
个人项目-北京地铁线路规划

一、项目概况:
语言:Java ,运行环境: macOS
本次项目主要是对于北京市地铁出行道路的规划,简单地说就是对于两个地点的最短路的规划。如果是单单是两个站点之间的最短路径的规划显然思想是简单的,那么有没有办法可以在较短的时间里面准确地处理出很多的查询信息的线路规划,此次借鉴莫队算法和狄杰斯特拉算法的思想来尝试处理这一次的问题。
二、存储结构:
1.对于两个站点之间的边的存储
对于边来说相对简单,我们存储每一条边的名称,并赋予他一个ID,开始站点与结束站点的名称,如果连着边的边号一起存储下来后续会更方便。
private int id; private String StartAddress; private String EndAddress; private String name;
2.对于站点的存储:
很显然,站点至少需要的信息为:站点名称、站点编号
其次,由于处理站点信息时使用了借鉴使用了莫队算法的有关知识,所以我们需要存储站点之间的相对位置,这边预处理时只处理节点的左右相对位置,那么综上,每个站点一共会有3个参数,分别为:站点名称,站点编号,和站点的相对位置,虽然这边的相对位置我们会体现在数组的下标上面,但是为了防止左右相同站点的出错,还是需要存储站点的相对位置
//站点结构 private id; private pos; private name; //站点存储数组 static ArrayList<BeanStation> nodes = new ArrayList<>();
3.读入文件浏览:
边的读入格式:

站点的读入格式(文件需要与处理好站点从左到右的信息):

三、简单的逻辑实现举例
在我们实现这段代码之前,我们先要理解两种算法:杰斯特拉算法和莫队算法。
1.狄杰斯特拉算法:
这个方法不在赘述了,直接上代码,主要就是由起点不断地向外扩增,直到无法扩增或者到达终点为止。
但在本项目中需要注意,除了路径的长短,我们还需要引入第二对比因素,由于前面笼统地把站点间的距离都处理为1,这里我们在扩增时碰到路径长度相同的状况时需要对比在扩增站点处前面的线路,相同线路则扩增,不同则不扩增。
public void djs(int v1,int v2) { int i; f =0; int max = 0x3f3f3f3f; for(i=0;i<path.length;i++) { path[i] =-1; } path[v1] = -1; for(i=0;i<nodes.size();i++) { dis[i] = max; } dis[v1] =0; for(i=0;i<nodes.size();i++) { vis[i] = 0; } vis[v1] = 0; while(true) { int min =max; int v = -1; for(i=0;i<nodes.size();i++) { if(vis[i] == 0&&dis[i]<min) { min = dis[i]; v = i; } } if(v == v2 || v == -1) { if(v == -1) f++; return ; } vis[v] = 1;
