
[转]如何处理不均衡数据?
https://mp.weixin.qq.com/s/e0jXXCIhbaZz7xaCZl-YmA
不均衡的数据通常来说形式都比较固定,并且也比较好区分.比如说你手头上现在有苹果和梨,在这个时候你手中的数据都跟你说,全世界的人都吃梨哦,这个时候你去找一个路人甲,问问他你是不是喜欢吃梨啊,这个时候我们大多数人都会猜测,这个人会吃梨,这个时候梨就可以作为优势数据变得很骄傲了.
这个时候,让我们来引入今天的问题,如何处理不均衡数据.
其实不均衡的数据理解预测起来很简单,永远都是预测多的数据的那一方,这样准没错,特别是数据多很多的情况的那一方,比如多的占了90%,少的占10%.只要每一次都预测多的那一批数据,预测的准确性就可以达到90%了。
没错,这样听起来是不是有点偷懒的感觉呢?其实机器也懂得这些小伎俩,所以经过训练以后,机器也变得精明了,每一次都预测多的那部分数据,但是这样是不可以的!接下来我们来谈谈解决这个问题的几种方法
方法1:想办法获取更多的数据(前后期趋势不同)
首先我们要想一想我们是否可以获取更多的数据,有的时候我们在获取数据的前期,通常数据会呈现一个变化的趋势,这时候表现为某一种数据量偏多,等到数据的后半段的时期,数据的变化的趋势可能就会不一样了。
如果没有获取后半期的数据,从整体来看,预测就可能不会那么的精准.所以想办法获得更多的数据有可能会改善这个情况~
方法2:换一种评判方式
通常情况下,我们会使用准确率(Accuracy)和误差(Cost)两种方式来判断机器学习的成果.但是在不均衡的数据面前,高的准确率和低的误差就显得没有那么有用和重要了.
所以我们就可以换个方式去计算,很多时候我们会使用Confusion Matrix去计算Precision&Recall,然后在通过Precision&Recall去计算F1 Score(or F-score).通过这样的数据,我们可以很大程度上去区分不均衡数据,并且可以给出更好的分数.因为我水平的问题,具体的计算推理过程等我日后会进行推导!(立flag)
方法3:重组数据
第三种方法相对来说最为简单粗暴,对不均衡的数据进行重新组合,使之均衡。
第一种方式是复制少数数据里的样本,使其可以达到和多数数据样本差不多的数量。(数据扩样)
第二种方式就是对多数样本的数据进行开刀,砍掉一些多数样本的数据,还是使两者的数量差不多
方法4:使用其他的机器学习方法
在使用一些机器学习的方法中,比如神经网络,在面对不均衡数据的时候都是束手无策的,但是像决策树这样的方法就不会受到不均衡数据的影响
方法5:修改算法
在所有方法中,最具有创造力的方法莫过于这个修改算法了,如果你使用的是Sigmoid函数,他会有一个预测的门槛,如果低于门槛,预测的结果为梨,如果超过了门槛,预测的结果为苹果。
不过因为现在梨的数量过多,这个时候我们就需要调解下门槛的位置,使得门槛更加的偏向于苹果这一边,只有数据非常准确的情况下,模型才会预测为苹果,从而使机器学习学习到更好的效果.
不平衡数据下的机器学习方法
改变分类算法
代价矩阵
采样算法从数据层面解决不平衡数据的学习问题,在算法层面上解决不平衡数据学习的方法主要是基于代价敏感学习算法(Cost-Sensitive Learning),代价敏感学习方法的核心要素是代价矩阵,我们注意到在实际的应用中不同类型的误分类情况导致的代价是不一样的,例如在医疗中,“将病人误疹为健康人”和“将健康人误疹为病人”的代价不同;在信用卡盗用检测中,“将盗用误认为正常使用”与“将正常使用识破认为盗用”的代价也不相同,因此我们定义代价矩阵如下图5所示。标记Cij为将类别j误分类为类别i的代价,显然C_00=C_11=0,C_01,C_10为两种不同的误分类代价,当两者相等时为代价不敏感的学习问题。
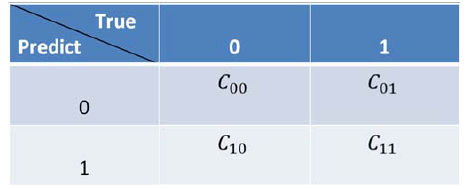
基于以上代价矩阵的分析,代价敏感学习方法主要有以下三种实现方式,分别是:
1、从学习模型出发,着眼于对某一具体学习方法的改造,使之能适应不平衡数据下的学习,研究者们针对不同的学习模型如感知机,支持向量机,决策树,神经网络等分别提出了其代价敏感的版本。以代价敏感的决策树为例,可从三个方面对其进行改进以适应不平衡数据的学习,这三个方面分别是决策阈值的选择方面、分裂标准的选择方面、剪枝方面,这三个方面中都可以将代价矩阵引入
2、从贝叶斯风险理论出发,把代价敏感学习看成是分类结果的一种后处理(先验信息),按照传统方法学习到一个模型,以实现损失最小为目标对结果进行调整,优化公式如下所示。此方法的优点在于它可以不依赖所用具体的分类器,但是缺点也很明显它要求分类器输出值为概率。

3、从预处理的角度出发,将代价用于权重的调整,使得分类器满足代价敏感的特性,下面讲解一种基于Adaboost的权重更新策略。
Adaboost算法通过反复迭代,每一轮迭代学习到一个分类器,并根据当前分类器的表现更新样本的权重,如图中红框所示,其更新策略为正确分类样本权重降低,错误分类样本权重加大,最终的模型是多次迭代模型的一个加权线性组合,分类越准确的分类器将会获得越大的权重。
AdaCost算法修改了Adaboost算法的权重更新策略,其基本思想是对于代价高的误分类样本大大地提高其权重,而对于代价高的正确分类样本适当地降低其权重,使其权重降低相对较小。总体思想是代价高样本权重增加得大降低得慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号