flink1.14.0中集成hive3.1.2
不想看太多的话,直接拉到第二部分操作步骤:
1. 是解决过程:
在flink1.14.0中已经移除sql-client-defaults.yml配置文件了。
参考地址:https://issues.apache.org/jira/browse/FLINK-21454
于是我顺着这个issue找到了FLIP-163这个链接。
https://cwiki.apache.org/confluence/display/FLINK/FLIP-163%3A+SQL+Client+Improvements
Use commands to configure the client Currently sql-client uses a YAML file to configure the client, which has its own grammar rather than the commands used in the client.
It causes overhead for users because users have to study both gramars and it's very tricky for users to debug the YAML problems.
Considering the Table Api has developed sophisticated grammar, it's better to use the same commands in the client for users to
configure their settings including set the runtime/table settings and register Catalog/Module/Database/Table/Function. For better understanding, the chart below lists the relationship between YAML and the command in the client.
看不懂没关系,直接翻译:
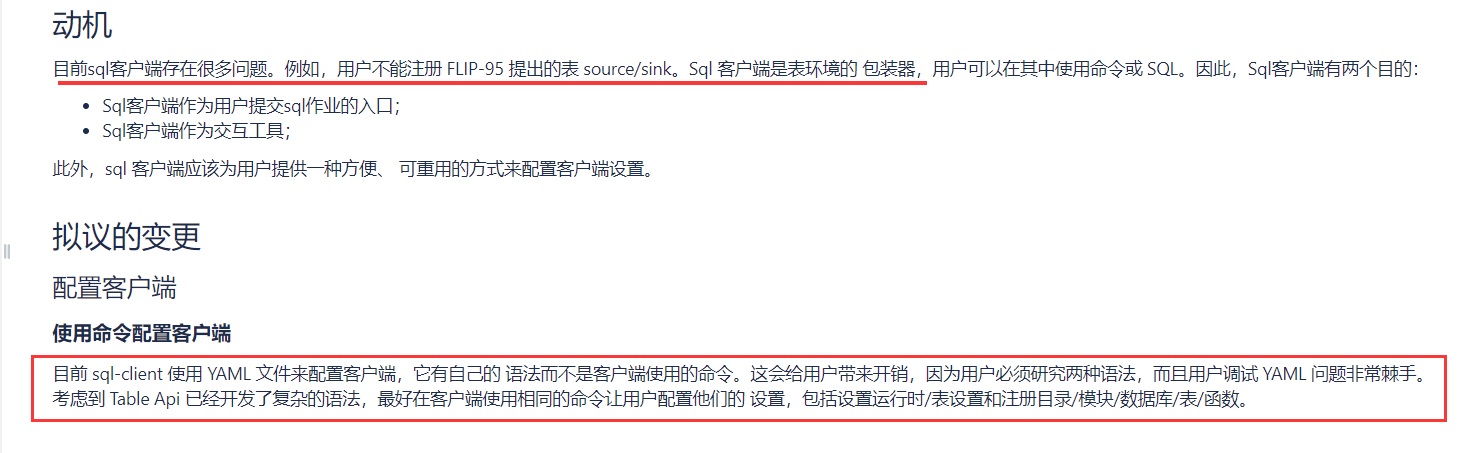
也就是目前这个sql客户端还有很多bug,并且使用yaml文件和本身的命令语法会导致用户学习成本增加,所以在未来会放弃使用这个配置项,可以通过命令行模式来配置。
接着我们看到了在启动sql-client时,可以通过-i参数来额外指定配置。

配置方式如下:
-- set up the default properties SET sql-client.execution.mode=batch; SET parallism.default=10; SET pipeline.auto-watermark-interval=500; -- set up the catalog CREATE CATALOG HiveCatalog WITH ( 'type' = 'hive' ); USE CATALOG HiveCatalog; -- register the table CREATE IF NOT EXISTS TABLE pageviews ( user_id BIGINT, page_id BIGINT, viewtime TIMESTAMP, proctime AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'pageviews', 'properties.bootstrap.servers' = '...', 'format' = 'avro' ); CREATE IF NOT EXISTS TABLE pageviews_enriched ( user_id BIGINT, page_id BIGINT, viewtime TIMESTAMP, user_region STRING, WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = 'pageviews_enriched', ... );
上面一大段配置,除了第一个hivecatalog的配置比较通用以外,其他的都是属于定制化的配置,视为具体的业务应用场景时,自己配置。
那么我们就参照这个自己写一个hivecatalog配置如下,文件为sql-conf.sql。
CREATE CATALOG myhive WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/opt/local/hive/conf', 'hadoop-conf-dir'='/opt/local/hadoop/etc/hadoop/' ); -- set the HiveCatalog as the current catalog of the session USE CATALOG myhive;
将该文件保存到flink/conf/文件下当做一个通用的配置吧。
然后启动方式如下:
bin/sql-client.sh embedded -i conf/sql-conf.sql
还是没有发现hive的文件,于是想到官网的连接hive的包如下:

