MapReduce过程<原创>
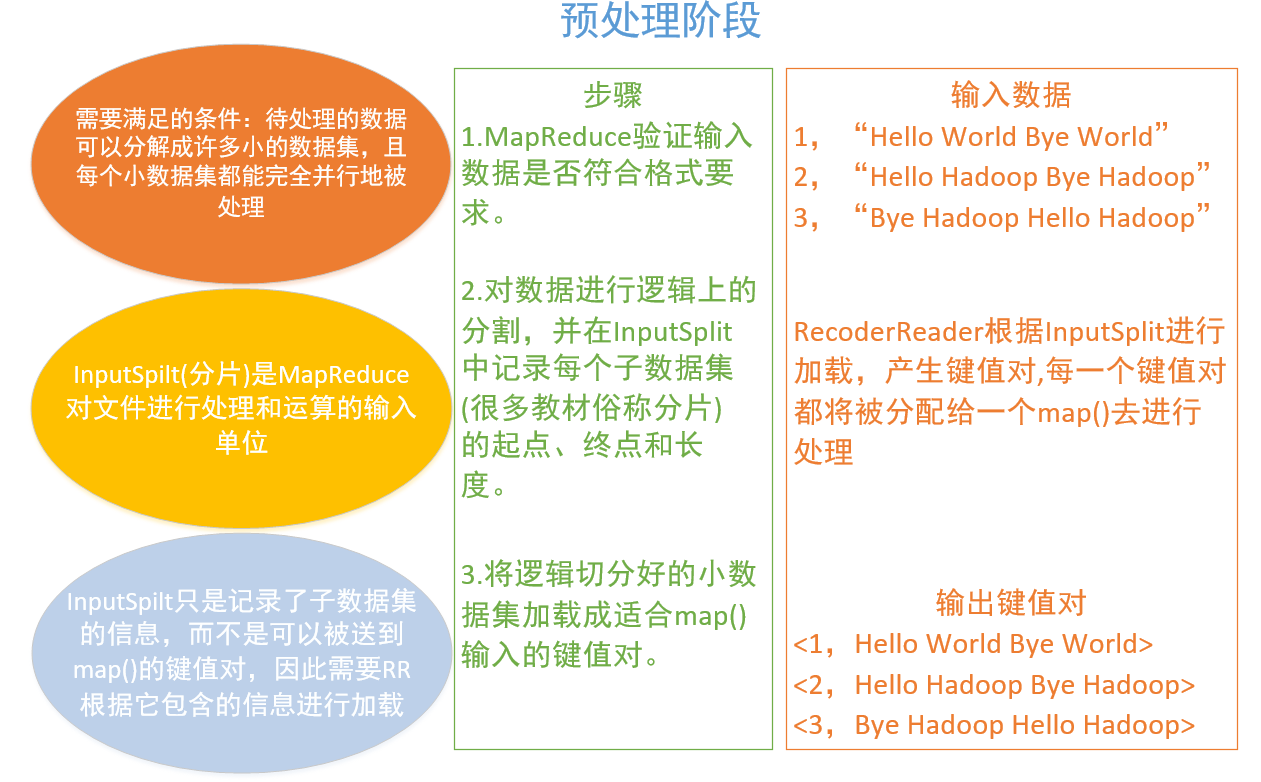
一、预处理阶段
二、Map阶段
一个Map任务被JobTracker(管家)分配到多个TaskTracker(弟弟)执行,如下图所示,弟弟的map()只负责拆分,虽然map()输出两个相同的键值对,但它并不会对两个重复的键值对进行合并,而且输出的键值对也是无序的,没有按照字母顺序排列。而这些工作都会交给Shuffle(洗牌)阶段去做。

三、Shuffle阶段
Shuffle阶段实际上并不是一个和Map阶段和Reduce阶段独立的阶段,实际上它分为Map端的Shuffle阶段和Reduce端的阶段,为了方便讨论,就把这个两个子阶段放在一起讨论,统称为Shuffle阶段。
(一)Map端的Shuffle阶段
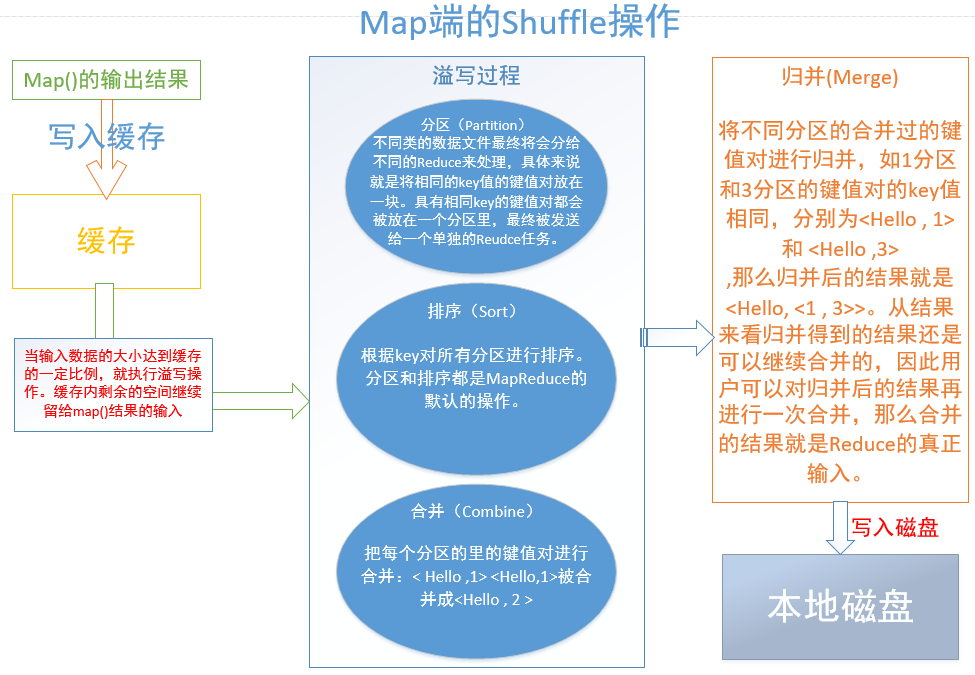
每个map()任务都会被分配一块缓存,对于每个map()的输出数据,不是直接写入磁盘,而是先写入缓存里,当缓存达到一定比例时对它进行溢写操作,将溢写好的数据进行归并(、合并)发送到本地磁盘,并清空该数据占用的缓存,还在执行的map()们可以继续不停地将结果写入缓存。之所以这样设计,是为了减少I/O消耗,节省了时间。
溢写,包括分区(Partiyion)、排序(Sort)、合并(Combine)。溢写过程,是在缓存中完成的。
看过巨佬的博客之后对错误的理解进行了更正:每个分区含有多个不同key值的键值对,而不是一个分区只含有一种key值对应的多个键值对。举例:
1分区: < Hello ,1> <Hello ,1 > <Hadoop ,1 > , 2分区:<World ,1 > <World ,1>
即key值为Hello的键值对全部被分到1分区,其他分区不会存在key值为Hello的键值对,而1分区除了Hello还有多个其他的key值的键值对存在。
合并(Combine)与归并(Merge)的区别:
