获取csdn某个博主的全部文章python代码
import requests
from lxml import etree
# 请求头,也可以随机一个请求头用header = {"User-Agent":UserAgent().random}
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
# 博主名字,记得换成你要爬取的博主名字
author_name = "xxxx"
# 博主博文页数
with open("page_num.txt", "r") as y:
for line in y:
line = line.strip('\n')
page_num = int(line)
y.close()
with open("url.txt", "w") as x:
for index in range(1, page_num + 1):
# 拼接URL
page_url = "https://blog.csdn.net/" + author_name + "/article/list/" + str(index)
# 发送请求,获取响应
response = requests.get(page_url, headers=header).content
# 将HTML源码字符串转换尘土HTML对象
page_html = etree.HTML(response)
# 博客文章的链接
csdn_article_link_list = page_html.xpath("//div[@class='article-item-box csdn-tracking-statistics']//h4//a/@href")
for obj in csdn_article_link_list:
x.write(obj)
x.write('\n')
x.close()
使用方法
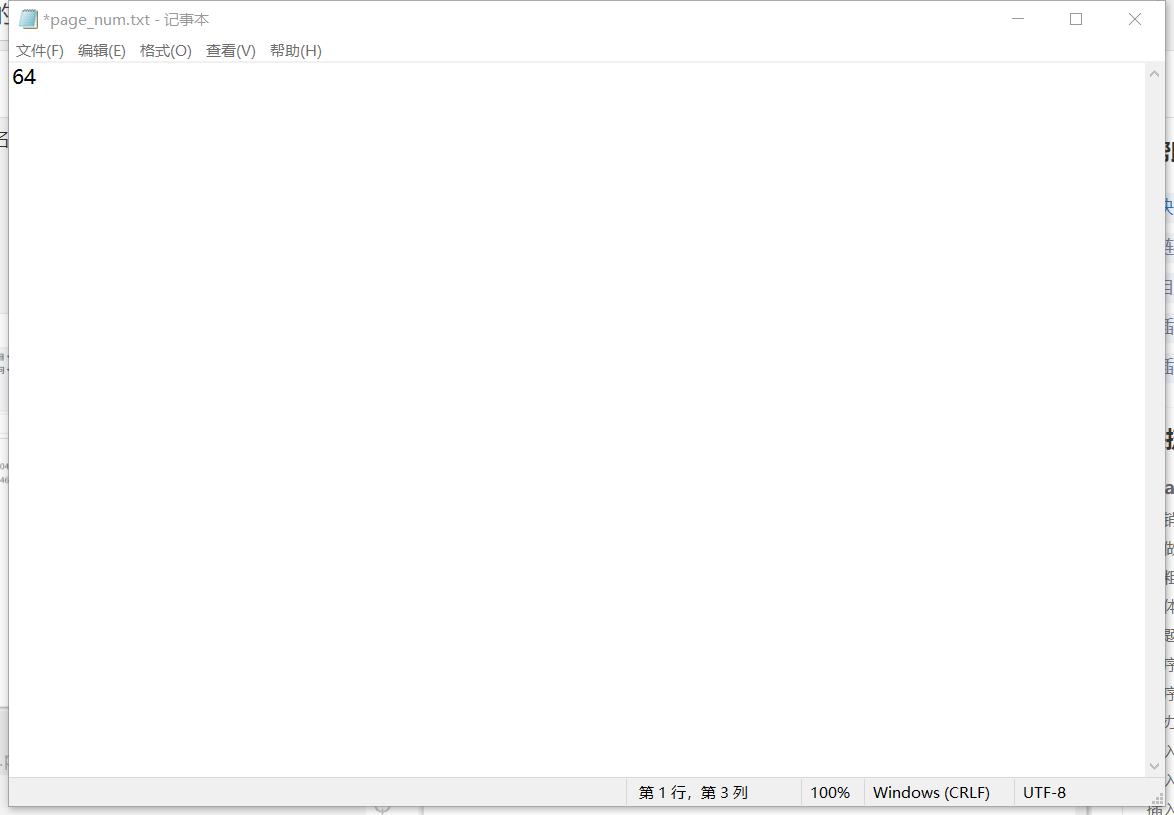
- 记得在代码的同级目录下创建一个名为
page_num.txt的文件,里面写你要爬取的博主的文章页数 - 记得修改代码里面的
author_name
注意事项
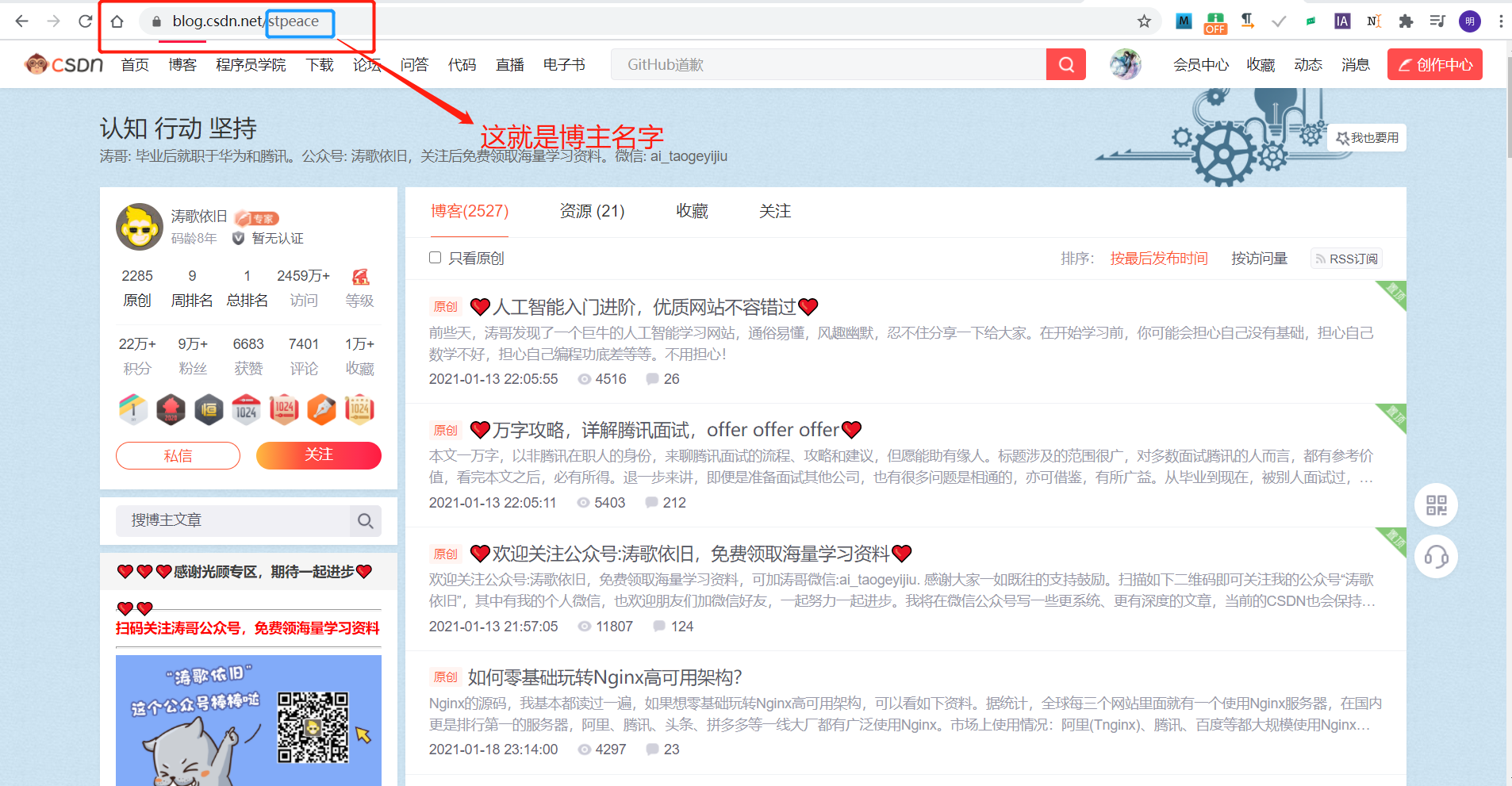
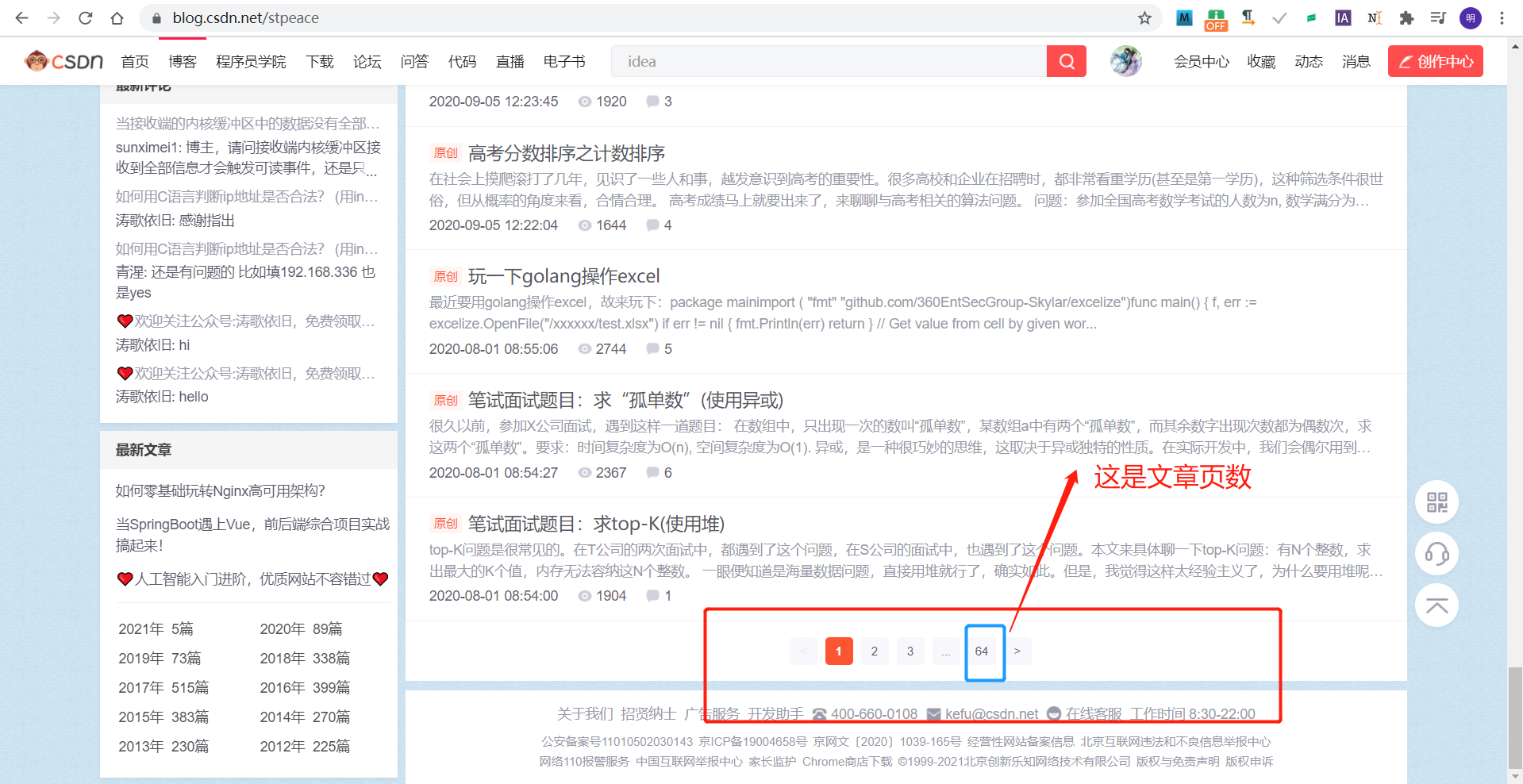
author_name和文章页数怎么找,进入你想要爬取博主的主页,以排名第一的大佬为例