数据结构第七章小结
1、typedef struct 和struct 的区别
struct Studen1 { int ID; char name; }stu1; typedef struct Student2 { int ID; char name; }stu2;
Student1是结构体的名字,stu1是一个变量,相当于struct Student1 stu1;
而stu2是一个变量的类型,相当于struct Student2的别名。
2、召回率也叫查全率,准确率也叫查准率。
召回率与准确率概念公式:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
3.PTA实践1--二分查找变形
自左向右查找第一个大于等于x的数,当x存在时很容易想到是用二分查找找到的key,可当key不存在时,就会比较麻烦。所以联想到mooc里面的一个讨论,当二分查找中high=mid时,不存在key时,会陷入一个死循环,而死循环里面刚好卡在了大于等于x这个数,而当x存在时,不会对二分查找产生影响,直接能找到x。所以说想到这个方法,还是挺快能写出来的。
4.感想
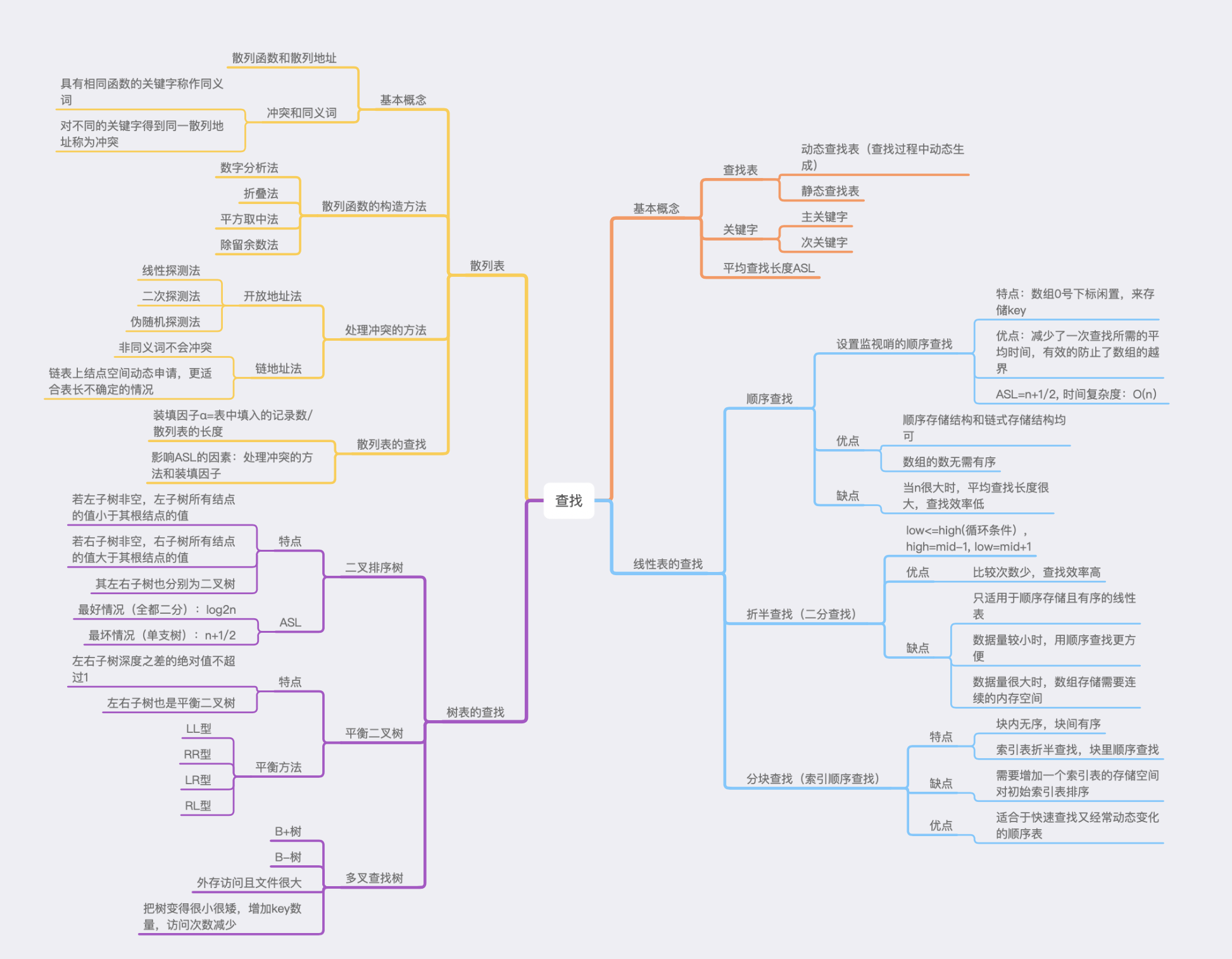
感觉本章还是比较的循序渐进。首先是顺序查找的一种简单的for循环的查找,由于数据大时查找效率低,所以引出了第二种线性表查找--折半查找。折半查找相对于顺序查找效率高但是只是适合于静态查找。因此又引出了分块查找,分块查找有利于查找动态变化的线性表,但是效率没有二分查找的高。所以引出了二叉排序树,既适合动态查找又可以有很大的时间效率。但是由于左子树的值一定要比根结点数值低,右子树得值一定要比根结点高,所以可能树会变成单支树,为了让树变得匀称,提高效率又引出了平衡二叉树,让其时间效率一定是O(log2n)。由于二叉树只适合于内存,对于外存的数据就引出了多叉树。散列表直接算出位置,查找与数据量无关。
5.小结
对于这章的知识点,感觉还是挺多的。之前在听课的时候感觉自己都已经收获满满了,懂了这些东西。但是在小测里还是懵了。其实当时对于构造散列表还是没有很深的了解,书里的类似的例题也没有自己去在尝试一遍,所以才会错误。在小测之后自己又再一次对题目分析,解答,过程中也发现了自己的很多不足之处,但是最终还是学会了这类的题型,还是很不错的。希望自己能够多多去写书中的例题,真看真感受,要动手!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号