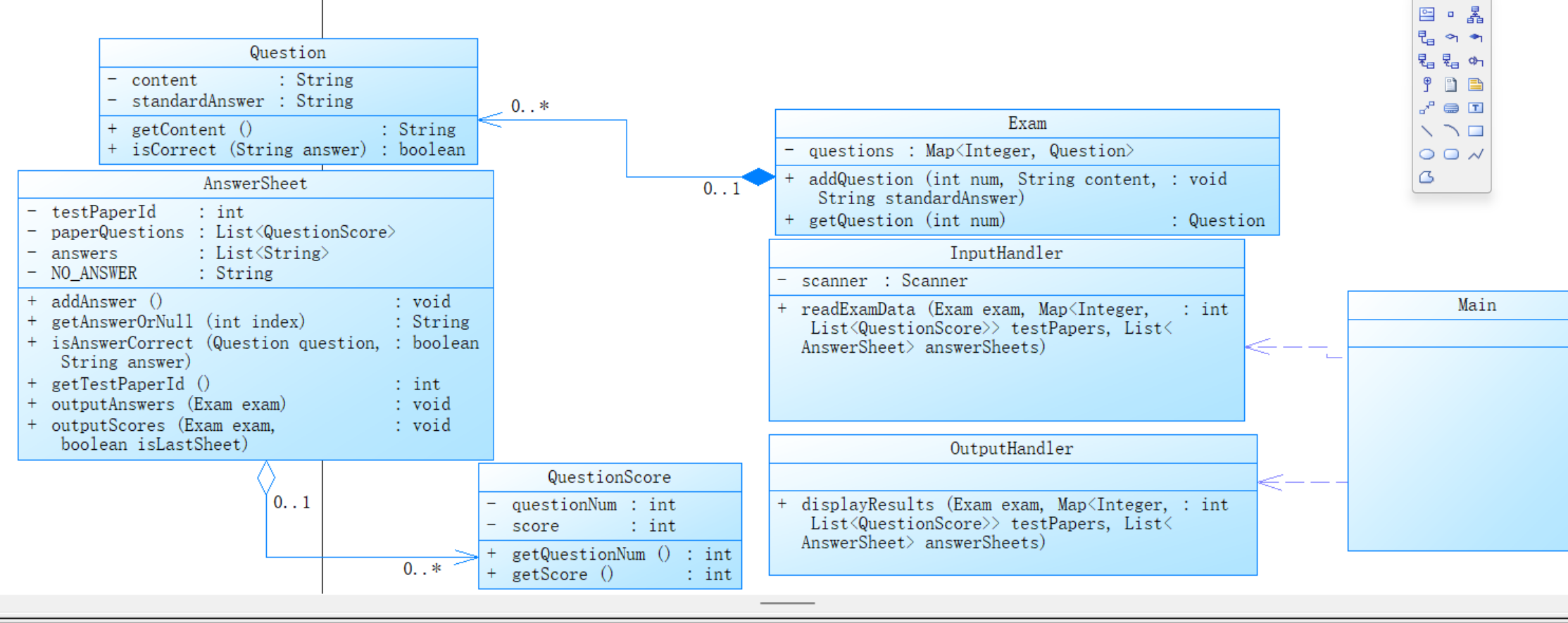
3、答题判题程序3
(1)Main 类:
依赖于 InputHandler 和 OutputHandler 来处理输入和输出。
Exam、AnswerSheet、Student、QuestionScore 等类是整个系统的数据实体。
(2)InputHandler 类:
依赖关系:
InputHandler 类依赖于 Scanner 用来读取输入。
InputHandler 类依赖于 Exam、AnswerSheet、QuestionScore、Student 等对象,将输入数据解析后存储到对应的类中。
关联关系:
InputHandler 将学生信息、题目信息、试卷信息和答卷信息组织起来,关联到相应的实体类上。
(3)OutputHandler 类:
依赖关系:
依赖于 Exam、AnswerSheet、Student 等类来输出答卷信息和成绩。
关联关系:
OutputHandler 类通过与 AnswerSheet 和 Student 类的关联,输出每个学生的答卷结果和成绩。
(4)Exam 类:
组合关系:
Exam 组合了多个 Question 对象,表示每场考试由多个题目组成。
Exam 负责题目的管理(添加题目、删除题目等)。
依赖关系:
Exam 依赖于 Question 类来存储和管理每个题目的内容和标准答案。
(5)AnswerSheet 类:
关联关系:
每个 AnswerSheet 与多个 QuestionScore 相关联,表示某张试卷的题目及其对应分数。
依赖关系:
AnswerSheet 依赖于 Exam 类来判断题目的正确与否,并计算分数。
AnswerSheet 也依赖于 Student 类来与学生信息关联。
组合关系:
AnswerSheet 组合了一个 answers Map 用于存储题目编号和对应的学生答案。
(6)Question 类:
关联关系:
Question 与 Exam 是一个关联关系,表示 Exam 管理着一系列 Question。
(7)Student 类:
关联关系:
Student 类与 AnswerSheet 类通过学生的答卷信息相关联。
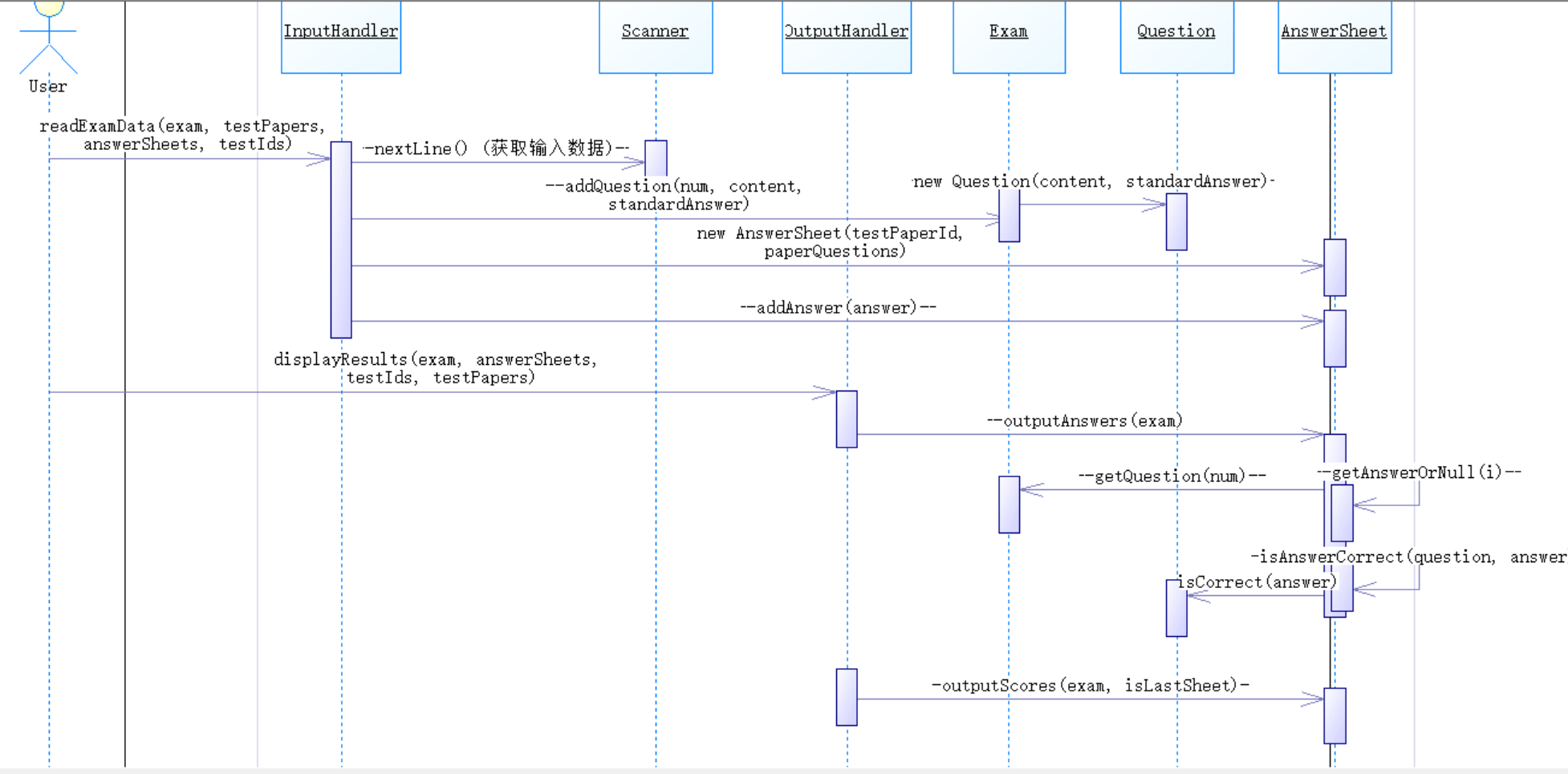
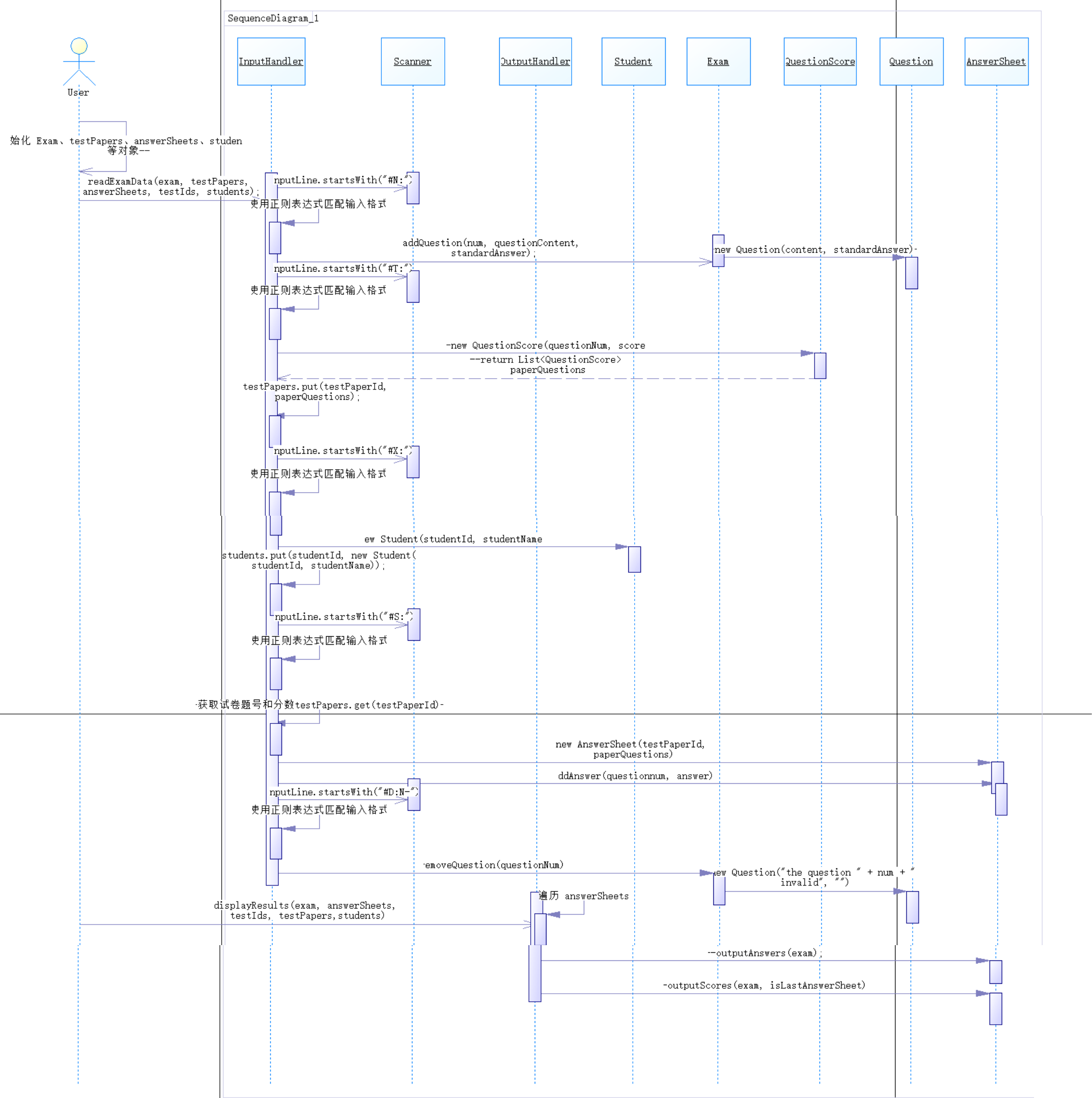
根据各类之间的关系设计了以下顺序图:
2.1.2 源码分析与复杂度评估
复杂度小结