下载对应的包,安装,后面遇到兼容性问题,修改包后即可解决。

2. 操作步骤:
1. 下载
flink1.14.0的包,解压缩。
2. 配置
配置系统环境变量/etc/profile和flink的配置文件flink-conf.yaml
/etc/profile 增加配置如下(这里默认jdk,haodoop都配置好):
#flink config export HADOOP_CLASSPATH=`hadoop classpath` export FLINK_HOME=/opt/local/flink export PATH=$PATH:$FLINK_HOME/bin
flink-conf.yaml配置如下:
# 修改了一个task可以使用2个slot
taskmanager.numberOfTaskSlots: 2
# 增加一行
classloader.check-leaked-classloader: false
在bin/config.sh中第一行也添加了 以下环境变量
export HADOOP_CLASSPATH=`hadoop classpath`
3. 设置启动配置
新增sql-conf.sql配置文件,配置hivecatalog
CREATE CATALOG myhive WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/opt/local/hive/conf', 'hadoop-conf-dir'='/opt/local/hadoop/etc/hadoop/' ); -- set the HiveCatalog as the current catalog of the session USE CATALOG myhive;
4. 下载相关依赖包
注意一共有4个,其中红色方框中2个为必选(因为测试不够深入,不知道其他两个是否需要):
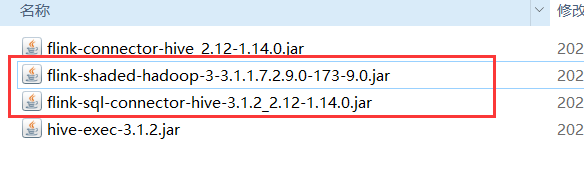
注意: hive-exec-3.1.2.jar同样存在guava和flink不兼容的问题,所以也是直接删除里面的com.google文件夹。
第一个包下载路径:flink-sql-connector-hive-3.1.2_2.12-1.14.0.jar
官网地址如下:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/connectors/table/hive/overview/

