go中的协程-goroutine的底层实现(1)
1. goroutine的使用
在Go语言中,表达式go f(x, y, z)会启动一个新的goroutine运行函数f(x, y, z),创建一个并发任务单元。即go关键字可以用来开启一个goroutine(协程))进行任务处理。
创建单个goroutine
1 package main
2
3 import (
4 "fmt"
5 )
6
7 func HelloWorld() {
8 fmt.Println("Hello goroutine")
9 }
10
11 func main() {
12 go HelloWorld() // 开启一个新的并发运行
time.Sleep(1*time.Second)
13 fmt.Println("后输出消息!")
14 }
输出
1 Hello goroutine 2 后输出消息!
这里的sleep是必须的,否则你可能看不到goroutine里头的输出,或者里面的消息后输出。因为当main函数返回时,所有的gourutine都是暴力终结的,然后程序退出。
创建多个goroutine时
1 package main 2 3 import ( 4 "fmt" 5 "time" 6 ) 7 8 func DelayPrint() { 9 for i := 1; i <= 3; i++ { 10 time.Sleep(500 * time.Millisecond) 11 fmt.Println(i) 12 } 13 } 14 15 func HelloWorld() { 16 fmt.Println("Hello goroutine") 17 } 18 19 func main() { 20 go DelayPrint() // 第一个goroutine 21 go HelloWorld() // 第二个goroutine 22 time.Sleep(10*time.Second) 23 fmt.Println("main func") 24 }
输出
1 Hello goroutine 2 1 3 2 4 3 5 4 6 7 main func
当去掉 DelayPrint() 函数里的sleep之后,输出为:
1 1 2 2 3 3 4 4 5 Hello goroutine 6 main function
说明第二个goroutine不会因为第一个而堵塞或者等待。事实是当程序执行go FUNC()的时候,只是简单的调用然后就立即返回了,并不关心函数里头发生的故事情节,所以不同的goroutine直接不影响,main会继续按顺序执行语句。
goroutine阻塞
场景一:
1 package main 2 3 func main() { 4 ch := make(chan int) 5 <- ch // 阻塞main goroutine, 通道被锁 6 }
运行程序会报错:
1 fatal error: all goroutines are asleep - deadlock! 2 3 goroutine 1 [chan receive]: 4 main.main()
场景二
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int), make(chan int) 5 6 go func() { 7 ch1 <- 1 // ch1通道的数据没有被其他goroutine读取走,堵塞当前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch2 // ch2 等待数据的写 12 }
非缓冲通道上如果只有数据流入,而没有流出,或者只流出无流入,都会引起阻塞。 goroutine的非缓冲通道里头一定要一进一出,成对出现。 上面例子,一:流出无流入;二:流入无流出。
处理方式:
1. 读取通道数据
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int), make(chan int) 5 6 go func() { 7 ch1 <- 1 // ch1通道的数据没有被其他goroutine读取走,堵塞当前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch1 // 取走便是 12 <- ch2 // chb 等待数据的写 13 }
