

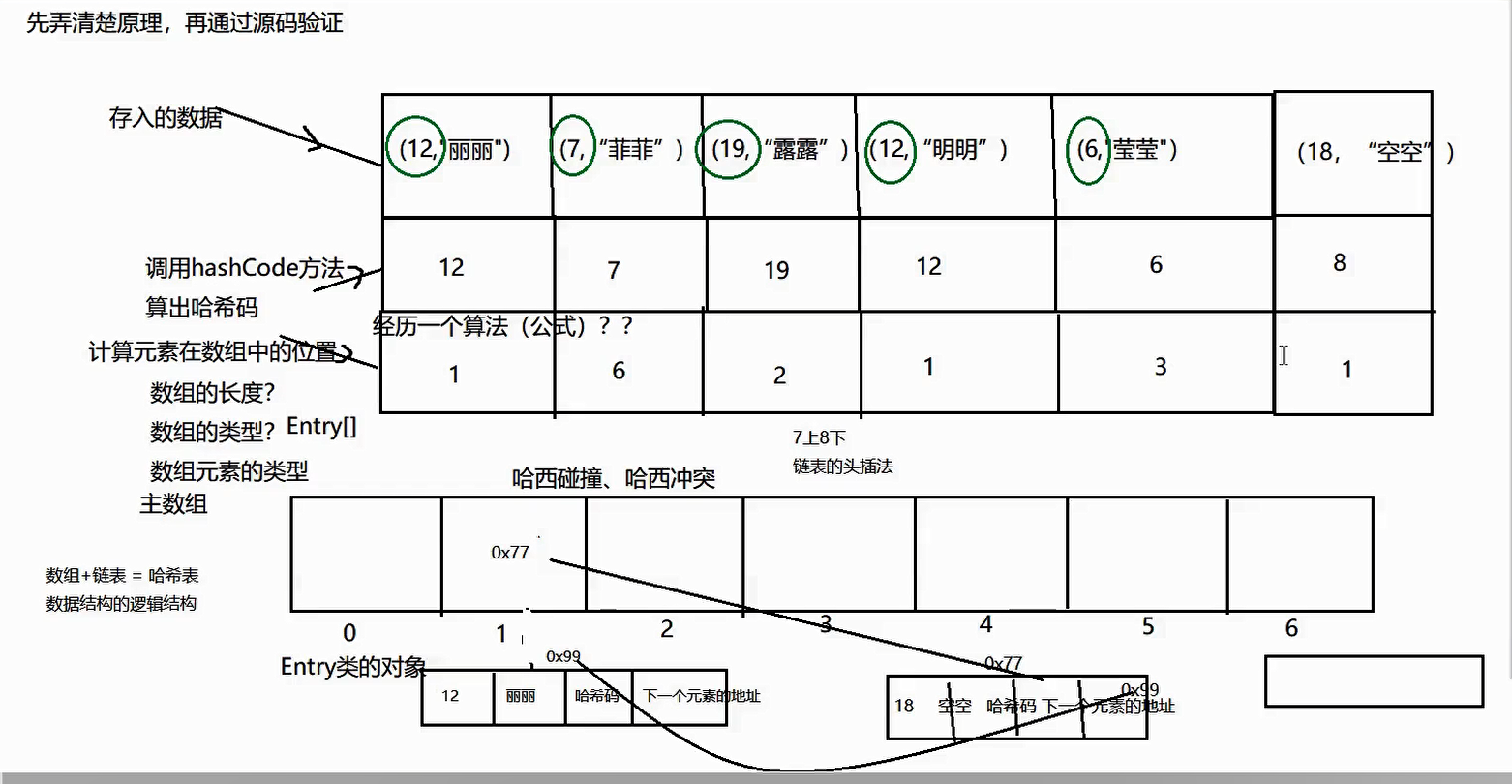
Hash Map 存储原理 (图解比较详细)
调用hashcode方法算出哈希码,然后再算出在主数组中对应的存储位置,将key value 、哈希码 、下一个元素的地址 这四个数据存储在一个Entry类的对象中,这样以来,主数组就成为了一个Entry的数组。
每一个数组元素都是由链表组成的,链表头部的头节点只存储下一个链表元素的地址,
哈希冲突(哈希碰撞):两个键值对根据key计算出的哈希值是相同的,也就意味着他们要存入同一个位置,分为两种情况:
1.key 完全一样,比如(12,"丽丽") (12,"明明") 先插入丽丽 ,后插入明明,这时候 明明 就会把 丽丽 替换掉,最后得到的结果是(12,"明明"),但是 12 是第一个插入的键值对的12。
2.key不一样,但是计算出的值 是相等的,最后也要存储到同一个位置,这是将后插入的元素方法头节点的后面,而头节点存储的地址也要换成后插入节点的地址,后插入节点的地址
下一个元素的地址也就只想原来的节点(元素和节点理解为同一概念,知识为了便于分辨过程中不同元素)
其实jdk 1.7 和jdk 1.8 插入方式是不一样的,遵循 “7 上 8 下” 的原则,1.7是在前面插入(头插法),而1.8 是在后面插入(尾插法)
最底层的原理 是由哈希表组成 ,而 哈希表 = 数组 + 链表
HashMap的父类AbstractMap已经实现了Map接口,但是在HashMap中又再一次地实现了类Map接口,这个操作就是一个多余地操作,包括list也是,本来是作者想对做一些事,但是最后没做
重要属性 :
//HashMap的父类AbstractMap已经实现类Map接口,但是源码中又单独实现了Map接口//这个操作就是一个多余的操作-->集合的创作者承认了
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>,Cloneable, serializable{//重要属性:
static final int DEFAUIT_INITIAL_CAPACITY = 16;//定义了一个16,一会要赋给数组的长度static final int MAXIMUM _CAPACITY= 1 <<30;//定义了一个很大很大的数
static final float DEFAULT_LOAD_FACTOR = 0.75f;//定义了一个值:0.75负载因子,加载因子transient Entry<K,V>[]table;//底层主数组
transient int size;//添加的元素的数量
int threshold;//定义个变量,没赋值默认为0 ,-->这个变量是用来表示数组扩容的边界值,门槛值final float loadFactor;//这个变量用来接收:装填因子,负载因子,加载因子


put方法
在put()方法添加元素地时候,计算出哈希码,然后在进行二次散列,才是最后的位置,在数组中的位置,底层计算位置的公式都是&运算,相当于对长度length取余数,但是用&位比较的方式效率高于直接取余,但是length 必须书 2的n次幂,所以底层才要求length 是2的n次幂。
JDK 1.8 存储原理
jdk1.8与1.7 的hashmap实现还是有一些差别的,但是表层的逻辑理解上差别并不是很大。8在7 的基础上,二次散列由四次变为一次,将头插法改为尾插法,为了更好的遍历链表,而且在链表长度大于8的时候会调用treeifbin()方法,来判断数组长度是否大于64,如果大于64,就会将链表树化,变为红黑树,而当删减红黑树中的元素的时候,删除到书的元素小于6的时候,就会将红黑树链化,变为链表。
在元素方面,使用了Node节点并且实现了Map.Entry<K , V >的接口,所以元素不再是Entry,而是Node