圈复杂度:InputHandler和AnswerSheet这两个类的圈复杂度较高,因为它们包含了较多条件判断和循环。
职责分工:总体来说职责划分清晰,但InputHandler类做的事情有点多。
可读性:InputHandler类使用了大量的正则表达式和条件判断,对新读代码的人来说稍显复杂。
扩展性:要是未来加新题型或答题格式,估计要改InputHandler,因为它一个方法中处理了很多功能。
2.1.3 提交源码的设计与分析
这里只详细针对答题判题程序3来进行解析,因为他在前两题的基础上增加了功能,这样也能突出其他两题在设计上的相似之处。
这个 Java 程序的核心目的是能处理题库、试卷、学生信息和他们的答卷,还能算出每个学生的得分。系统主要通过解析输入字符串来存储这些信息,并在最后输出学生的成绩。代码结构分成几个部分,具体来说:
主类 Main:主要负责初始化各类数据结构,启动输入和输出处理。
输入处理类 InputHandler**:用来解析输入字符串,识别不同的标识符(比如 #N: 表示题目,#T: 表示试卷)并存储数据。
// 解析题目信息if (inputLine.startsWith("#N:")) { Pattern questionPattern = Pattern.compile("#N:(\\d+)\\s+(?::(#Q:(.+?))\\s+#A:(.+?))"); Matcher matcher = questionPattern.matcher(inputLine);
// 解析试卷信息 else if (inputLine.startsWith("#T:")) { Pattern testPattern = Pattern.compile("#T:(\\d+) ((\\d+-\\d+ ?)+)"); Matcher matcher = testPattern.matcher(inputLine);
// 解析学生信息 else if (inputLine.startsWith("#X:")) { Pattern studentPattern = Pattern.compile("#X:(.+)"); Matcher matcher = studentPattern.matcher(inputLine);
// 解析答卷信息 else if (inputLine.startsWith("#S:")) { Pattern answerPattern = Pattern.compile("#S:(\\d+) (\\d+)( (#A:\\d+-.+)*)*"); Matcher matcher = answerPattern.matcher(inputLine);