2. 创建缓冲通道
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int, 3), make(chan int) 5 6 go func() { 7 ch1 <- 1 // cha通道的数据没有被其他goroutine读取走,堵塞当前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch2 // ch2 等待数据的写 12 }
2. goroutine调度器相关结构
goroutine的调度涉及到几个重要的数据结构,我们先逐一介绍和分析这几个数据结构。这些数据结构分别是结构体G,结构体M,结构体P,以及Sched结构体。前三个的定义在文件runtime/runtime.h中,而Sched的定义在runtime/proc.c中。Go语言的调度相关实现也是在文件proc.c中。
2.1 结构体G
g是goroutine的缩写,是goroutine的控制结构,是对goroutine的抽象。看下它内部主要的一些结构:
1 type g struct { 2 //堆栈参数。 3 //堆栈描述了实际的堆栈内存:[stack.lo,stack.hi)。 4 // stackguard0是在Go堆栈增长序言中比较的堆栈指针。 5 //通常是stack.lo + StackGuard,但是可以通过StackPreempt触发抢占。 6 // stackguard1是在C堆栈增长序言中比较的堆栈指针。 7 //它是g0和gsignal堆栈上的stack.lo + StackGuard。 8 //在其他goroutine堆栈上为〜0,以触发对morestackc的调用(并崩溃)。
9 //当前g使用的栈空间,stack结构包括 [lo, hi]两个成员 10 stack stack // offset known to runtime/cgo
11 // 用于检测是否需要进行栈扩张,go代码使用 12 stackguard0 uintptr // offset known to liblink
13 // 用于检测是否需要进行栈扩展,原生代码使用的 14 stackguard1 uintptr // offset known to liblink
15 // 当前g所绑定的m 16 m *m // current m; offset known to arm liblink
17 // 当前g的调度数据,当goroutine切换时,保存当前g的上下文,用于恢复 18 sched gobuf
19 // goroutine运行的函数 20 fnstart *FuncVal 21 // g当前的状态 22 atomicstatus uint32 23 // 当前g的id 24 goid int64
25 // 状态Gidle,Grunnable,Grunning,Gsyscall,Gwaiting,Gdead 26 status int16
27 // 下一个g的地址,通过guintptr结构体的ptr set函数可以设置和获取下一个g,通过这个字段和sched.gfreeStack sched.gfreeNoStack 可以把 free g串成一个链表 28 schedlink guintptr
29 // 判断g是否允许被抢占 30 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
31 // g是否要求要回到这个M执行, 有的时候g中断了恢复会要求使用原来的M执行 32 lockedm muintptr
33 // 用于传递参数,睡眠时其它goroutine设置param,唤醒时此goroutine可以获取
param *void
34 // 创建这个goroutine的go表达式的pc 35 uintptr gopc 36 }