由于要根据不同的地址下载不同的版本,并且要根据自己使用的scala版本来选择不同的jar。这里给出这个链接的的ftp目录可以自己选择。
我的hive是3.1.2,但是由于给出的连接是scala2.11的,所以我顺着这个地址找到2.12版本的如下:
https://repo.maven.apache.org/maven2/org/apache/flink/
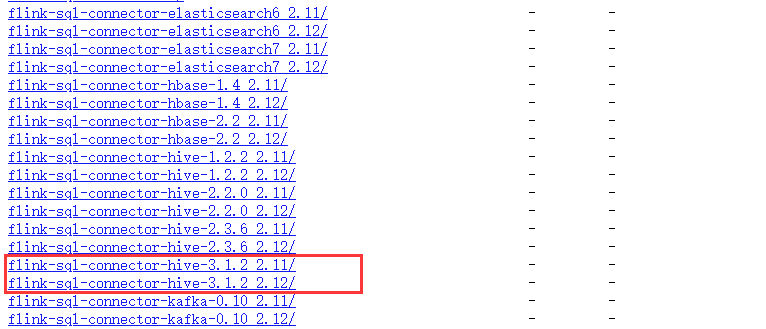
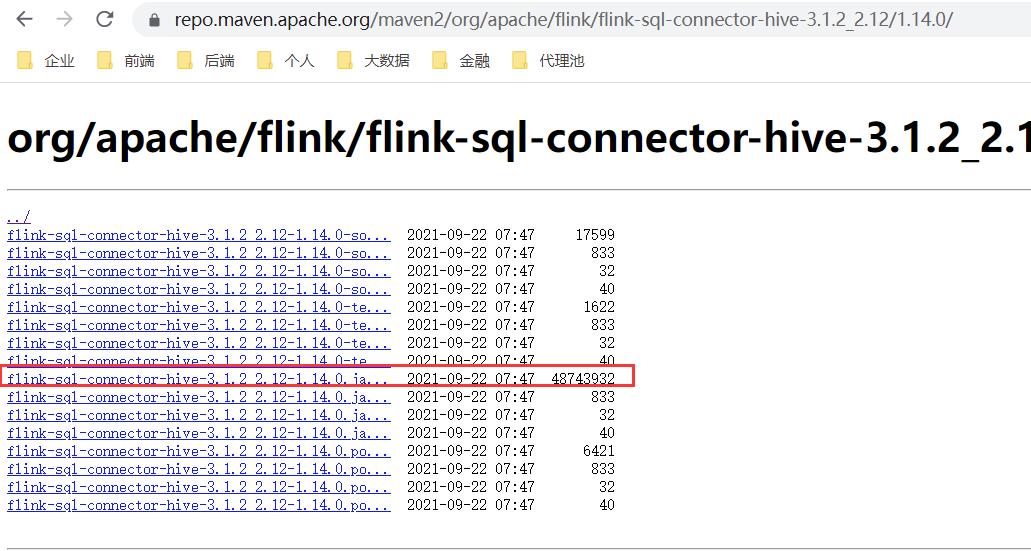
最终的地址:这个包有46.4m大小。
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.0/
其余三个下载方式:
可以在上面的maven网站找,也可以新建个项目,添加以下依赖后获得。
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>${hive.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-shaded-hadoop-3</artifactId> <version>3.1.1.7.2.9.0-173-9.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-hive_${scala.version} </artifactId> <version>${flink-version}</version> <scope>provided</scope> </dependency>
5. 解决包冲突问题
由于下载的这个 flink-sql-connector-hive-3.1.2_2.12-1.14.0.jar 以及 hive-exec-3.1.2.jar 包含的guava版本和hadoop版本有冲突,所以操作如下:
用压缩软件打开
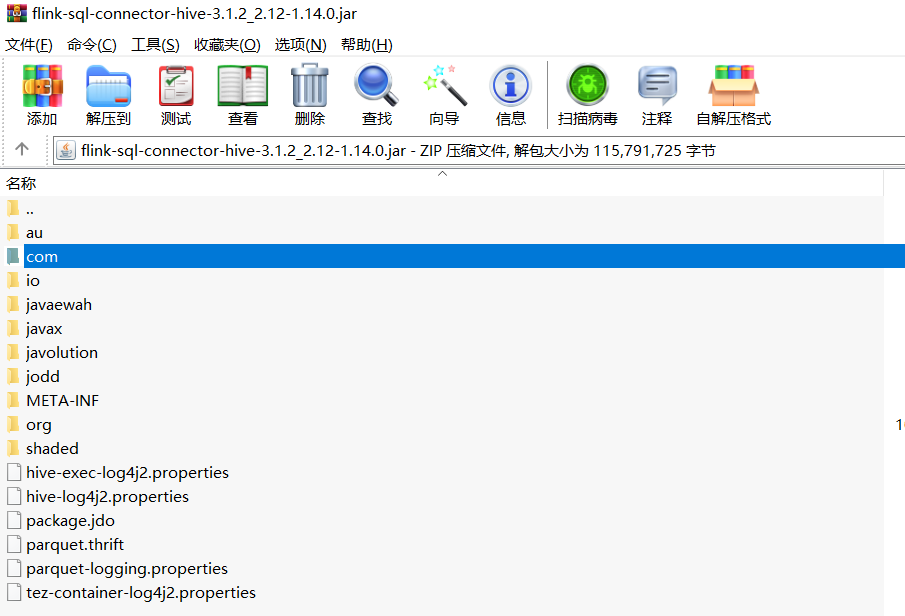
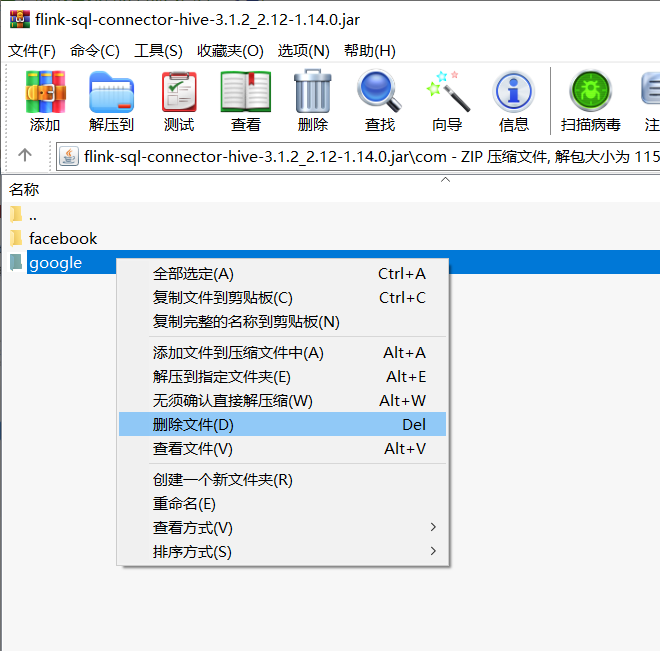
找到com/google,然后把这个google全部删除。(注意:不需要解压缩,直接右键删除)
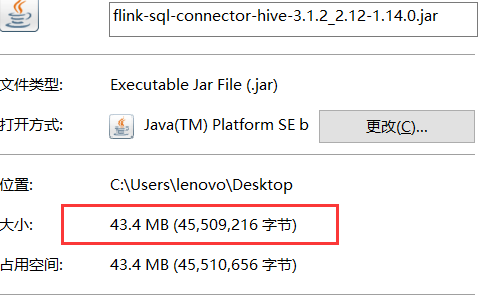
删除完后,关闭窗口,这时候只有43.4m了.
2个包都同样操作,然后将4个jar包都上传到flink/lib文件夹下面。

