
go中的协程-goroutine的底层实现(2)
1. goroutine源码分析
1.1 初始化
go程序的启动流程分为四步
- call osinit, 这里就是设置了全局变量ncpu = cpu核心数量
- call schedinit
- make & queue new G (runtime.newproc, go func()也是调用这个函数来创建goroutine)
- call runtime·mstart
其中,schedinit 就是调度器的初始化,除了schedinit 中对内存分配,垃圾回收等操作,针对调度器的初始化大致就是初始化自身,设置最大的maxmcount, 确定p的数量并初始化这些操作。
schedinit
schedinit这里对当前m进行了初始化,并根据osinit获取到的CPU核数和设置的GOMAXPROCS确定P的数量,并进行初始化。
1 func schedinit() { 2 // 从TLS或者专用寄存器获取当前g的指针类型 3 _g_ := getg() 4 // 设置m最大的数量 5 sched.maxmcount = 10000 6 7 // 初始化栈的复用空间 8 stackinit() 9 // 初始化当前m 10 mcommoninit(_g_.m) 11 12 // osinit的时候会设置 ncpu这个全局变量,这里就是根据cpu核心数和参数GOMAXPROCS来确定p的数量 13 procs := ncpu 14 if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { 15 procs = n 16 } 17 // 生成设定数量的p 18 if procresize(procs) != nil { 19 throw("unknown runnable goroutine during bootstrap") 20 } 21 }
初始化当前M时调用了 mcommoninit() 函数,再看下这个函数的实现
mcommoninit
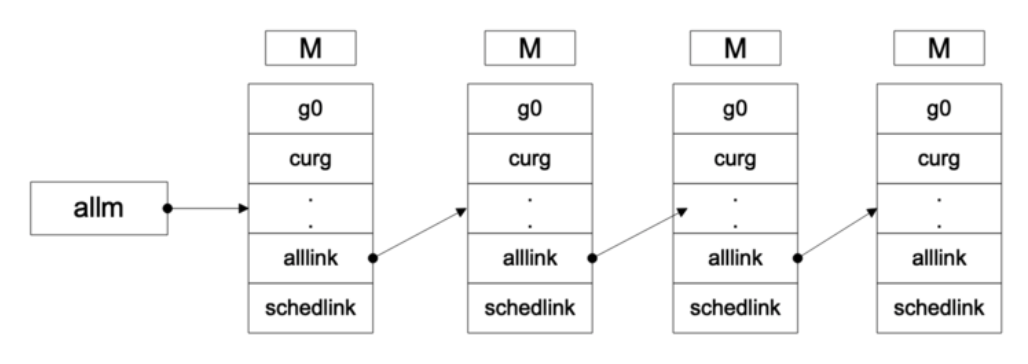
1 func mcommoninit(mp *m) { 2 _g_ := getg() 3 4 lock(&sched.lock) 5 // 判断mnext的值是否溢出,mnext需要赋值给m.id 6 if sched.mnext+1 < sched.mnext { 7 throw("runtime: thread ID overflow") 8 } 9 mp.id = sched.mnext 10 sched.mnext++ 11 // 判断m的数量是否比maxmcount设定的要多,如果超出直接报异常 12 checkmcount() 13 // 创建一个新的g用于处理signal,并分配栈 14 mpreinit(mp) 15 if mp.gsignal != nil { 16 mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard 17 } 18 19 //添加到allm,以便垃圾收集器不会释放g-> m 20 //仅在寄存器或线程本地存储中时。 21 22 // 接下来的两行,首先将当前m放到allm的头,然后原子操作,将当前m的地址,赋值给m,这样就将当前m添加到了allm链表的头了 23 mp.alllink = allm 24 25 // NumCgoCall()遍历不带schedlock的allm, 26 //,因此我们需要安全地发布它。 27 atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp)) 28 unlock(&sched.lock) 29 30 //如果cgo调用崩溃,则分配内存以保留cgo追溯。 31 if iscgo || GOOS == "solaris" || GOOS == "windows" { 32 mp.cgoCallers = new(cgoCallers) 33 } 34 }
在这里就开始涉及到了m链表了,这个链表可以如下图表示:
再来看一下生成P的函数procesize:
procresize
这个函数可以改变p的数量,多退少补的原则,在初始化过程中,由于最开始是没有p的,所以开始的作用就是初始化设定数量的p。procresize不仅在初始化的时候会被调用,当用户手动调用runtime.GOMAXPROCS 的时候,会重新设定 nprocs,然后执行 startTheWorld(), startTheWorld()会是使用新的 nprocs 再次调用procresize 这个方法。
1 func procresize(nprocs int32) *p { 2 old := gomaxprocs 3 if old < 0 || nprocs <= 0 { 4 throw("procresize: invalid arg") 5 } 6 // 更新统计 7 now := nanotime() 8 if sched.procresizetime != 0 { 9 sched.totaltime += int64(old) * (now - sched.procresizetime) 10 } 11 sched.procresizetime = now 12 13 // Grow allp if necessary. 14 // 如果新给的p的数量比原先的p的数量多,则新建增长的p 15 if nprocs > int32(len(allp)) { 16 // 与取录同步(可能正在运行)同时运行,因为它不在P上运行。 17 lock(&allpLock) 18 // 判断allp 的cap是否满足增长后的长度,满足就直接使用,不满足,则需要扩张这个slice 19 if nprocs <= int32(cap(allp)) { 20 allp = allp[:nprocs] 21 } else { 22 nallp := make([]*p, nprocs) 23 //复制所有内容至allp的上限,因此我们永远不会丢失旧分配的P。 24 copy(nallp, allp[:cap(allp)]) 25 allp = nallp 26 } 27 unlock(&allpLock) 28 } 29 30 // initialize new P's 31 // 初始化新增的p 32 for i := int32(0); i < nprocs; i++ { 33 pp := allp[i] 34 if pp == nil { 35 pp = new(p) 36 pp.id = i 37 pp.status = _Pgcstop 38 pp.sudogcache = pp.sudogbuf[:0] 39 for i := range pp.deferpool { 40 pp.deferpool[i] = pp.deferpoolbuf[i][:0] 41 } 42 pp.wbBuf.reset() 43 // allp是一个slice,直接将新增的p放到对应的索引下面就ok了 44 atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) 45 } 46 if pp.mcache == nil { 47 // 初始化时,old=0,第一个新建的p给当前的m使用 48 if old == 0 && i == 0 { 49 if getg().m.mcache == nil { 50 throw("missing mcache?") 