DOM和selenium的使用准备
1、DOM
“文档对象模型(Document Object Model,简称DOM)
DOM提供了对整个文档的访问模型,将文档作为一个树形结构,树的每个结点表示了一个HTML标签或标签内的文本项
将HTML或XML文档转化为DOM树的过程称为解析(parse)。HTML文档被解析后,转化为DOM树,因此对HTML文档的处理可以通过对DOM树的操作实现。”
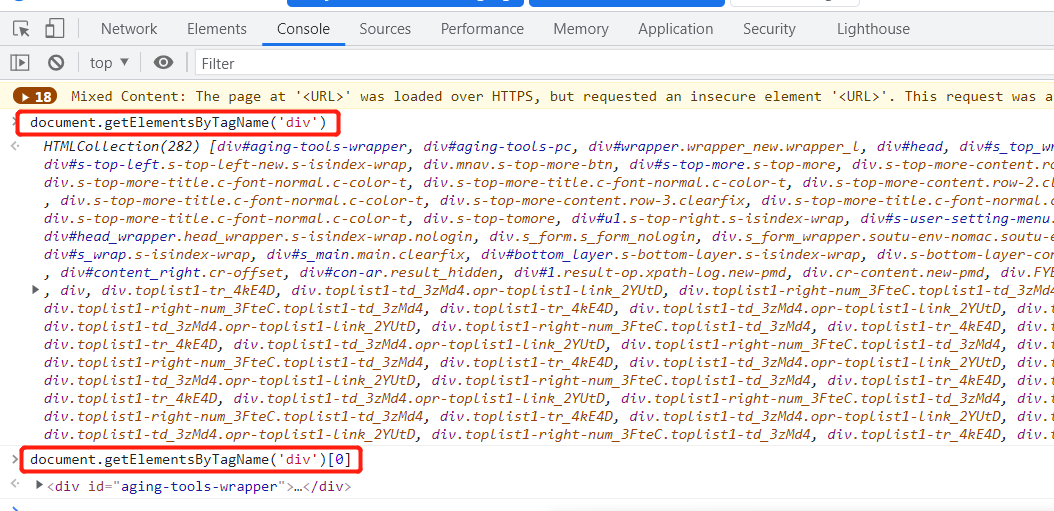
在打开的网页中,按f12--elements,再借助这个页面左上角的箭头,可以找到页面元素对应的html语言
在console窗口里可以通过document.getElementById/ClassName/TagName等进行操作,找出多个时,可以下标取值,取定后可以进行获取、改值等操作
如:
2、selenium的使用准备
① pip install selenium
② 搜索淘宝镜像,找到chromedriver(和浏览器版本相对应)下载,下载后解压得到一个.exe文件,将这个文件放到python的安装目录下(此步操作后不必再去配置环境变量)
https://npmmirror.com/
from selenium import webdriver # 配置了环境变量,不用传参数 driver = webdriver.Chrome() # 如果没有给chromedriver配置环境变量,要通过参数去指定chromedriver所在的路径 # driver = webdriver.Chrome(executable_path=r"chromedriver.exe所在的路径")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号