其中包含了栈信息stackbase和stackguard,有运行的函数信息fnstart。这些就足够成为一个可执行的单元了,只要得到CPU就可以运行。goroutine切换时,上下文信息保存在结构体的sched域中。goroutine切换时,上下文信息保存在结构体的sched域中。goroutine是轻量级的线程或者称为协程,切换时并不必陷入到操作系统内核中,很轻量级。
结构体G中的Gobuf,其实只保存了当前栈指针,程序计数器,以及goroutine自身。
1 struct Gobuf 2 { 3 //这些字段的偏移是libmach已知的(硬编码的)。 4 sp uintper; 5 pc *byte; 6 g *G; 7 ... 8 };
记录g是为了恢复当前goroutine的结构体G指针,运行时库中使用了一个常驻的寄存器extern register G* g,这是当前goroutine的结构体G的指针。这种结构是为了快速地访问goroutine中的信息,比如,Go的栈的实现并没有使用%ebp寄存器,不过这可以通过g->stackbase快速得到。"extern register"是由6c,8c等实现的一个特殊的存储,在ARM上它是实际的寄存器。在linux系统中,对g和m使用的分别是0(GS)和4(GS)。链接器还会根据特定操作系统改变编译器的输出,每个链接到Go程序的C文件都必须包含runtime.h头文件,这样C编译器知道避免使用专用的寄存器。
2.2 结构体P
P是Processor的缩写。结构体P的加入是为了提高Go程序的并发度,实现更好的调度。M代表OS线程。P代表Go代码执行时需要的资源。
1 type p struct { 2 lock mutex 3 4 id int32 5 // p的状态,稍后介绍 6 status uint32 // one of pidle/prunning/... 7 8 // 下一个p的地址,可参考 g.schedlink 9 link puintptr
// 每次调用 schedule 时会加一
schedtick uint32
// 每次系统调用时加一
syscalltick uint32
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
sysmontick sysmontick // last tick observed by sysmon
10 // p所关联的m 指向绑定的 m,如果 p 是 idle 的话,那这个指针是 nil 11 m muintptr // back-link to associated m (nil if idle) 12 13 // 内存分配的时候用的,p所属的m的mcache用的也是这个 14 mcache *mcache 15 16 // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. 17 // 从sched中获取并缓存的id,避免每次分配goid都从sched分配 18 goidcache uint64 19 goidcacheend uint64 20 21 // Queue of runnable goroutines. Accessed without lock. 22 // p 本地的runnbale的goroutine形成的队列 23 runqhead uint32 24 runqtail uint32 25 runq [256]guintptr 26 27 // runnext,如果不是nil,则是已准备好运行的G 28 //当前的G,并且应该在下一个而不是其中运行 29 // runq,如果运行G的时间还剩时间 30 //切片。它将继承当前时间剩余的时间 31 //切片。如果一组goroutine锁定在 32 //交流等待模式,该计划将其设置为 33 //单位并消除(可能很大)调度 34 //否则会由于添加就绪商品而引起的延迟 35 // goroutines到运行队列的末尾。 36 37 // 下一个执行的g,如果是nil,则从队列中获取下一个执行的g 38 runnext guintptr 39 40 // Available G's (status == Gdead) 41 // 状态为 Gdead的g的列表,可以进行复用 42 gfree *g 43 gfreecnt int32 44 }