51 } 52 pp.mcache = getg().m.mcache // bootstrap 53 } else { 54 // 为p分配内存 55 pp.mcache = allocmcache() 56 } 57 } 58 } 59 60 // free unused P's 61 // 释放掉多余的p,当新设置的p的数量,比原先设定的p的数量少的时候,会走到这个流程 62 // 通过 runtime.GOMAXPROCS 就可以动态的修改nprocs 63 for i := nprocs; i < old; i++ { 64 p := allp[i] 65 // move all runnable goroutines to the global queue 66 // 把当前p的运行队列里的g转移到全局的g的队列 67 for p.runqhead != p.runqtail { 68 // pop from tail of local queue 69 p.runqtail-- 70 gp := p.runq[p.runqtail%uint32(len(p.runq))].ptr() 71 // push onto head of global queue 72 globrunqputhead(gp) 73 } 74 // 把runnext里的g也转移到全局队列 75 if p.runnext != 0 { 76 globrunqputhead(p.runnext.ptr()) 77 p.runnext = 0 78 } 79 // if there's a background worker, make it runnable and put 80 // it on the global queue so it can clean itself up 81 // 如果有gc worker的话,修改g的状态,然后再把它放到全局队列中 82 if gp := p.gcBgMarkWorker.ptr(); gp != nil { 83 casgstatus(gp, _Gwaiting, _Grunnable) 84 globrunqput(gp) 85 // This assignment doesn't race because the 86 // world is stopped. 87 p.gcBgMarkWorker.set(nil) 88 } 89 // sudoig的buf和cache,以及deferpool全部清空 90 for i := range p.sudogbuf { 91 p.sudogbuf[i] = nil 92 } 93 p.sudogcache = p.sudogbuf[:0] 94 for i := range p.deferpool { 95 for j := range p.deferpoolbuf[i] { 96 p.deferpoolbuf[i][j] = nil 97 } 98 p.deferpool[i] = p.deferpoolbuf[i][:0] 99 } 100 // 释放掉当前p的mcache 101 freemcache(p.mcache) 102 p.mcache = nil 103 // 把当前p的gfree转移到全局 104 gfpurge(p) 105 // 修改p的状态,让他自生自灭去了 106 p.status = _Pdead 107 // 无法释放P本身,因为它可以被syscall中的M引用 108 } 109 110 // Trim allp. 111 if int32(len(allp)) != nprocs { 112 lock(&allpLock) 113 allp = allp[:nprocs] 114 unlock(&allpLock) 115 } 116 // 判断当前g是否有p,有的话更改当前使用的p的状态,继续使用 117 _g_ := getg() 118 if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs { 119 // continue to use the current P 120 _g_.m.p.ptr().status = _Prunning 121 } else { 122 // release the current P and acquire allp[0] 123 // 如果当前g有p,但是拥有的是已经释放的p,则不再使用这个p,重新分配 124 if _g_.m.p != 0 { 125 _g_.m.p.ptr().m = 0 126 } 127 // 分配allp[0]给当前g使用 128 _g_.m.p = 0 129 _g_.m.mcache = nil 130 p := allp[0] 131 p.m = 0 132 p.status = _Pidle 133 // 将p m g绑定,并把m.mcache指向p.mcache,并修改p的状态为_Prunning 134 acquirep(p) 135 } 136 var runnablePs *p 137 for i := nprocs - 1; i >= 0; i-- { 138 p := allp[i] 139 if _g_.m.p.ptr() == p { 140 continue 141 } 142 p.status = _Pidle 143 // 根据 runqempty 来判断当前p的g运行队列是否为空 144 if runqempty(p) { 145 // g运行队列为空的p,放到 sched的pidle队列里面 146 pidleput(p) 147 } else { 148 // g 运行队列不为空的p,组成一个可运行队列,并最后返回 149 p.m.set(mget()) 150 p.link.set(runnablePs) 151 runnablePs = p 152 } 153 } 154 stealOrder.reset(uint32(nprocs)) 155 var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32 156 atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs)) 157 return runnablePs 158 }
- runqempty: 根据 p.runqtail == p.runqhead 和 p.runnext 来判断有没有待运行的g
- pidleput: 将当前的p设置为 sched.pidle,然后根据p.link将空闲p串联起来,可参考上图allm的链表示意图
1.2 任务
只需要使用 go func 就可以创建一个goroutine,编译器会将go func 翻译成 newproc 进行调用,新建的任务是如何调用的呢,下面从创建开始进行源码跟踪
newproc
newproc 函数获取了参数和当前g的pc信息,并通过g0调用newproc1去真正的执行创建或获取可用的g:
1 func newproc(siz int32, fn *funcval) { 2 // 获取第一参数地址 3 argp := add(unsafe.Pointer(&fn), sys.PtrSize) 4 // 获取当前执行的g 5 gp := getg() 6 // 获取当前g的pc 7 pc := getcallerpc() 8 systemstack(func() { 9 // 使用g0去执行newproc1函数 10 newproc1(fn, (*uint8)(argp), siz, gp, pc) 11 }) 12 }
newproc1
newporc1 的作用就是创建或者获取一个空的g,并初始化这个g,并尝试寻找一个p和m去执行g。
1 func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) { 2 _g_ := getg() 3 4 if fn == nil { 5 _g_.m.throwing = -1 // 不要转储完整的堆栈 6 throw("go of nil func value") 7 } 8 // 加锁禁止被抢占 9 _g_.m.locks++ // 禁用抢占,因为它可以将p保留在本地变量中 10 siz := narg 11 siz = (siz + 7) &^ 7 12 13 // We could allocate a larger initial stack if necessary. 14 // Not worth it: this is almost always an error. 15 // 4*sizeof(uintreg): extra space added below 16 // sizeof(uintreg): caller's LR (arm) or return address (x86, in gostartcall). 