可选: 因为没有测试更多的sql,所以不排除后面有依赖,先都放进去吧。
6. 启动环境
先启动yarn-session
bin/yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm test1 -d
然后再启动sql-client,让sql在yarn-session上执行:
bin/sql-client.sh embedded -i conf/sql-conf.sql -s yarn-session
注意看到success表示执行成功。

这时候可以在hadoop的yarn上看到这个任务 :


7. 测试DDL语句

官方其实在操作hive时,建议使用hive方言的,可以在命令行设置hive方言:
set table.sql-dialect=hive;

测试简单查询:
select * from dt_dwd.dwd_stock_day_history limit 100;
说实在的,这界面比hive不是丑了一点点。。而是巨丑。

测试统计查询:(查询浦发银行每年收盘的最大价和最小价格)
select code,name,substr(dt,1,4) as yr,min(close) as min_close,max(close) as max_close from dt_dwd.dwd_stock_day_history where code = '600000' group by code,name,substr(dt,1,4);
效率还可以:
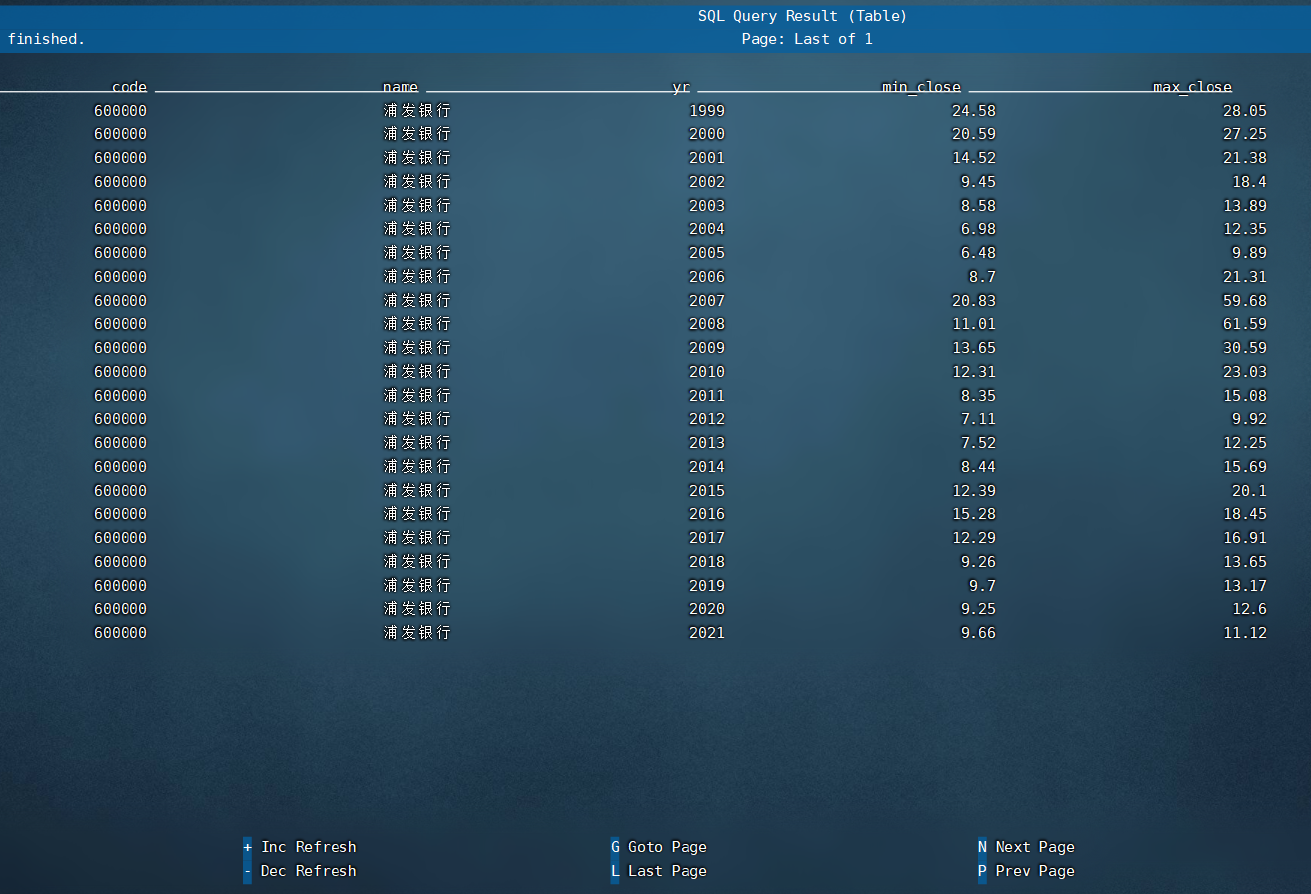
最后次统计查询耗时39s