跟G不同的是,P不存在waiting状态。MCache被移到了P中,但是在结构体M中也还保留着。在P中有一个Grunnable的goroutine队列,这是一个P的局部队列。当P执行Go代码时,它会优先从自己的这个局部队列中取,这时可以不用加锁,提高了并发度。如果发现这个队列空了,则去其它P的队列中拿一半过来,这样实现工作流窃取的调度。这种情况下是需要给调用器加锁的。
2.3 结构体M
M是machine的缩写,是对机器的抽象,每个m都是对应到一条操作系统的物理线程。
1 type m struct { 2 // g0是用于调度和执行系统调用的特殊g 3 g0 *g // goroutine with scheduling stack 4 // m当前运行的g 5 curg *g // current running goroutine 6 // 当前拥有的p 7 p puintptr // attached p for executing go code (nil if not executing go code)
8 // 线程的 local storage 9 tls [6]uintptr // thread-local storage 10 // 唤醒m时,m会拥有这个p 11 nextp puintptr 12 id int64 13 // 如果 !="", 继续运行curg 14 preemptoff string // if != "", keep curg running on this m
15 // 自旋状态,用于判断m是否工作已结束,并寻找g进行工作 16 spinning bool // m is out of work and is actively looking for work
17 // 用于判断m是否进行休眠状态 18 blocked bool // m is blocked on a note 19 // m休眠和唤醒通过这个,note里面有一个成员key,对这个key所指向的地址进行值的修改,进而达到唤醒和休眠的目的 20 park note
21 // 所有m组成的一个链表 22 alllink *m // on allm 23 // 下一个m,通过这个字段和sched.midle 可以串成一个m的空闲链表 24 schedlink muintptr 25 // mcache,m拥有p的时候,会把自己的mcache给p 26 mcache *mcache 27 // lockedm的对应值 28 lockedg guintptr 29 // 待释放的m的list,通过sched.freem 串成一个链表 30 freelink *m // on sched.freem 31 }
和G类似,M中也有alllink域将所有的M放在allm链表中。lockedg是某些情况下,G锁定在这个M中运行而不会切换到其它M中去。M中还有一个MCache,是当前M的内存的缓存。M也和G一样有一个常驻寄存器变量,代表当前的M。同时存在多个M,表示同时存在多个物理线程。
2.4 Sched结构体
Sched是调度实现中使用的数据结构,该结构体的定义在文件proc.c中。
1 type schedt struct { 2 // 全局的go id分配 3 goidgen uint64 4 // 记录的最后一次从i/o中查询g的时间 5 lastpoll uint64 6 7 lock mutex 8 9 //当增加nmidle,nmidlelocked,nmsys或nmfreed时,应 10 //确保调用checkdead()。 