//先取得这一站点前面确定的线路号,所以说还是记下站点号的编号简单。。。 int p =-1,j; for(j =0;j<edges.size();j++) { if(path[v]!=-1) { if(edges.get(j).getStartAddress().equals(nodes.get(path[v]))&&edges.get(j).getEndAddress().equals(nodes.get(v))) p = edges.get(j).getId(); } } for(i=0;i<nodes.size();i++) { if(vis[i] == 0 && dis[i] > dis[v]+e[v][i]) { dis[i] = dis[v]+e[v][i]; path[i] = v; } else if(vis[i] == 0 && dis[i] == dis[v] + e[v][i]) {
//还是获取需要改变的站点前面的站点信息,避免相同路程成环情况下面换乘的情况 int p2 = -1; if(path[i]!=-1) { for(j =0;j<edges.size();j++) { if(edges.get(j).getStartAddress().equals(nodes.get(path[i]))&&edges.get(j).getEndAddress().equals(nodes.get(v))) p2 = edges.get(j).getId(); } } if(p == p2) { dis[i] = dis[v]+e[v][i]; path[i] = v; } } } } }
2.莫队算法:
如果我们按照狄杰斯特拉算法来对于每一次的询问都进行一次查找,北京站点约为1000个,狄杰斯特拉的复杂度为O(n^2),作为中国的首都,在同一时间段有1e4个人查找北京地铁的信息不过分吧,这么说大概需要时间为1e3*1e3*1e4=1e10,服务器一秒运行1e8次,就是说大概要两分钟才能出全部处理完,总不能让乘客每次都抱着手机等两分钟查一次吧,这样的算法显然无法令人满意。我们使用莫队算法来改进这次项目。
首先我们把这些站点从左到右排了序,这个时候先读入所有的询问,这个时候我们将询问排列一下,先不管起点和终点,单纯地按照相对位置排序,先按照左边的点从左到右排序,再按照右边的点从左到右排序,放入队列中,这时我们只要逐一取出对队列中的站点来跑狄杰斯特拉算法就可以了,这个样子可以避免无数的重复计算。
注意:我们每次跑的只有从每对点的左边的点到每对点的右边的点,不用全跑,每次的运行次数大大下降
下面是改变以后的狄杰斯特拉算法:
public void djs(int v1,int v2,int l,int r)//l 为此次所找的在数组中的最左起点,r为此次所找的在数组中的最右终点
{
int i;
f =0;
int max = 0x3f3f3f3f;
//此时为了使用上一次的记录,我们把初始化全部放在外面,里面的结束可以留给下一次询问while(true) {
int min =max;
int v = -1;