17 18 // 如果参数过多,则直接抛出异常,栈大小是2k 19 if siz >= _StackMin-4*sys.RegSize-sys.RegSize { 20 throw("newproc: function arguments too large for new goroutine") 21 } 22 23 _p_ := _g_.m.p.ptr() 24 // 尝试获取一个空闲的g,如果获取不到,则新建一个,并添加到allg里面 25 // gfget首先会尝试从p本地获取空闲的g,如果本地没有的话,则从全局获取一堆平衡到本地p 26 newg := gfget(_p_) 27 if newg == nil { 28 newg = malg(_StackMin) 29 casgstatus(newg, _Gidle, _Gdead) 30 // 新建的g,添加到全局的 allg里面,allg是一个slice, append进去即可 31 allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. 32 } 33 // 判断获取的g的栈是否正常 34 if newg.stack.hi == 0 { 35 throw("newproc1: newg missing stack") 36 } 37 // 判断g的状态是否正常 38 if readgstatus(newg) != _Gdead { 39 throw("newproc1: new g is not Gdead") 40 } 41 // 预留一点空间,防止读取超出一点点 42 totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // 多余的空间,以防读取超出框架 43 // 空间大小进行对齐 44 totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign 45 sp := newg.stack.hi - totalSize 46 spArg := sp 47 // usesLr 为0,这里不执行 48 if usesLR { 49 // caller's LR 50 *(*uintptr)(unsafe.Pointer(sp)) = 0 51 prepGoExitFrame(sp) 52 spArg += sys.MinFrameSize 53 } 54 if narg > 0 { 55 // 将参数拷贝入栈 56 memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg)) 57 // ... 省略 ... 58 } 59 // 初始化用于保存现场的区域及初始化基本状态 60 memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) 61 newg.sched.sp = sp 62 newg.stktopsp = sp 63 // 这里保存了goexit的地址,在用户函数执行完成后,会根据pc来执行goexit 64 newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function 65 newg.sched.g = guintptr(unsafe.Pointer(newg)) 66 // 这里调整 sched 信息,pc = goexit的地址 67 gostartcallfn(&newg.sched, fn) 68 newg.gopc = callerpc 69 newg.ancestors = saveAncestors(callergp) 70 newg.startpc = fn.fn 71 if _g_.m.curg != nil { 72 newg.labels = _g_.m.curg.labels 73 } 74 if isSystemGoroutine(newg) { 75 atomic.Xadd(&sched.ngsys, +1) 76 } 77 newg.gcscanvalid = false 78 casgstatus(newg, _Gdead, _Grunnable) 79 // 如果p缓存的goid已经用完,本地再从sched批量获取一点 80 if _p_.goidcache == _p_.goidcacheend { 81 / Sched.goidgen是最后分配的ID,此批次必须为[sched.goidgen + 1,sched.goidgen + GoidCacheBatch]。 82 //在启动时sched.goidgen = 0,因此主goroutine接收goid = 1。 83 _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch) 84 _p_.goidcache -= _GoidCacheBatch - 1 85 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch 86 } 87 // 分配goid 88 newg.goid = int64(_p_.goidcache) 89 _p_.goidcache++ 90 // 把新的g放到 p 的可运行g队列中 91 runqput(_p_, newg, true) 92 // 判断是否有空闲p,且是否需要唤醒一个m来执行g 93 if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted { 94 wakep() 95 } 96 _g_.m.locks-- 97 if _g_.m.locks == 0 && _g_.preempt { // 恢复抢占请求,以防我们在新堆栈中清除了它 98 _g_.stackguard0 = stackPreempt 99 } 100 }
gfget
这个函数就是看一下p有没有空闲的g,没有则去全局的freeg队列查找,这里就涉及了p本地和全局平衡的一个交互了:
1 func gfget(_p_ *p) *g { 2 retry: 3 gp := _p_.gfree 4 // 本地的g队列为空,且全局队列不为空,则从全局队列一次获取至多32个下来,如果全局队列不够就算了 5 if gp == nil && (sched.gfreeStack != nil || sched.gfreeNoStack != nil) { 6 lock(&sched.gflock) 7 for _p_.gfreecnt < 32 { 8 if sched.gfreeStack != nil { 9 // 优先选择带堆栈的Gs。 10 gp = sched.gfreeStack 11 sched.gfreeStack = gp.schedlink.ptr() 12 } else if sched.gfreeNoStack != nil { 13 gp = sched.gfreeNoStack 14 sched.gfreeNoStack = gp.schedlink.ptr() 15 } else { 16 break 17 } 18 _p_.gfreecnt++ 19 sched.ngfree-- 20 gp.schedlink.set(_p_.gfree) 21 _p_.gfree = gp 22 } 23 // 已经从全局拿了g了,再去从头开始判断 24 unlock(&sched.gflock) 25 goto retry 26 } 27 // 如果拿到了g,则判断g是否有栈,没有栈就分配 28 // 栈的分配跟内存分配差不多,首先创建几个固定大小的栈的数组,然后到指定大小的数组里面去分配就ok了,过大则直接全局分配 29 if gp != nil { 30 _p_.gfree = gp.schedlink.ptr() 31 _p_.gfreecnt-- 32 if gp.stack.lo == 0 { 33 // 堆栈已在gfput中释放,分配一个新的。 34 systemstack(func() { 35 gp.stack = stackalloc(_FixedStack) 36 }) 37 gp.stackguard0 = gp.stack.lo + _StackGuard 38 } else { 39 // ... 省略 ... 40 } 41 } 42 // 注意: 如果全局没有g,p也没有g,则返回的gp还是nil 43 return gp 44 }
runqput
runqput会把g放到p的本地队列或者p.runnext,如果p的本地队列过长,则把g到全局队列,同时平衡p本地队列的一半到全局