虽然 任务都能提交并且执行成功,但是还遗留了一个问题没解决,那就是后台日志总是在报一些奇怪的错误。
就是当任务执行完成后,会显示一些错误信息(并不影响结果)。
at org.apache.flink.table.client.gateway.local.result.CollectResultBase$ResultRetrievalThread.run(CollectResultBase.java:74) [flink-sql-client_2.12-1.14.0.jar:1.14.0] Caused by: org.apache.flink.runtime.rest.util.RestClientException: [Internal server error., <Exception on server side: org.apache.flink.runtime.messages.FlinkJobNotFoundException: Could not find Flink job (1357b58d9e46be54f7713850c26c681d) at org.apache.flink.runtime.dispatcher.Dispatcher.getJobMasterGateway(Dispatcher.java:917) at org.apache.flink.runtime.dispatcher.Dispatcher.performOperationOnJobMasterGateway(Dispatcher.java:931) at org.apache.flink.runtime.dispatcher.Dispatcher.deliverCoordinationRequestToCoordinator(Dispatcher.java:719) at sun.reflect.GeneratedMethodAccessor14.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRpcInvocation$1(AkkaRpcActor.java:316) at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:83) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:314) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:217) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20) at scala.PartialFunction.applyOrElse(PartialFunction.scala:123) at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at akka.actor.Actor.aroundReceive(Actor.scala:537) at akka.actor.Actor.aroundReceive$(Actor.scala:535) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580) at akka.actor.ActorCell.invoke(ActorCell.scala:548) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270) at akka.dispatch.Mailbox.run(Mailbox.scala:231) at akka.dispatch.Mailbox.exec(Mailbox.scala:243) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172) End of exception on server side>] at org.apache.flink.runtime.rest.RestClient.parseResponse(RestClient.java:532) ~[flink-dist_2.12-1.14.0.jar:1.14.0] at org.apache.flink.runtime.rest.RestClient.lambda$submitRequest$3(RestClient.java:512) ~[flink-dist_2.12-1.14.0.jar:1.14.0] at java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:966) ~[?:1.8.0_261] at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:940) ~[?:1.8.0_261] at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:456) ~[?:1.8.0_261] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_261] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_261] at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_261]
目前百度到的信息碎片可能是任务执行结果的回执未收到,待后续再研究。
flink1.14.0的完整包或者依赖包可以通过百度网盘直接获取: 链接:https://pan.baidu.com/s/1QNCFSRDJyUzJtAbdN7k9Fw 提取码:pang
本文来自博客园,作者:硅谷工具人,转载请注明原文链接:https://www.cnblogs.com/30go/p/15370240.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号