// 解析删除题目信息 else if (inputLine.startsWith("#D:N-")) { Pattern deletePattern = Pattern.compile("#D:N-(\\d+)"); Matcher matcher = deletePattern.matcher(inputLine);
输出处理类 OutputHandler:根据题目信息、答卷和评分标准,输出每个学生的答题情况和总分。
点击查看代码
// 遍历所有答卷,并输出答案和分数
int flag = 1;
for (Map.Entry<Integer, List<AnswerSheet>> entry : answerSheets.entrySet()) {
int studentId = entry.getKey();
List<AnswerSheet> studentAnswerSheets = entry.getValue();
Student student = students.get(studentId);
for (AnswerSheet answerSheet : studentAnswerSheets) {
int testPaperId = answerSheet.getTestPaperId();
// 检查 testPaperId 是否存在于 testPapers
if (!testPapers.containsKey(testPaperId)) {
System.out.println("The test paper number does not exist");
continue; // 跳过不存在的试卷
}
// 输出答卷的答案和分数
answerSheet.outputAnswers(exam);
if (student == null) {
System.out.println(studentId + " not found");
continue;
}
if (flag == 1){
System.out.print(studentId + " " + student.getName() + ": ");
flag ++;
}
boolean isLastAnswerSheet = answerSheet == studentAnswerSheets.get(studentAnswerSheets.size() - 1);