1 func runqput(_p_ *p, gp *g, next bool) { 2 if randomizeScheduler && next && fastrand()%2 == 0 { 3 next = false 4 } 5 // 如果next为true,则放入到p.runnext里面,并把原先runnext的g交换出来 6 if next { 7 retryNext: 8 oldnext := _p_.runnext 9 if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) { 10 goto retryNext 11 } 12 if oldnext == 0 { 13 return 14 } 15 // Kick the old runnext out to the regular run queue. 16 gp = oldnext.ptr() 17 } 18 19 retry: 20 h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with consumers 21 t := _p_.runqtail 22 // 判断p的队列的长度是否超了, runq是一个长度为256的数组,超出的话就会放到全局队列了 23 if t-h < uint32(len(_p_.runq)) { 24 _p_.runq[t%uint32(len(_p_.runq))].set(gp) 25 atomic.Store(&_p_.runqtail, t+1) // store-release, makes the item available for consumption 26 return 27 } 28 // 把g放到全局队列 29 if runqputslow(_p_, gp, h, t) { 30 return 31 } 32 // the queue is not full, now the put above must succeed 33 goto retry 34 }
runqputslow
1 func runqputslow(_p_ *p, gp *g, h, t uint32) bool { 2 var batch [len(_p_.runq)/2 + 1]*g 3 4 // 首先,从本地队列中抓取一批。 5 n := t - h 6 n = n / 2 7 if n != uint32(len(_p_.runq)/2) { 8 throw("runqputslow: queue is not full") 9 } 10 // 获取p后面的一半 11 for i := uint32(0); i < n; i++ { 12 batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr() 13 } 14 if !atomic.Cas(&_p_.runqhead, h, h+n) { // cas-release, commits consume 15 return false 16 } 17 batch[n] = gp 18 19 // 链接goroutines。 20 for i := uint32(0); i < n; i++ { 21 batch[i].schedlink.set(batch[i+1]) 22 } 23 24 // 现在将批次放入全局队列。 25 // 放到全局队列队尾 26 lock(&sched.lock) 27 globrunqputbatch(batch[0], batch[n], int32(n+1)) 28 unlock(&sched.lock) 29 return true 30 }
新建任务至此基本结束,创建完成任务后,等待调度执行就好了,从上面可以看出,任务的优先级是 p.runnext > p.runq > sched.runq
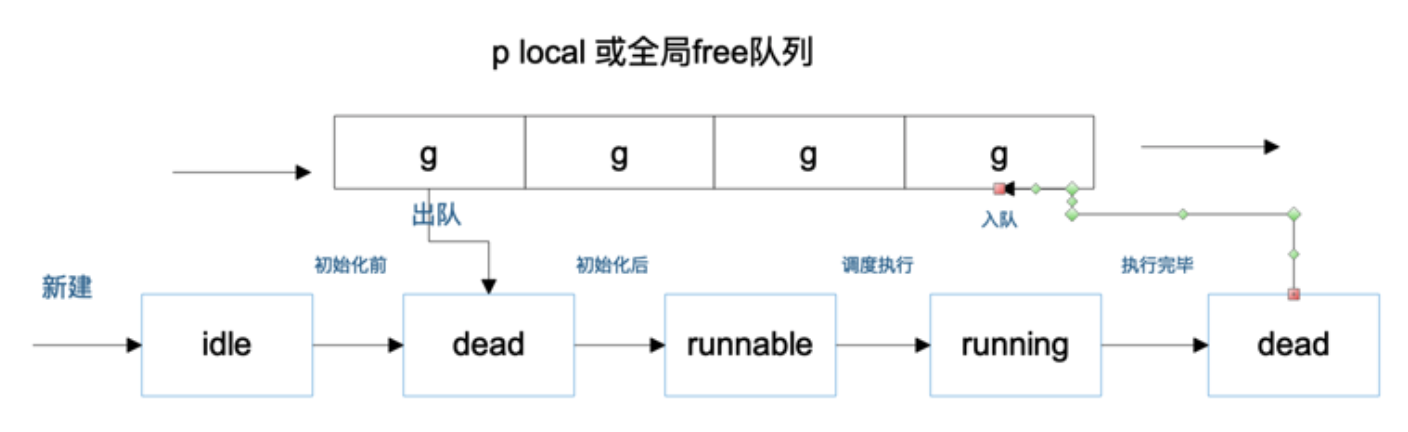
g从创建到执行结束并放入free队列中的状态转换大致如下图所示:
wakep
当 newproc1创建完任务后,会尝试唤醒m来执行任务
1 func wakep() { 2 // 对旋转线程持保守态度。 3 // 一次应该只有一个m在spining,否则就退出 4 if !atomic.Cas(&sched.nmspinning, 0, 1) { 5 return 6 } 7 // 调用startm来执行 8 startm(nil, true) 9 }
startm
调度m或者创建m来运行p,如果p==nil,就会尝试获取一个空闲p,p的队列中有g,拿到p后才能拿到g
1 func startm(_p_ *p, spinning bool) { 2 lock(&sched.lock) 3 if _p_ == nil { 4 // 如果没有指定p, 则从sched.pidle获取空闲的p 5 _p_ = pidleget() 6 if _p_ == nil { 7 unlock(&sched.lock) 8 // 如果没有获取到p,重置nmspinning 9 if spinning { 10 // The caller增加了nmspinning,但是没有空闲的Ps,因此,只需取消增量并放弃就可以了。 11 if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 { 12 throw("startm: negative nmspinning") 13 } 14 } 15 return 16 } 17 } 18 // 首先尝试从 sched.midle获取一个空闲的m 19 mp := mget() 20 unlock(&sched.lock) 21 if mp == nil { 22 // 如果获取不到空闲的m,则创建一个 mspining = true的m,并将p绑定到m上,直接返回 23 var fn func() 24 if spinning { 25 // The caller incremented nmspinning, so set m.spinning in the new M. 26 fn = mspinning 27 } 28 newm(fn, _p_) 29 return 30 } 31 // 判断获取到的空闲m是否是spining状态 32 if mp.spinning { 33 throw("startm: m is spinning") 34 } 35 // 判断获取到的m是否有p 36 if mp.nextp != 0 { 37 throw("startm: m has p") 38 } 39 if spinning && !runqempty(_p_) { 40 throw("startm: p has runnable gs") 41 } 42 // The caller incremented nmspinning, so set m.spinning in the new M. 43 // 调用函数的父函数已经增加了nmspinning, 这里只需要设置m.spining就ok了,同时把p绑上来 44 mp.spinning = spinning 45 mp.nextp.set(_p_) 46 // 唤醒m 47 notewakeup(&mp.park) 48 }
newm
newm 通过allocm函数来创建新m
1 func newm(fn func(), _p_ *p) { 2 // 新建一个m 3 mp := allocm(_p_, fn) 4 // 为这个新建的m绑定指定的p 5 mp.nextp.set(_p_) 6 // ... 省略 ... 7 // 创建系统线程 8 newm1(mp) 9 }
new1m
1 func newm1(mp *m) { 2 // runtime cgo包会把iscgo设置为true,这里不分析 3 if iscgo { 4 var ts cgothreadstart 5 if _cgo_thread_start == nil { 6 throw("_cgo_thread_start missing") 7 } 8 ts.g.set(mp.g0) 9 ts.tls = (*uint64)(unsafe.Pointer(&mp.tls[0])) 10 ts.fn = unsafe.Pointer(funcPC(mstart)) 11 if msanenabled { 12 msanwrite(unsafe.Pointer(&ts), unsafe.Sizeof(ts)) 13 } 14 execLock.rlock() //防止进程克隆。 15 asmcgocall(_cgo_thread_start, unsafe.Pointer(&ts)) 16 execLock.runlock() 17 return 18 } 19 execLock.rlock() // Prevent process clone. 20 newosproc(mp) 21 execLock.runlock() 22 }
