
Word2Vec之Skip-Gram模型
理解 Word2Vec 之 Skip-Gram 模型
模型
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。本篇文章仅讲解Skip-Gram模型。
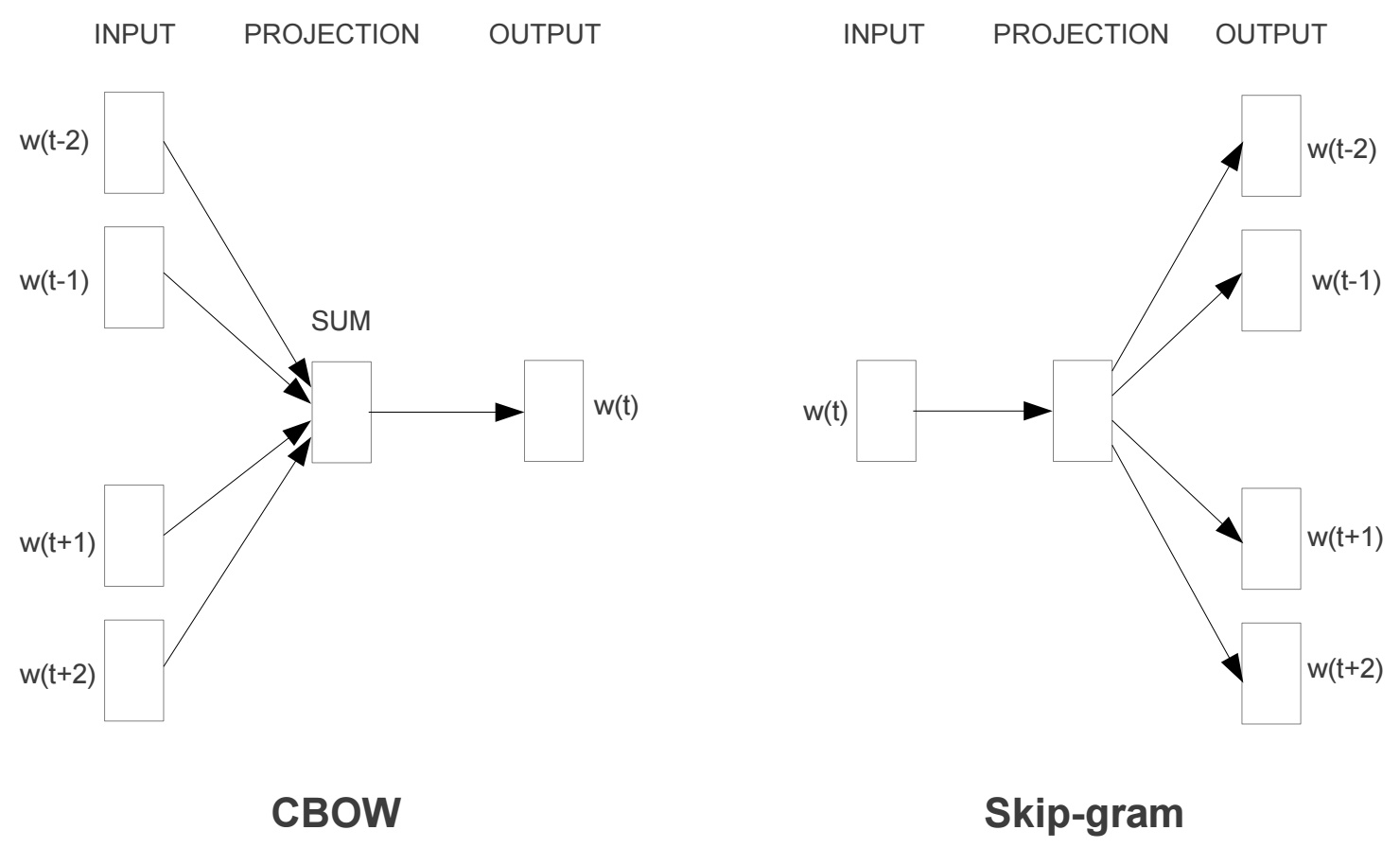
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。
模型输入
(input word, output word)
output word获取:
skip_window,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。
num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word
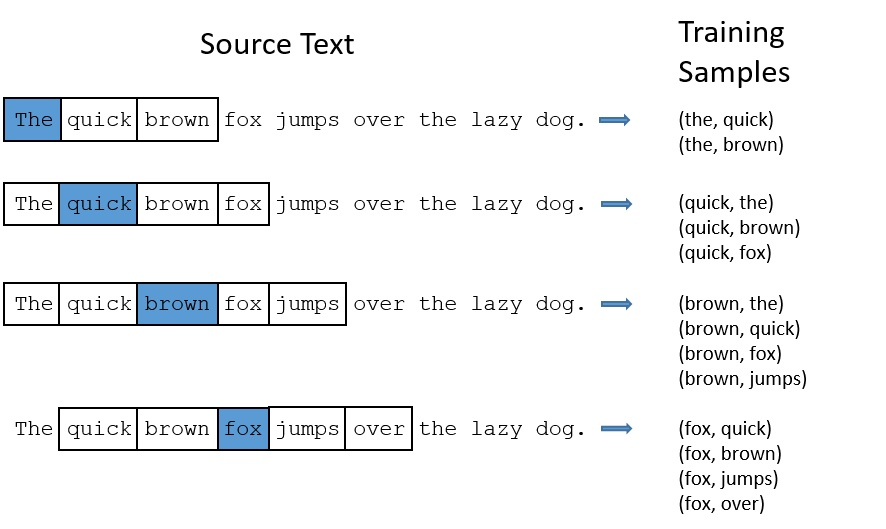
下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。
如何来表示这些单词
最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行one-hot编码。
例子
The dog barked at the mailman”,我们基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):("the", "dog", "barked", "at", "mailman"),我们对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
下图是我们神经网络的结构:
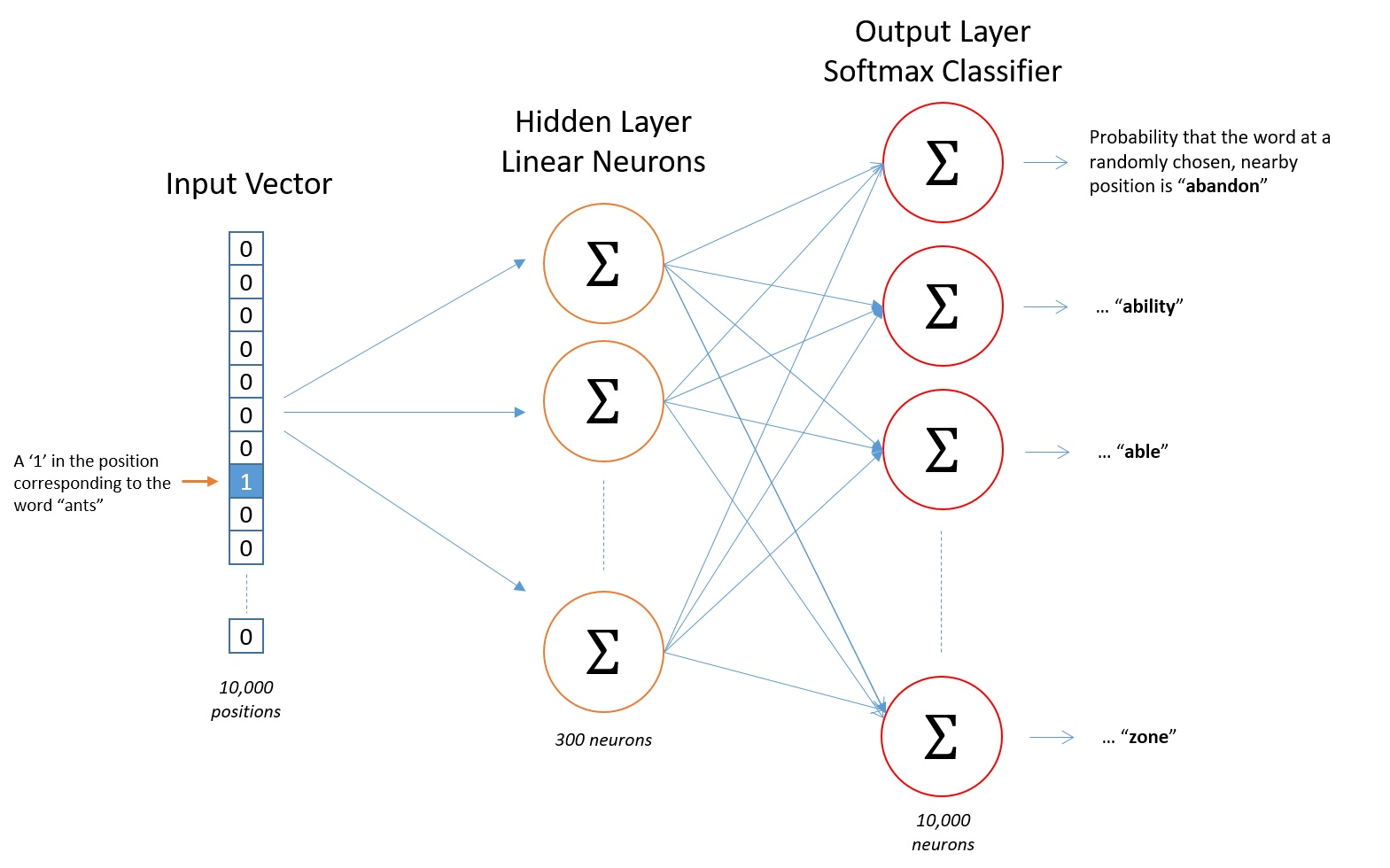
隐层没有使用任何激活函数,但是输出层使用了sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