11 12 // m的空闲链表,结合m.schedlink 就可以组成一个空闲链表了 13 midle muintptr // idle m's waiting for work 14 nmidle int32 // number of idle m's waiting for work 15 nmidlelocked int32 // number of locked m's waiting for work 16 // 下一个m的id,也用来记录创建的m数量 17 mnext int64 // number of m's that have been created and next M ID 18 // 最多允许的m的数量 19 maxmcount int32 // maximum number of m's allowed (or die) 20 nmsys int32 // number of system m's not counted for deadlock 21 // free掉的m的数量,exit的m的数量 22 nmfreed int64 // cumulative number of freed m's 23 24 ngsys uint32 // 系统goroutine的数量;原子更新 25 26 pidle puintptr // 闲置的 27 npidle uint32 28 nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go. 29 30 // Global runnable queue. 31 // 这个就是全局的g的队列了,如果p的本地队列没有g或者太多,会跟全局队列进行平衡 32 // 根据runqhead可以获取队列头的g,然后根据g.schedlink 获取下一个,从而形成了一个链表 33 runqhead guintptr 34 runqtail guintptr 35 runqsize int32 36 37 // freem是m等待被释放时的列表 38 //设置了m.exited。通过m.freelink链接。 39 40 // 等待释放的m的列表 41 freem *m 42 }
大多数需要的信息都已放在了结构体M、G和P中,Sched结构体只是一个壳。可以看到,其中有M的idle队列,P的idle队列,以及一个全局的就绪的G队列。Sched结构体中的Lock是非常必须的,如果M或P等做一些非局部的操作,它们一般需要先锁住调度器。
3. G、P、M相关状态
g.status
- _Gidle: goroutine刚刚创建还没有初始化
- _Grunnable: goroutine处于运行队列中,但是还没有运行,没有自己的栈
- _Grunning: 这个状态的g可能处于运行用户代码的过程中,拥有自己的m和p
- _Gsyscall: 运行systemcall中
- _Gwaiting: 这个状态的goroutine正在阻塞中,类似于等待channel
- _Gdead: 这个状态的g没有被使用,有可能是刚刚退出,也有可能是正在初始化中
- _Gcopystack: 表示g当前的栈正在被移除,新栈分配中
goroutine的状态变化
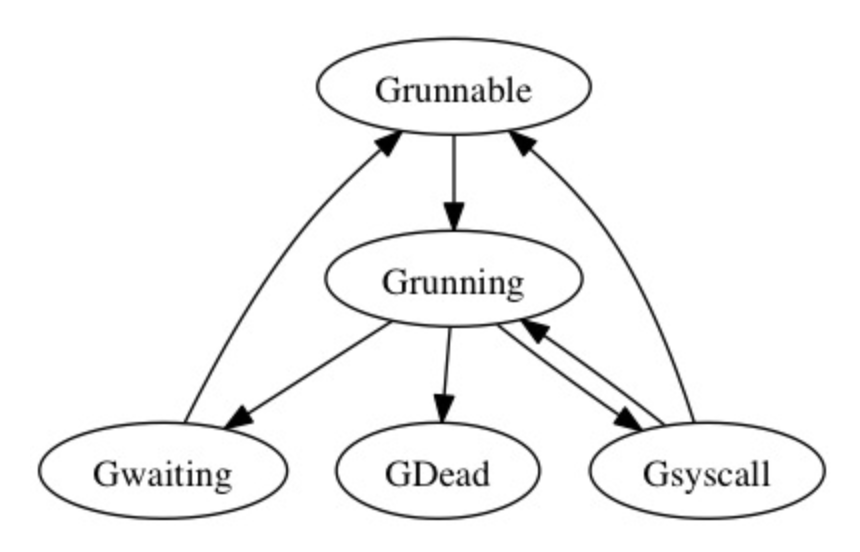
在newproc1中新建的goroutine被设置为Grunnable状态,投入运行时设置成Grunning。Grunning状态的goroutine会在entersyscall的时候goroutine的状态被设置为Gsyscall,到出系统调用时根据它是从阻塞系统调用中出来还是非阻塞系统调用中出来,又会被设置成Grunning或者Grunnable的状态。在goroutine最终退出的runtime.exit函数中,goroutine被设置为Gdead状态。还会在进行I/O时可能会进入waiting状态,主动让出CPU,此时会被移到所属P中的其他G后面,等待下一次轮到执行。
p.status
- _Pidle: 空闲状态,此时p不绑定m
- _Prunning: m获取到p的时候,p的状态就是这个状态了,然后m可以使用这个p的资源运行g
- _Psyscall: 当go调用原生代码,原生代码又反过来调用go的时候,使用的p就会变成此态
- _Pdead: 当运行中,需要减少p的数量时,被减掉的p的状态就是这个了
m.status
m的status没有p、g的那么明确,但是在运行流程的分析中,主要有以下几个状态