newosproc
newosproc 创建一个新的系统线程,并执行mstart_stub函数,之后调用mstart函数进入调度,后面在执行流程会分析
1 func newosproc(mp *m) { 2 stk := unsafe.Pointer(mp.g0.stack.hi) 3 //初始化属性对象。 4 var attr pthreadattr 5 var err int32 6 err = pthread_attr_init(&attr) 7 8 // 最后,创建线程。它从mstart_stub开始,它执行一些低级操作设置,然后调用mstart。 9 var oset sigset 10 sigprocmask(_SIG_SETMASK, &sigset_all, &oset) 11 // 创建线程,并传入启动启动函数 mstart_stub, mstart_stub 之后调用mstart 12 err = pthread_create(&attr, funcPC(mstart_stub), unsafe.Pointer(mp)) 13 sigprocmask(_SIG_SETMASK, &oset, nil) 14 if err != 0 { 15 write(2, unsafe.Pointer(&failthreadcreate[0]), int32(len(failthreadcreate))) 16 exit(1) 17 } 18 }
allocm
allocm这里首先会释放 sched的freem,然后再去创建m,并初始化m:
1 func allocm(_p_ *p, fn func()) *m { 2 _g_ := getg() 3 _g_.m.locks++ // 禁用GC,因为可以从sysmon调用它 4 if _g_.m.p == 0 { 5 acquirep(_p_) // 在此函数中临时为mallocs借用p 6 } 7 8 // 释放免费的M列表。我们需要在某个地方这样做,这样可以释放我们可以使用的堆栈。 9 // 首先释放掉freem列表 10 if sched.freem != nil { 11 lock(&sched.lock) 12 var newList *m 13 for freem := sched.freem; freem != nil; { 14 if freem.freeWait != 0 { 15 next := freem.freelink 16 freem.freelink = newList 17 newList = freem 18 freem = next 19 continue 20 } 21 stackfree(freem.g0.stack) 22 freem = freem.freelink 23 } 24 sched.freem = newList 25 unlock(&sched.lock) 26 } 27 28 mp := new(m) 29 // 启动函数,根据startm调用来看,这个fn就是 mspinning, 会将m.mspinning设置为true 30 mp.mstartfn = fn 31 // 初始化m,上面已经分析了 32 mcommoninit(mp) 33 //如果是cgo或Solaris或Darwin,pthread_create将使我们成为堆栈。 34 // Windows和Plan 9将在操作系统堆栈上安排预定的堆栈。 35 // 为新的m创建g0 36 if iscgo || GOOS == "solaris" || GOOS == "windows" || GOOS == "plan9" || GOOS == "darwin" { 37 mp.g0 = malg(-1) 38 } else { 39 mp.g0 = malg(8192 * sys.StackGuardMultiplier) 40 } 41 // 为mp的g0绑定自己 42 mp.g0.m = mp 43 // 如果当前的m所绑定的是参数传递过来的p,解除绑定,因为参数传递过来的p稍后要绑定新建的m 44 if _p_ == _g_.m.p.ptr() { 45 releasep() 46 } 47 48 _g_.m.locks-- 49 if _g_.m.locks == 0 && _g_.preempt { // 恢复抢占请求,以防我们在新堆栈中清除了它 50 _g_.stackguard0 = stackPreempt 51 } 52 53 return mp 54 }
notewakeup
1 func notewakeup(n *note) { 2 var v uintptr 3 // 设置m 为locked 4 for { 5 v = atomic.Loaduintptr(&n.key) 6 if atomic.Casuintptr(&n.key, v, locked) { 7 break 8 } 9 } 10 11 // Successfully set waitm to locked. 12 // What was it before? 13 // 根据m的原先的状态,来判断后面的执行流程,0则直接返回,locked则冲突,否则认为是wating,唤醒 14 switch { 15 case v == 0: 16 // Nothing was waiting. Done. 17 case v == locked: 18 // Two notewakeups! Not allowed. 19 throw("notewakeup - double wakeup") 20 default: 21 // Must be the waiting m. Wake it up. 22 // 唤醒系统线程 23 semawakeup((*m)(unsafe.Pointer(v))) 24 } 25 }
1.3 执行
在startm函数分析的过程中会,可以看到,有两种获取m的方式
- 新建: 这时候执行newm1下的newosproc,同时最终调用mstart来执行调度
- 唤醒空闲m:从休眠的地方继续执行
m执行g有两个起点,一个是线程启动函数 mstart, 另一个则是休眠被唤醒后的调度schedule了,我们从头开始,也就是mstart, mstart 走到最后也是 schedule 调度。
mstart
1 func mstart() { 2 _g_ := getg() 3 4 osStack := _g_.stack.lo == 0 5 if osStack { 6 //从系统堆栈初始化堆栈边界。 7 // Cgo可能在stack.hi中具有左堆栈大小。 8 // minit可能会更新堆栈边界。 9 10 // 从系统堆栈上直接划出所需的范围 11 size := _g_.stack.hi 12 if size == 0 { 13 size = 8192 * sys.StackGuardMultiplier 14 } 15 _g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size))) 16 _g_.stack.lo = _g_.stack.hi - size + 1024 17 } 18 //初始化堆栈保护,以便我们可以开始调用Go和C函数都具有堆栈增长序言。 19 _g_.stackguard0 = _g_.stack.lo + _StackGuard 20 _g_.stackguard1 = _g_.stackguard0 21 // 调用mstart1来处理 22 mstart1() 23 24 // Exit this thread. 25 if GOOS == "windows" || GOOS == "solaris" || GOOS == "plan9" || GOOS == "darwin" { 26 // Window,Solaris,Darwin和Plan 9总是系统分配堆栈,但将其放在mstart之前的_g_.stack中,因此上述逻辑尚未设置osStack。 27 osStack = true 28 } 29 // 退出m,正常情况下mstart1调用schedule() 时,是不再返回的,所以,不用担心系统线程的频繁创建退出 30 mexit(osStack) 31 }
mstart1