x:词汇 y:相关词汇
输入 词汇总个数 10000 每一行表示一个单词, 每一行都是0或1,表示单词是否出现
隐含层单层 300神经元
输出层 词汇总个数 softmax 10000 每一行表示这个单词相关的概率
输入到隐含层参数 10000*300
隐含层到输出参数 300*10000
抽样率用于减少训练样本的个数。
负采样用于反向传播参数的更新,一次只更新一小部分参数
损失函数
交叉熵函数:

其中y代表我们的真实值,a代表我们softmax求出的值。i代表的是输出结点的标号
如何在skip-gram模型上进行高效的训练。
- 将常见的单词组合(word pairs)或者词组作为单个“words”来处理。
- 对高频次单词进行抽样来减少训练样本的个数。
- 对优化目标采用“negative sampling”方法,这样每个训练样本的训练只会更新一小部分的模型权重,从而降低计算负担。
事实证明,对常用词抽样并且对优化目标采用“negative sampling”不仅降低了训练过程中的计算负担,还提高了训练的词向量的质量。
对高频词抽样
“The quick brown fox jumps over the laze dog”,如果我使用大小为2的窗口,那么我们可以得到图中展示的那些训练样本:

对于“the”这种常用高频单词,这样的处理方式会存在下面两个问题:
- 当我们得到成对的单词训练样本时,("fox", "the") 这样的训练样本并不会给我们提供关于“fox”更多的语义信息,因为“the”在每个单词的上下文中几乎都会出现。
- 由于在文本中“the”这样的常用词出现概率很大,因此我们将会有大量的(”the“,...)这样的训练样本,而这些样本数量远远超过了我们学习“the”这个词向量所需的训练样本数。
Word2Vec通过“抽样”模式来解决这种高频词问题。它的基本思想如下:对于我们在训练原始文本中遇到的每一个单词,它们都有一定概率被我们从文本中删掉,而这个被删除的概率与单词的频率有关。
抽样率
word2vec的C语言代码实现了一个计算在词汇表中保留某个词概率的公式。
