Collection集合家族
集合家族
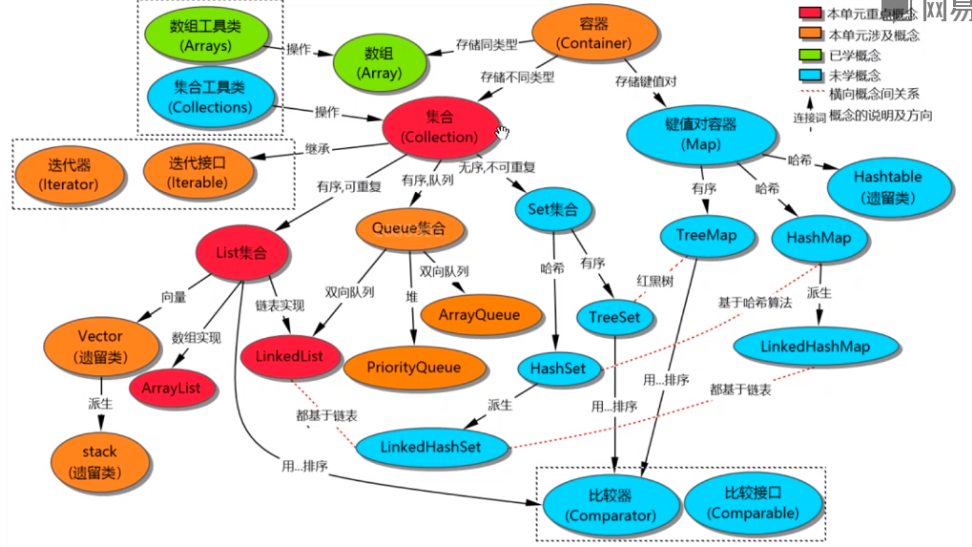
- 数组:存储相同类型的多个元素
- 对象:存储不同类型的多个元素
- 集合:存储多个不同类型的对象
List
List继承自Collection接口,是有序可重复的集合。
它的实现类有:ArrayList、LinkedList、Vector、Stack
ArrayList
本质上是一个能存储任意类型的对象的动态数组,元素的删除和添加涉及到数组的扩容以及拷贝元素,所以效率很慢。由于数组是可以通过下标来查找的,因此查找速度快。
LinkedList
基于双向链表实现,增删快,查找慢。根据链表的性质,增加元素时只需让前一个元素记住自己就行,删除的时候让前一个元素记住后一个元素,后一个元素记住前一个元素,这种增删的效率比较高,但查找元素需要遍历链表,效率低。
public static void main(String[] args){
List<Dog> list = new LinkedList<>();
System.out.println(list.size());
Dog dog1 = new Dog("小苏","藏獒");
Dog dog2 = new Dog("小王","二哈");
Dog dog3 = new Dog("小李","金毛");
((LinkedList<Dog>) list).addFirst(dog1);
list.add(dog2);
((LinkedList<Dog>) list).addLast(dog3);
System.out.println(list);
System.out.println(((LinkedList<Dog>) list).getFirst());
System.out.println(list.get(1));
System.out.println(((LinkedList<Dog>) list).getLast());
}
Vector
基于数组实现,线程同步的遗留集合类,和ArrayList原理相同,但是线程安全,效率低。
Stack
后进先出
Set
Set继承自Collection接口,是无序不可重复的集合
它的实现类有HashSet、LinkedHashSet、TreeSet
HashSet
基于哈希表实现,元素存储的地址是该元素的哈希值。
HashSet存储元素的步骤:
- 通过哈希算法计算元素的哈希值
- 判断集合中哈希值得位置是否已经有元素
- 若没有,则将元素添加到该位置
- 若有,使用equals方法判断该元素和已有的元素是否相等,相等则不添加,不相等则添加
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("邵阳---长沙");
set.add("武汉---南京");
set.add("合肥---北京");
set.add("武汉---南京");
System.out.println("-------第一种输出方式:toString方法--------");
System.out.println(set);
System.out.println("-------第二种输出方式:增强for循环--------");
for (String str: set) {
System.out.println(str);
}
System.out.println("-------第三种输出方式:迭代器方法--------");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// set集合是无序的,因此没有下标,无法用for循环来遍历
}
@Test
public void setObject(){
Set<Student> set = new HashSet<>();
set.add(new Student("小贝 ",9));
set.add(new Student("小胡 ",19));
set.add(new Student("小贝 ",9));
set.add(new Student("小福 ",23));
Iterator<Student> iterator = set.iterator();
while (iterator.hasNext()){
/*
* 由于hash表示无序的,因此输出结果可能和存储结果不一致
*/
System.out.println(iterator.next().toString());
}
/*
* 若Student类重写了equals方法,则第二个小贝不会被存入set,
* 这种情况下只会比较两个小贝的名字和年龄的值,因为两个小贝的名字和年龄一样,因此他们被认为是两个相同的对象
* 若Student类没有重写equals方法,则第二个小贝会被存入set,
* 这种情况下只会比较两个小贝的地址,因为是两个不同的对象所以地址不同,因此他们被认为是两个不同的对象
*/
}
/*
* 被重写的equals方法
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
/*
* 注意基本类型的变量直接用==比较,而对象类型的,分情况讨论:
* 若只比较值,则用equals方法,因为String类重写了equals方法
*/
}
LinkedHashSet
基于哈希表和双向链表实现,元素有序且不可重复,存储步骤和HashSet一致,元素的顺序是其存储顺序
@Test
public void printLinkedHashList() {
Set<String> set = new LinkedHashSet<>();
set.add("绝地求生");
set.add("球球大作战");
set.add("守望先锋");
set.add("超级玛丽");
set.add("超级玛丽");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
/* 输出结果和存储结果一致:
* 绝地求生
* 球球大作战
* 守望先锋
* 超级玛丽
*/
}
TreeSet
TreeSet是基于红黑树的有序且不可重复的集合,元素的顺序和元素本身有关,和存储顺序无关
/*
* 这个方法在执行的时候会报错,因为在TreeSet在存储时不知道根据学生的姓名还是年龄来排序,准确地说,Student * 类没有实现Comparable接口,因此无法对Student排序。将一组乱序的数字或字符串存入TreeSet,重新输出会得到* 一组有序的数据,因为String类默认实现了Comparable接口。
* 报错信息如下:java.lang.ClassCastException: Student cannot be cast to java.lang.Comparable
*/
@Test
public void testSort() {
Set<Student> set = new TreeSet<>();
set.add(new Student("小贝 ",9));
set.add(new Student("小胡 ",19));
set.add(new Student("小贝 ",10));
set.add(new Student("小福 ",23));
Iterator<Student> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
/*
* 对Student类进行修改,让他继承Comparable接口,并重写Comparable里的comparaTo方法,按照学生的年龄进行* 排序
*/
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public void comparaTo() {
}
@Override
public int comparaTo(Student o) {
/*
* 结果为负,排在o对象之前
* 结果为正,排在o对象之后
* 结果为0, 说明两个对象相等
*/
return this.age - o.age;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号