- 运行中: 拿到p,执行g的过程中
- 运行原生代码: 正在执行原声代码或者阻塞的syscall
- 休眠中: m发现无待运行的g时,进入休眠,并加入到空闲列表中
- 自旋中(spining): 当前工作结束,正在寻找下一个待运行的g
4. G、P、M的调度关系
一个G就是一个gorountine,保存了协程的栈、程序计数器以及它所在M的信息。P全称是Processor,处理器,它的主要用途就是用来执行goroutine的。M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上的。程序启动时,会创建一个主G,而每使用一次go关键字也创建一个G。go func()创建一个新的G后,放到P的本地队列里,或者平衡到全局队列,然后检查是否有可用的M,然后唤醒或新建一个M,M获取待执行的G和空闲的P,将调用参数保存到g的栈,将sp,pc等上下文环境保存在g的sched域,这样整个goroutine就准备好了,只要等分配到CPU,它就可以继续运行,之后再清理现场,重新进入调度循环。
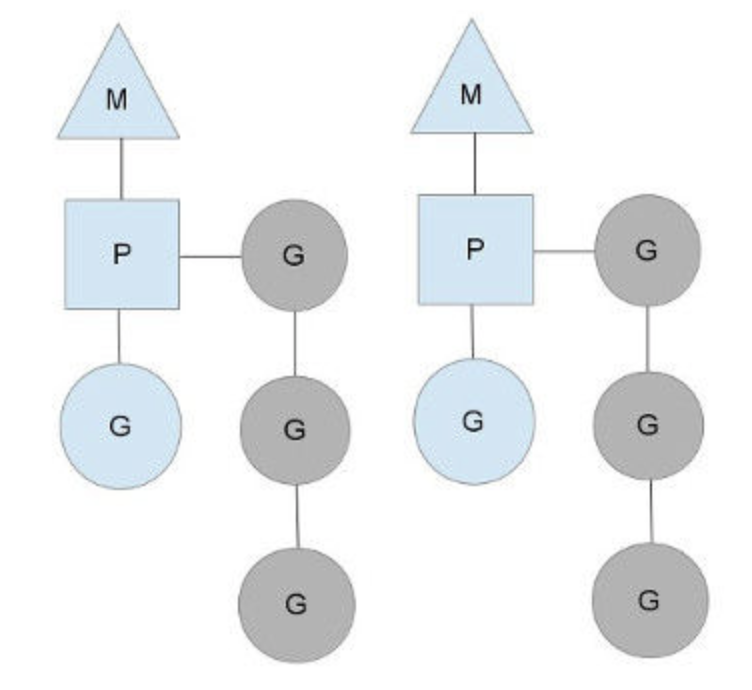
4.1 调度实现
图中有两个物理线程,M0、M1每一个M都拥有一个处理器P,每一个P都有一个正在运行的G。P的数量可以通过GOMAXPROCS()来设置,它其实也代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色goroutine都是处于ready的就绪态,正在等待被调度。由P维护这个就绪队列(runqueue),go function每启动一个goroutine,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出一个goroutine执行。
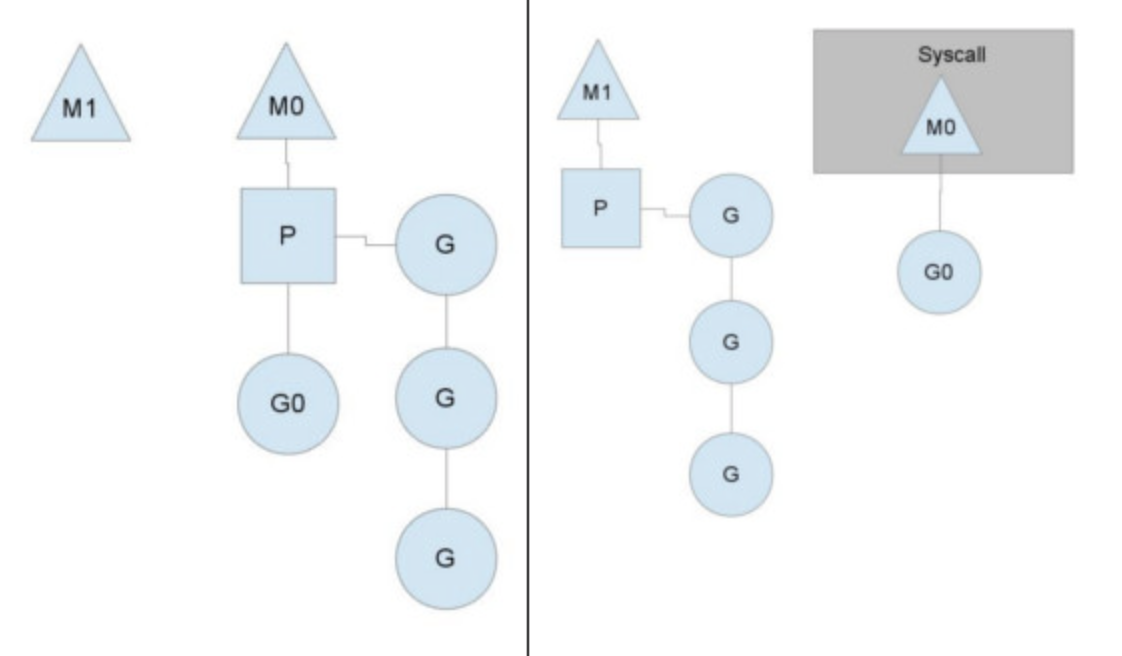
当一个OS线程M0陷入阻塞时,P转而在M1上运行G,图中的M1可能是正被创建,或者从线程缓存中取出。当MO返回时,它尝试取得一个P来运行goroutine,一般情况下,它会从其他的OS线程那里拿一个P过来执行,像M1获取P一样;如果没有拿到的话,它就把goroutine放在一个global runqueue(全局运行队列)里,然后自己睡眠(放入线程缓存里)。所有的P会周期性的检查全局队列并运行其中的goroutine,否则其上的goroutine永远无法执行。
另一种情况是P上的任务G很快就执行完了(分配不均),这个处理器P很忙,但是其他的P还有任务,此时如果global runqueue也没有G了,那么P就会从其他的P里拿一些G来执行。一般来说,如果一般就拿run queue的一半,这就确保了每个OS线程都能充分的使用。
4.2 P、M的数量
M的数量:go语言本身的限制:go程序启动时,会设置M的最大数量,默认10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。runtime/debug中的SetMaxThreads函数,设置M的最大数量。一个M阻塞了,会创建新的M。
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
4.2 P、G的调度细节
P上G的调度:如果一个G不主动让出cpu或被动block,所属P中的其他G会一直等待顺序执行。
M上P和G的调度:每当一个G要开始执行时,调度器判断当前M的数量是否可以很好处理完G:如果M少G多且有空闲P,则新建M或唤醒一个sleep M,并指定使用某个空闲P;如果M应付得来,G被负载均衡放入一个现有P+M中。
协程特点
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此,协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作执行者则是用户自身程序,goroutine也是协程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号