是一个单词,
是
这个单词在所有语料中出现的频次。举个栗子,如果单词“peanut”在10亿规模大小的语料中出现了1000次,那么
。
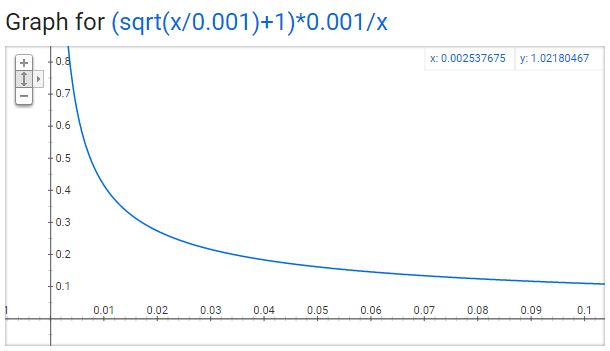
在代码中还有一个参数叫“sample”,这个参数代表一个阈值,默认值为0.001。这个值越小意味着这个单词被保留下来的概率越小(即有越大的概率被我们删除)。
代表着保留某个单词的概率:
负采样(negative sampling)
训练一个神经网络意味着要输入训练样本并且不断调整神经元的权重,从而不断提高对目标的准确预测。每当神经网络经过一个训练样本的训练,它的权重就会进行一次调整。
正如我们上面所讨论的,vocabulary的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过我们数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢。
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。
如何选择negative words
Word2Vec源码解析
我们使用“一元模型分布(unigram distribution)”来选择“negative words”。
要注意的一点是,一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。

上图线段的每一段是由词汇表中每个单词的索引号填充的
将单词出现频率按比例转换为线段长度(词线段),出现频率越高线段越长,越容易选中
roll点之间是等间隔的。
每次我们进行负采样时,只需要在roll点范围内生成一个随机数,然后选择roll点对应词线段的那个单词作为我们的negative word即可。一个单词的负采样概率越大,那么它在这个表中出现的次数就越多,它被选中的概率就越大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号