1 func mstart1() { 2 _g_ := getg() 3 4 if _g_ != _g_.m.g0 { 5 throw("bad runtime·mstart") 6 } 7 8 //记录调用方,以用作mcall和用于终止线程。 9 //在调用schedule之后,我们再也不会回到mstart1了,以便其他调用可以重用当前帧。 10 11 // 保存调用者的pc sp等信息 12 save(getcallerpc(), getcallersp()) 13 asminit() 14 // 初始化m的sigal的栈和mask 15 minit() 16 17 //安装信号处理程序; 在minit之后,minit可以准备线程以处理信号。 18 19 // 安装sigal处理器 20 if _g_.m == &m0 { 21 mstartm0() 22 } 23 // 如果设置了mstartfn,就先执行这个 24 if fn := _g_.m.mstartfn; fn != nil { 25 fn() 26 } 27 28 if _g_.m.helpgc != 0 { 29 _g_.m.helpgc = 0 30 stopm() 31 } else if _g_.m != &m0 { 32 // 获取nextp 33 acquirep(_g_.m.nextp.ptr()) 34 _g_.m.nextp = 0 35 } 36 schedule() 37 }
acquirep1
1 func acquirep1(_p_ *p) { 2 _g_ := getg() 3 4 // 让m p互相绑定 5 _g_.m.p.set(_p_) 6 _p_.m.set(_g_.m) 7 _p_.status = _Prunning 8 }
schedule
开始进入到调度函数了,这是一个由schedule、execute、goroutine fn、goexit构成的逻辑循环,就算m是唤醒后,也是从设置的断点开始执行。
schedule函数在runtime需要进行调度时执行,为当前的P寻找一个可以运行的G并执行它,寻找顺序如下:
- 1) 调用runqget函数来从P自己的runnable G队列中得到一个可以执行的G;
- 2) 如果1)失败,则调用findrunnable函数去寻找一个可以执行的G;
- 3) 如果2)也没有得到可以执行的G,那么结束调度,从上次的现场继续执行。
- 4) 注意)//偶尔会先检查一次全局可运行队列,以确保公平性。否则,两个goroutine可以完全占用本地runqueue。 通过 schedtick计数 %61来保证
1 func schedule() { 2 _g_ := getg() 3 4 if _g_.m.locks != 0 { 5 throw("schedule: holding locks") 6 } 7 // 如果有lockg,停止执行当前的m 8 if _g_.m.lockedg != 0 { 9 // 解除lockedm的锁定,并执行当前g 10 stoplockedm() 11 execute(_g_.m.lockedg.ptr(), false) // Never returns. 12 } 13 14 //我们不应该将正在执行cgo调用的g排开,因为cgo调用正在使用m的g0堆栈。 15 if _g_.m.incgo { 16 throw("schedule: in cgo") 17 } 18 19 top: 20 // gc 等待 21 if sched.gcwaiting != 0 { 22 gcstopm() 23 goto top 24 } 25 26 var gp *g 27 var inheritTime bool 28 29 if gp == nil { 30 //偶尔检查全局可运行队列以确保公平。 31 //否则,两个goroutine可以完全占据本地运行队列 通过不断重生彼此。 32 // 为了保证公平,每隔61次,从全局队列上获取g 33 if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { 34 lock(&sched.lock) 35 gp = globrunqget(_g_.m.p.ptr(), 1) 36 unlock(&sched.lock) 37 } 38 } 39 if gp == nil { 40 // 全局队列上获取不到待运行的g,则从p local队列中获取 41 gp, inheritTime = runqget(_g_.m.p.ptr()) 42 if gp != nil && _g_.m.spinning { 43 throw("schedule: spinning with local work") 44 } 45 } 46 if gp == nil { 47 // 如果p local获取不到待运行g,则开始查找,这个函数会从 全局 io poll, p locl和其他p local获取待运行的g,后面详细分析 48 gp, inheritTime = findrunnable() // blocks until work is available 49 } 50 51 //此线程将运行goroutine并且不再旋转,因此,如果标记为正在旋转,则需要立即重置它,并可能开始一个新的旋转M。 52 if _g_.m.spinning { 53 // 如果m是自旋状态,取消自旋 54 resetspinning() 55 } 56 57 if gp.lockedm != 0 { 58 //将自己的p交给锁定的m,然后阻止等待新的p。 59 // 如果g有lockedm,则休眠上交p,休眠m,等待新的m,唤醒后从这里开始执行,跳转到top 60 startlockedm(gp) 61 goto top 62 } 63 // 开始执行这个g 64 execute(gp, inheritTime) 65 }
因为当前的m绑定了lockedg,而当前g不是指定的lockedg,所以这个m不能执行,函数 stoplockedm() 解除lockedm的锁定,上交当前m绑定的p,并且休眠m直到调度lockedg。这个函数首先会释放当前P ->release() 然后通过 handoffp() 函数调用startm函开始调度。handoffp会判断有没有正在寻找p的m以及有没有空闲的p,如果有,尝试调用startm进行调度,如果全局队列运行g队列不为空,尝试使用startm进行调度。
handoffp函数将P从系统调用或阻塞的M中传递出去,如果P还有runnable G队列,那么新开一个M,调用startm函数,新开的M不空旋。
execute()函数就开始执行g的代码了:
1 func execute(gp *g, inheritTime bool) { 2 _g_ := getg() 3 // 更改g的状态,并不允许抢占 4 casgstatus(gp, _Grunnable, _Grunning) 5 gp.waitsince = 0 6 gp.preempt = false 7 gp.stackguard0 = gp.stack.lo + _StackGuard 8 if !inheritTime { 9 // 调度计数 10 _g_.m.p.ptr().schedtick++ 11 } 12 _g_.m.curg = gp 13 gp.m = _g_.m 14 // 开始执行g的代码了 15 gogo(&gp.sched) 16 }
gogo函数承载的作用就是切换到g的栈,开始执行g的代码,gogo执行完函数后,是怎么再次进入调度呢?回到前面newproc1函数的L63 newg.sched.pc = funcPC(goexit) + sys.PCQuantum ,这里保存了pc的质地为goexit的地址,所以当执行完用户代码后,就会进入 goexit 函数。
goexit0
goexit 在汇编层面就是调用 runtime.goexit1,而goexit1通过 mcall 调用了goexit0 所以这里直接分析了goexit0。goexit0 重置g的状态,并重新进行调度,这样就调度就又回到了schedule() 了,开始循环往复的调度。