for(i=l;i<=r;i++)//可以发现,这里所有的边界条件全部改变
{
if(vis[i] == 0&&dis[i]<min)
{
min = dis[i];
v = i;
}
}
if(v == v2 || v == -1)
{
if(v == -1)
f++;
return ;
}
vis[v] = 1;
int p =-1,j;
//这里没法改变,存储结构不允许,所以说最好先记录。。。
for(j =0;j<edges.size();j++) {
if(path[v]!=-1) {
if(edges.get(j).getStartAddress().equals(nodes.get(path[v]))&&edges.get(j).getEndAddress().equals(nodes.get(v)))
p = edges.get(j).getId();
}
}
//注意,这里的更新不是说排序在l前的点全部找到最短路,而是说在这一组询问中,前面的点都不会再用到了,所以不管最短与否,我们都不再去管他
for(i=l;i<=r;i++)
{
if(vis[i] == 0 && dis[i] > dis[v]+e[v][i])
{
dis[i] = dis[v]+e[v][i];
path[i] = v;
}
else if(vis[i] == 0 && dis[i] == dis[v] + e[v][i])
{
int p2 = -1;
if(path[i]!=-1) {
for(j =0;j<edges.size();j++) {
if(edges.get(j).getStartAddress().equals(nodes.get(path[i]))&&edges.get(j).getEndAddress().equals(nodes.get(v)))
p2 = edges.get(j).getId();
}
}
if(p == p2)
{
dis[i] = dis[v]+e[v][i];
path[i] = v;
}
}
}
}
}
//排序函数与,pair存放两个节点
public boolean cmp(pair a,pair b){
return a.get(0).getid() == b.get(0).getid() ? a.get(1).getid() < b.get(1).getid() : a.get(0).getid() == b.get(0).getid() ;
}
虽然借鉴了莫队算法的思想,但是和莫队算法有一点不同,莫队在每次更改询问时都会将左边多出去的部分剪掉,而我们这一边不需要了,又加速了N/2。
四、时间复杂度分析
莫队算法平均可以将复杂度控制在O(n√n),也就是说,可以将效率提升大约33倍。然而,在最坏的情况下,如果说每一次询问的边界l,r均不相交且正好覆盖整个地图,那么这一种方法没有任何帮助。但一定比弗洛伊德快。
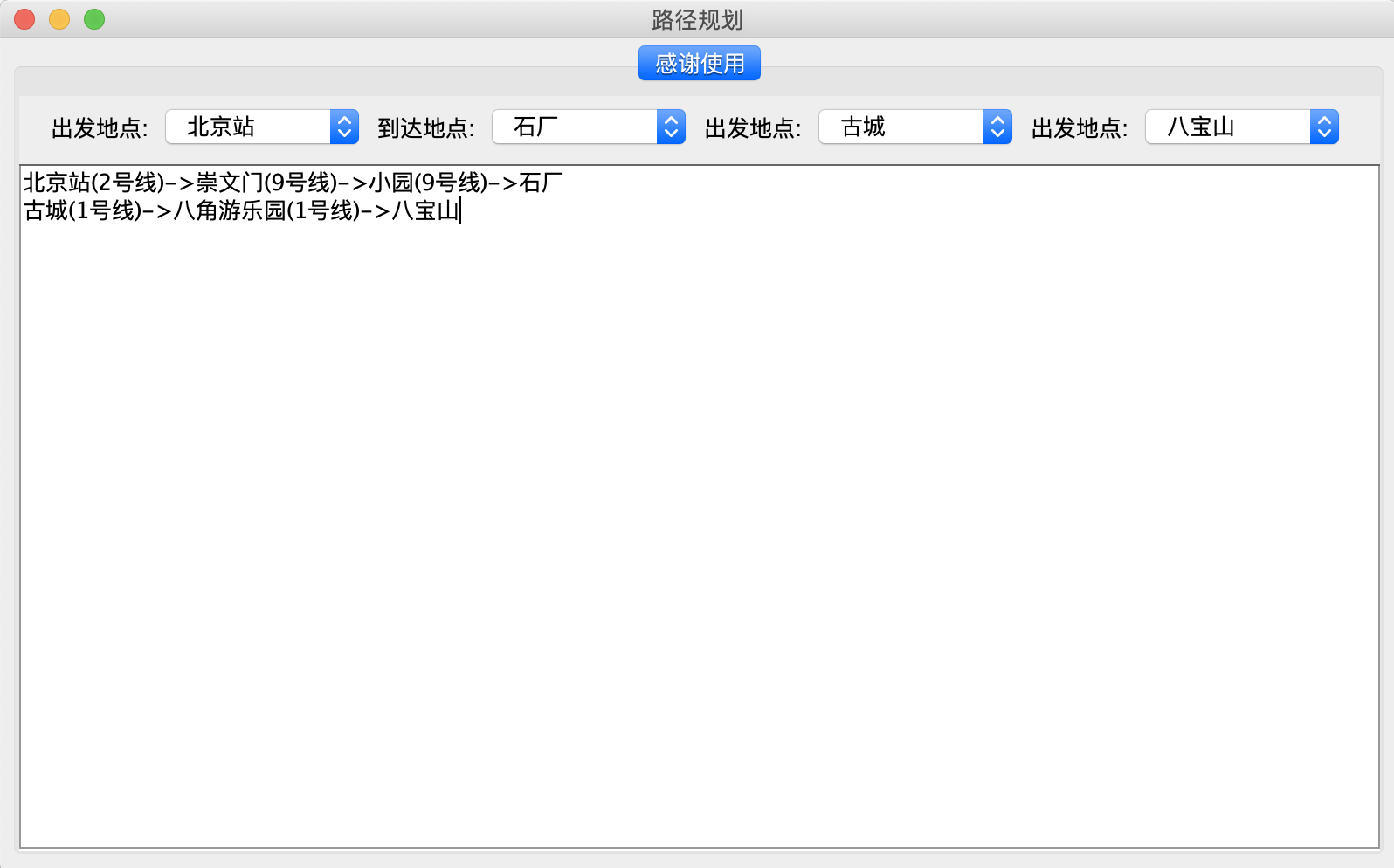
五、运行举例

源代码下载位置: https://github.com/wljLlla/Llla.github.io