answerSheet.outputScores(exam, isLastAnswerSheet);
}
}
其他核心类:包括 Exam、Question、QuestionScore、AnswerSheet 和 Student,它们分别代表题库、单个题目、题目分数、答卷和学生信息。
程序有几个关键设计
正则表达式解析输入数据:InputHandler 用正则表达式识别不同类型的数据输入,但复杂的正则解析可能会影响性能。
数据映射:使用了 Map 和 List 来管理题目、试卷和学生答卷信息,方便通过题号、试卷号快速找到相应数据。
答题和评分逻辑:AnswerSheet 里有方法负责输出题目答题情况和评分,评分会根据是否答对来计算得分。
优化建议
优化正则表达式:可以分解复杂的正则解析,提升代码可读性。
答卷映射改进:可以考虑优化 AnswerSheet 中的答题号获取方式,避免出现题号偏移的错误。
评分和输出逻辑抽象:可以把评分和输出逻辑抽到一个专门的类里,比如 ScoreCalculator,让 AnswerSheet 只关注答卷数据,代码结构更清晰。
设计思路
模块化和解耦:通过输入和输出的分离,降低了主类的复杂性,并将题目、试卷和答卷分别封装成不同类,符合单一职责原则。
异常处理:当前程序的异常处理较简单,可以针对不同错误给出更具体的提示,提升用户体验。
- 采坑心得
3.1 源码提交过程中的问题
3.1.1 编译和运行问题
遇到的问题:提交代码的时候,有时会出现编译报错或者运行时崩溃的情况,常见的就是输入时为匹配正确的格式或者变量未能正确的进行传参和被使用,导致提交中提示非零返回。还有输入顺序可能影响程序的正常运行,在输入顺序为乱序时,程序应能正确处理题号和对应的题目跟答案将这些存入Map或者List数组中。
一些具体例子:
比如正则表达式没有设计好,导致错误内容被错误接收并处理;
还有对于未出现的试卷Id要进行统一处理这和处理按输入顺序处理的答卷信息一样在OuputHandler类中进行处理。
// 检查 testPaperId 是否存在于 testPapers if (!testPapers.containsKey(testPaperId)) { System.out.println("The test paper number does not exist"); continue; // 跳过不存在的试卷 }
3.1.2 正确性与逻辑错误
问题描述:还有一些逻辑上的小错误,比如评分的时候,没有处理题目被删除的情况,导致得分不对。
如何解决:
通过单步调试找到问题,然后在评分逻辑里加入题目有效性的检查,保证只有有效题目才能计分。
优化后的代码:通过引入一个题目检查的方法来判断题目是否有效,解决了错误计分的问题。
- 改进建议
4.1. 代码重构和模块化
- 提取公共方法:OutputHandler 和 InputHandler 中有很多重复的代码,比如字符串解析和验证,可以把这些重复的逻辑提取到一个公共方法里,方便以后改动时一处改动,全局生效。
- 优化错误处理:现在的 try-catch 块有点冗长。可以把错误处理的逻辑封装到一个独立的类,这样 readExamData 方法的逻辑会更清晰。
- 引入业务逻辑层:可以把主要的业务逻辑分离出来,比如创建 ExamService 和 StudentService 类,把考试和学生管理的逻辑从 Exam、Student、AnswerSheet 等类中抽离,这样代码更容易理解和维护。
4.2. 增强数据的可扩展性
- 使用枚举代替字符串常量:现在代码里用到很多固定字符串,比如 #N:、#T: 等。可以用枚举来代替,减少硬编码的字符串,这样要扩展时也更灵活。
- 改进数据存储结构:如果需要处理大量试卷或答卷,HashMap 可能不够用。可以考虑用数据库存储数据,这样查询和数据管理会更方便。
4.3. 改进正则表达式处理
- 增强正则的健壮性:正则匹配可能出错,可以考虑用一个正则解析器类来集中管理所有正则逻辑。这样出错时能有清晰的提示。
- 简化正则结构:可以分步骤匹配,减少正则表达式的复杂性和出错率。
4.4. 提升代码的可读性
- 使用流式 API 和 Optional:Java 的 Stream API 和 Optional 可以让代码更简洁,比如在 outputScores 里用 Stream 来计算总分,代码会更简洁。
- 优化控制结构:检查行首前缀时,switch 语句比一堆 if-else 更清晰,也更高效。
4.5. 多态和接口使用
- 接口隔离职责:可以为 OutputHandler 和 InputHandler 定义接口,让它们的功能更通用。比如,用 DataParser 接口处理数据解析,这样如果输入格式有变化,只需要实现新的解析类,不需要改原有代码。
- 继承和多态:可以创建不同类型的 Question 类,比如 SingleChoiceQuestion 和 EssayQuestion,来支持不同题型,增强系统的扩展性。
4.6. 提升测试和维护便利性
- 增加测试覆盖率:可以写单元测试来验证每个类和方法的行为,比如 InputHandler 处理的各种输入类型,这样能更快发现错误,提高代码质量。