1 func goexit0(gp *g) { 2 _g_ := getg() 3 // 转换g的状态为dead,以放回空闲列表 4 casgstatus(gp, _Grunning, _Gdead) 5 if isSystemGoroutine(gp) { 6 atomic.Xadd(&sched.ngsys, -1) 7 } 8 // 清空g的状态 9 gp.m = nil 10 locked := gp.lockedm != 0 11 gp.lockedm = 0 12 _g_.m.lockedg = 0 13 gp.paniconfault = false 14 gp._defer = nil // 应该是真实的,但以防万一。 15 gp._panic = nil // 恐慌期间,对于Goexit不为零。指向堆栈分配的数据。 16 gp.writebuf = nil 17 gp.waitreason = 0 18 gp.param = nil 19 gp.labels = nil 20 gp.timer = nil 21 22 注意,gp的堆栈扫描现在“有效”,因为它没有堆栈。 23 gp.gcscanvalid = true 24 dropg() 25 26 // 把g放回空闲列表,以备复用 27 gfput(_g_.m.p.ptr(), gp) 28 // 再次进入调度循环 29 schedule() 30 }
goexit函数是当G退出时调用的。这个函数对G进行一些设置后,将它放入free G列表中,供以后复用,之后调用schedule函数调度。
至此,单次调度结束,再次进入调度,循环往复。
findrunnable() 寻找一个可运行的g,过程:
- 从p自己的local队列中获取可运行的g
- 从全局队列中获取可运行的g
- 从netpoll中获取一个已经准备好的g
- 从其他p的local队列中获取可运行的g,随机偷取p的runnext,有点任性
- 无论如何都获取不到的话,就stopm了
stopm
stop会把当前m放到空闲列表里面,同时绑定m.nextp 与 m
1 func stopm() { 2 _g_ := getg() 3 retry: 4 lock(&sched.lock) 5 // 把当前m放到sched.midle 的空闲列表里 6 mput(_g_.m) 7 unlock(&sched.lock) 8 // 休眠,等待被唤醒 9 notesleep(&_g_.m.park) 10 noteclear(&_g_.m.park) 11 // 绑定p 12 acquirep(_g_.m.nextp.ptr()) 13 _g_.m.nextp = 0 14 }
1.4 监控
sysmon
go的监控是依靠函数 sysmon 来完成的,监控主要做一下几件事:
- 释放闲置超过5分钟的span物理内存
- 如果超过两分钟没有执行垃圾回收,则强制执行
- 将长时间未处理的netpoll结果添加到任务队列
- 向长时间运行的g进行抢占
- 收回因为syscall而长时间阻塞的p
监控线程并不是时刻在运行的,监控线程首次休眠20us,每次执行完后,增加一倍的休眠时间,但是最多休眠10ms。
1 func sysmon() { 2 lock(&sched.lock) 3 sched.nmsys++ 4 checkdead() 5 unlock(&sched.lock) 6 7 // 如果垃圾回收后5分钟内未使用堆范围,我们将其交还给操作系统。 8 scavengelimit := int64(5 * 60 * 1e9) 9 10 if debug.scavenge > 0 { 11 // 大量测试。 12 forcegcperiod = 10 * 1e6 13 scavengelimit = 20 * 1e6 14 } 15 16 lastscavenge := nanotime() 17 nscavenge := 0 18 19 lasttrace := int64(0) 20 idle := 0 // 我们没有连续唤醒多少个周期。 21 delay := uint32(0) 22 for { 23 // 判断当前循环,应该休眠的时间 24 if idle == 0 { // start with 20us sleep... 25 delay = 20 26 } else if idle > 50 { // start doubling the sleep after 1ms... 27 delay *= 2 28 } 29 if delay > 10*1000 { // up to 10ms 30 delay = 10 * 1000 31 } 32 usleep(delay) 33 // STW时休眠sysmon 34 if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) { 35 lock(&sched.lock) 36 if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) { 37 atomic.Store(&sched.sysmonwait, 1) 38 unlock(&sched.lock) 39 // 使唤醒时间足够小,采样正确。 40 maxsleep := forcegcperiod / 2 41 if scavengelimit < forcegcperiod { 42 maxsleep = scavengelimit / 2 43 } 44 shouldRelax := true 45 if osRelaxMinNS > 0 { 46 next := timeSleepUntil() 47 now := nanotime() 48 if next-now < osRelaxMinNS { 49 shouldRelax = false 50 } 51 } 52 if shouldRelax { 53 osRelax(true) 54 } 55 // 进行休眠 56 notetsleep(&sched.sysmonnote, maxsleep) 57 if shouldRelax { 58 osRelax(false) 59 } 60 lock(&sched.lock) 61 // 唤醒后,清除休眠状态,继续执行 62 atomic.Store(&sched.sysmonwait, 0) 63 noteclear(&sched.sysmonnote) 64 idle = 0 65 delay = 20 66 } 67 unlock(&sched.lock) 68 } 69 // 必要时触发libc拦截器 70 if *cgo_yield != nil { 71 asmcgocall(*cgo_yield, nil) 72 } 73 // poll network if not polled for more than 10ms 74 lastpoll := int64(atomic.Load64(&sched.lastpoll)) 75 now := nanotime() 76 // 如果netpoll不为空,每隔10ms检查一下是否有ok的 77 if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { 78 atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) 79 // 返回了已经获取到结果的goroutine的列表 80 gp := netpoll(false) // non-blocking - returns list of goroutines 81 if gp != nil { 82 incidlelocked(-1) 83 // 把获取到的g的列表加入到全局待运行队列中 84 injectglist(gp) 85 incidlelocked(1) 86 } 87 } 88 // 重新获取系统调用中阻止的P,并抢占长期运行的G 89 // 抢夺syscall长时间阻塞的p和长时间运行的g 90 if retake(now) != 0 { 91 idle = 0 92 } else { 93 idle++ 94 } 95 // check if we need to force a GC 96 // 通过gcTrigger.test() 函数判断是否超过设定的强制触发gc的时间间隔, 97 if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 { 98 lock(&forcegc.lock) 99 forcegc.idle = 0 100 forcegc.g.schedlink = 0 101 // 把gc的g加入待运行队列,等待调度运行 102 injectglist(forcegc.g) 103 unlock(&forcegc.lock) 104 } 105 // scavenge heap once in a while 106 // 判断是否有5分钟未使用的span,有的话,归还给系统 107 if lastscavenge+scavengelimit/2 < now { 108 mheap_.scavenge(int32(nscavenge), uint64(now), uint64(scavengelimit)) 109 lastscavenge = now 110 nscavenge++ 111 } 112 if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now { 113 lasttrace = now 114 schedtrace(debug.scheddetail > 0) 115 } 116 } 117 }
