spark中生成时间序列数据的函数stack和sequence
Sequence函数
用Sequence函数生成时间序列函数,真的是非常简便易用,之前因为没找到,所以走了不少弯路。
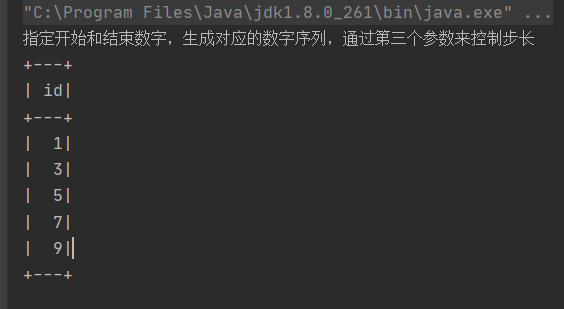
println("指定开始和结束数字,生成对应的数字序列,通过第三个参数来控制步长")
SparkUtil.executeSQL("""
|select explode(sequence(1,10,2)) id
|""".stripMargin)(spark)
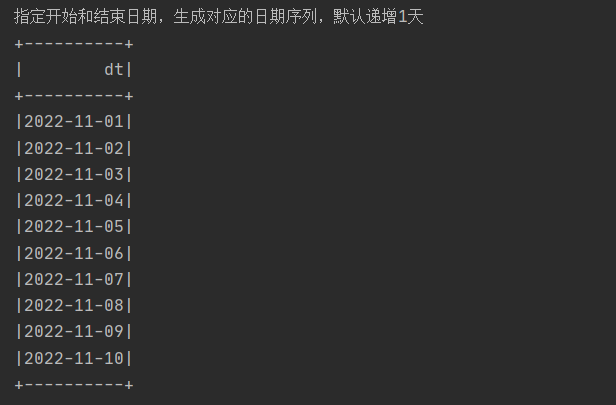
println("指定开始和结束日期,生成对应的日期序列,默认递增1天")
SparkUtil.executeSQL("""
|select explode(sequence(to_date('2022-11-01','yyyy-MM-dd'),to_date('2022-11-10','yyyy-MM-dd'))) dt
|""".stripMargin)(spark)
println("指定开始和结束日期,生成对应的日期序列,指定递增间隔天数")
SparkUtil.executeSQL("""
|select explode(sequence(to_date('2022-11-01','yyyy-MM-dd'),to_date('2022-11-10','yyyy-MM-dd'),interval 2 day)) dt
|""".stripMargin)(spark)

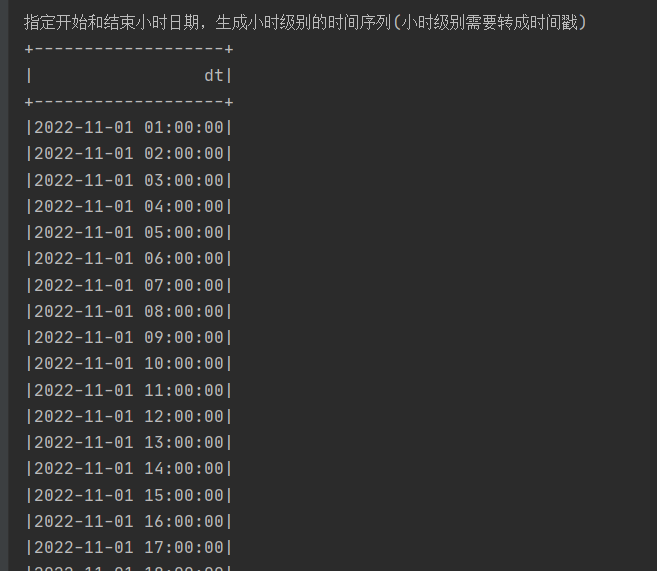
println("指定开始和结束小时日期,生成小时级别的时间序列(小时级别需要转成时间戳)")
SparkUtil.executeSQL("""
|select explode(sequence(to_timestamp('2022-11-01 01:00:00','yyyy-MM-dd HH:mm:ss'),to_timestamp('2022-11-04 01:00:00','yyyy-MM-dd HH:mm:ss'),interval 1 hours)) dt
|""".stripMargin,100)(spark)
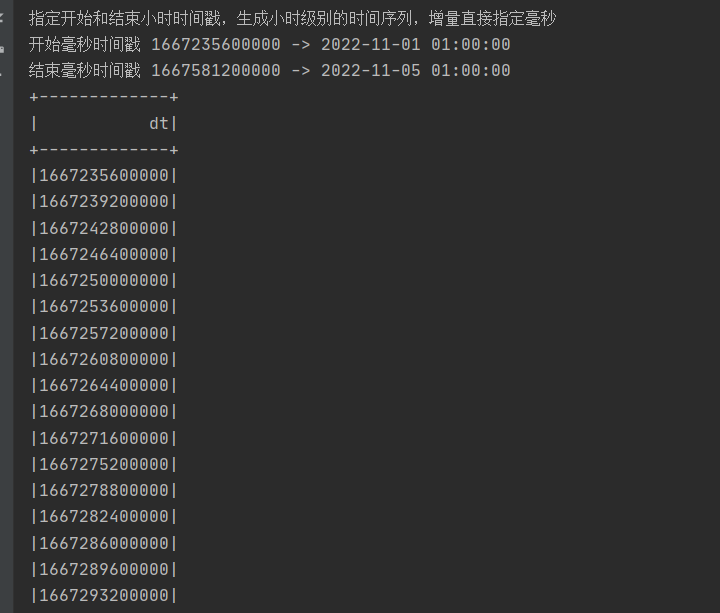
println("指定开始和结束小时时间戳,生成小时级别的时间序列,增量直接指定毫秒")
println("开始毫秒时间戳 1667235600000 -> 2022-11-01 01:00:00")
println("结束毫秒时间戳 1667581200000 -> 2022-11-05 01:00:00")
SparkUtil.executeSQL("""
|select explode(sequence(1667235600000,1667581200000,3600000)) dt
|""".stripMargin,100)(spark)
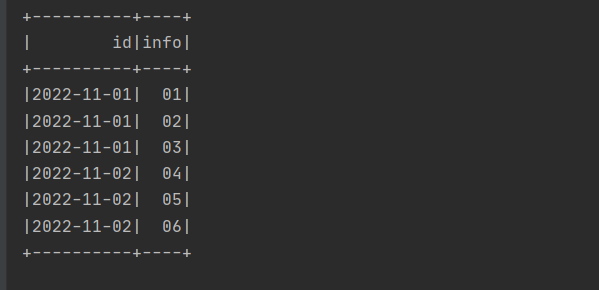
SparkUtil.executeSQL("""