合并是针对每个分区内部的键值对的操作,而归并是针对磁盘中的多个溢写文件的操作,将多个溢写文件归并成一个大的溢写文件。
对于两个键值对< a ,1 >和< a ,1>,合并的结果是 <a , 2 >:合并实际上就是在map端执行reduce的操作,是为了减少网络传输开销,但是并不是所有的情况都能使用合并操作,可通过调用job.setCombinerClass(MyReduce.class)设置这一操作;
而归并的结果是<a,<1,1>>,合并是不是默认MapReduce的默认操作,归并是默认操作。归并的结果是可以继续合并再作为最终结果发送到本地磁盘作为Reduce的输入的。
(二)Reduce端的Shuffle阶段
1.领取数据
Map端的Shuffle阶段将合并或归并好的数据发送到本地磁盘里。在Map任务开始后,Reduce会不断的通过RPC通信协议来询问JobTracker(管家),Map任务是否已经完成。JobTracker检测到一个Map任务完成后会通知相关的Reduce来领取属于自己的数据。一般系统中会存在多个Map机器,Reduce需要使用多线程同时从多个Map机器领取数据。
2.归并、输出
尽管每个map()都在之前进行过合并、归并处理,但当Reduce从多个Map机器中领取回数据后,Reduce机器的缓冲中又存在着相同的可以合并的键值对、具有相同key值的键值对也会被归并。在这个阶段,合并也不是默认的,需要用户自定义。和Map端的Shuffle阶段不同的是,当前阶段生成多个文件发送给Reduce阶段。
三、Reduce阶段
对不同分区的相同key对应的值进行相加,输出最后的结果。并写入到HDFS系统中,也就是写入磁盘。
一定要看:
巨佬博客(一看就懂系列):https://www.cnblogs.com/npumenglei/p/3631244.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号