sysmon函数是Go runtime启动时创建的,负责监控所有goroutine的状态,判断是否需要GC,进行netpoll等操作。sysmon函数中会调用retake函数进行抢占式调度。跟前面添加p和m的逻辑差不多,下面看如何抢占:
retake
1 const forcePreemptNS = 10 * 1000 * 1000 // 10ms 2 3 func retake(now int64) uint32 { 4 n := 0 5 //防止allp slice更改。此锁将完全,没有竞争,除非我们已经停止了世界。 6 lock(&allpLock) 7 //我们不能对allp使用范围循环,因为我们可能暂时删除allpLock。因此,我们需要重新获取每次循环时分配。 8 for i := 0; i < len(allp); i++ { 9 _p_ := allp[i] 10 if _p_ == nil { 11 //如果procresize增加了,就会发生这种情况 allp,但尚未创建新的P。 12 continue 13 } 14 pd := &_p_.sysmontick 15 s := _p_.status 16 if s == _Psyscall { 17 //如果系统调用中的P超过1个sysmon滴答声(至少20us),则将其取回。 18 // pd.syscalltick 即 _p_.sysmontick.syscalltick 只有在sysmon的时候会更新,而 _p_.syscalltick 则会每次都更新,所以,当syscall之后,第一个sysmon检测到的时候并不会抢占,而是第二次开始才会抢占,中间间隔至少有20us,最多会有10ms 19 t := int64(_p_.syscalltick) 20 if int64(pd.syscalltick) != t { 21 pd.syscalltick = uint32(t) 22 pd.syscallwhen = now 23 continue 24 } 25 //一方面,如果您没有其他工作要做,我们不想重新获得P,但另一方面,我们希望最终将它们重新收录,因为它们可以防止sysmon线程进入深度睡眠状态。 26 27 // 是否有空p,有寻找p的m,以及当前的p在syscall之后,有没有超过10ms 28 if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now { 29 continue 30 } 31 //删除allpLock,以便我们使用sched.lock。 32 //解锁(&allpLock),需要减少空闲锁定M的数量 33 //(假设还有一个正在运行)。 34 //否则,我们从中夺回的M可以退出系统调用,递增nmidle并报告deadlock.sleep。 35 incidlelocked(-1) 36 // 抢占p,把p的状态转为idle状态 37 if atomic.Cas(&_p_.status, s, _Pidle) { 38 if trace.enabled { 39 traceGoSysBlock(_p_) 40 traceProcStop(_p_) 41 } 42 n++ 43 _p_.syscalltick++ 44 // 把当前p移交出去,上面已经分析过了 45 handoffp(_p_) 46 } 47 incidlelocked(1) 48 lock(&allpLock) 49 } else if s == _Prunning { 50 //如果G运行时间过长,则抢占G。 51 // 如果p是running状态,如果p下面的g执行太久了,则抢占 52 t := int64(_p_.schedtick) 53 if int64(pd.schedtick) != t { 54 pd.schedtick = uint32(t) 55 pd.schedwhen = now 56 continue 57 } 58 // 判断是否超出10ms, 不超过不抢占 59 if pd.schedwhen+forcePreemptNS > now { 60 continue 61 } 62 // 开始抢占 63 preemptone(_p_) 64 } 65 } 66 unlock(&allpLock) 67 return uint32(n) 68 }
preemptone
抢占实现:
1 func preemptone(_p_ *p) bool { 2 mp := _p_.m.ptr() 3 if mp == nil || mp == getg().m { 4 return false 5 } 6 gp := mp.curg 7 if gp == nil || gp == mp.g0 { 8 return false 9 } 10 // 标识抢占字段 11 gp.preempt = true 12 13 // go例程中的每个调用都检查堆栈溢出,比较当前堆栈指针与gp-> stackguard0。 14 //将gp-> stackguard0设置为StackPreempt折叠,抢占正常的堆栈溢出检查。 15 16 // 更新stackguard0,保证能检测到栈溢 17 gp.stackguard0 = stackPreempt 18 return true 19 }
在这里,作者会更新 gp.stackguard0 = stackPreempt,然后让g误以为栈不够用了,那就只有乖乖的去进行栈扩张,站扩张的话就用调用newstack 分配一个新栈,然后把原先的栈的内容拷贝过去,而在 newstack 里面有一段如下。
1 if preempt { 2 if thisg.m.locks != 0 || thisg.m.mallocing != 0 || thisg.m.preemptoff != "" || thisg.m.p.ptr().status != _Prunning { 3 //让goroutine现在继续运行。 4 //已设置gp-> preempt,因此下一次将被抢占。 5 gp.stackguard0 = gp.stack.lo + _StackGuard 6 gogo(&gp.sched) // never return 7 } 8 }
然后这里就发现g被抢占了,这种抢占方式自动1.5(也可能更早)就一直存在,且稳定运行。
2. 总结
调度器
- 复用线程:协程本身就是运行在一组线程之上,不需要频繁的创建、销毁线程,而是对线程的复用。在调度器中复用线程还有2个体现:1)work stealing,当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。2)handoff,当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
- 利用并行:GOMAXPROCS设置P的数量,当GOMAXPROCS大于1时,就最多有GOMAXPROCS个线程处于运行状态,这些线程可能分布在多个CPU核上同时运行,使得并发利用并行。另外,GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。
- 抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
- 全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
多级缓存: 这一块跟内存上的设计思想也是一直的,p一直有一个 g 的待运行队列,自己没有货过多的时候,才会平衡到全局队列,全局队列操作需要锁,则本地操作则不需要,大大减少了锁的创建销毁所消耗的资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号