- 添加注释和文档:在关键代码处添加注释,特别是解释特定输入格式和复杂逻辑的地方,这样以后维护或团队协作时更容易理解。
4.7. 优化性能
- 惰性加载:对于数据量较大的 questions、testPapers 等,可以只在需要时才加载,避免不必要的内存占用。
- 并行处理:如果有大量的答卷,可以用并行流处理评分输出 (outputAnswers 和 outputScores),这样速度会更快。
- 总结
5.1 本阶段的知识总结
算法和数据结构:加深了对 HashMap、ArrayList 等数据结构的理解,并学会了在不同场景下如何选择和应用它们。另外,像排序、查找和字符串解析这些基础算法也都有练习,帮助我们慢慢建立算法的思维方式。
面向对象设计:通过实践面向对象编程,掌握了像封装、继承和多态这些核心概念。比如,在题库管理系统的代码中,我们学会了如何把题目、学生、试卷等不同角色分成独立的类,这样设计让代码结构更清晰,也更好维护。
问题分析和代码优化:练习了如何把复杂的问题分解成更小的步骤来解决。学会了基本的代码优化技巧,比如消除重复代码、提取公共方法、简化逻辑结构等,让代码更简洁高效。
效率提升:也接触到了基本的性能优化,认识到如何通过选择合适的数据结构和算法来提升代码的执行速度。
5.2 未来学习方向
高级算法和数据结构:进一步了解像图、堆、树这样的高级数据结构,以及动态规划、贪心算法等复杂的算法技巧,这些有助于我们解决更难的问题。
性能优化和并行计算:学习如何通过多线程和并行计算来加快代码的运行速度,比如学会使用惰性加载和并行流等优化方法,适应更大规模的数据需求。
设计模式:可以多学一些常见的设计模式,比如工厂模式、观察者模式、单例模式等等,提升代码的复用性、扩展性和可维护性。
测试和代码质量:多学习不同的测试方法,包括单元测试和集成测试等,确保代码的稳定性和质量。
5.3 对教师、课程、作业及组织方式的建议
教学方式:希望增加项目实践和小组讨论的机会,这样能更好地帮助大家在实际操作中巩固知识。还可以多分享一些代码范例和完整项目,让大家能更好地理解知识点的应用。
作业难度:作业难度可以分为基础和进阶两部分,基础的用于巩固课堂知识,进阶的让大家有更多的空间思考和探索,不同水平的同学都能有适合的任务。
课下资源:建议可以提供更多的在线学习资源,比如一些编程学习网站和技术文档,帮助大家在课后有更多的自学途径。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异