
SVM
线性可分支持向量机
函数间隔和几何间隔 max(2/||w||) 或min((1/2)*||w||)
原始问题的对偶问题是极大极小问题 maxaminw,b
1.对w,b求偏导数并令其等于0
2.KKT条件
从KKT条件可知,对偶问题解出的α参数,仅support vectors的αi非零,其余全0。
函数间隔和几何间隔
所以样本点与超平面
之间的函数间隔定义为
但是该定义存在问题:即和
同时缩小或放大M倍后,超平面并没有变化,但是函数间隔却变化了。所以,需要将
的大小固定,如令
,使得函数间隔固定。这时的间隔也就是几何间隔 ,二者相等
几何间隔的定义如下
实际上,几何间隔就是点到超平面的距离。
几何间隔就是函数间隔除以||w||,而且函数间隔y*(wx+b) = y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量,而几何间隔|f(x)|/||w||才是直观上的点到超平面的距离。
线性可分支持向量机
$\underbrace{min}_{\alpha} \frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_j(x_i \bullet x_j) - \sum\limits_{i=1}^{m} \alpha_i$
$s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0$
$\alpha_i \geq 0 \; i=1,2,...m$
怎么得到支持向量呢?根据KKT条件中的对偶互补条件$\alpha_{i}^{*}(y_i(w^Tx_i + b) - 1) = 0$,如果$\alpha_i>0$则有$y_i(w^Tx_i + b) =1$即点在支持向量上,否则如果$\alpha_i=0$则有$y_i(w^Tx_i + b) \geq 1$,即样本在支持向量上或者已经被正确分类。$\alpha_i>0$点i在支持向量上

线性支持向量机
线性支持向量机和线性可分支持向量机异同点
(1)相同点:
它们由拉格朗日函数构造的对偶问题的目标函数一样(约束条件不同);它们w,b的计算公式一样;w都是唯一的;在求出w,b后,分类决策函数一样。
(2)不同点
原始问题不同,一个是优化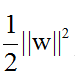 ,一个是优化
,一个是优化
ai的取值范围不同,一个为ai>=0,一个为0<=ai<=C;
线性支持向量机b可能不唯一。
支持向量情况不同:线性可分支持向量机的支持向量分布在:间隔边界上
线性支持向量机的支持向量可能分布在:间隔边界上,间隔边界与超平面之间,分离超平面误分一侧。
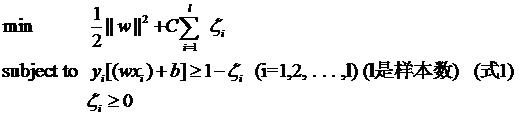
这个式子有这么几点要注意:
(1)并非所有的样本点都有一个松弛变量与其对应。实际上只有“离群点”才有,或者也可以这么看,所有没离群的点松弛变量都等于0(对负类来说,离群点就是在下面图中,跑到H2右侧的那些负样本点,对正类来说,就是跑到H1左侧的那些正样本点)。
(2)松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
(3)惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点,最极端的情况是你把C定为无限大,这样只要稍有一个点离群,目标函数的值马上变成无限大,马上让问题变成无解,这就退化成了硬间隔问题。
(4)惩罚因子C不是一个变量,整个优化问题在解的时候,C是一个你必须事先指定的值,指定这个值以后,解一下,得到一个分类器,然后用测试数据看看结果怎么样,如果不够好,换一个C的值,再解一次优化问题,得到另一个分类器,再看看效果,如此就是一个参数寻优的过程,但这和优化问题本身决不是一回事,优化问题在解的过程中,C一直是定值,要记住。
(5)尽管加了松弛变量这么一说,但这个优化问题仍然是一个优化问题,解它的过程比起原始的硬间隔问题来说,没有任何更加特殊的地方。
惩罚因子常用点:解决分类问题中样本的“偏斜”问题
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个
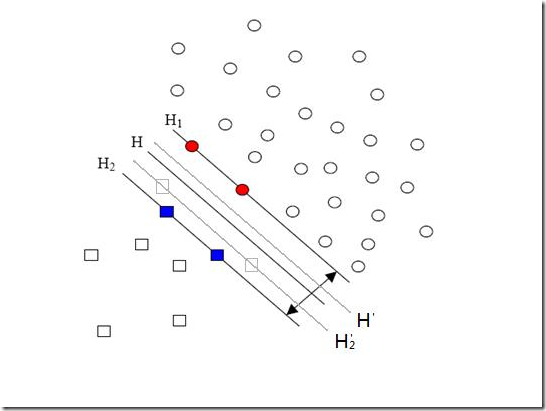
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:
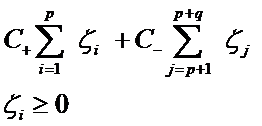
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比值来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。
说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!
所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
说来说去,这岂不成了一个解决不了的问题?然而事实如此,完全的方法是没有的,根据需要,选择实现简单又合用的就好(例如libSVM就直接使用样本数量的比)。
非线性支持向量机
将低维空间中的非线性分类问题转换为高位空间中的线性分类问题。从而在高维空间里面学习线性支持向量机,进行分类。
如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的
此时,核函数就隆重登场了,核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
使用松弛变量处理 outliers 方法
在最开始讨论支持向量机的时候,我们就假定,数据是线性可分的,亦即我们可以找到一个可行的超平面将数据完全分开。后来为了处理非线性数据,使用 Kernel 方法对原来的线性 SVM 进行了推广,使得非线性的的情况也能处理。虽然通过映射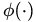 将原始数据映射到高维空间之后,能够线性分隔的概率大大增加,但是对于某些情况还是很难处理。
将原始数据映射到高维空间之后,能够线性分隔的概率大大增加,但是对于某些情况还是很难处理。
例如可能并不是因为数据本身是非线性结构的,而只是因为数据有噪音。对于这种偏离正常位置很远的数据点,我们称之为 outlier ,在我们原来的 SVM 模型里,outlier 的存在有可能造成很大的影响,因为超平面本身就是只有少数几个 support vector 组成的,如果这些 support vector 里又存在 outlier 的话,其影响就很大了。例如下图:

用黑圈圈起来的那个蓝点是一个 outlier ,它偏离了自己原本所应该在的那个半空间,如果直接忽略掉它的话,原来的分隔超平面还是挺好的,但是由于这个 outlier 的出现,导致分隔超平面不得不被挤歪了,变成途中黑色虚线所示(这只是一个示意图,并没有严格计算精确坐标),同时 margin 也相应变小了。当然,更严重的情况是,如果这个 outlier 再往右上移动一些距离的话,我们将无法构造出能将数据分开的超平面来。
为了处理这种情况,SVM 允许数据点在一定程度上偏离一下超平面。例如上图中,黑色实线所对应的距离,就是该 outlier 偏离的距离,如果把它移动回来,就刚好落在原来的 超平面 蓝色间隔边界上,而不会使得超平面发生变形了。
插播下一位读者@Copper_PKU的理解:“换言之,在有松弛的情况下outlier 点也属于支持向量SV,同时,对于不同的支持向量,拉格朗日参数的值也不同,如此篇论文《Large Scale Machine Learning》中的下图所示:
对于远离分类平面的点值为0;对于边缘上的点值在[0, 1/L]之间,其中,L为训练数据集个数,即数据集大小;对于outline数据和内部的数据值为1/L。
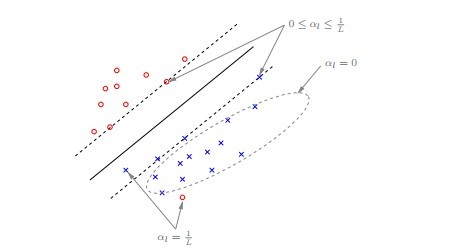
损失函数 hinge loss

其中t为标签{-1,1} y为预测分类。
对于二分类svm而言,正确分类且非支持向量点的 l 值为0.即可看为放弃了使用非支持向量点,这正是SVM的核心所在。
一般情况下解释hinge loss的含义:
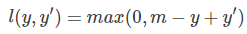
其中,y是正样本的得分,y’是负样本的得分,m是margin(自己选一个数。我们希望正样本分数越高越好,负样本分数越低越好,但二者得分之差最多到m就足够了,差距增大并不会有任何奖励。
机器学习中的损失函数 (着重比较:hinge loss vs softmax loss)
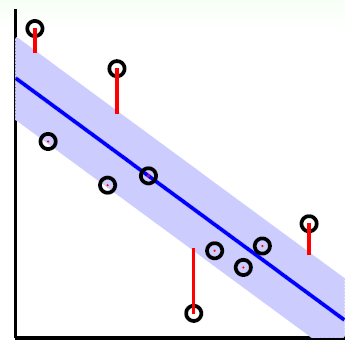
和SVM分类模型类似,SVM回归模型也可以对每个样本点
和SVM分类模型一样,我们也可以用拉格朗日函数将目标优化函数变成无约束的形式,即:
其中
支持向量机(SVM)是否适合大规模数据?
按照我的理解,SVM工作内容是去找超平面
在你的数据分布还不够的时候,增加数据当然能够增加模型的准确率,能够有效调整分类面的长相,但是当你的数据分布覆盖面足够的时候,你的支持向量已经基本选定,你继续增加训练数据,正常的数据是不会对分类面产生任何影响的,因为它们并不是支持向量,而一些噪声数据则会对分类面产生不好的影响,它们可能会在分类面附近甚至被当做支持向量,导致支持向量过多,超平面过拟合,这种不管在计算速度上还是在准确率上都会产生不太好的影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号