|
|with tmp_a as (
| select '2022-11-01' as id,'01,02,03' as infos
| union all
| select '2022-11-02' as id,'04,05,06' as infos
|)
|select id,info from tmp_a LATERAL VIEW explode(split(infos,',')) t AS info
|""".stripMargin)(spark)
在spark中向前填充或向后填充的案例,这个其实就是先排下,然后用last或者first取值去替换。
其中last(timeField, true)第二个参数,是是否忽略空值。
val window = Window.partitionBy(idField).orderBy(timeField).rowsBetween(-1, 0)
val filled = last(timeField, true).over(window)
outputDF = outputDF.selectExpr(field1: _*).withColumn(rule.getField, filled)
//后向填充
val window = Window.partitionBy(idField).orderBy(timeField).rowsBetween(0, 1)
val filled = last(timeField, true).over(window)
outputDF = outputDF.withColumn(rule.getField, filled)
stack
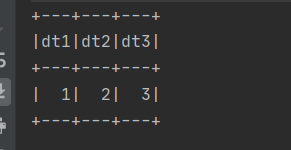
SparkUtil.executeSQL(
"""
|select stack(1, 1, 2, 3) as (dt1,dt2,dt3)
|""".stripMargin)(spark)
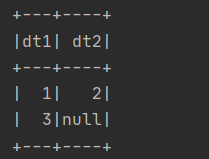
SparkUtil.executeSQL(
"""
|select stack(2, 1, 2, 3) as (dt1,dt2)
|""".stripMargin)(spark)
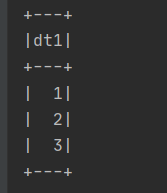
SparkUtil.executeSQL(
"""
|select stack(3, 1, 2, 3) as dt1
|""".stripMargin)(spark)
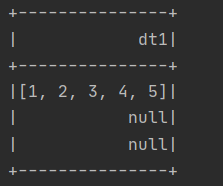
SparkUtil.executeSQL("""
|select stack(3, split('1,2,3,4,5',',')) as dt1
|""".stripMargin)(spark)
本文来自博客园,作者:硅谷工具人,转载请注明原文链接:https://www.cnblogs.com/30go/p/16910069.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号